Agentic Design Patterns:一本让我重新理解"Agent 到底是什么"的书
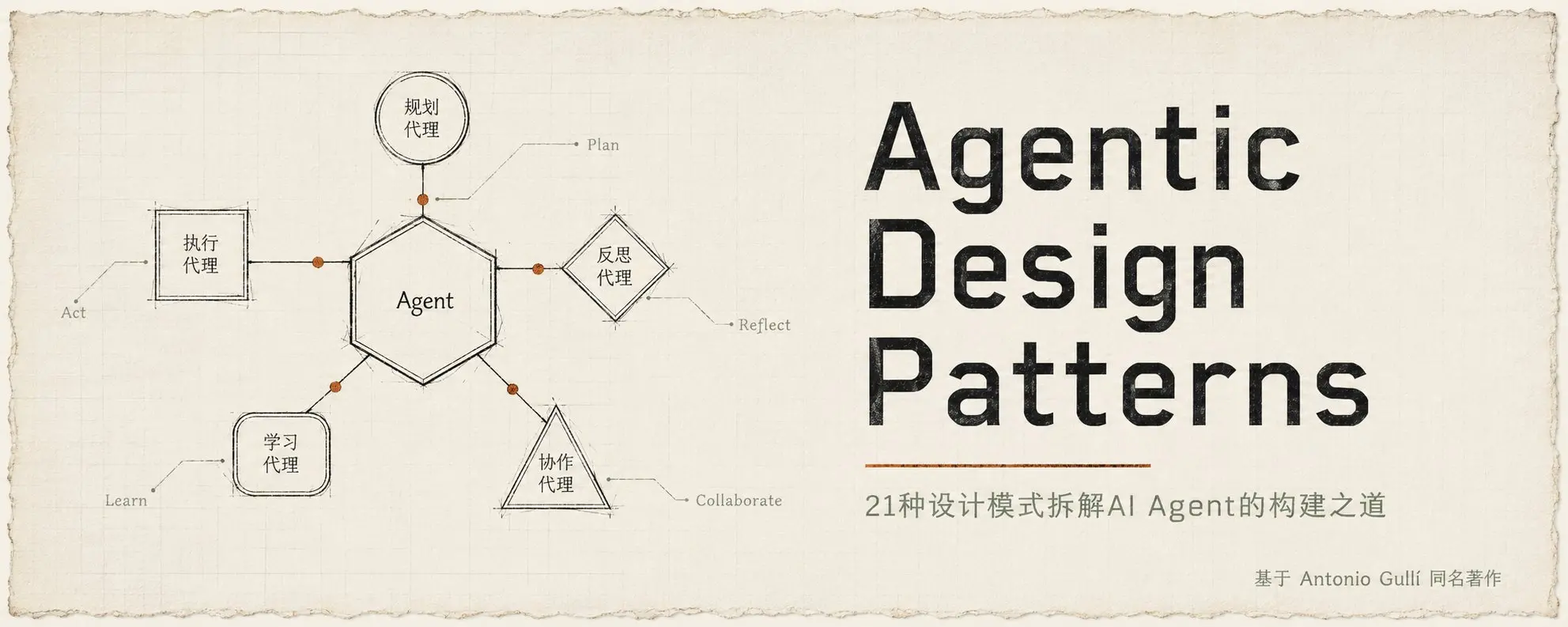
《Agentic Design Patterns》一书由Google工程总监Antonio Gullí撰写,系统性地将AI Agent开发拆解为21种设计模式。文章作者阅读后,对Agent的本质有了更深刻的理解。
书中将Agent划分为四个等级:Level 0仅为裸LLM,不具备行动能力,并非真正的Agent;Level 1能自主调用工具完成任务;Level 2具备战略规划与上下文工程能力,能对信息进行裁剪和降噪,并进行自我反思;Level 3则是多智能体协作,像团队一样分工合作。
文章重点阐述了几个核心概念:
1. **上下文工程**:超越提示词工程,系统地为Agent构建包括系统指令、外部数据、隐式信息和反馈回路在内的四层上下文环境,以提升其准确性和效率。
2. **反思模式**:采用“生产者-批评者”双智能体模式,让一个智能体负责创作,另一个负责审查和提出修改意见,通过迭代循环显著提升输出质量,但需设置合理的迭代次数以控制成本。
3. **多智能体协作**:并非越复杂越好,应根据任务复杂度选择合适的通信拓扑结构(如独立执行、对等网络、中心调度等)。通常,一个达到Level 2的单智能体加上反思机制已能应对大多数场景。
4. **记忆三层模型**:分为会话层(临时对话上下文)、状态层(任务进行中的临时数据)和持久层(跨会话的长期记忆),需要设计相应的存储与检索策略。
书末还提出了对未来Agent发展的五个假设,其中最颠覆的是“变形多智能体”:系统能根据最终目标自动创建、调整、重组智能体团队,实现完全自主的任务规划与执行。
作者建议读者可立即实践三点:为现有智能体增加一个“批评者”角色以进行审查;开始实践系统的上下文工程而非仅关注提示词;优先将单智能体能力提升至Level 2,而非盲目追求多智能体系统。
这本书的价值在于,它将许多开发者在实践中摸索的经验系统化、模式化,为AI Agent开发提供了一份清晰的“地图”。
链捕手05/25 04:42