作者:Li Yuan
你有没有向 AI 助手问过你的健康问题?
如果你和我一样是一个 AI 的深度用户,大概率你也试过。
OpenAI 自己给出来的数据是,健康已成为 ChatGPT 最常见的使用场景之一,全球每周有超过 2.3 亿人提出与健康和保健相关的问题。
正因如此,跨入 2026 年,健康领域也大有成为 AI 领域必争之地的迹象了。
1 月 7 日,OpenAI 发布 ChatGPT 健康,允许用户连接电子医疗记录和各类健康应用,让用户能够获得更针对性的医疗回复;而 1 月 12 日,Anthropic 也立马推出了 Claude for Healthcare,并强调了新模型的医学场景能力。
不过有趣的是,这次,中国公司没有落下,甚至大有领先之意。
1 月 13 日,百川智能宣布发布百川 M3 模型,在 OpenAI 发布的医疗健康领域评估测试集 HealthBench,反超 OpenAI 的 GPT-5.2 High,获得 SOTA。
在宣布 All-in 医疗受到诸多质疑后,百川智能似乎终于证明了自己。极客公园此次也专程与王小川聊了聊百川智能如何看待此次 M3 模型的能力,以及 AI 医疗的终局。
01 首次在健康领域测试集超越 OpenAI
此次发布的 M3 模型,最亮眼的成绩之一,在于模型第一次在 OpenAI 发布的医疗健康领域评估测试集 HealthBench,超越 OpenAI 的 GPT-5.2 High,获得 SOTA。
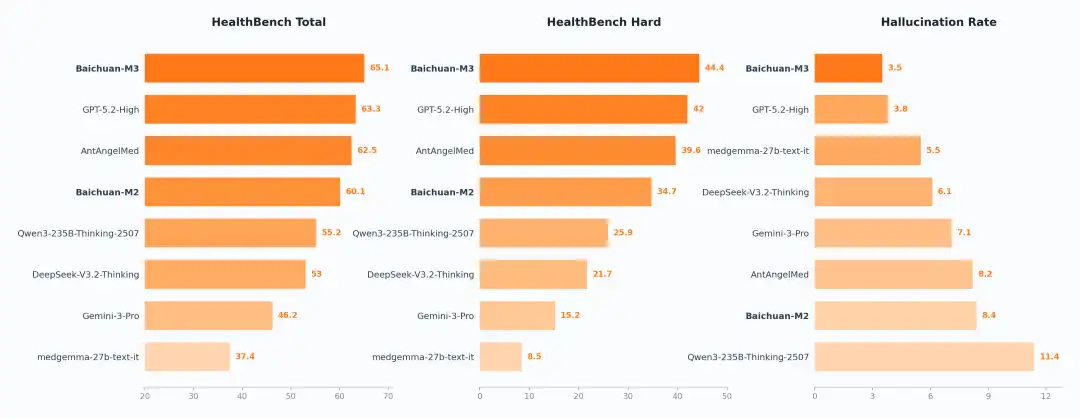
SOTA On Healthbench、Healthbench Hard and Hallucination Evaluation
Healthbench 是 OpenAI 在 2025 年 5 月份发布的医疗健康领域评估测试集,由 262 位来自 60 个国家的医生共同构建,收录了 5000 组高度逼真的多轮医疗对话,是目前全球最权威、也最贴近真实临床场景的医疗评测集之一。
发布后,OpenAI 的模型一直霸榜。
而此次,百川智能的新一代开源医疗大模型 Baichuan-M3,则获得了 65.1 分的综合成绩位列全球第一,甚至在专门考验复杂决策能力的 HealthBench Hard 上,M3 也成功夺冠,刷新了最高分。
百川还同步公布了一个幻觉率的测试结果,在幻觉率,M3 模型达到了 3.5%,属于全球最低。
值得注意的是,这个幻觉率是不依赖外部检索工具,纯模型设置下的医疗幻觉率。
百川智能表示,能够达到这两点,关键的模型提升在于为医疗引入了合适于医疗的强化学习算法。
百川在 M3 模型上首次使用了 Fact Aware RL(事实感知强化学习)技术,达到了既让模型不说套话,也不让模型乱说话的效果。
这在医疗领域实际上是非常关键的。
在没有优化的模型中提问医疗问题,最容易出现的问题就是两类,一是模型直接胡编乱造你的症状,臆测一个疾病出来;而另一个则是语义模糊,最终提示你还是得去看医生,而这无论对于医生还是患者,都没有太大帮助。
这正是因为很多模型以纯幻觉率作为优化目标,此时模型可能通过堆砌简单正确的事实来稀释整体幻觉率。而百川引入语义聚类与重要性加权机制——聚类消除冗余表述的干扰,加权确保核心医学论断获得更高权重。
同时,如果单纯引入高权重的幻觉惩罚,极易迫使模型陷入「少说少错」的保守策略,因此 Fact Aware RL 的算法中还设计了动态权重调节机制,根据模型当前的能力水平自适应地平衡这两个目标——在能力构建阶段,侧重医疗知识的学习与表达(高 Task Weight);在能力成熟后,逐步收紧事实性约束(提升 Hallucination Weight)。
当可以联网搜索时,百川还加入了基于多轮搜索的在线校验模块,同时引入了高效的缓存系统,进行海量医疗知识的对齐。
02 问诊水平超过人类医生,步入可用阶段
不过,在 Healthbench 上超过 OpenAI 并不是此次唯一的亮点。
此次更有趣的一个点,百川自己创造性地构建了一个 SCAN-benche 评测集。比起刷榜 OpenAI 的评测集,百川自己构建的评测集,或许更能说明百川智能在医疗上想要优化的方向。
此次百川构建的测评集,关键点在于优化「端到端的问诊能力」。这源于百川自己做的实验洞察:问诊准确度每增加 2%,诊疗结果准确度就会增加 1%。
也就是说相比于 OpenAI 的 HealthBench,仍然主要关注「AI 会不会回答问题」,百川的 SCAN-benche 希望评测出的是:AI 是否能在一问一答中,获取有效信息,同时给出正确的诊疗结果和医疗意见。
通常情况下,我们向 AI 助手提问,如果只是提到「你是一位经验丰富的医生」,通常并不会得到太好的模型效果。因为真正的医生,问诊的流程是十分规范的——百川将其归纳为四个象限的 SCAN 原则:Safety Stratification(安全分层)、Clarity Matters(信息澄清)、Association & Inquiry(关联追问)与 Normative Protocol(规范化输出)。
围绕 SCAN 原则,百川借鉴医学教育里长期使用的 OSCE 方法,联合 150 多位一线医生,搭建了 SCAN-bench 评测体系,将诊疗过程拆解为病史采集、辅助检查、精准诊断三大阶段,通过动态、多轮的方式进行考核,完整模拟医生从接诊到确诊的全过程,也以在这几个流程中,都获得更好的结果,来优化模型。
此次百川也公布了 M3 模型在 SCAN-benche 上的测评结果。
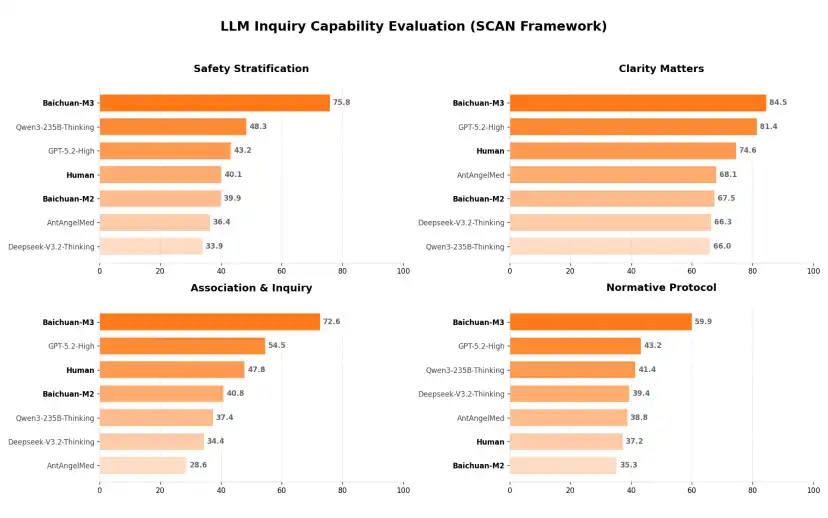
结果十分有趣。百川此次不仅和模型进行了对比,还找来了真人医生进行对比。而在四个象限中,真人医生实际上都已经落后于模型能够达到的水平了。
极客公园特意对此向百川团队进行了提问,得到的回答是:此次的测评,全都是真人的专科医生在专科案例上与模型进行的比较。模型能够获胜,其一,在于模型更耐心,但更重要的是,模型拥有更好的跨学科的知识的掌握能力。
比如在一个案例中,提到 10 岁孩子反复发热,而发热是一个非常综合的医疗现象,如果只询问咳嗽等肺部情况,就容易忽略关节和泌尿系统中的严重问题,误判为普通感染。
人类医生通常只对分科的病情比较擅长,这也是复杂症状常常需要专家会诊,或者疑难病症专家也常常要去翻书找资料的原因。
而没有经过专门训练,只是扮演医生的普通模型,往往也很难回答好这类问题。
03 下一步:逐渐开始做 C 端产品,推进更严肃的医疗
对于百川智能而言,超过人类医生这个节点,意义十分重大:这意味着 AI 开始迈过可用性的门槛,开始能够被部署到使用场景中了。
从 1 月 13 日起,用户已经可以开始在百小应的网站和 app 中,体验到 M3 模型提供的回答了。
目前的网站设计十分有趣,虽然都是使用 M3 模型进行回答,但是区分医生版和用户版。在医生版,回答更加简洁,引用更多参考文献,也更「不说人话」。而在普通病人版,模型几乎不会一次性给出回答,都会进行更多追问,进行更明确的诊断。

百川智能提到,模型在后台的思考很有意思。 「 我们经常能看到这个模型在思维链中提到,『这个患者没有理我的这个问题,但是这个问题我必须要问。』甚至我们有看到过那种极端的,说我已经问了患者 20 轮了,这个已经超出了设定的最大轮数,但是这个问题我还是要问。这是因为在训练的过程中模型把话说得讨巧,是得不到奖励的,它必须真的得到了足够多的关键的信息,得到正确的诊断,才能得到奖励。这个是我们跟其他人训练模型的一个明显的不同。」
近来很多 AI 公司都开始介入医疗领域。这也是百川智能认为自己的最大不同之处——要做更严肃的医疗。
「这意味着百川在选择场景时,并不是看哪个场景最好做就去做哪个。相反,百川坚持要不断上推技术能力,挑战更难的问题。」王小川讲到。
一个典型的例子是未来百川会优先做肿瘤专科的解决场景,而心理疗愈排在百川的优先级的比较靠后的位置。
在通俗观点中,普遍认为 AI 提供心理疗愈会更简单,也是一个更容易落地的场景。百川的判断逻辑则不同。他们认为肿瘤领域有更严格的科学依据。在这里,AI 更有可能做出严肃的医疗效果,从而达到或者超越人类医生的水平。相比之下,心理学领域缺乏这种确定性的科学锚点。
再比如有的公司选择给医生做分身,王小川则认为这种方向并不是百川想要做的方向。医生的分身本身不能完整复用医生的水平,更不能超越医生的水平。这样的 AI 最终只能沦为幌子和获客工具,并不能真正推动严肃医疗。
这种对严肃性的坚持,深刻影响了百川的很多商业选择。
这直接关系到王小川对医疗 AI 下个阶段根本问题的思考。他认为,当前这个阶段最重要的任务是在增强 AI 能力的基础上,逐渐提供更多的医疗供给。
中国多年来一直尝试推行分级诊疗和全科医生制度。初衷是希望老百姓先在基层看病,解决大医院挂号难、排队长、拥堵不堪的现状。
这个制度之所以推行困难,本质上是因为医疗资源的供给不足。基层医疗机构缺乏高水平的医生。大家即便只是感冒也愿意去三甲医院排队,是因为对基层的诊疗水平不放心。
这正是医疗 AI 发挥作用的关键点。大模型能够把顶尖的医学知识实现规模化分发。它填补了基层的供给缺口,让每一个社区、每一个家庭都能拥有像三甲医院专家一样的诊疗能力。
而长远来开,这还能有更广泛的影响,可能让医疗的让决策权从医生手中逐渐转移到用户身上。在传统的医疗场景中,患者是利益的受益方,但往往没有决策权。决策权集中在医生手中。这种权力的不对称往往会带来沟通成本和治疗中的痛苦。
而百川希望通过 AI,让患者能够更容易地获得优质医疗资源的供给。「很多人觉得医疗太复杂了,患者是永远理解不了的。但我们想的在美国的司法体系里面有个叫陪审团制度。法律也是非常专业的一个事,陪审团的普通人不懂,那就要求在法官、律师和检察官能够进行带领,做充分的辩论,把话说清楚,说到一个普通人能判断有罪没罪的程度,让普通人能依据逻辑正常判断即可。」王小川讲到。
这也是百川智能不愿意只做简单场景,而是希望不断向高难度的严肃诊疗推进的原因之一。
当被问到解决高难度问题是否在商业上最有回报时,王小川给出了深刻的回答。
他认为,解决感冒发烧这类小问题,很难在用户心中建立起足够的信任。医疗是一个高度依赖信任的行业。只有当 AI 能够解决重疾等高难度难题时,才能真正建立起信任的基础。
从商业逻辑上看,患者面对严肃的健康问题时,也更有意愿为高质量的 AI 服务付费。这种信任不仅是商业回报的前提,更是 AI 医疗能够规模化应用的核心。
而从更根本的意义上讲,医疗对于百川智能和王小川本人而言,仍然意味着是一条接近通用人工智能(AGI)的路径。
王小川认为,AI 目前在文、理、工、艺等领域都已找到了切实的解法,医疗则是一个极为独特的领域。人类对医学的探索尚未穷尽,AI 在这一领域也正处于摸索阶段。
百川的路线图非常清晰。首先通过 AI 提升诊病效率,解决当前医疗供给短缺的问题。在此基础上,百川致力于建立与患者之间的深度信任。当患者愿意使用 AI 工具,长期进行医疗咨询,AI 就能在长期的陪伴中积累真实且高质量的医疗数据。
这些数据的终极目标是构建生命的数学模型。这是一条人类医生至今尚未完全走通的道路,未来很有可能由 AI 率先实现。如果能完成对生命本质的建模,这将成为推动通用人工智能迈向更高阶进步的关键一步。