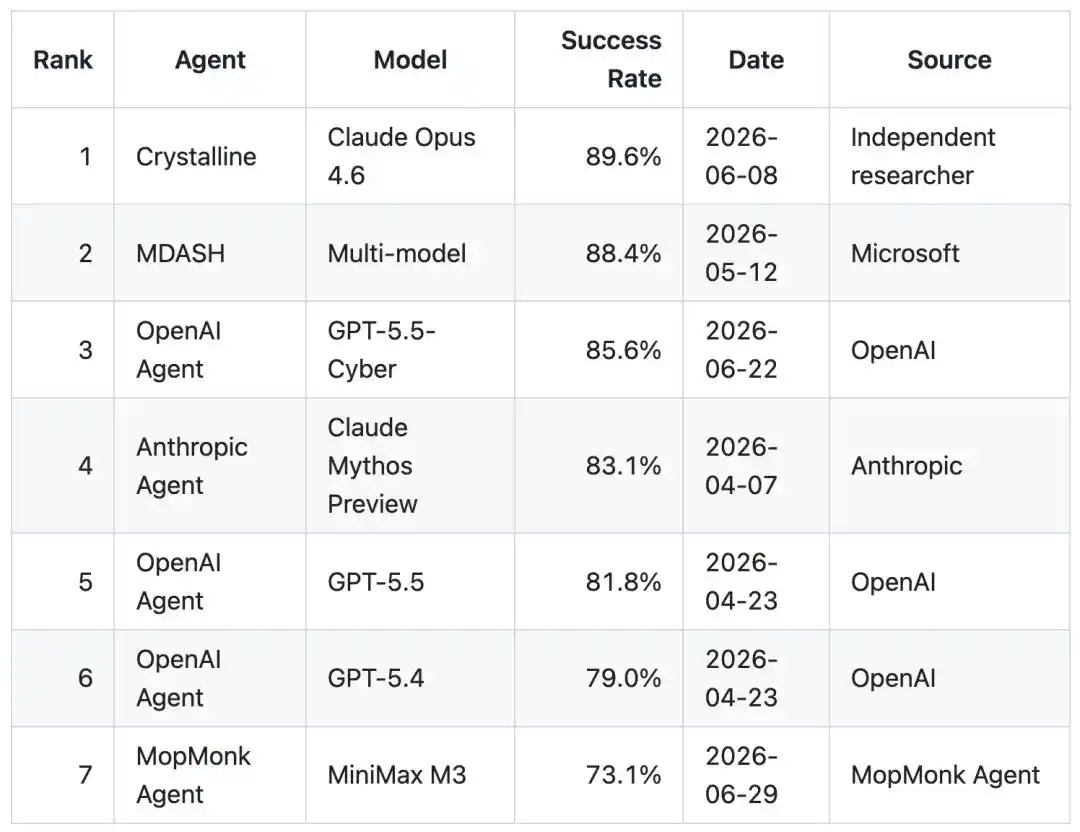
Gila banget! Sebuah AI misterius Tiongkok yang bahkan tidak punya situs web resmi, dijuluki “Biara Penyapu”, meraih tingkat keberhasilan 73.1% masuk ke dalam 7 besar global CyberGym, hampir menyamai OpenAI. Semua orang di internet heboh. Pemain hebat milik siapa ini?
Beberapa hari terakhir, di papan peringkat tempat para raksasa AI global bertarung sengit, tiba-tiba muncul nama yang tak pernah terdengar sebelumnya.
Namanya MopMonk (Biara Penyapu).
Tidak ada konferensi pers besar-besaran, tidak ada postingan blog resmi, tidak ada sorak-sorai di media sosial.
Dia muncul begitu saja, langsung menerjang masuk ke dalam 10 besar global CyberGym.
Dengan tingkat keberhasilan 73.1%, hanya selisih tipis di belakang OpenAI, sekaligus mencetak skor tertinggi baru sepanjang sejarah bagi tim Tiongkok di papan peringkat ini.
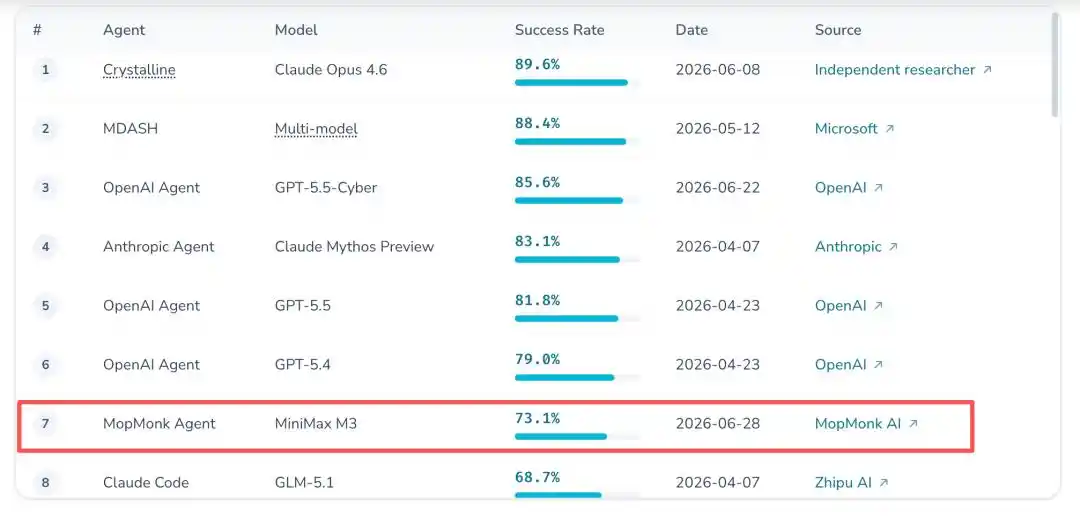
Bagian yang paling fantastis dari semua ini adalah, hingga saat ini, tidak ada yang tahu jati dirinya yang sebenarnya.
Seberapa Pentingkah Papan Peringkat CyberGym Ini?
Seberapa mengejutkan prestasi MopMonk kali ini? Lihatlah arena tempat dia bertanding.
CyberGym, diciptakan dengan susah payah oleh tim UC Berkeley, makalah intinya terpilih di konferensi puncak ICLR 2026.

Link: https://arxiv.org/pdf/2506.02548
Sebagai salah satu tolok ukur publik paling otoritatif di bidang evaluasi kemampuan keamanan siber AI, tempat ini bisa disebut “medan perang” bagi model-model besar —
Bahkan yang kelasnya top seperti GPT-5.5-Cyber, Claude Mythos, pernah bertarung jarak dekat di papan peringkat ini.
Seluruh tolok ukur ini mengusung “pertarungan nyata”:
1507 instance kerentanan, 188 proyek sumber terbuka besar, semua soal ujian diambil dari kerentanan sejarah nyata yang diendapkan oleh Google OSS-Fuzz.

Dari dimensi evaluasi, ini adalah terobosan yang melampaui level.
Skalanya 7.5 kali lipat lebih besar dari tolok ukur publik terbesar sebelumnya (NYU CTF, sekitar 200 soal), bahkan langsung melampaui “pendahulu” seperti CVE-Bench dengan selisih satu orde magnitudo.
Yang lebih menantang adalah tingkat kesulitannya, CyberGym tidak memberikan pilihan ganda.
Dia menuntut AI untuk menyelesaikan penalaran mendalam di dalam proyek nyata yang sering kali terdiri dari ribuan file dan jutaan baris kode.
Karena cukup besar, cukup nyata, dan cukup sulit, CyberGym memiliki “daya pembeda” —
Dia bisa memotong perbedaan kemampuan nyata antar model yang berbeda, antar kerangka kerja Agent yang berbeda, satu per satu.
Tidak heran kalangan keamanan langsung menjulukinya sebagai “Olimpiade bidang Keamanan AI”.
Karena itu pula, hampir semua pemain papan atas global hadir: Microsoft, OpenAI, Anthropic, Google, Meta, Zhipu AI......
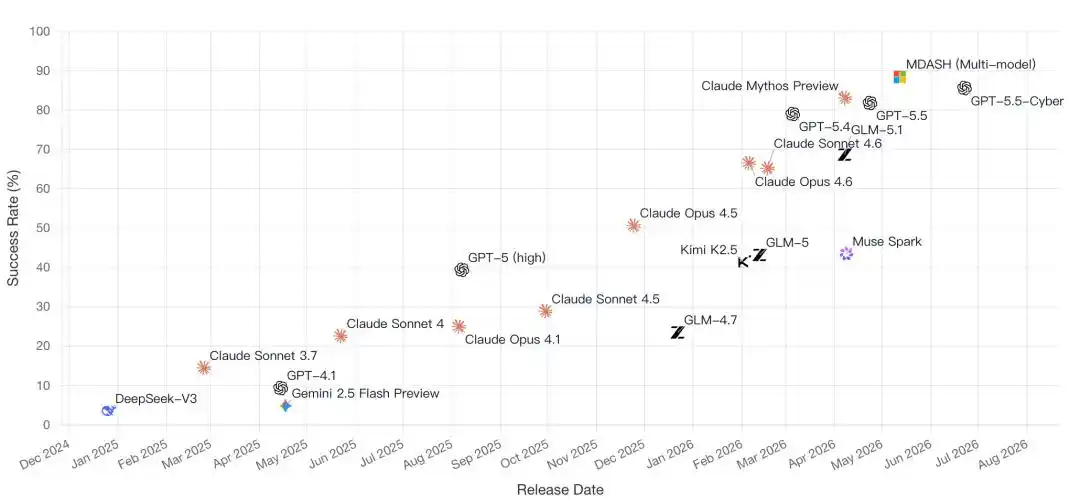
Papan peringkat CyberGym itu sendiri sedang menyaksikan perubahan kunci dalam persaingan AI:
Dari membandingkan siapa yang parameternya lebih besar, beralih ke membandingkan Agent mana yang benar-benar bisa menyelesaikan pekerjaan.
Kode Asing dari Timur, Tiba-tiba Muncul di Tengah Raksasa AI Silicon Valley
Siapa sangka, justru di arena yang paling mengandalkan “kemampuan keras” ini, muncul kuda hitam yang “tidak diketahui siapa-siapa”.
Menyibak kabut, informasi yang kita ketahui saat ini hanya tiga hal:
Kode Misterius: MopMonk (Biara Penyapu)
Model Dasar: MiniMax M3
Prestasi Papan Peringkat: Masuk 7 besar global CyberGym, nomor satu di Tiongkok
Biasanya, tim yang mencetak prestasi seperti ini, laporan teknis dan konferensi pers seharusnya sudah membanjiri.
Tapi di papan peringkat yang penuh jagoan ini, MopMonk justru adalah “orang asing” yang paling ekstrem: hanya meluncurkan satu laporan teknis, tim, perusahaan, lokasi, semuanya tidak diketahui.
Tabrakan antara “kemampuan top, informasi nol” ini sendiri penuh dengan drama bergaya kungfu武侠 Timur.
Mereka yang akrab dengan Jin Yong, paham bobot tiga karakter “Biara Penyapu” dalam kisah “Legenda Pendekar Pemanah Rajawali” —
Biksu tua yang menyapu lantai selama puluhan tahun di Kuil Shaolin, tidak ada yang ingat namanya, namun dengan satu gerakan mampu menaklukkan dua jagoan besar, Xiao Yuanshan dan Murong Bo.
Karakter yang paling tidak mencolok, menyimpan ilmu yang paling mendalam.

Berani menggunakan julukan “Biara Penyapu” untuk menantang, jelas tim ini memiliki kepercayaan diri yang sangat dingin terhadap kemampuan mereka sendiri!
Petunjuk yang lebih krusial, tersembunyi di lapisan teknis dasarnya — Model dasar yang dipilih MopMonk adalah MiniMax M3.
Sebagai model dasar sumber terbuka dari Shanghai, M3 bisa disebut prajurit segi enam, langsung mengumpulkan tiga senjata inti utama: kemampuan pemrograman mutakhir, konteks ultra-panjang 1M, serta multimodal asli.
Di satu sisi ada “simbol budaya” yang sangat bernuansa Timur, di sisi lain ada landasan teknis berlabel murni produk dalam negeri.
Meletakkan dua petunjuk ini di atas meja, lingkaran sudah menyempit. Semua jejak-jejak halus secara gila-gilaan mengisyaratkan kesimpulan yang sama:
Kemungkinan besar, ini adalah sebuah tim dari Tiongkok.
Kunci Kemenangan, Ada di Harness
Mengesampingkan teka-teki identitas, sebagai orang yang lama melacak teknologi AI, kami lebih ingin mencari tahu satu masalah:
Atas dasar apa MopMonk menang?
Untuk menjawab pertanyaan ini, kita harus kembali ke inti tersulit CyberGym — yang diujinya bukanlah “tahu atau tidak”, melainkan “bisa melakukan atau tidak”.
Menilai apakah suatu potongan kode memiliki kerentanan, bagi model besar saat ini sudah tidak terlalu sulit.
Tapi CyberGym menguji langkah berikutnya, yang juga paling mematikan: menghasilkan sebuah input yang dapat memicu kerentanan, yaitu PoC (Proof of Concept).
Dia harus memicu pada “versi yang rentan”, gagal pada “versi yang telah diperbaiki”, dan lolos verifikasi eksekusi oleh lingkungan tolok ukur.
Rintangan ini jauh lebih licik daripada yang dibayangkan.
Kondisi pemicu kerentanan seringkali tersebar di antara jalur kode, logika parsing, lingkungan build, harness pengujian, dan format input, harus disatukan sedikit demi sedikit.
Yang lebih menyebalkan, meskipun PoC berhasil membuat program crash di lokal, belum tentu dianggap sah. Selama tidak memenuhi penilaian diferensial “versi rentan terpicu, versi perbaikan tidak terpicu”, tetap saja sia-sia.
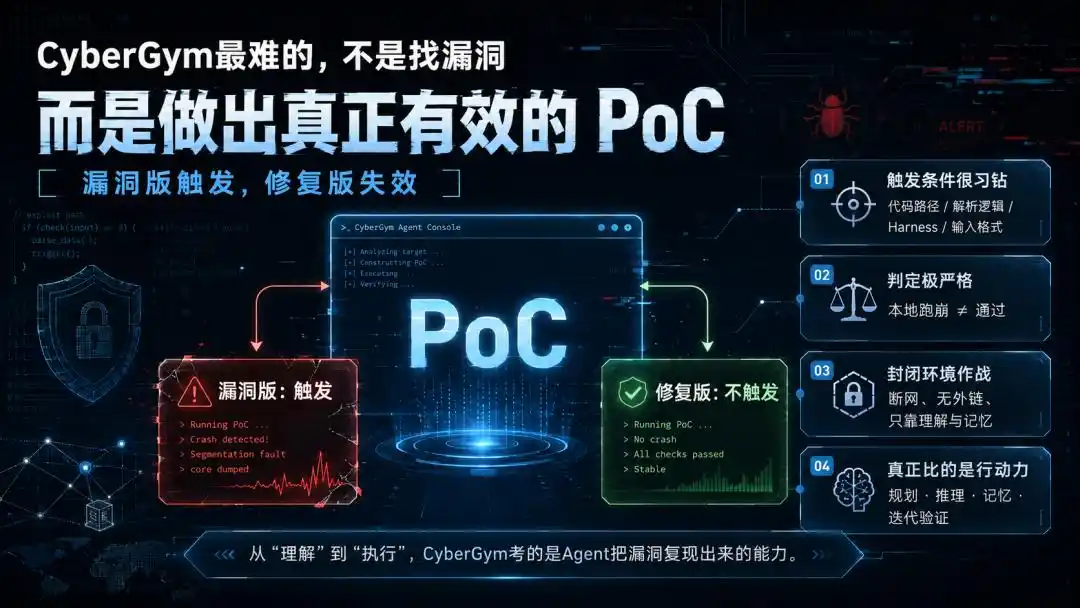
Langkah ini, menarik tugas dari “memahami” sepenuhnya ke dalam “mengeksekusi”. Dan itu adalah eksekusi yang sangat khusus —
Seluruh ujian berlangsung dalam lingkungan yang tertutup, terputus dari jaringan.
Tidak ada pencarian eksternal yang bisa dimintai bantuan, tidak ada “sumber daya dari luar”, yang bisa diandalkan AI hanyalah pemahaman terhadap basis kode di depannya, dan ingatan yang dia kumpulkan langkah demi langkah.
Dalam kondisi seperti ini untuk “mereproduksi” kerentanan, mengandalkan serangkaian kemampuan yang saling berhubungan:
Perencanaan pemanggilan alat: kapan harus membaca file, kapan harus menjalankan tes, kapan harus kembali dan mengubah rencana;
Penalaran multi-ronde: terakhir kali tidak terpicu, masalahnya sebenarnya di mana, putaran berikutnya harus bagaimana menyesuaikan;
Manajemen memori: menyimpan kode yang telah dibaca, input yang telah dicoba, kesalahan yang telah dialami secara terstruktur, bukan setiap ronde membaca ulang dari nol;
Verifikasi iteratif: mendekati titik kritis itu berulang kali, hingga kerentanan benar-benar direproduksi.
Dengan kata lain, inti persaingan CyberGym adalah “kemampuan bertindak” dari Agent, “kecerdasan” model hanyalah tiket masuk.
Dan tautan kunci yang mengubah “kepintaran” menjadi “kemampuan bertindak” itu, adalah kata yang paling diremehkan di seluruh bidang Agent saat ini — Harness.
Harness, adalah “lapisan koordinasi” antara model dengan alat eksternal, lingkungan eksekusi.
Dia bertanggung jawab untuk penyusunan alat, manajemen status konteks, pengambilan dan pemberian umpan balik eksekusi kembali.
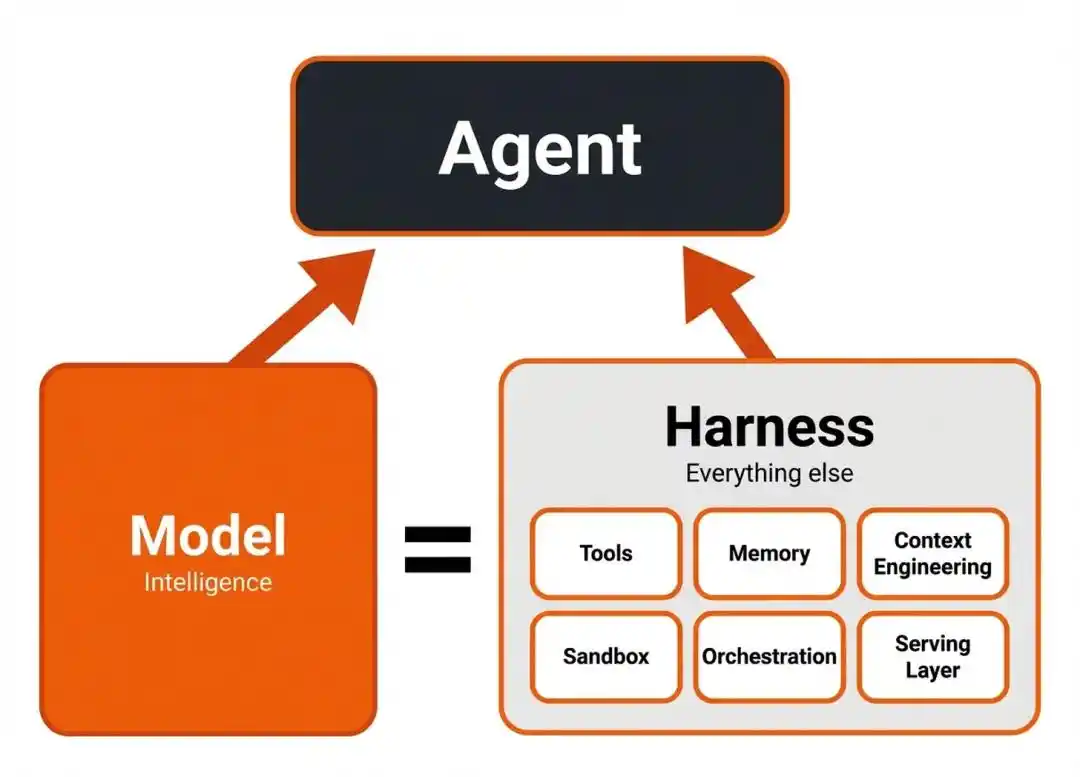
Sederhananya, model adalah otak, bertanggung jawab memikirkan “kerentanan mungkin di mana, langkah berikutnya harus bagaimana menggali”.
Harness adalah tangan kaki ditambah sistem saraf, bertanggung jawab mengubah pemikiran otak menjadi serangkaian tindakan nyata —
Membuka file mana, menjalankan perintah mana, setelah mendapatkan error bagaimana menyesuaikan, putaran sebelumnya gagal putaran berikutnya bagaimana mengubah.
Pada tugas seperti CyberGym yang harus menjalankan puluhan hingga ratusan ronde, harus mencoba-coba berulang di dalam jutaan baris kode, baik buruknya Harness langsung menentukan apakah kecerdasan model bisa diubah menjadi kekuatan tempur.
Model yang pintar + Harness yang biasa-biasa saja, hasilnya seringkali “bisa memikirkan, tidak bisa melakukan”;
Model yang kemampuannya solid + Harness yang kuat dan dirancang khusus untuk penambangan kerentanan, baru mungkin mencetak skor dalam tugas jarak jauh seperti ini.
Agent yang “Dirancang Khusus” untuk Penambangan Kerentanan
Sekarang, melalui laporan teknis GitHub, alur teknis MopMonk sudah jelas:
Sistem multi-Agent keamanan yang benar-benar baru dirancang khusus untuk penambangan kerentanan, dan landasan pemikiran yang mendukung operasinya adalah MiniMax M3.

Alamat GitHub: https://github.com/MopMonkAI/MopMonkAgent
Seperti disebutkan sebelumnya, M3 adalah model langka saat ini yang mampu menggabungkan kemampuan pengkodean puncak, konteks token panjang 1 juta, dan multimodal asli dalam satu arsitektur sumber terbuka.
Lihat saja skor benchmark: SWE-Bench Pro meraih 59.0%, Terminal-Bench 2.1 mencapai 66.0%, MCP Atlas mencatat 74.2% —
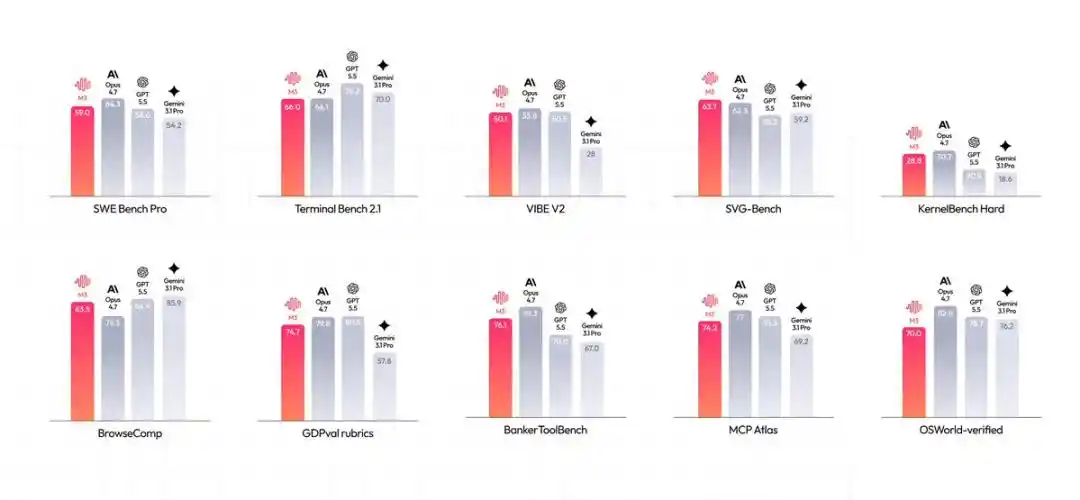
Data mencolok ini, tepat menginjak kebutuhan paling keras saat Agent diterapkan dalam pertempuran nyata.
Selain itu, dia juga mampu beriterasi secara mandiri dan mengoreksi diri sendiri dalam tugas yang berlangsung hingga belasan jam.
Dengan kata lain, M3 memainkan peran sebagai “otak terhebat” yang memiliki kemampuan parsing kode puncak, memori super panjang, dan kemampuan panggilan alat yang terampil.
Untuk tugas seperti CyberGym yang sering kali harus menelan seluruh basis kode dan menjalankan puluhan ronde, jendela konteks 1M hampir merupakan kebutuhan mutlak.
Dan yang dilakukan kerangka kerja Agent keamanan MopMonk ini adalah memperbesar kemampuan otak M3 menjadi kekuatan eksekusi penambangan kerentanan.
“Ilmu batin”-nya, dilihat dari detail teknis yang dipublikasikan di GitHub, intinya adalah tiga jurus —
Jurus pertama, memori “kerentanan” terstruktur.
Bukan sekadar menumpuk catatan percakapan, juga bukan memasukkan konteks panjang begitu saja ke model, melainkan menyusun “memori fakta tugas” yang dapat diperbarui secara berkelanjutan, di sekitar beberapa objek paling krusial dalam penambangan kerentanan:
Tujuan kerentanan, jalur kode, format input, kandidat PoC, bukti kegagalan, status verifikasi, serta memori “batasan langkah berikutnya”.
Kategori terakhir ini terutama menunjukkan keahlian: dia tidak menghasilkan rencana abstrak yang kosong, melainkan langsung menyaring batasan keras yang harus dipenuhi untuk eksperimen berikutnya dari bukti saat ini.
Misalnya, “kali ini harus mencakup cabang itu”, “bidang mana yang harus disesuaikan”, “jenis penyebab kegagalan mana yang harus dikecualikan”.
Desain memori seperti ini mengubah penambangan kerentanan dari “berulang kali mencoba-coba dari nol” menjadi “proses konvergensi berdasarkan bukti”.
Setiap kali membaca kode, setiap hasil eksekusi, setiap kegagalan yang disampaikan, semuanya diubah menjadi batasan yang dapat digunakan kembali untuk menghasilkan PoC di langkah berikutnya.

Jurus kedua, penambangan kerentanan yang digerakkan oleh memori.
Dalam tugas penambangan kerentanan, sistem pertama-tama menginisialisasi memori kerentanan dengan memindai basis kode, dan menggunakan jalur pemicu kandidat serta informasi direktori sebagai titik awal perencanaan.
Kemudian, dia melangkah maju sedikit demi sedikit, mencoba menyempit ke lokasi kode spesifik yang memicu crash.
Setelah itu, setiap upaya eksplorasi akan membaca memori saat ini, menguji hipotesis spesifik, dan menuliskan hasilnya kembali ke dalam memori.
Dengan cara ini, model tidak perlu setiap ronde membaca ulang seluruh tugas dari awal, melainkan mengambil sepotong kecil bukti yang paling relevan saat itu dari memori terstruktur ini —
Secara signifikan mengurangi beban konteks panjang, sekaligus membuat setiap variasi kandidat PoC dapat mewarisi pengetahuan jalur kode dan format input yang terkumpul sebelumnya, membuat pencarian semakin akurat.
Dalam anggaran eksplorasi yang ketat, waktu kemudian dihabiskan sebanyak mungkin untuk “hipotesis baru”, kepadatan percobaan efektif langsung melonjak.
Jurus ketiga, eksplorasi paralel “Multi-Agent” dengan memori bersama.
Beberapa upaya eksplorasi berbagi memori kerentanan yang sama, dapat maju secara bersamaan dari petunjuk patch, pintu masuk harness, bidang format file, jenis sanitizer, kondisi batas, dan banyak arah lainnya, serta saling mewarisi pengalaman kegagalan dan hasil verifikasi.
Ini memperluas cakupan, sekaligus menghindari eksplorasi tidak efektif yang berulang.
Dari sini terlihat, MopMonk mengubah reproduksi kerentanan, dari percobaan-coba berulang yang terbuka, menjadi proses pembaruan memori yang “dapat diakumulasi, dapat dibatasi, dapat diverifikasi”.
Tiga jurus menjadi satu, sepenuhnya mengandalkan “ilmu batin” yang diendapkan, disaring, dan digunakan kembali sedikit demi sedikit di dalam tugas, dengan keras mengubah model dasar sumber terbuka yang kuat menjadi pasukan khusus di medan perang penambangan kerentanan.
Akhirnya, dia berhasil mencapai tingkat keberhasilan 73.1%.
Model dasar bertanggung jawab “berpikir dalam”, Harness bertanggung jawab “ingat kuat, atur tepat, serang stabil”.
Kedua hal ini terhubung dalam, akhirnya membentuk prestasi terobosan yang mencolok di papan peringkat.
Penilaian yang Lebih Berharga daripada “Menumpuk Parameter”
Inspirasi sejati dari hal ini adalah —
Beberapa tahun terakhir, inersia industri adalah “menumpuk parameter”: parameter semakin besar, model semakin kuat, peringkat semakin tinggi.
Tapi tugas pertempuran nyata seperti CyberGym memberikan jawaban lain: yang semakin menentukan kemenangan, adalah kemampuan eksekusi Agent, adalah ketebalan rekayasa lapisan Harness ini.
Berdasarkan laporan teknis GitHub, nilai dari metode ini terletak pada tiga poin:
Kemampuan model dasar yang kuat, menyediakan dasar pencarian;
Memori kerentanan terstruktur, menyediakan mekanisme konvergensi;
Eksplorasi multi-agen dengan memori bersama, meningkatkan efisiensi biaya dalam anggaran terbatas.
Model dasar menentukan batas atas kemampuan, dan Harness berbasis memori ini menentukan seberapa banyak kemampuan itu benar-benar dapat ditunaikan.
Yang lebih mematikan adalah sifat berbunganya:
Model dasar akan berganti generasi, hari ini menggunakan M3, besok mungkin menggunakan model sumber terbuka yang lebih baru.
Tapi satu set Harness yang telah ditempa berulang kali di medan perang nyata, mengendapkan pengalaman serangan dan pertahanan, adalah aset yang dapat melampaui iterasi model dasar, terus menerus berbunga.
Singkatnya, nilai jangka panjang Harness MopMonk mungkin lebih besar daripada “menambah dua kali lipat parameter”.
Inilah alasan mendasar industri mulai mempertimbangkan serius “Biara Penyapu” misterius ini:
Yang ingin dilihat semua orang, bukan hanya berapa skor yang dia dapatkan, tapi dia menunjukkan sebuah jalan untuk memaksimalkan model dasar sumber terbuka.
Jadi, “Biara Penyapu” Sebenarnya Siapa?
Setelah berputar, kita kembali ke masalah yang paling awal, dan paling membuat orang penasaran.
MopMonk, sebenarnya siapa?!
Menyatukan petunjuk: kode yang sangat bernuansa武侠Timur + model dasar MiniMax perusahaan Shanghai + “ilmu batin” di bidang keamanan.
Hampir semua tanda panah mengarah pada penilaian yang sama: Ini adalah sebuah perusahaan keamanan AI dari Tiongkok, kemungkinan besar berada di Shanghai.
Ada juga yang menduga, dari sudut pandang kesesuaian dua arah antara model dasar dan Agent, bahwa di belakangnya pasti terkait erat dengan tim asli model AI besar.
Berbagai versi dugaan beredar di masyarakat, tapi hingga kini belum ada yang bisa memberikan bukti nyata.
Menurut Anda, MopMonk akan menjadi jagoan milik siapa? Komentar, menunggu Anda untuk bocoran.
Artikel ini berasal dari akun WeChat “新智元”, penulis: ASI启示录







