Every day, about 500,000 hours of human labor are utilized for free by Google. And the people contributing this labor are simply trying to log into their online banking.
reCAPTCHA is the most successful covert data operation in internet history. At its peak, 200 million people completed the verification daily. But almost no one realized what each click truly meant.
Google's self-driving car company, Waymo, now has a market valuation of $45 billion. A significant portion of its core training data was provided for free by you while accessing various websites.
Here is the full story:
The Origin: A Clever Concept
In 2000, spam bots were destroying the internet. Forums were flooded, inboxes were clogged, and websites desperately needed a way to distinguish humans from machines.
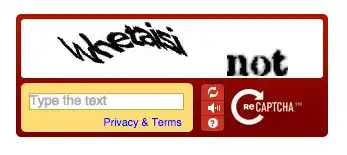
Professor Luis von Ahn from Carnegie Mellon University solved this problem. He invented the CAPTCHA: a distorted text that only humans could read, which bots couldn't pass.
But von Ahn saw more. Millions of people were expending effort on these challenges. What if this effort could do two things at once?
In 2007, he launched reCAPTCHA. Its brilliance lay in this: it no longer showed random gibberish, but two words. One was known to the system, the other was a real scanned word from books that computers couldn't yet recognize. Your response helped digitize these books.
These books came from The New York Times archives and Google Books, numbering up to 130 million volumes.
You thought you were just logging into a regular website, but you were actually doing OCR (Optical Character Recognition) for the world's largest digital library.
In 2009, Google officially acquired reCAPTCHA.
Later, Google Changed the Game
The era of "distorted text" ended around 2012.
Google faced a new challenge: its Street View cars had photographed every road globally, but the photos were just raw data. For AI to be useful, it needed to understand what it saw: road signs, crosswalks, traffic lights, storefronts.
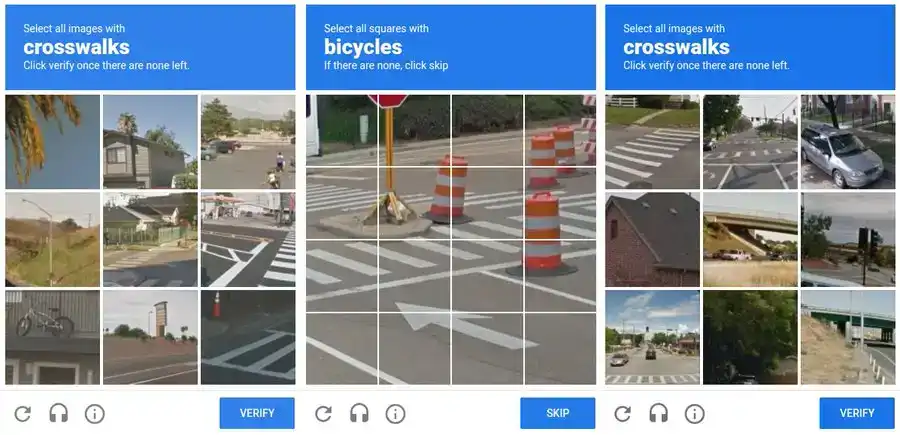
So Google redesigned reCAPTCHA v2. Instead of distorted text, there were grids of photos. "Click all squares with traffic lights." "Select every crosswalk." "Identify the storefront."
These images came directly from Google Street View. Your clicks were the labels.
Every selection was telling Google's computer vision model: this cluster of pixels is a traffic light, that shape is a crosswalk. You weren't passing a test; you were building a dataset.
A Scale Beyond Imagination
At its peak, 200 million reCAPTCHAs were solved daily. Each challenge took about 10 seconds, meaning 2 billion seconds of human labor were generated every day. That's: 500,000 hours per day.
Paid data annotation costs roughly $10 to $50 per hour. Using the lowest estimate: the value of labor extracted for free daily was a staggering $5 million.
And reCAPTCHA isn't just on one app. It's embedded in every bank, every government portal, every e-commerce site. You had no choice: want to log into your account? Label this dataset first. Google never asked for your consent, never paid a cent in wages, and never even told you about it.
What Did All This Create?
This data fed directly into two products:
- Google Maps: The world's most used navigation tool. Its ability to recognize road signs, stores, and urban geography is partly thanks to billions of human annotations made while logging into websites.
- Waymo: Google's self-driving project. To navigate, autonomous vehicles need near-perfect recognition of thousands of visual patterns.
The ground truth training data for that recognition work was precisely what millions of people labeled unknowingly through reCAPTCHA. Waymo completed over 4 million paid rides in 2024 and is valued at $45 billion. Its foundation was laid by "unpaid internet citizens" who just wanted to check their email.
Why Can't Anyone Replicate This Model?
Data annotation is extremely expensive. Companies like Scale AI, Appen, and Labelbox exist to solve this problem, employing hundreds of thousands of workers, sometimes for less than $1 per hour.
Google's solution was different: they made annotation mandatory. No payment, no consent required; it's the "ticket" to enter every corner of the internet. The result: billions of labeled images, global coverage, all-weather conditions, every city in the world. No annotation company could achieve this. The internet itself is the factory, and every netizen is an unsigned contract worker.

You Are Still Participating Today
reCAPTCHA v3, launched in 2018, doesn't even show a challenge. It observes how you move your mouse, your scrolling speed, your dwell time. Your behavioral fingerprint tells it if you're human. This behavioral data also feeds back into Google's AI systems.
You never actively opted in; there was never a checkbox for you to tick. But right now, on most websites you visit, you are still doing it.
The Disturbing Irony
Luis von Ahn's original intention was genius: to turn wasted human effort into useful output. But what Google did with this vision is another matter. They leveraged a security mechanism users had to use, deployed it across the entire web, and harvested the output to build commercial products worth hundreds of billions of dollars. The users gained nothing, and knew nothing.
The deepest irony is this: You spent years proving you were human by doing visual recognition work that AI couldn't yet do. And once AI learned it, human visual annotation was no longer needed.
You proved you were human, only to make yourself replaceable.








