Collectionner n'est pas posséder, surligner n'est pas comprendre.
Ces articles profonds qui vous enthousiasmaient à deux heures du matin, ces innombrables liens bidirectionnels extraits d'Obsidian, ces bases de données méticuleusement mises en page dans Notion, ce sont tous des « momies cybernétiques » dormant dans vos applications de prise de notes.
Le graphe semble impressionnant, mais il est en réalité déjà pourri.
C'est l'échec systémique de toute cette ère de surcharge informationnelle.
L'ingénieur actuel d'Anthropic, ancien cofondateur d'OpenAI, ancien directeur de l'IA chez Tesla, Karpathy, n'en pouvait plus et a lâché une bombe.

Portail : https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Il n'a pas annoncé de nouveau modèle, ni publié de nouveau framework. Il a simplement dit : Considérez vos notes comme un code source immuable, et laissez le LLM être le compilateur.
Deux mois plus tard, ce document a déjà déclenché une migration silencieuse mais intense dans les communautés Obsidian, Claude et Cursor.
Certains ont déjà étendu leur Wiki à des centaines de pages, des centaines de milliers de mots.
Des plugins d'automatisation commencent à apparaître. Chercheurs académiques, entrepreneurs indépendants, apprenants tout au long de la vie se tournent collectivement vers un tout nouveau mode de production de connaissances.
Le crépuscule du RAG, le transport d'information ne sauvera pas votre pensée
Avant l'avènement du LLM-WIKI, la solution principale était le RAG (Retrieval-Augmented Generation).
En bref, on donne au grand modèle un « fouilleur » : quand vous posez une question, il va chercher quelques extraits dans vos notes, puis assemble une réponse.
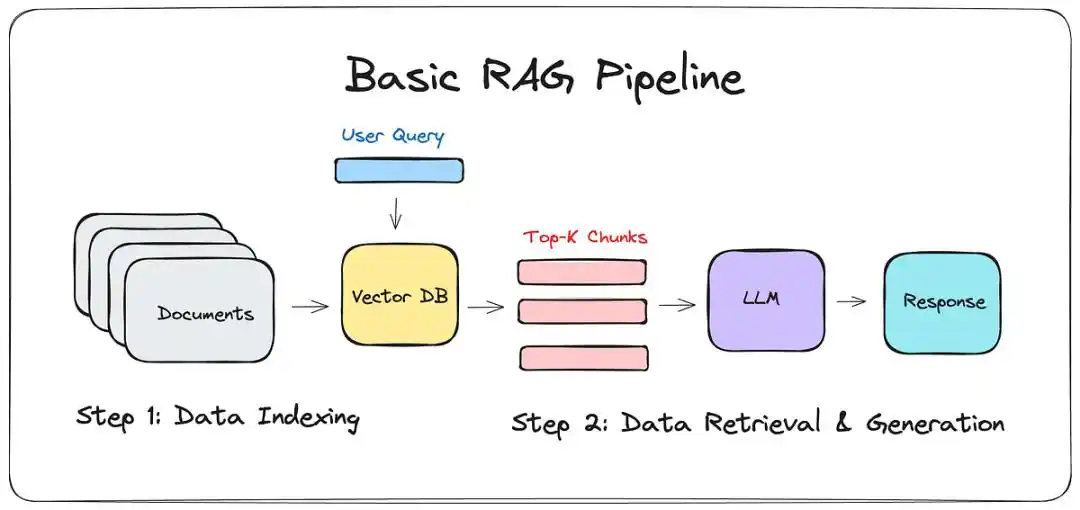
Cela semble beau, mais ceux qui l'ont utilisé connaissent l'écart entre la « présentation » et la « réalité ».
Il n'est qu'un manutentionnaire : Le RAG ne peut traiter que localement, il ne comprend pas la vue d'ensemble.
Il peut vous dire que la 5ème note mentionne A, mais il ne peut pas vous révéler la logique sous-jacente commune à ces 500 notes.
Il devient « schizophrène » : Si vous pensiez que A était vrai il y a six mois, mais que vous avez écrit une note hier pour réfuter A, le RAG tombe souvent dans des contradictions, crachant un tas de bêtises logiquement incohérentes.
Pourriture du graphe : Les liens de connaissances maintenus manuellement sont comme du code sans fonction de nettoyage automatique. Avec le temps, les liens morts pullulent, et l'efficacité de la recherche diminue de façon exponentielle.
L'intuition de Karpathy est extrêmement tranchante : La recherche et la récupération sont une manifestation de l'incapacité humaine. Nous avons besoin de « consensus », de « structure », de « vérité ».
Considérer la connaissance comme du code source, laisser le LLM être le compilateur
La réponse de Karpathy vient d'une action que les programmeurs font tous les jours, mais n'ont jamais pensée pour la connaissance : la compilation.
Vous écrivez un morceau de code source, vous ne le relisez pas à chaque exécution du programme.
Vous le compilez en un fichier binaire. Cette compilation est coûteuse, mais ensuite chaque exécution est rapide. Le coût de la compilation est amorti par des milliers d'utilisations ultérieures.
Pourquoi la connaissance ne pourrait-elle pas fonctionner ainsi ?
Karpathy dit : Considérez vos notes brutes comme un code source immuable, considérez le LLM comme un compilateur, et laissez-le « compiler » une fois pour toutes ce tas de matériel désordonné en un Wiki structuré et interconnecté.
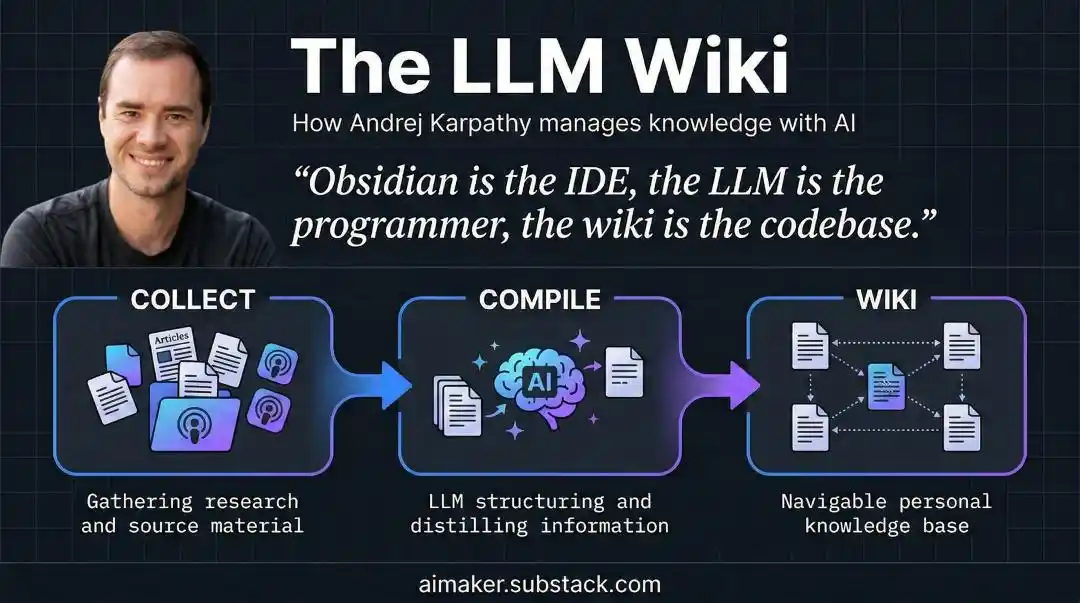
À chaque ajout d'un nouveau matériau, l'IA effectue une fusion : met à jour les pages d'entrées concernées, révise les synthèses, signale les conflits entre nouvelles données et anciennes conclusions, et renforce ou remet en question les jugements existants.
La différence cruciale est ici : Les connaissances sont compilées une fois, puis restent fraîches, au lieu d'être reconstruites temporairement à chaque interrogation.
Lorsque vous venez poser une question, les renvois croisés sont déjà là, les contradictions sont déjà signalées, les synthèses reflètent déjà tout ce que vous avez lu.
Vous ne recompilez pas le code source à chaque exécution du programme. Alors pourquoi, à chaque question, faudrait-il que l'IA relise toutes vos notes ?
Le transfert fondamental des rapports de production cognitive
Dans son framework LLM-WIKI, les notes ne sont plus des mots morts, mais du « code source ».
Le grand modèle n'est plus un traducteur cherchant dans le dictionnaire, mais un « compilateur ».
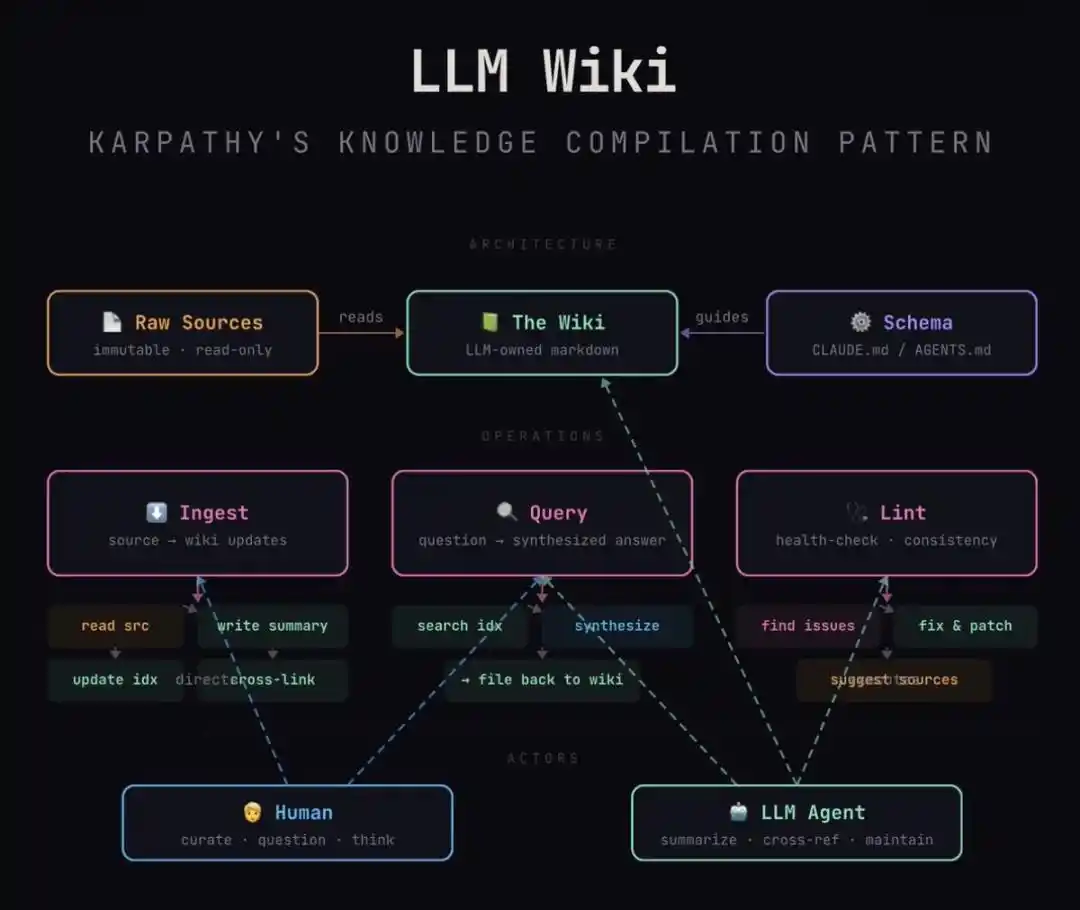
Cette architecture réalise de manière extrêmement ingénieuse un découplage en trois couches :
1. La couche Raw (matériau brut) : C'est votre minerai d'inspiration brut. Les idées notées rapidement, les articles élagués, les comptes-rendus de réunion. Elle est « immuable », préservant la nature brute et imparfaite de l'entrée humaine.
2. La couche Schema (constitution de la connaissance) : C'est le « règlement » que vous écrivez pour l'IA. Par exemple, vous stipulez : chaque entrée de personnage doit contenir « motivation, limites, réalisations clés » ; chaque pile technologique doit expliquer « avantages/inconvénients ».
3. La couche Wiki (produit compilé) : C'est la zone entièrement maintenue par l'IA. Elle compile, selon votre Schema, ce tas de Raw désordonné en pages d'encyclopédie structurées, croisées et logiquement cohérentes.
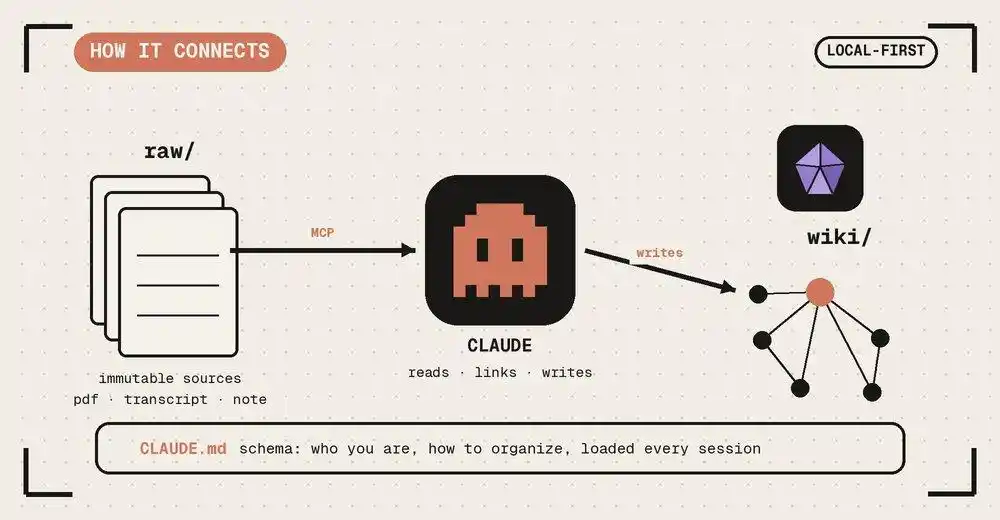
Au quotidien, trois actions seulement :
1. Ingest (ingestion) : Jetez-y un nouveau matériau. L'IA le lit, passe en revue les points clés avec vous, écrit un résumé, balaye toute la base pour mettre à jour les pages concernées — une source peut impacter une dizaine de pages.
2. Query (interrogation) : Interrogez directement le Wiki compilé. Les réponses viennent avec des citations. Le plus génial : les bonnes réponses peuvent directement être archivées en nouvelles pages, chaque exploration que vous faites génère aussi des intérêts composés.
3. Lint (examen de santé) : Faites régulièrement passer à l'IA un examen d'auto-vérification, comme une revue de code — chercher les contradictions, les affirmations dépassées, les pages isolées sans liens, les lacunes à combler. Nettoyer tôt, pour éviter que la base ne pourrisse en grandissant.
Vous n'êtes plus le manutentionnaire de la connaissance, mais l'architecte de cet empire de la sagesse.
Vous êtes seulement responsable de l'entrée et de la revue finale. L'IA s'occupe de tout le « travail ingrat » : organiser, aligner, créer des liens croisés, détecter les contradictions.
C'est le transfert fondamental des rapports de production cognitive.
Ce n'est pas un autre chatbot. ChatGPT connaît Internet, LLM-Wiki vous connaît — plus précisément, ce que vous lui avez enseigné.
Chaque réponse vient avec des [liens-wiki] vers votre graphe de connaissances. Chaque réponse est un point de départ pour une piste d'exploration, et non une fin.
Une invention en retard de 80 ans
À ce stade, vous pourriez penser que ce n'est qu'un flux de travail intelligent ?
Pas seulement.
À la fin de son gist, Karpathy mentionne légèrement un nom : Vannevar Bush, et son article de 1945, « As We May Think ».

1945, juste après la Seconde Guerre mondiale, ce grand nom de la science américaine imagina une machine appelée « Memex » :
Un bureau mécanique, capable de stocker tous vos livres, notes, correspondances, et d'établir entre les entrées pertinentes des « chemins d'association » — les connexions entre documents étant aussi précieuses que les documents eux-mêmes.
Cela vous semble familier ? C'est presque la description mot pour mot du LLM-Wiki.
La vision de Bush était en fait plus proche de cela que le Web ne l'a été plus tard : un réseau de connaissances privé, personnellement organisé, où la connexion est la valeur.

Alors pourquoi le Memex n'a-t-il pas été construit en 80 ans ?
Parce que Bush est resté bloqué sur un problème qu'il ne pouvait résoudre — Qui allait le maintenir ?
Chaque chemin d'association devait être établi manuellement. Chaque référence croisée devait être connectée par quelqu'un.
Bush imaginait des « opérateurs » dédiés traçant des sentiers dans la connaissance pour vous.
Mais la réalité est qu'aucun être humain ne peut, à grande échelle, persister dans cette corvée fastidieuse. Les humains abandonnent la maintenance, car son coût augmente toujours plus vite que la valeur qu'elle apporte.
Cette phrase de Karpathy est le point crucial de tout le paradigme : La partie la plus fatigante de la maintenance d'une base de connaissances n'a jamais été la lecture, c'est la « tenue des comptes ».
Mettre à jour les références croisées, garder les résumés frais, signaler les conflits entre nouvelles données et anciennes conclusions, maintenir la cohérence entre des dizaines de pages. Cette monotonie est suffisante pour décourager tout le monde.
Et le grand modèle, lui, n'oubliera pas de mettre à jour une référence croisée, peut modifier 15 fichiers d'un coup.
Il ne se fatigue pas. Ne s'ennuie pas. N'est pas épuisé par les nuits tardives. Le coût de maintenance est ramené à pratiquement zéro.
Ainsi, cette machine qui a bloqué l'humanité pendant quatre-vingts ans, s'est soudain mise en marche.
Ce qui est libéré, c'est l'attention humaine
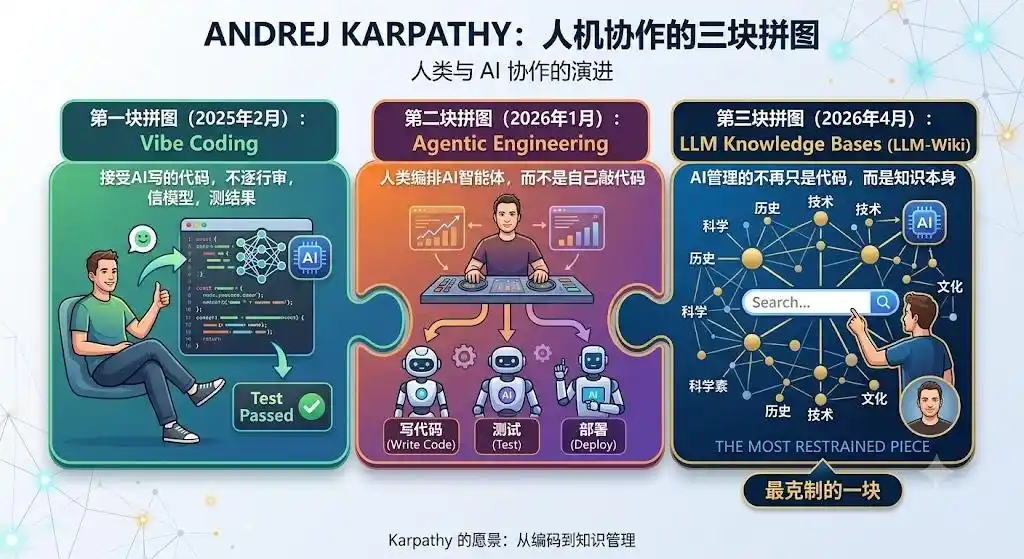
En y repensant, LLM-Wiki est la troisième pièce du puzzle de Karpathy sur la « collaboration homme-machine », et aussi la plus sobre.
La première, Vibe Coding (février 2025) : Accepter le code écrit par l'IA, ne pas le revoir ligne par ligne, faire confiance au modèle, tester le résultat.
La deuxième, Agentic Engineering (janvier 2026) : Les humains orchestrent des agents IA, au lieu de coder eux-mêmes.
La troisième, LLM Knowledge Bases (avril 2026) : Ce que l'IA gère n'est plus seulement du code, mais la connaissance elle-même.
Dans ce nouveau paradigme, ce qui est retiré à l'humain, ce sont les tâches ingrates que personne n'aime faire : collectionner, organiser, lier, tenir les comptes.
Ce qui reste à l'humain, ce ne sont que deux choses : décider de quoi lire, et, comprendre ce que tout cela signifie vraiment. Ce sont précisément les deux choses que la machine ne peut pas encore faire à votre place, et ne devrait surtout pas faire pour vous.
C'est l'histoire d'un outil qui, en évoluant à l'extrême, finit par faire un cercle complet et rendre l'attention humaine à l'humain lui-même.
Ce fichier markdown si sobre qu'il en est presque frustrant, n'a pas sorti de modèle, n'a pas dominé de classements.
Il rappelle simplement, tranquillement, une chose : votre cerveau n'était pas fait pour tenir des comptes.
Cet article provient du compte public WeChat « 新智元 » (New Wisdom Era), auteur : ASI Apocalypse







