Is Moore's Law saved?
IBM unveiled the world's first 0.7 nanometer chip process node, integrating nearly 100 billion transistors on a chip the size of a fingernail, achieving a density double that of 2nm chips.
Previously, TSMC's most advanced process was 2nm, which had been difficult to advance beyond for years.
NVIDIA CEO Jensen Huang had repeatedly declared Moore's Law dead, but now there is finally a turning point.

0.7 nanometers, or 7 angstroms, marks the first time human-made transistors have broken through the 1 nanometer threshold, approaching the scale of individual atoms (0.1-0.5 nanometers).
Compared to the 2nm process, it can deliver either a 50% performance improvement or a 70% increase in power efficiency; one or the other.
NanoStack Architecture Arrives
The core of this breakthrough is IBM's "NanoStack" architecture, the industry's first 3D vertically stacked transistor design based on nanosheets.
To understand NanoStack, one must first review the path chip architecture has taken in recent years.
In the 7nm and 10nm era, the mainstream solution was FinFET (Fin Field-Effect Transistor) with the gate wrapping around the channel on three sides to control current. Below 5nm, FinFET's leakage issues became increasingly severe and unsustainable.
In 2017, IBM introduced the Gate-All-Around (GAA) nanosheet technology, where the gate completely surrounds the horizontally stacked nanosheet channel on all four sides, significantly enhancing electrostatic control. This became the technical foundation for its 2nm chip and was subsequently adopted by mainstream manufacturers like TSMC and Samsung.
At the end of 2021, IBM and Samsung jointly announced the VTFET (Vertical-Transport Field-Effect Transistor), which changed the current flow direction from horizontal to vertical. Simulation data showed it could either double performance or reduce power consumption by 85% compared to a similarly sized FinFET solution.
This NanoStack is a further extension of the above roadmap.
Its method is:
Take two wafers with nanosheet transistors, invert one and place it on top of the other, bonding them via an ultrathin dielectric bonding layer to form a vertically interconnected 3D structure. Each layer can use different material combinations, allowing n-type and p-type transistors to be independently optimized without interference.
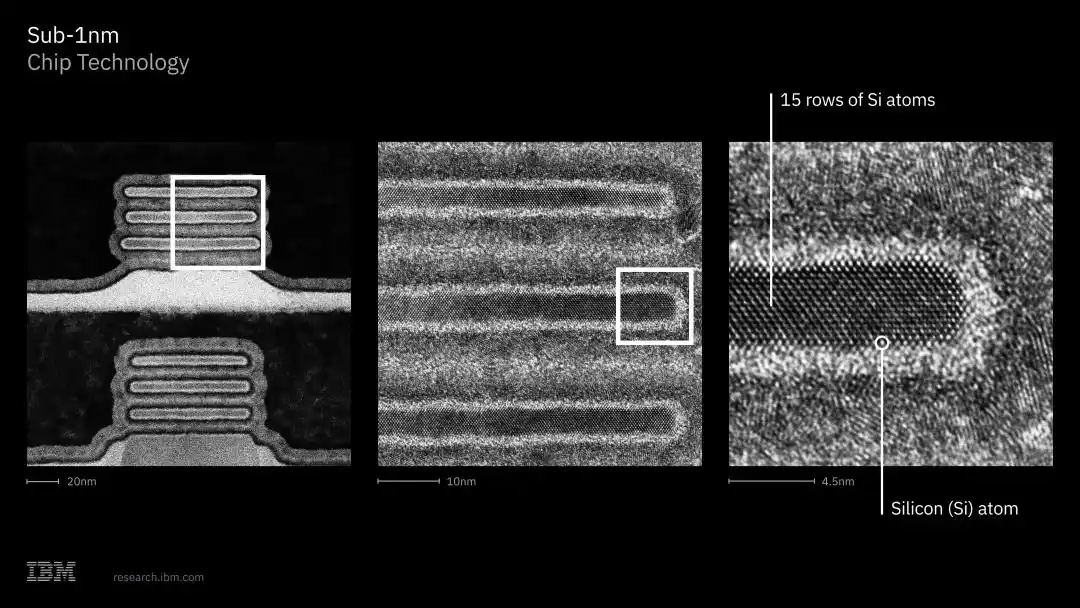
IBM has already completed validation in the lab, demonstrating CMOS integration, dual-channel engineering capabilities, and a fully functional CMOS inverter with switching performance meeting expectations, confirming that this technology can be manufactured and support real computation.
At the VLSI 2026 symposium, IBM further showcased NanoStack's performance on SRAM: a 40% area reduction. SRAM is a core component of on-chip cache, which has long been extremely difficult to scale down. This progress is particularly crucial for the high-bandwidth data pathways required by AI chips.
"Nobody Wants to Pay the Electricity Bill"
Huiming Bu, vice president of chip research at IBM Research, stated: Everyone wants higher performance, but nobody wants to pay the electricity bill.
This is the reality facing the current AI computing power race. The energy consumption of AI chips has evolved from a technical issue to an infrastructure problem, with some data center projects experiencing construction delays due to insufficient power supply.
The 70% power efficiency improvement offered by the 0.7nm technology directly addresses this demand.
However, IBM itself no longer manufactures or sells chips. It develops manufacturing process technologies at its research center in Albany, New York, and then licenses them to chip manufacturers.
Past licensees have included Samsung and the newly formed Japanese semiconductor company Rapidus. Huiming Bu declined to disclose potential customers for the 0.7nm technology.
Regarding competing solutions, the Belgian research institute Imec is advancing another 3D architecture scheme, building transistor structures through layer-by-layer stacking, which has attracted attention from several chip manufacturers.
For mass production, IBM's given timeline is: NanoStack technology could achieve mass production within the next five years at the earliest.
IBM's semiconductor roadmap predicts that with the NanoStack architecture, chip scaling can continue for at least another decade.

References:
[1]https://newsroom.ibm.com/2026-06-25-ibm-debuts-worlds-first-sub-1-nanometer-chip-technology
This article is from the WeChat public account "QbitAI", author: Meng Chen






