文 | 字母AI
每次前沿模型发布,AI圈都会盯着几张熟悉的成绩单。
MMLU-Pro、MMMU、MMMU-Pro……这些名字对普通用户来说有些陌生,但对模型公司和研究者而言,它们几乎已经成了“标准科目”。GPT、Claude、Gemini、Llama、Qwen、DeepSeek们不断在这些基准上交卷。
“是骡子是马拉出来溜溜”,模型怎么样,往往都要靠这些分数来证明。
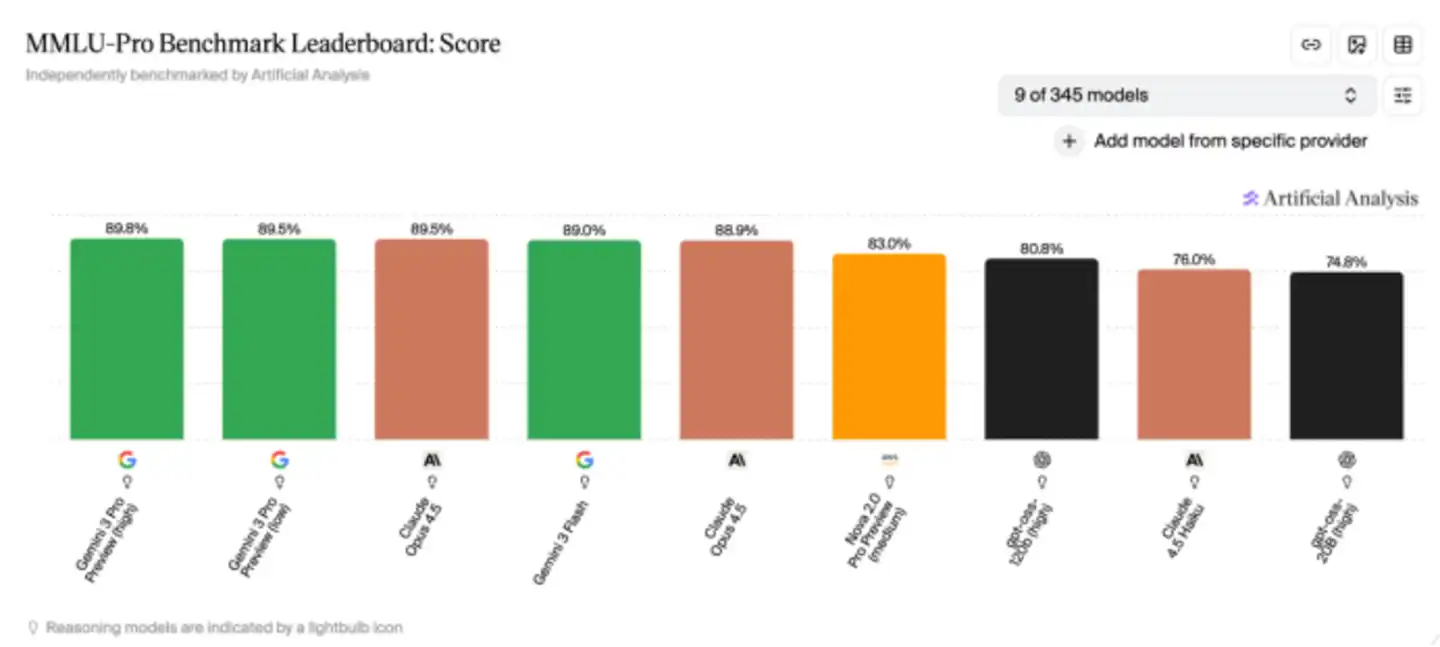
很多模型发布会上的性能对比图,离不开它们;HuggingFace上的一些排行榜,也建立在这些评测体系之上。甚至可以说,今天AI行业讨论模型能力时,使用的已经是一套由这些基准定义的共同语言。
但有意思的是,几乎所有人都在关注分数,却很少有人知道出题的人是谁。而MMLU-Pro、MMMU和MMMU-Pro背后,都能看到同一个名字——陈文虎。
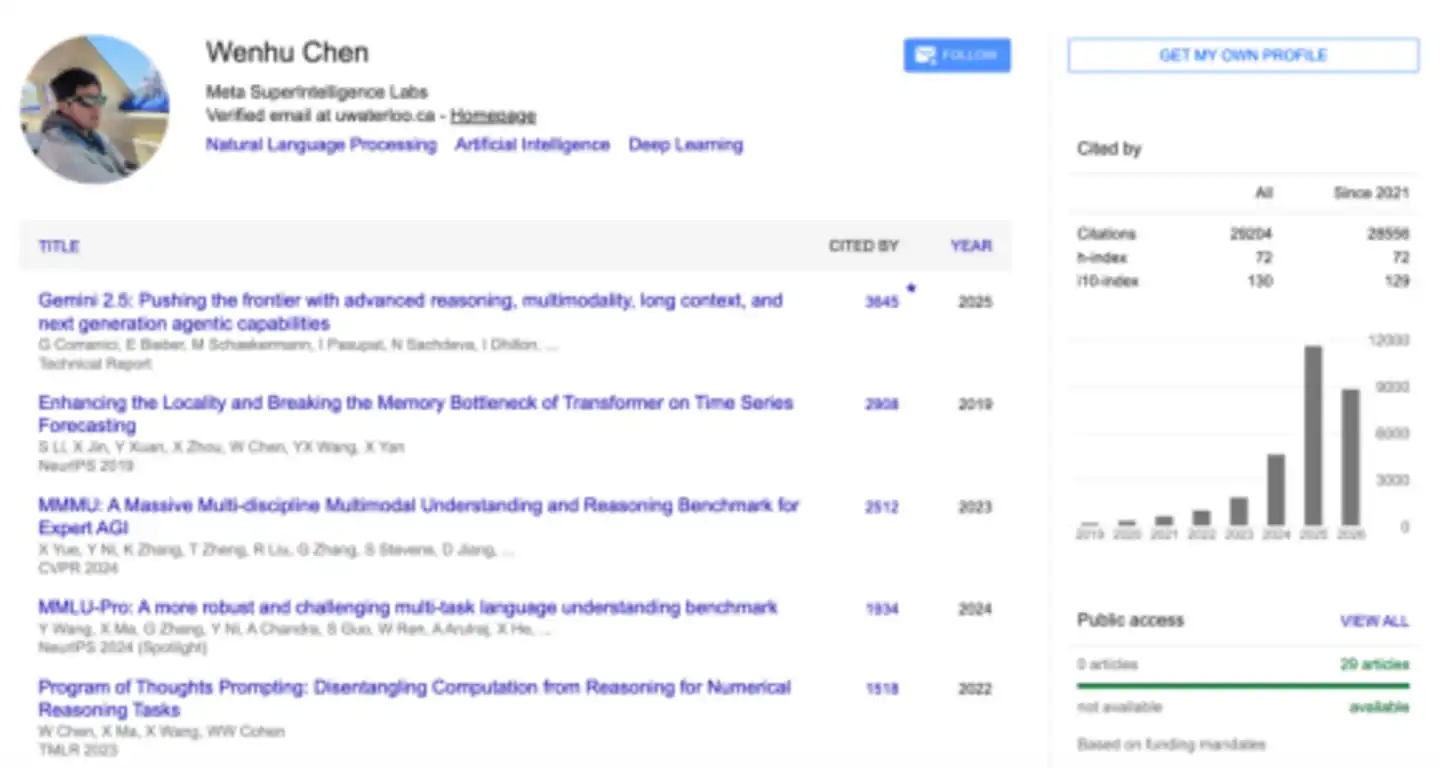
他是加拿大滑铁卢大学计算机科学系助理教授,在谷歌学术上,他的论文被引用超过3万次。
他也是“老虎实验室(TIGERLab)”的创始人,这个实验室的英文全称是Text and Image GEnerative Research Lab,因为名字里有一个“虎”字,陈文虎为其起了一个很有辨识度的中文名——虎头帮。
旧考卷失灵之后
陈文虎最先被更多人注意到,是因为MMLU-Pro。
MMLU曾经是大语言模型能力评估中最常用的基准评测之一。它像一张综合试卷,覆盖多个学科,用来衡量模型在知识理解和推理任务上的表现。
在早期,这张卷子很有用。模型之间的差距能被分数拉开,行业也可以通过它观察大语言模型是不是真的在进步。
但问题很快出现了。
随着模型能力不断提升,MMLU逐渐变得“不够考”了。前沿模型的分数越来越高,彼此之间的差距越来越小。
到OpenAI发布o3之后,这个问题变得更加明显。o3在MMLU上的准确率已经接近100%,其他前沿模型也陆续交出逼近满分的成绩。
这听起来像是一个好消息,但对评估来说,反而意味着麻烦。
一张试卷如果大家都能考接近满分,就很难继续判断谁更强、强在哪里。它仍然可以证明模型已经具备某些能力,却不再适合衡量新的进步。
AI行业需要一张更难、也更不容易被“糊弄过去”的卷子。
2024年,陈文虎和团队推出了MMLU-Pro。
MMLU-Pro重新改造了这张考卷,而非简单把题库扩大。
它包含12032道题,覆盖数学、物理、化学、法律、工程、心理学、健康等14个领域。相比原版MMLU,它把选项从4个扩展到10个,降低模型靠猜测蒙对的概率;同时加入更多偏推理的问题,清理掉原题库中相对简单、存在歧义或者区分度不足的题目。
效果很直接。
论文结果显示,模型在MMLU-Pro上的准确率相比原版MMLU下降了16%到33%。同一模型在24种不同提示词风格下测试时,成绩波动也从原MMLU的4%到5%,下降到约2%。
也就是说,这张新卷子不仅更难,也更稳定。
它让那些在旧考卷上看起来都很优秀的模型,重新被拉开了差距。模型到底是真会推理,还是只是更擅长应付旧题,也因此更容易被看出来。
好用的基准评测
MMLU-Pro很快被行业拿去用了。
MMLU-Pro随后进入NeurIPS2024数据集与基准评测赛道,也被EleutherAI的语言模型评测框架lm-evaluation-harness集成。对开源模型社区来说,这意味着它不再只是一篇论文里的数据集,而是进入了常用评测工具链。
很多模型发布时,开始报告MMLU-Pro分数。HuggingFace上的一些排行榜,也把它纳入评估体系。
如果说MMLU-Pro解决的是语言模型评估里的“旧考卷失灵”,那么MMMU则把陈文虎和TIGERLab推到了多模态评测的中心。
多模态模型的问题更复杂。
语言模型答题,主要处理文字。多模态模型则要同时处理图片、图表、示意图、地图、表格、乐谱、化学结构等不同形式的信息。它不只是要读懂题干,还要真正看懂图像里的内容,并把视觉信息、文本信息和学科知识放在一起推理。
MMMU基准评测包含1.15万道多模态问题,来自大学考试、测验和教材,覆盖艺术与设计、商业、科学、健康与医学、人文社科、技术与工程六大领域,进一步细分为30个学科和183个子领域。
这些题目不是简单问模型“图里有什么”,它要求模型像学生做专业题一样,把图像信息和学科知识结合起来。
MMMU发布时,研究团队测试了14个开源多模态模型,以及GPT-4V、GeminiUltra等代表性闭源模型。即便是当时最强的闭源模型,GPT-4V和GeminiUltra也只达到56%和59%的准确率。
这组数字说明,多模态模型看起来进步很快,但在真正需要专业理解和推理的问题上,仍然有大量空间。
后来,陈文虎团队又推出了MMMU-Pro,进一步堵住模型绕过视觉信息的空间。它过滤掉只靠文本模型也能回答的问题,扩展候选项,并引入vision-only设置,把问题嵌入图像中,要求模型同时完成视觉读取和文本理解。
简单说,就是不让模型“只看文字猜答案”。
这类工作听起来颇有点琐碎之感,但它们很关键。因为多模态模型未来要进入医疗、教育、科研、设计、工程等场景,仅仅能描述图片是不够的。它必须能判断、推理、解释,也必须能在复杂视觉信息中找到真正有用的部分。
“考卷”背后的人
陈文虎后来做MMLU-Pro和MMMU,来自于他一直以来的研究方向。

他的研究兴趣本来就与复杂信息理解、知识问答和推理有关。
他本科毕业于华中科技大学,之后到德国亚琛工业大学攻读硕士,再到加州大学圣巴巴拉分校获得计算机科学博士学位。博士期间,他已经开始围绕复杂问答、表格推理、知识证据定位等方向做研究。
这类任务有一个共同点:答案往往不在单一文本里。
它可能藏在一张表格里,也可能需要结合一段文字和一张图片,还可能需要模型先检索信息,再整合、计算和推理。模型不能只会复述已有知识。
陈文虎参与过的HybridQA、TabFact、ProgramofThoughts、MAmmoTH等项目,都和这条线有关。
这也解释了他为什么会对模型评估里的漏洞敏感。
好的基准评测不是简单把题目搞得越来越难,而是要预判模型最容易在哪里“蒙对题”“看起来会”。
模型可能记住了题库,也可以靠选项猜答案,还可能用文字绕过视觉信息……好的评估得把这些漏洞补好。
博士毕业后,陈文虎进入谷歌研究院,随后在2021年至2025年参与谷歌DeepMind的Gemini多模态模型和评估工作。这段经历也很重要。长期接触前沿模型研发,让他更清楚模型能力是如何增长的,也更容易看见评估中可能存在的偏差和盲区。
2022年秋季,陈文虎加入滑铁卢大学计算机科学学院,担任助理教授。同年,他入选CanadaCIFARAIChair。之后,他创办“老虎实验室(也就是虎头帮)”,继续围绕基础模型、多模态能力和基准评测展开研究。

虎头帮并不只是做基准评测,也在做模型和系统研究。
在视频方向上,UniVideo试图把视频理解、生成和编辑放进同一个框架,让模型不只是生成一段画面,也能理解内容、响应指令并完成修改。Vamba瞄准长视频理解,解决一小时级别视频带来的显存、计算和训练效率问题。与Meta生成式AI团队合作的MoCha,则把重点放在说话虚拟角色生成上,通过语音和文字描述生成高质量人物视频。
一个从来不做题的出题人是不可能出好题的。自己下场做模型,反过来也让他们更适合做评估。
因为真正好的评估,往往来自对模型能力边界的理解。只有知道模型是怎么做出来的,知道它在真实任务里会遇到什么问题,才更容易设计出能测出差距、也能暴露问题的题目。
如今,陈文虎进入Meta超级智能实验室,工作继续集中在多模态预训练数据和评估,并服务于Meta基础模型。
AI行业并不缺少被看见的人。AI行业里,聚光灯通常会落在创业者、明星研究员和大模型公司的负责人身上。新产品发布、融资消息、开源模型和团队调整,往往最容易吸引外界关注,也让这些名字更容易进入公众视野。
但今天的AI领域,华人人才的参与已经远不止这些最显眼的位置。