今年以来,美国 AI 三巨头纷纷给自家模型产品贴上了一些“科幻”标签。
OpenAI 说,ChatGPT 学会了“做梦”;Anthropic 要给 Claude 配一个内置的“个人 Wiki”;Google 则宣称,让 Gemini“原生自带你十年的记忆”。
三种说法,看上去关系不大,其实是在竞争同一样东西——Context。
早期,Context 只是个不起眼的技术参数,衡量模型一次能读进多少字符。如今,Context 的含义正在拓宽:它是用户资产,是工具权限,也是任务进行到哪一步的实时状态,更是AI 究竟有多了解你。
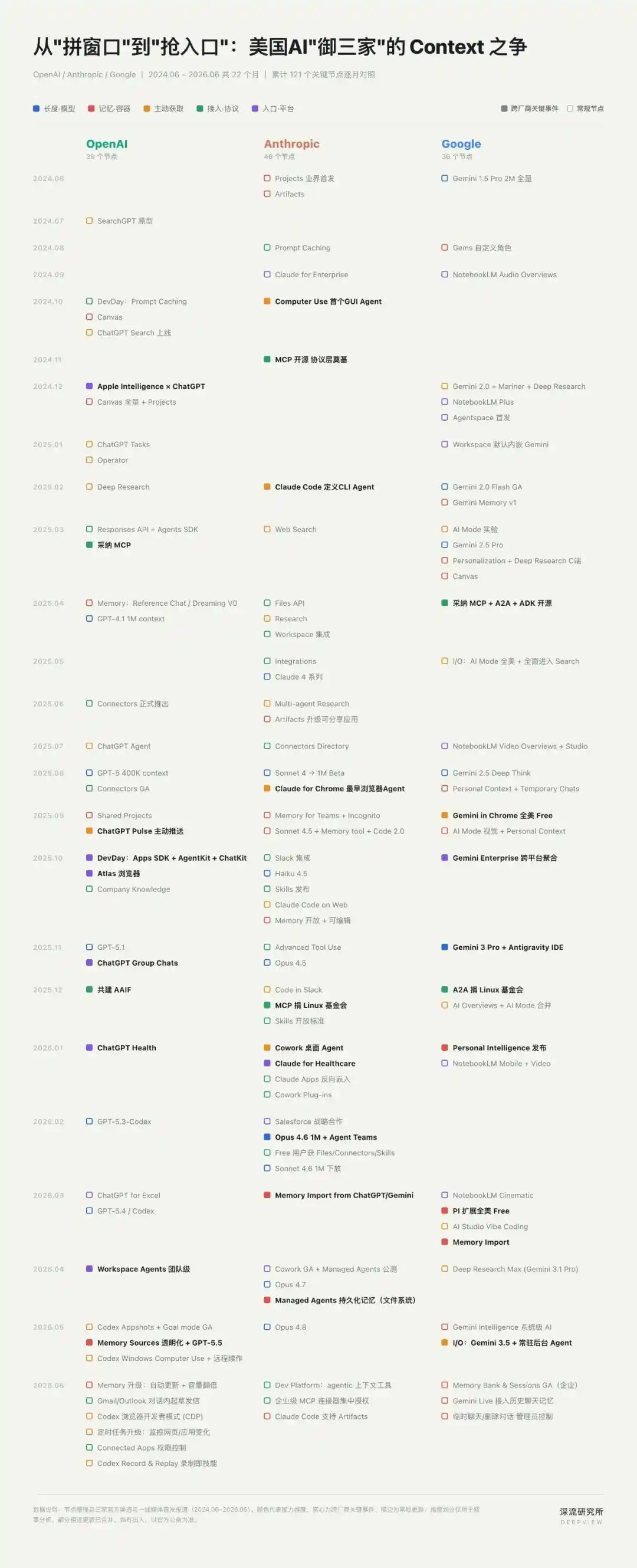
据「深流研究所」统计,今年以来,OpenAI、Anthropic、Google 围绕 Context 已发布 40 余项重要产品和功能更新——平均每三四天,就有一项新能力被推向市场。
从长上下文窗口,到跨会话 Memory,再到浏览器、桌面和 GUI 操作能力,过去两年 AI 产品最重要的变化,几乎都围绕 Context 展开。
一场关于“Context”的战争已经打响,这也在悄然重构 AI 时代的护城河。
1、从长窗口到真实环境,Context 边界的三次跃迁
Context 最早的竞争,发生在“文本长度”上。
Chatbot 时代,Context 主要意味着模型一次能读进多少信息。窗口越长,模型越能处理论文、代码库,甚至完整项目文档。于是,OpenAI、Anthropic、Google 掀起了一场上下文窗口的军备竞赛。
2023 年 5 月,Anthropic 率先把 Claude 的上下文窗口从 9K 拉到 100K,约等于 7.5 万字,首次让“上传一整本书”成为现实。2023 年 11 月,OpenAI 用 GPT-4 Turbo 的 128K 跟进。三个月后,Google 又用 Gemini 1.5 Pro 把窗口推到百万级。
不到一年,Context 从十万级跃迁到百万级。
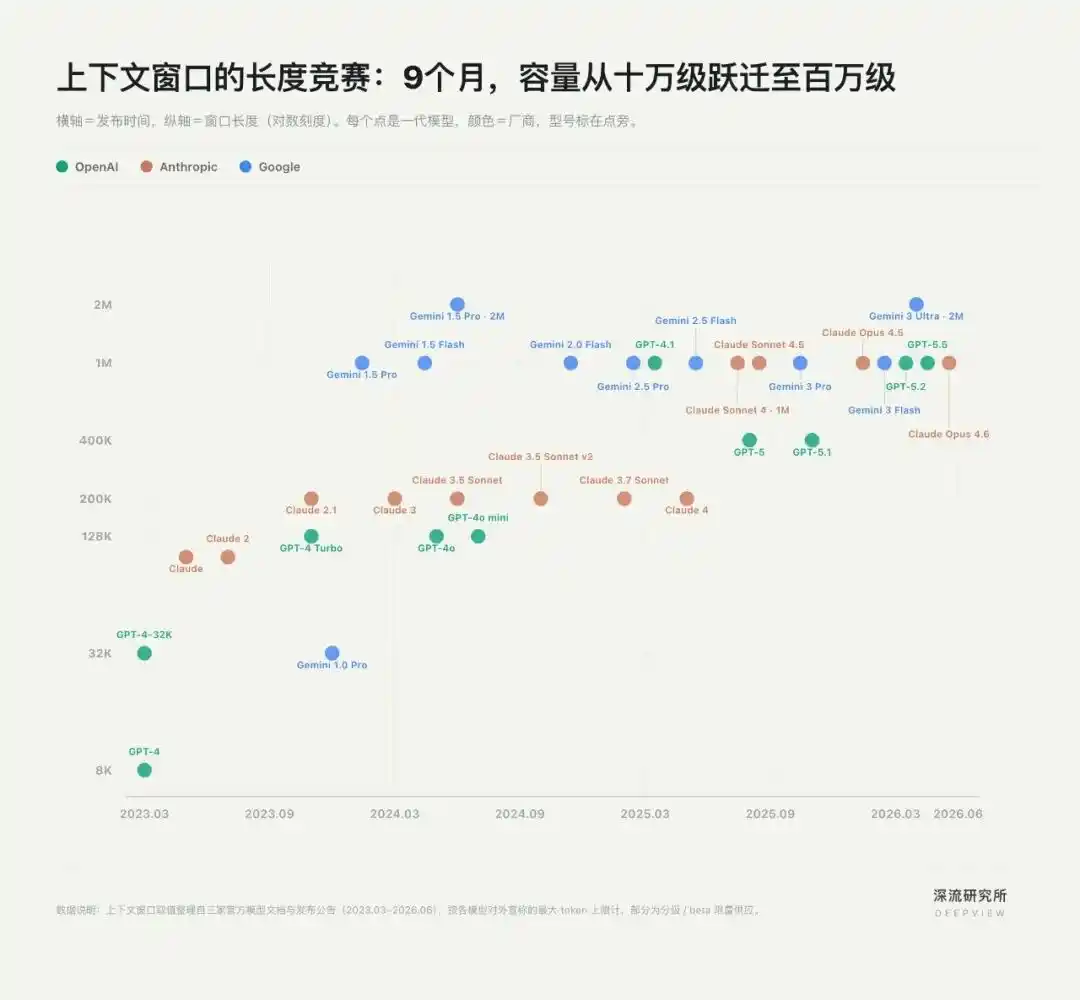
长窗口解决了 AI 的“吞吐量”问题,但这场竞赛很快暴露出局限:模型能看到更多信息,并不意味着它就能更好地理解任务。
尤其当 AI 产品从 Chatbot 走向 Agent,Context 的边界开始变化。它不再只是一次对话里的输入文本,而是任务循环中持续积累、动态更新的状态流。
竞争焦点也随之转移:从模型“一次能知道多少”,转向模型“长期能记住什么”。Memory 成为这一阶段典型的产品形态。
2024 年初,OpenAI 率先为 ChatGPT 引入跨会话记忆,让模型记住用户的偏好、背景与长期需求。随后,Anthropic 与 Google 也相继补齐 Claude、Gemini 的记忆能力。
Context 开始拥有时间维度。AI 不再只处理当前输入,也开始尝试在用户今天、上周、上个月的交互之间建立连续性。只有具备长期 Context 的 AI,才可能把离散的交互串成持续关系。
然而,Memory 回答的是“过去发生了什么”,还没有触及另一个更关键的问题:现在正在发生什么?
真正的分水岭出现在 2025 年下半年。
这一年 8 月开始,三家公司几乎同时把 Context 的战线推向浏览器:Anthropic 发布 Claude for Chrome,Google 将 Gemini 嵌入 Chrome,OpenAI 则推出独立 AI 浏览器 ChatGPT Atlas。
浏览器是天然的 Context 富矿。网页内容、搜索意图、登录状态、表单、历史记录、标签页,以及用户正在执行的任务,都沉淀在浏览器里。更重要的是,这里的 Context 更实时、更连续,也更接近真实任务现场。
之前,AI 获取 Context 的方式,本质上仍然是等待用户把材料送进来:上传文件、输入指令、授权记忆、连接数据源。
进入浏览器之后,逻辑变了。AI 开始进入用户的工作环境,观察页面状态,理解任务进度,捕捉操作意图,并在真实界面中执行下一步。
这是 Context 边界的第三次跃迁:它从模型侧输入的静态数据,变成了 Agent 在 GUI、网页和系统环境中捕捉到的动态状态。
长窗口决定模型一次能装进多少信息;Memory 决定模型能否跨时间理解用户;浏览器、桌面产品和 GUI 能力,则决定模型能否进入真实任务现场。
三者连在一起,构成了过去两年 AI 产品竞争的主线:Context 不再只是模型能力问题,而逐渐变成产品入口问题、用户关系问题,以及资产沉淀问题。
2、Context 成为新战场,美国 AI “御三家”的三种路径
当 Context 从模型参数变成用户资产,竞争的核心就变成了:谁能更稳定地获得、组织和调用 Context。
围绕这一点,OpenAI、Anthropic、Google 走出了三条差异化路径。
ChatGPT 是 OpenAI 最核心的 Context 来源。
用户在一次次对话中留下的记忆、偏好、历史任务和工具调用记录,逐渐沉淀到同一个 ChatGPT 账户之下。
这个账户不同于传统互联网账户。传统账户记录的是登录状态、订阅关系和支付信息;ChatGPT 账户记录的,则是用户“被 AI 理解过的历史”。
这是一种 AI 原生的用户资产。它的价值不只体现在回答更个性化,也体现在降低冷启动成本、延续任务状态,并在不同产品场景中复用同一套用户理解。
对 OpenAI 来说,由于缺少 Google 那样的原生数据生态,它必须让用户在 ChatGPT 体系内持续生成新的 Context。
因此,OpenAI 过去两年的产品动作,一直在不断扩大 ChatGPT 账户能够覆盖的任务半径——Apps SDK 让第三方应用进入 ChatGPT,Atlas 把浏览器纳入 ChatGPT,最新融合的 Codex 则把编程任务带入同一个工作流。
OpenAI 的特殊路径在于,它不是先掌握入口,再把 AI 接进去;而是以 ChatGPT 为原点,反向把应用、浏览器、编程等场景拉回同一个账户体系。
ChatGPT 因此不再只是对话入口,而是一个汇聚、调用、更新 Context 的中枢。
相比之下,Anthropic 既缺少 C 端入口,也没有大规模存量用户数据。
它的路径,是切入 Coding、Agent 这类高价值垂直场景,并在这些场景中强化 Claude 主动获取 Context 的能力。
对 Claude 来说,Context 不是用户输入的一段文字,而是任务现场里动态变化的环境:代码库、文件系统、终端输出、浏览器页面、数据库、项目文档,以及每一步执行后的反馈。
因此,Anthropic 更强调 Context 获取的主动性。模型不应只等待用户输入,也应该在任务执行过程中主动进入环境、读取状态、获得反馈。
2024 年 10 月,Anthropic 推出 Computer Use,让 Claude 可以根据屏幕截图移动鼠标、点击按钮、输入文本。
按照官方说法,Claude 3.5 Sonnet 是首个公开提供计算机使用能力的前沿 AI 模型。
这意味着,当 Context 存在于网页、表单、后台系统和本地软件界面中,而不是结构化 API 里时,Claude 也可以通过 GUI 进入环境、观察状态并执行操作。
一个月后,Anthropic 发布 MCP。这个连接 AI 助手与外部工具、数据源的开放协议,官方定义是把 AI 助手连接到“数据所在的系统”,包括内容库、业务工具和开发环境。
它的价值在于,让 Claude 不再依赖用户复制粘贴,而是可以通过标准方式接入外部工具和数据源。
这两类能力,对应的是 Anthropic 获取 Context 的两条路径:
computer Use 通过 GUI 进入界面,MCP 通过协议连接系统。一个进入任务现场,一个打通外部工具,共同让 Claude 获得动态 Context。
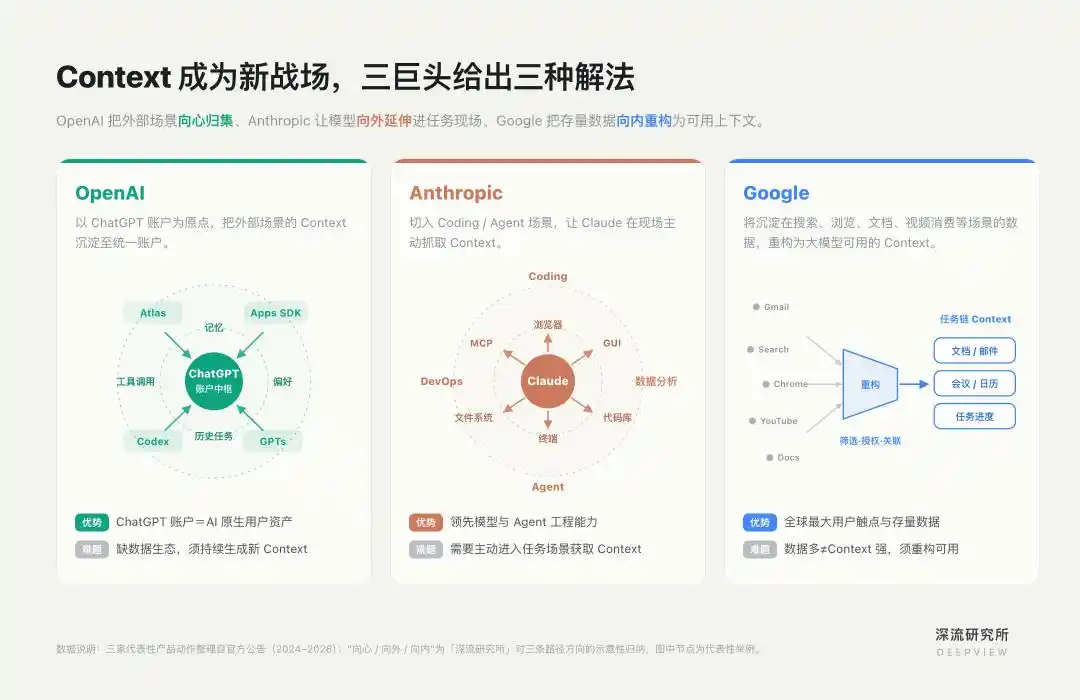
再看 Google。外界常说,Google 是拥有 Context 最多的公司之一。它不缺入口,也不缺数据。Chrome、Gmail、YouTube、Search 等产品,构成了全球范围内最大的用户触点之一。
但从 AI 的视角看,数据多并不等于 Context 强。
Google 过去积累的是搜索、浏览、邮件、文档、位置、视频消费等数据,主要服务于搜索排序、广告投放、内容推荐和办公协作。它们本质上是系统运作所需的行为信号。
而 Agent 需要的是可被模型理解、推理和调用的任务背景。
只有当模型能判断哪些信息与当前任务有关、哪些已经过时、哪些可以被调用,以及这些信息之间如何关联,数据才真正变成 Context。
Google 面临的不是简单“接入数据”,而是一场数据重构。它需要把分散在不同产品、服务于不同系统目标的旧数据,重新筛选、关联、授权,并转化为 Gemini 可用的个人上下文。
这个工程的难度,并不比 OpenAI 重新沉淀 Context、Anthropic 进入任务现场更低。
过去两年,Google 的产品动作不是另起炉灶,而是沿着既有阵地向内改造。这条路径的核心,是把碎片化数据组织成任务链。
2024 年 5 月,Gemini 1.5 Pro 进入 Workspace 侧边栏,让模型先在 Gmail、Docs、Drive 等工作场景中调用当前上下文。
2025 年 7 月,Gemini app 开始连接 Gmail、Drive、Calendar 等工具,把 Context 从单个应用扩展到跨应用任务。
2026 年 1 月,Personal Intelligence 推出测试版,进一步把 Gmail、Photos 等个人数据纳入 Gemini 的个性化背景。
Google 的 Context 战略并不是“数据多,所以天然领先”。
它真正要完成的,是一场数据可用化工程:把过往沉淀的、服务于搜索、广告和推荐等系统目标的行为数据,转化为 AI 时代可理解、可授权、可行动的 Context。
3、从“网络规模”到“个体纵深”,AI 时代的护城河变了
过去两年,OpenAI、Anthropic、Google 都在加速沉淀和挖掘 Context,并围绕它构建获取、组织和调用能力,试图形成新的竞争壁垒。
但一个看似矛盾的变化也在同步发生:今年以来,三家公司不约而同地让 Memory 变得透明、可解释,甚至可迁移。
2026 年 3 月,Anthropic 与 Google 先后推出 Memory Import,支持用户在 ChatGPT、Gemini、Claude 之间迁移记忆。
随后,OpenAI 通过 Memory Sources,让用户看到一条个性化回答背后调用了哪些记忆、历史聊天或外部数据源。
如果 Context 是 AI 时代最重要的资产,为什么平台反而开始开放它的权限?
答案在于,Memory Import 真正开放的,只是表层 Context:用户偏好、历史记忆摘要、对话历史的压缩版本。
这些信息高度结构化,也容易被自然语言描述。迁移它们,技术门槛并不高。
真正难以迁移的,是另一类 Context:任务状态、工具权限、企业系统接入、执行现场的实时反馈。
这些 Context 深度嵌在产品和系统环境之中,无法靠一段提示词完整搬走。
这也说明,AI 时代的竞争逻辑,正不同于互联网时代。
互联网的基本形态是网络。它把人、内容、商品、服务和信息连接成节点。节点越多、连接越密,产品越有价值。因此,互联网时代最强的护城河是网络效应,价值来自更多人在用。
AI 的基本形态,更接近一种新的计算机,或者说新的信息处理系统。
它的第一性价值不是连接更多人,而是理解信息、处理任务、调用工具并完成动作。一个 AI 即使只服务一个用户,也可能创造巨大价值。
因此,AI 时代的护城河,正在“网络规模”的基础上转向“个体纵深”。这种“个体纵深”的壁垒,主要来自三个层面:
第一,是 Context 的复利。AI 每完成一次任务,都会更了解用户的表达习惯、判断标准、资料来源和工作流程。下一次执行时,冷启动成本就会更低。
第二,是权限与工具链的嵌入。当用户把邮箱、文档、代码库等授权给 AI,AI 就不再只是一个可替换的问答工具,而是进入了真实的任务现场。
第三,是信任关系的形成。越复杂、越高价值的任务,用户越不会轻易交给一个陌生 AI。只有长期理解自己、知道边界、能延续上下文的 AI,才可能被允许执行下一步。
如果说互联网产品争夺的是注意力入口,那么 AI 产品争夺的就是任务入口。
一旦一个 AI 持续进入用户工作流、积累上下文并获得执行权限,迁移成本就不只是换一个应用,而是重新建立一套被理解、被授权、被信任的任务关系。
国内产品的变化,也可以放在这个逻辑下理解。
以腾讯为例,它在互联网时代积累了关系链、内容、服务生态和高频入口;到了 AI 时代,这些资产的价值,正在于能否被重新组织为 Agent 可理解、可调用、可执行的 Context。
无论是 WorkBuddy 接入文档、会议、企业微信等工作场景,还是微信“小微”尝试在微信生态调用小程序和服务,本质上都是把原本服务于人的内容、关系和流程,转化为 AI 可以进入的任务环境。
正如腾讯首席 AI 科学家姚顺雨所判断:Context 看似是数据资产,本质上却是产品能力、工程能力和组织协同能力的综合体现。
互联网时代,护城河看的是规模。AI 时代,护城河更应该看转化效率:
谁能把存量生态更快转化为 AI 的工作环境,谁能让 AI 在一次次任务中积累更深的用户理解,谁就更可能建立新的壁垒。
这也是 Context 之战真正值得关注的地方。
本文来自微信公众号“深流研究所”,作者:绛枫






