Sưu tầm không bằng sở hữu, đánh dấu không có nghĩa là hiểu.
Những bài viết sâu sắc khiến bạn dậy sóng lúc 2 giờ sáng, những liên kết hai chiều chằng chịt được kéo ra trong Obsidian, những cơ sở dữ liệu được xếp đặt cẩn thận trong Notion, tất cả đều là những "xác ướp kỹ thuật số" nằm im trong phần mềm ghi chú.
Biểu đồ tri thức trông hùng vĩ, nhưng thực ra đã mục nát từ lâu.
Đây là thất bại mang tính hệ thống của cả một thời đại quá tải thông tin.
Karpathy, kỹ sư hiện tại của Anthropic, đồng sáng lập viên cũ của OpenAI, cựu giám đốc AI của Tesla, không thể chịu đựng được nữa, đã ném xuống một quả bom.

Cổng dịch chuyển:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Anh ấy không công bố mô hình mới, không phát hành framework mới, anh ấy chỉ nói: Hãy coi ghi chú của bạn là mã nguồn bất biến, để LLM làm trình biên dịch.
Hai tháng trôi qua, tài liệu này đã gây ra một cuộc di cư âm thầm nhưng dữ dội trong cộng đồng Obsidian, Claude, Cursor.
Một số người đã mở rộng Wiki của họ lên hàng trăm trang, hàng chục vạn từ.
Các plugin tự động hóa bắt đầu xuất hiện. Nhà nghiên cứu học thuật, doanh nhân khởi nghiệp độc lập, người học suốt đời đang chuyển hướng tập thể sang một quan hệ sản xuất tri thức hoàn toàn mới.
Hoàng hôn của RAG, vận chuyển thông tin không cứu được tư tưởng của bạn
Trước khi LLM-WIKI xuất hiện, giải pháp chủ lưu là RAG (Retrieval-Augmented Generation).
Nói đơn giản, là gắn cho mô hình lớn một "người lục lọi": khi bạn hỏi, nó đi tìm trong ghi chú của bạn một vài đoạn trích, rồi ghép lại thành một câu trả lời.
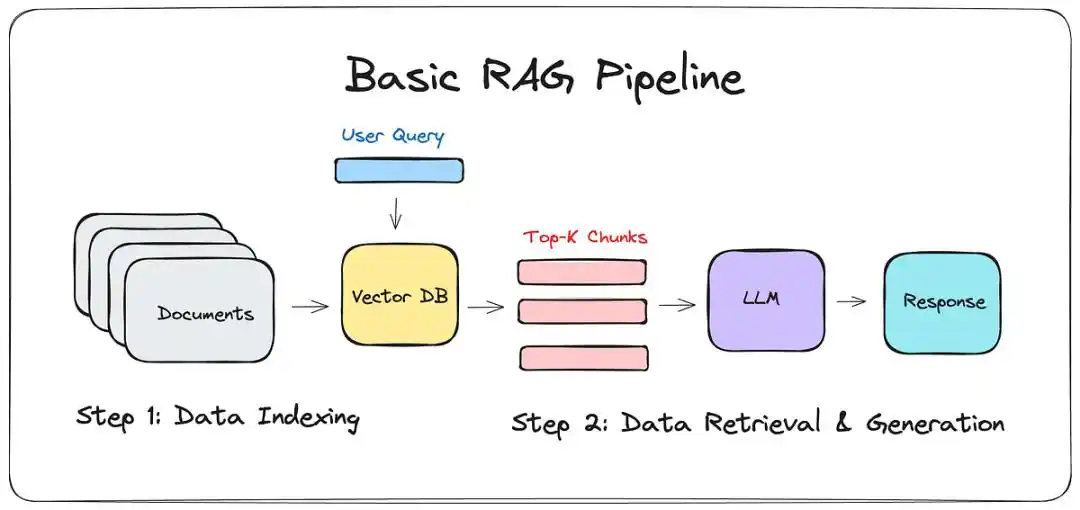
Nghe thì hay, nhưng người dùng qua đều biết cái khoảng cách giữa "mẫu quảng cáo" và "hàng thật nhận được".
Nó chỉ là khuân vác: RAG chỉ xử lý được cục bộ, không thể hiểu toàn cục.
Nó có thể nói cho bạn biết bài ghi chú thứ 5 nhắc đến A, nhưng nó không thể nói cho bạn biết logic cơ bản mà 500 bài ghi chú cùng chỉ ra.
Nó sẽ "phân liệt nhân cách": Nếu nửa năm trước bạn cho rằng A là đúng, nhưng hôm qua lại viết ghi chú phản bác A, RAG thường rơi vào mâu thuẫn tự thân, nhả ra một đống lời vô nghĩa logic hỗn loạn.
Biểu đồ mục nát: Liên kết tri thức bảo trì thủ công, giống như code không có tính năng dọn dẹp tự động. Lâu ngày, liên kết cụt đầu xuất hiện khắp nơi, hiệu quả truy xuất giảm theo cấp số mũ.
Trực giác của Karpathy rất sắc bén: Tìm kiếm và truy xuất là biểu hiện của sự bất lực của con người. Chúng ta cần là "sự đồng thuận", là "cấu trúc", là "chân tướng".
Coi tri thức là mã nguồn, để LLM làm trình biên dịch
Câu trả lời của Karpathy, đến từ một động tác mà lập trình viên ngày nào cũng làm, nhưng chưa bao giờ nghĩ đến áp dụng lên tri thức: biên dịch.
Bạn viết xong một đoạn mã nguồn, không phải mỗi lần chạy chương trình lại đọc lại code một lần.
Bạn biên dịch nó thành một file nhị phân, biên dịch lần này rất tốn công, nhưng sau đó mỗi lần chạy đều nhanh vùn vụt. Chi phí biên dịch, được chia đều cho hàng nghìn lần sử dụng sau.
Tri thức tại sao không thể làm như vậy?
Karpathy nói, hãy coi những ghi chú thô của bạn là mã nguồn không thể sửa đổi, để LLM làm trình biên dịch, để nó một lần "biên dịch" đống tài liệu lộn xộn này thành một Wiki có cấu trúc, liên kết chéo.
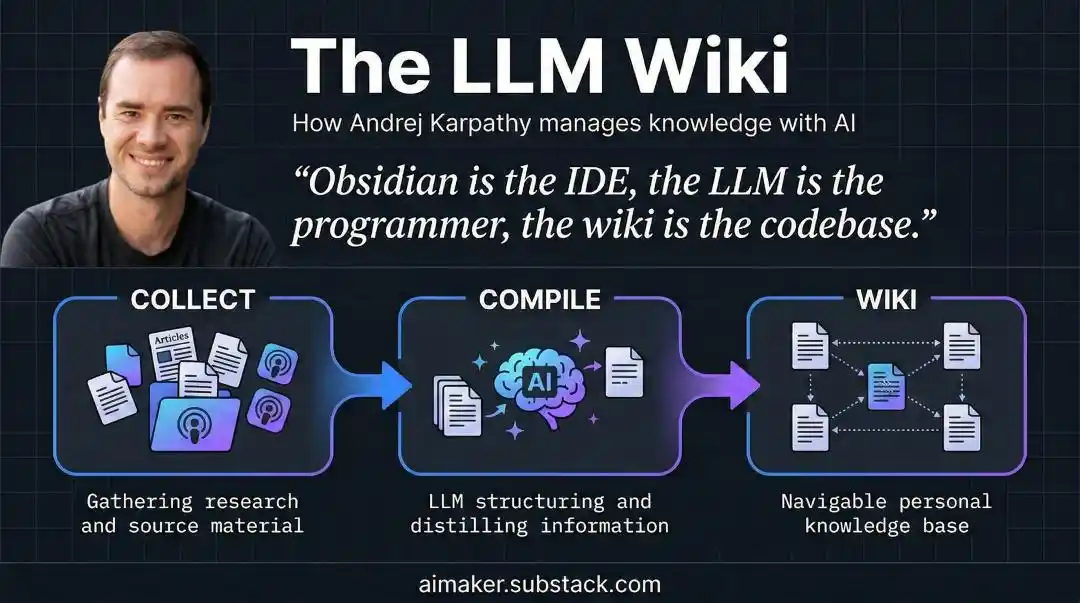
Mỗi lần thêm một tài liệu mới, AI thực hiện một lần dung hợp: cập nhật trang mục liên quan, sửa đổi tổng quan, đánh dấu những chỗ dữ liệu mới và kết luận cũ đánh nhau, thuận tay củng cố hoặc thách thức phán đoán hiện có.
Khác biệt then chốt ở đây: Tri thức được biên dịch một lần, sau đó tiếp tục tươi mới, chứ không phải mỗi lần truy vấn tái xây dựng tạm thời.
Đợi khi bạn đặt câu hỏi, liên kết chéo đã sẵn ở đó rồi, mâu thuẫn đã được đánh dấu rồi, tổng quan đã phản ánh tất cả những gì bạn đã đọc rồi.
Bạn không phải mỗi lần chạy chương trình lại biên dịch lại mã nguồn. Vậy tại sao mỗi lần hỏi, đều phải để AI đọc lại một lần ghi chú của bạn?
Chuyển dịch căn bản của quan hệ sản xuất nhận thức
Trong framework LLM-WIKI của anh ấy, ghi chú không còn là chữ viết chết, mà là "mã nguồn".
Mô hình lớn không còn là phiên dịch viên tra từ điển, mà là "trình biên dịch".
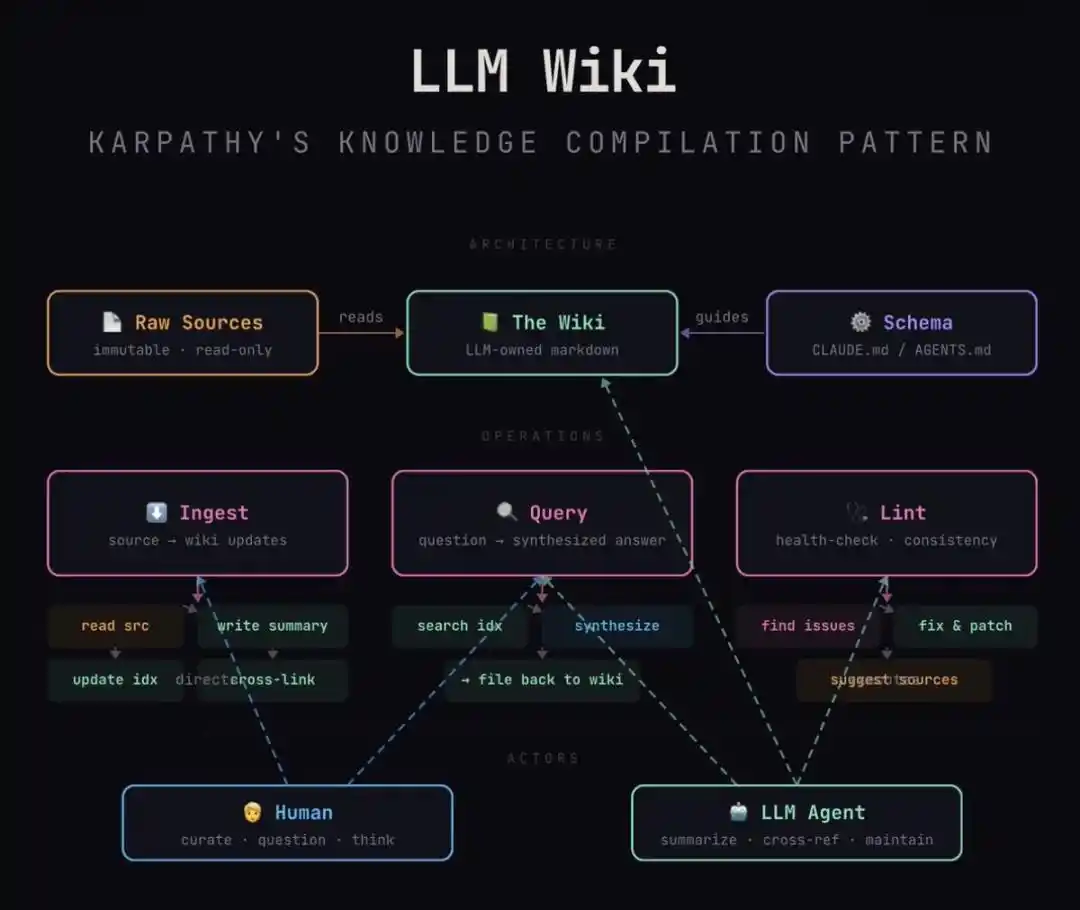
Kiến trúc này thực hiện cực kỳ tinh tế việc tách rời ba tầng:
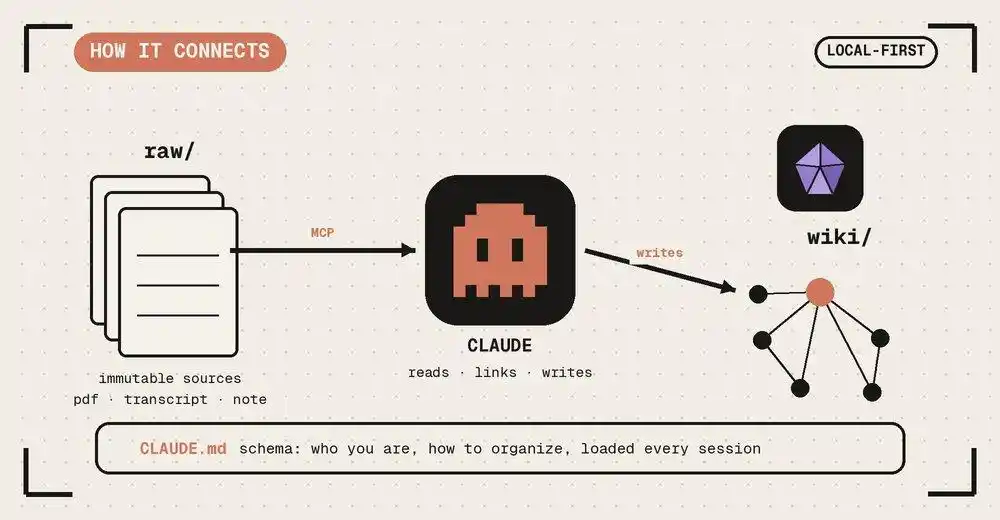
1. Lớp Raw (Nguyên liệu thô): Đây là mỏ cảm hứng thô của bạn. Những suy ngẫm bạn ghi tùy hứng, bài viết cắt ghép, biên bản cuộc họp. Nó là "bất biến", duy trì tính nguyên thủy và cảm giác không sạch sẽ của đầu vào con người.
2. Lớp Schema (Hiến pháp tri thức): Đây là "quân quy" bạn viết cho AI. Ví dụ bạn quy định: Mỗi mục từ nhân vật phải bao gồm "động cơ, hạn chế, thành tựu then chốt"; mỗi ngăn xếp công nghệ phải nói rõ "ưu nhược điểm".
3. Lớp Wiki (Sản phẩm biên dịch): Đây là khu vực do AI toàn quyền bảo trì. Nó căn cứ vào Schema của bạn, biên dịch đống Raw lộn xộn đó thành các trang bách khoa có cấu trúc, liên kết chéo, tự nhất quán logic.
Hàng ngày chỉ ba động tác:
1. Ingest (Hấp thu): Ném một mẩu tin mới vào, AI đọc xong, đi qua cùng bạn những điểm chính, viết tóm tắt, quét toàn bộ thư viện cập nhật các trang liên quan — một nguồn, có thể tác động đến hàng chục trang.
2. Query (Truy vấn): Hỏi trực tiếp Wiki đã biên dịch, trả lời có dẫn nguồn. Diệu nhất là: Câu trả lời hay có thể trực tiếp lưu trở lại thành trang mới, mỗi lần bạn khám phá cũng đang lãi kép.
3. Lint (Kiểm tra sức khỏe): Định kỳ để AI tự kiểm tra như kiểm tra code — tìm mâu thuẫn, tìm phán đoán lỗi thời, tìm trang cô lập không ai liên kết, tìm lỗ hổng nên bổ sung. Dọn sớm, không để thư viện càng dài càng mục.
Bạn không còn là người khuân vác tri thức, mà là kiến trúc sư của đế chế trí tuệ này.
Bạn chỉ phụ trách đầu vào và rà soát cuối cùng, AI phụ trách tất cả "công việc tạp": sắp xếp, căn chỉnh, liên kết chéo, phát hiện mâu thuẫn.
Đây là chuyển dịch căn bản của quan hệ sản xuất nhận thức.
Đây không phải một chatbot khác. ChatGPT hiểu internet, LLM-Wiki hiểu bạn — chính xác là, thứ bạn dạy cho nó.
Mỗi câu trả lời đều mang theo [wiki-links] trở về biểu đồ tri thức của bạn. Mỗi phản hồi đều là điểm khởi đầu của một con đường khám phá, chứ không phải điểm kết thúc.
Phát minh muộn 80 năm
Đến đây, bạn có thể nghĩ đây không gì hơn một workflow thông minh?
Không chỉ vậy.
Karpathy ở cuối gist, nhẹ nhàng điểm một cái tên: Vannevar Bush, và bài viết năm 1945 của ông "As We May Think".

Năm 1945, Thế chiến II vừa kết thúc, vị đại thần khoa học Mỹ này, đã mơ tưởng một cỗ máy tên "Memex":
Một chiếc bàn cơ khí, có thể lưu trữ tất cả sách, ghi chép, thư tín của bạn, và giữa các mục liên quan, thiết lập lên "con đường liên tưởng" — kết nối giữa tài liệu và tài liệu, quý giá như chính bản thân tài liệu.
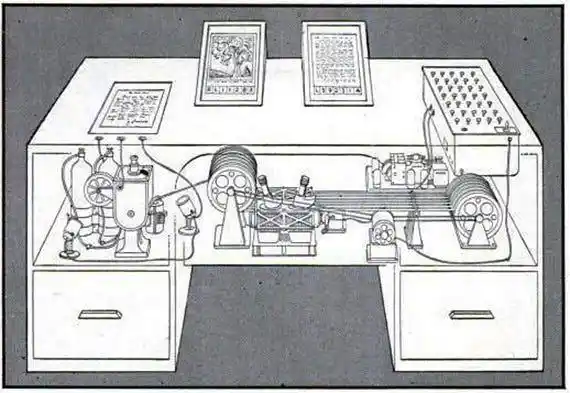
Nghe có quen không? Đây gần như là mô tả nguyên văn của LLM-Wiki.
Tầm nhìn của Bush, thực ra còn gần với thứ này hơn cả World Wide Web sau này: mạng tri thức riêng tư, do chính tay tuyển chọn, kết nối chính là giá trị.

Vậy tại sao Memex 80 năm không chế tạo ra?
Bởi vì Bush mắc kẹt ở một vấn đề ông không thể giải quyết — Ai bảo trì?
Mỗi con đường liên tưởng, đều phải thiết lập thủ công. Mỗi liên kết chéo, đều phải có người đi nối.
Bush mơ tưởng có "nhân viên vận hành" chuyên biệt rải lối mòn cho bạn trong tri thức.
Nhưng thực tế là, không có ai có thể kiên trì làm công việc khổ sai nhàm chán này trên quy mô lớn. Con người sẽ từ bỏ việc bảo trì, vì chi phí bảo trì, luôn luôn tăng nhanh hơn giá trị nó mang lại.
Câu này của Karpathy, là điểm nhãn của cả mô hình: Phần mệt mỏi nhất của việc bảo trì một thư viện tri thức, chưa bao giờ là đọc, mà là kế toán.
Cập nhật liên kết chéo, giữ cho tóm tắt luôn tươi mới, đánh dấu xung đột giữa dữ liệu mới và kết luận cũ, để hàng chục trang giữa chúng luôn nhất quán. Sự nhàm chán này, đủ để khiến mọi người nản lòng.
Mà mô hình lớn, không quên cập nhật một liên kết chéo nào, có thể một hơi sửa đổi 15 file.
Nó không mệt. Không chán. Không bị khuất phục bởi đêm khuya. Chi phí bảo trì, bị ép xuống gần như bằng không.
Và thế là, cỗ máy đã làm con người kẹt 80 năm, đột nhiên quay được.
Được giải phóng, là sự chú ý của con người
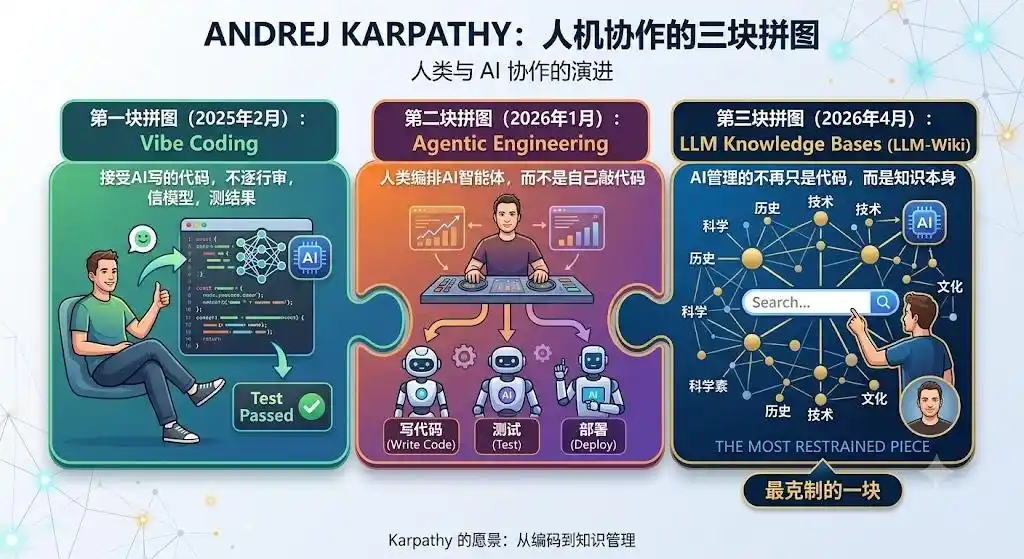
Nhìn lại, LLM-Wiki là mảnh ghép thứ ba của Karpathy về "hợp tác người-máy", cũng là mảnh tiết chế nhất.
Mảnh thứ nhất, Vibe Coding (Tháng 2/2025): Chấp nhận code do AI viết, không rà soát từng dòng, tin mô hình, kiểm tra kết quả.
Mảnh thứ hai, Agentic Engineering (Tháng 1/2026): Con người sắp xếp các agent AI, chứ không phải tự mình gõ code.
Mảnh thứ ba, LLM Knowledge Bases (Tháng 4/2026): AI quản lý không chỉ code nữa, mà là bản thân tri thức.
Trong mô hình mới này, thứ bị tước bỏ khỏi con người, là những công việc tạp không ai thích làm: sưu tầm, sắp xếp, liên kết, kế toán.
Thứ được để lại cho con người, chỉ còn hai việc: Quyết định đọc cái gì, và, nghĩ cho rõ tất cả những điều này rốt cuộc có ý nghĩa gì. Đây chính xác là hai việc mà máy móc đến nay không làm được, và cũng không nên thay bạn làm nhất.
Đây là câu chuyện một công cụ tiến hóa đến cực hạn, cuối cùng đi một vòng, trả lại sự chú ý của con người cho chính con người.
File markdown giản dị đến mức đáng tát đó, không phát hành mô hình, không đánh bảng xếp hạng.
Nó chỉ yên lặng nhắc nhở một câu: Bộ não của bạn, vốn không nên dùng để kế toán.
Bài viết từ tài khoản công chúng WeChat "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục








