Tháng 2 năm 2026, nền tảng Xiaohongshu đã ra thông báo yêu cầu nội dung được tạo hoặc tổng hợp bằng AI phải được chủ động gắn nhãn, những nội dung không gắn nhãn sẽ bị hạn chế phân phối. Hơn ba tháng sau, một dự án mã nguồn mở có tên guizang-social-card-skill xuất hiện trên GitHub, chuyên tạo đồ họa với tỷ lệ 3:4 cho Xiaohongshu và ảnh bìa cho WeChat Official Accounts. Lựa chọn kỹ thuật của nó có một điểm khác thường: không sử dụng bất kỳ mô hình AI nào để tạo ra pixel hình ảnh, toàn bộ giao diện dựa vào HTML+CSS để render, còn hình minh họa lấy từ việc tìm kiếm trong các thư viện ảnh thực tế như Unsplash. Đầu ra không phải là "hình ảnh được tạo bởi AI", mà là một ảnh chụp màn hình (screenshot) được raster hóa từ engine trình duyệt.
Lựa chọn này tương ứng với một sự thay đổi cụ thể. Kể từ năm 2026, Xiaohongshu đã triển khai mô hình nhận diện âm thanh-hình ảnh, thông qua việc phân tích quy luật phân bố pixel của hình ảnh và đặc trưng âm thanh để phán đoán nội dung AIGC. Cùng thời điểm, nền tảng đã xử lý hơn 800 nghìn tài khoản đăng ký hosting AI và gần 150 nghìn bài ghi chép (note) giả mạo bằng AI. Đối với những người sáng tạo nội dung cần sản xuất đồ họa với tần suất cao, xác suất hình ảnh được tạo bởi Midjourney hoặc Canva AI bị phát hiện và gắn nhãn đang tiếp tục tăng lên. Skill của Tàng sư phụ đã chọn một con đường khác: để AI đưa ra quyết định về bố cục (layout), và giao pixel cuối cùng cho engine render cùng thư viện ảnh thực tế.
Đây là một sự vòng tránh kỹ thuật có chủ ý. Nhưng giải pháp này có thể đi được bao xa, phụ thuộc vào độ linh hoạt trong định nghĩa của nền tảng đối với cụm từ "nội dung được tạo/tổng hợp bằng AI".
28 khung bố cục, AI chịu trách nhiệm về logic sắp xếp chứ không phải vẽ tranh
Tàng sư phụ tên thật là Quy Tàng, trước đây đã phát hành guizang-ppt-skill, cũng là một công cụ AI hướng đến việc thiết kế đồ họa. Lần này, social-card-skill có định vị tập trung hơn: hướng đến đồ họa 3:4 cho Xiaohongshu, ảnh bìa 1:1 và 21:9 cho WeChat Official Accounts, đầu ra có độ phân giải lần lượt là 1080×1440, 1080×1080 và 2100×900.
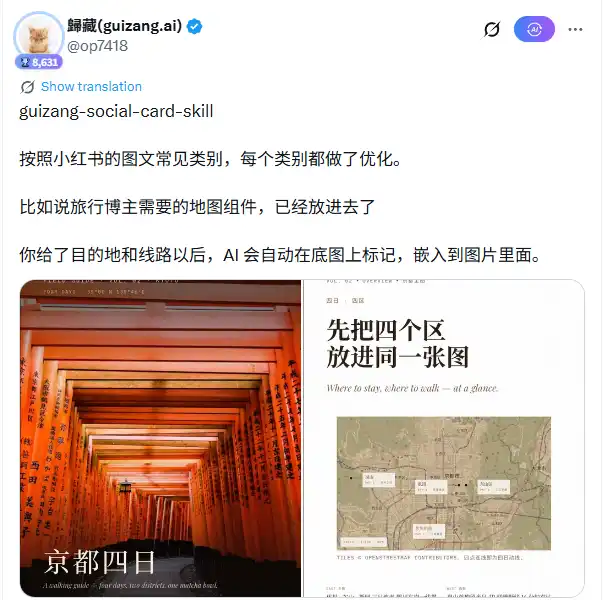
Về kiến trúc kỹ thuật, Skill này tích hợp sẵn 28 khung bố cục, chia thành hai hệ thống trực quan: Editorial (phong cách tạp chí, 16 bố cục) và Swiss (phong cách Swiss International Style, 12 bố cục), kèm theo 10 bộ cài đặt màu sắc chủ đề (theme) mặc định. Sau khi người dùng nhập thông tin về điểm đến, hành trình hoặc chủ đề bài ghi chú, AI chịu trách nhiệm chọn khung bố cục phù hợp, quyết định vị trí chữ, xử lý tham số đánh dấu bản đồ, sau đó viết tất cả quyết định thiết kế thành HTML+CSS. Playwright render engine tiếp quản các bước tiếp theo, chụp ảnh màn hình từng trang và xuất ra PNG.
Một thành phần đặc biệt hữu ích cho các blogger du lịch là module bản đồ. Nó sử dụng MapLibre để tải các tile thực tế từ OpenStreetMap, hỗ trợ đánh dấu và nối nhiều địa điểm. Người dùng chỉ cần cung cấp tên thành phố hoặc điểm tham quan, AI tự động tạo bản đồ nền có đánh dấu và nhúng vào bố cục. Quy trình làm việc liên quan đến nguồn ảnh đi kèm có thứ tự ưu tiên rõ ràng: ảnh thực tế do người dùng cung cấp được ưu tiên nhất; nếu không có ảnh từ người dùng, sẽ tự động tìm kiếm ảnh minh họa theo thứ tự Unsplash → Pexels → Flickr CC → Wallhaven.

Toàn bộ quy trình được thực hiện qua bảy bước: Intake (tiếp nhận đầu vào) → Style & Theme (xác định phong cách và chủ đề) → Layout Selection (lựa chọn bố cục) → Asset Prep (chuẩn bị tài nguyên) → Compose & Render (sắp xếp bố cục và render) → Deliver & Review (xuất và kiểm tra lại) → Iterate (lặp lại và sửa đổi). Mỗi bước đều được ghi lại trong file .poster trong thư mục task. Khi xuất hàng loạt ảnh, chạy lệnh
node render.mjs, Playwright sẽ render lần lượt từng cái. Còn có một script kiểm tra validate-social-deck.mjs để đo lường các phần tử DOM trong môi trường trình duyệt thực, phát hiện các sự cố bố cục như chữ bị tràn, kích thước font vượt quá giới hạn, va chạm với các phần tử footer.
Mục tiêu thiết kế của cơ chế này rất rõ ràng: kiểm soát chính xác như phần mềm dàn trang in ấn, chứ không tự do nhưng không thể đoán trước như các mô hình khuếch tán (diffusion model). Cái giá phải trả là sự tự do sáng tạo bị thu hẹp trong 28 khung. Đối với những người sáng tạo phụ thuộc vào phong cách nhiếp ảnh cá nhân, các yếu tố vẽ tay hoặc cắt dán không theo quy tắc, những khung bố cục này không mang lại sự nâng cao hiệu suất, mà là các ràng buộc về thiết kế.
Về độ khó sử dụng, phiên bản CLI cần cài đặt Playwright, môi trường Node, đồng thời cần có quyền truy cập API của Claude Code hoặc Codex. Còn có một cổng vào phiên bản web xiaohongshu.guizang.ai dành cho người dùng không phải nhà phát triển, nhưng thông tin về việc tính năng của nó có đầy đủ và nhất quán với phiên bản CLI hay không thì chưa có so sánh công khai. Một số tweet trên nền tảng X và README được cập nhật liên tục từ nhà phát triển cho thấy dự án này vẫn đang được lặp lại nhanh chóng.
Pixel không đến từ mô hình sinh, nhưng tuân thủ không có nghĩa là an toàn lâu dài
Logic phát hiện nội dung AI của Xiaohongshu, dựa trên phân tích thông tin công khai và tài liệu kỹ thuật, chủ yếu dựa vào mô hình nhận diện âm thanh-hình ảnh. Mô hình này phân tích quy luật phân bố pixel của hình ảnh để phán đoán nội dung có đến từ mô hình tạo AI hay không. Các mô hình khuếch tán (diffusion model) và GAN khi tạo hình ảnh sẽ để lại những đặc trưng thống kê cụ thể ở cấp độ pixel, những đặc trưng này khác biệt với ánh sáng tự nhiên được cảm biến máy ảnh chụp, biến dạng ống kính, mẫu nhiễu. Mục tiêu huấn luyện của mô hình nhận diện âm thanh-hình ảnh chính là nắm bắt sự không nhất quán trong quy luật thống kê này.
Logic tránh né của Skill Tàng sư phụ được xây dựng dựa trên một sự phân biệt quan trọng: pixel hình ảnh đầu ra của nó không đến từ bất kỳ mô hình tạo nào. Engine render HTML thực hiện raster hóa các kiểu CSS, tạo ra các đặc trưng phân bố pixel gần giống với ảnh chụp màn hình giao diện trình duyệt hoặc đầu ra của phần mềm dàn trang. Phần ảnh chụp đến từ tài liệu ảnh thực tế do người chụp từ các thư viện như Unsplash, những hình ảnh này được chụp bằng máy ảnh, qua xử lý hậu kỳ thủ công, không mang dấu vết của mô hình khuếch tán.

Nhưng sự phân biệt này chỉ đúng với điều kiện tiên quyết là định nghĩa phạm vi "nội dung được tạo/tổng hợp bằng AI" của nền tảng vừa khớp với ranh giới "mô hình AI tạo ra pixel". Thông báo chính thức của Xiaohongshu sử dụng cụm từ "nội dung được tạo/tổng hợp bằng AI", bản gốc bao phủ phạm vi không hẹp. Một khi nền tảng mở rộng định nghĩa ra "đầu ra render chương trình được thiết kế hỗ trợ bởi AI", hoặc đưa đặc trưng render trình duyệt của hình ảnh raster hóa HTML vào tập dữ liệu huấn luyện mô hình nhận diện, lợi thế kỹ thuật hiện tại của giải pháp này sẽ biến mất.
Nền tảng có cơ sở kỹ thuật và động cơ quản trị để mở rộng định nghĩa. Bản thân mô hình nhận diện âm thanh-hình ảnh đang được lặp liên tục. Nếu dữ liệu huấn luyện đưa vào nhiều mẫu so sánh giữa hình ảnh render HTML và hình ảnh tạo bởi AI, mô hình có thể học cách phân biệt "đặc trưng khử răng cưa subpixel của font chữ được render bởi trình duyệt" với "khối pixel không đều khi GAN tạo ra chữ". Hiện tại chưa có thông tin công khai nào cho thấy Xiaohongshu đã bắt đầu huấn luyện theo hướng này, nhưng xét về ranh giới khả năng của mô hình, việc mở rộng như vậy là khả thi về mặt kỹ thuật.
Một yếu tố cần lưu ý hơn nữa là các yếu tố tuân thủ liên quan đến hosting mini program. Hiện tại không thấy bất kỳ tài liệu chính thức nào nói rằng Skill này đã tích hợp số đăng ký mô hình (model registration number) hoặc đã hoàn tất các thủ tục đăng ký tuân thủ liên quan. Nếu nền tảng bổ sung yêu cầu truy xuất nguồn gốc chuỗi công cụ tạo hình ảnh trong quy trình xét duyệt nội dung, việc thiếu thông tin đăng ký có thể trở thành điểm chặn mới.
Engine template API, công cụ tùy chỉnh nền tảng và render HTML, đang mở ra ba con đường phân kỳ
Quan sát các công cụ tạo ảnh cho mạng xã hội trên thị trường, sẽ thấy chúng đang phân hóa thành ba hướng kỹ thuật khác nhau. Mỗi hướng đối mặt với cấu trúc rủi ro kiểm duyệt khác nhau.
AI model trực tiếp xuất ảnh. Con đường này đại diện là tính năng Magic Design do Canva AI phát hành vào tháng 4 năm 2026, nó tạo ra bản thiết kế bao gồm các yếu tố trực quan AI trực tiếp từ lời nhắc văn bản (text prompt). Các hình ảnh được tạo bởi các mô hình như Midjourney, DALL·E cũng thuộc phạm trù này. Vấn đề rõ ràng: những hình ảnh này là mục tiêu chính của mô hình nhận diện âm thanh-hình ảnh. Cách ứng phó của Canva là khuyến khích gắn nhãn minh bạch, thay vì tránh né phát hiện. Trên Xiaohongshu, hiện chưa có dữ liệu công khai nào xác nhận việc các bài đăng có ảnh từ AI model bị gắn nhãn có làm giảm trọng số đề xuất hay không, nhưng tuyên bố của nền tảng về "hạn chế phân phối nội dung AI không được gắn nhãn" đã là chính sách đã định. Mỗi lần cập nhật phiên bản của mô hình khuếch tán, đặc trưng thống kê pixel có thể thay đổi, mô hình phát hiện tương ứng cũng sẽ được lặp đồng bộ, người sáng tạo phải đối mặt với một bia mục tiêu liên tục di chuyển.
Render bằng engine template API. Bannerbear là đại diện tiêu biểu của hướng này. Người dùng tạo template trong trình thiết kế, truyền dữ liệu JSON qua REST API để sửa đổi các biến layer, server-side render và xuất ra PNG hoặc JPG. Lõi của nó cũng là "render chương trình" chứ không phải "mô hình tạo pixel", đầu ra không chứa dấu vết của mô hình khuếch tán. Sự khác biệt với Skill của Tàng sư phụ nằm ở chỗ: template của Bannerbear phụ thuộc vào thiết kế thủ công, AI không tham gia vào quyết định bố cục; Skill của Tàng sư phụ để Claude trực tiếp đọc và viết HTML, quyền lựa chọn bố cục giao cho AI. Rủi ro của giải pháp Bannerbear nằm ở một khía cạnh khác: khi một lượng lớn tài khoản sử dụng cùng một template, cùng một bảng màu, cùng một font chữ để sản xuất đồ họa, ngay cả khi mỗi hình ảnh không phải do AI tạo, nó cũng sẽ kích hoạt nhận diện mô hình "sản xuất hàng loạt có chương trình" (programmatic batch production) ở phía nền tảng. Điều kiện kích hoạt quy tắc chống spam không hoàn toàn giống với phát hiện AI, nhưng đối với những người sáng tạo vận hành tài khoản hàng loạt, kết quả cuối cùng vẫn là bị hạn chế phân phối.
Tạo tùy chỉnh cho nền tảng. Pin Generator được thiết kế riêng cho Pinterest, tự động tạo Pin hình ảnh phù hợp với sở thích thuật toán của nền tảng. Cốt lõi của hướng đi này không phải là tránh né, mà là thích ứng hoàn toàn - kích thước, phong cách trực quan, nhịp độ đăng tải đều tuân thủ quy chuẩn nền tảng. Ưu điểm là rủi ro kiểm duyệt thấp nhất, nhược điểm cũng rõ ràng: khả năng của công cụ bị ràng buộc chặt chẽ với quy tắc nền tảng, khi Pinterest điều chỉnh thuật toán hoặc hạn chế gọi API bên thứ ba, công cụ sẽ mất tác dụng ngay lập tức. So sánh với Skill của Tàng sư phụ, cái trước thuộc loại công cụ chuyên dụng cho nền tảng, cái sau là giải pháp đa nền tảng phổ quát. Công cụ chuyên dụng nền tảng an toàn hơn nhưng cũng mong manh hơn, giải pháp đa nền tảng linh hoạt hơn nhưng phức tạp hơn, đây là một sự đánh đổi xuất hiện lặp đi lặp lại trong lĩnh vực công cụ AI.
Cấu trúc rủi ro của ba con đường không giống nhau. Xuất ảnh bằng AI tự do nhất nhưng mỗi lần cập nhật đều phải ứng phó với mô hình phát hiện mới. Engine template ổn định nhất nhưng có thể bị nhận diện nhầm bởi quy tắc chống spam. Render HTML đi ở giữa hai cái này: bố cục được AI linh hoạt kiểm soát, pixel giao cho trình duyệt và tài liệu ảnh thực tế, tránh được phát hiện ở tầng "AI tạo pixel", nhưng không thể đối phó với sự mở rộng quy tắc ở tầng ngữ nghĩa nền tảng.
Giới hạn trên của hệ thống bố cục, không nằm trong code mà nằm ở loại hình nội dung
28 khung bố cục bao phủ hai hệ thống trực quan chủ đạo là phong cách tạp chí và phong cách Swiss. Đối với các blogger du lịch cần hiển thị tuyến đường bản đồ, dòng thời gian, lịch trình nhiều ngày, hệ thống này có độ phù hợp cao. Việc đánh dấu bản đồ và nối các điểm trong hành trình là thông tin cốt lõi của những bài ghi chép này, khung bố cục đã cấu trúc hóa thông tin, đồng thời duy trì cảm giác chuyên nghiệp của việc dàn trang.
Nhưng hệ sinh thái nội dung của Xiaohongshu phong phú hơn nhiều so với hướng dẫn du lịch. Các bài ghi chép về phối đồ phụ thuộc vào phong cách nhiếp ảnh cá nhân và điều chỉnh màu sắc, đánh giá mỹ phẩm cần ảnh chụp macro độ phân giải cao và ảnh so sánh sản phẩm, nội dung về lối sống sử dụng nhiều ảnh cắt dán (collage) và chú thích viết tay. "Bố cục" của những loại nội dung này không phải là sự trình bày cấu trúc thông tin, mà là sự thể hiện thẩm mỹ cá nhân và cảm xúc. 28 khung bố cục trong bối cảnh này không phải là công cụ, mà là ràng buộc.

Các hạn chế về mặt kỹ thuật cũng rất thực tế. Hiện tại hỗ trợ ba kích thước: 1080×1440 (Xiaohongshu 3:4), 2100×900 (WeChat Official Accounts 21:9) và 1080×1080 (WeChat Official Accounts 1:1). Ảnh bìa dọc 9:16 của Douyin (TikTok Trung Quốc), ảnh bìa ngang 16:9 của Bilibili không được hỗ trợ. Thư viện ảnh phụ thuộc vào Unsplash và Pexels, tài liệu của hai nền tảng này nghiêng về nhiếp ảnh chất lượng cao, phù hợp với nhu cầu ảnh minh họa cho du lịch, phong cảnh, kiến trúc đô thị. Nhưng độ phủ của các tài liệu tần suất cao cho nội dung chuyên sâu như ảnh cận cảnh đồ ăn, ảnh chụp sản phẩm mỹ phẩm, ảnh từng món đồ phối đồ thì có hạn trong các thư viện này. Chiến lược ưu tiên ảnh của người dùng có thể phần nào giảm nhẹ vấn đề này, với điều kiện người sáng tạo tự có đủ tài liệu ảnh thực tế tích lũy được.
Cơ chế kiểm tra là một con dao hai lưỡi. validate-social-deck.mjs có thể chặn các sự cố bố cục trước khi xuất ảnh, đảm bảo 100 lần render hàng loạt không có lỗi. Đây là sự đảm bảo hiệu suất trong các tình huống vận hành cần cập nhật hàng chục hình ảnh mỗi ngày. Nhưng nó cũng có nghĩa là bất kỳ thiết kế nào không tuân thủ quy tắc bố cục đặt trước đều sẽ bị script từ chối. Những người sáng tạo muốn thêm một trang trí chữ nghiêng hoặc khoảng cách lề tùy chỉnh trong bố cục tiêu chuẩn, không thể kéo và điều chỉnh trực tiếp như trong Canva, mà cần chỉnh sửa trực tiếp mã nguồn HTML và CSS.
Ngưỡng triển khai cục bộ (local deployment) là một điểm phân tầng khác. Những người sáng tạo có thể chạy Playwright và script Node, có thể đi sâu vào khung bố cục và script render để tùy chỉnh. Nhưng đối với phần lớn blogger trên Xiaohongshu, những gì họ tiếp cận được là tập con chức năng của giao diện phiên bản web. Hai loại người dùng này nhận được giá trị thực tế khác nhau rất lớn từ Skill này. Nhóm người dùng cốt lõi của dự án mã nguồn mở là những người sáng tạo và nhà phát triển có nền tảng kỹ thuật, sẵn sàng mày mò, chứ không phải nhu cầu "xuất ảnh một click" của những người sản xuất nội dung thông thường.
Không có câu trả lời vạn năng, nhưng sự phân hóa của các hướng kỹ thuật tự nó đã nói lên vấn đề
Một blogger du lịch trên Xiaohongshu đứng trước ba lựa chọn: dùng Midjourney tạo ảnh hành trình phong cách minh họa, chấp nhận rủi ro bị gắn nhãn và giảm trọng số; dùng Bannerbear thiết lập template và mỗi ngày đổ dữ liệu hàng loạt vào, chấp nhận rủi ro chống spam do template đồng nhất mang lại; hoặc dùng Skill của Tàng sư phụ, để AI chọn bố cục rồi dùng HTML render ra ảnh, chấp nhận rủi ro nền tảng mở rộng định nghĩa "nội dung tổng hợp". Không có lá bài an toàn, chỉ có sự kết hợp của các cấu trúc rủi ro khác nhau.
Bản thân cục diện này đang truyền tải một thông điệp: cuộc đua lặp giữa nền tảng và công cụ AI đã bắt đầu. Mỗi lần nền tảng cập nhật mô hình phát hiện, thời kỳ lợi thế kỹ thuật của một loạt công cụ sẽ kết thúc. Mỗi lần có công cụ mới tìm ra đường vòng tránh, nền tảng lại điều chỉnh chiến lược. Đây không phải là một quá trình sẽ hội tụ đến trạng thái ổn định. Thời hạn hiệu lực của giải pháp render HTML phụ thuộc vào hướng huấn luyện của mô hình nhận diện âm thanh-hình ảnh của Xiaohongshu là tiếp tục tập trung vào "đặc trưng pixel của mô hình khuếch tán", hay mở rộng ra "tất cả pixel không phải từ nhiếp ảnh gốc".
Đối với người sáng tạo nội dung, việc phân biệt "AI hỗ trợ" và "AI thay thế" trở nên có ý nghĩa thực tế. Thái độ của nền tảng đã rõ ràng: khuyến khích AI như một bộ khuếch đại sáng tạo, phản đối việc dùng AI thay thế con người để sản xuất hàng loạt chất lượng thấp. Trong Skill của Tàng sư phụ, AI đưa ra quyết định bố cục chứ không phải tạo nội dung, ảnh chụp là thực tế, bố cục là khung do nhà thiết kế con người đặt trước. Điều này vừa khớp với vùng "AI hỗ trợ". Những đồ họa văn bản được sản xuất hoàn toàn bằng mô hình sinh từ văn bản đến hình ảnh, mới là đối tượng mà nền tảng muốn xử lý rõ ràng.
Hiện tại chưa chắc chắn liệu sự phân biệt này có trở thành tiêu chuẩn vận hành cho việc kiểm duyệt của nền tảng hay không. Nhưng các nhà phát triển công cụ đã dùng lựa chọn kỹ thuật để phản hồi định nghĩa này rồi.






