Bayangkan skenario ini:
Seorang lansia yang tinggal sendiri jatuh di ruang tamu, rasa sakit membuatnya tidak bisa meminta tolong. Saat itu, perangkat pintar yang dikenakannya atau kamera di rumah "melihat" kejadian tidak normal itu. Tanpa menunggu perintah suara apa pun, AI langsung mengeluarkan peringatan dan dengan cepat menghubungi keluarga atau pusat darurat.
Atau, Anda sedang menonton pertandingan sepak bola yang seru, saat terjadi gol kunci dalam sekejap, Anda tidak sempat mengulang dan bertanya, kacamata AI otomatis memberikan analisis gerak lambat dan penjelasan taktik untuk Anda.
Skenario-skenario ini bukan lagi khayalan masa depan, melainkan adalah proposisi nyata yang dicoba dipecahkan oleh model interaksi visual-bahasa global pertama yang sepenuhnya open-source di seluruh stack yang baru diopen source-kan oleh JD.com, JoyAI-VL-Interaction.

Dua tahun terakhir, batas kemampuan model besar terus diperluas, tetapi cara interaksi utama masih terjebak pada logika "giliran" yaitu "pengguna bertanya, model menjawab". Ini efisien, tetapi dalam banyak skenario tidak masuk akal. Banyak peristiwa penting terjadi terlalu cepat, pengguna tidak sempat bertanya; banyak skenario juga sama sekali tidak memiliki perintah suara.
Tahun ini, sebuah penilaian sedang menjadi konsensus industri: AI sedang bergerak dari "memprediksi token berikutnya", menuju "memprediksi keadaan fisik berikutnya". Ini juga berarti, AI harus berevolusi dari pemroses informasi pasif menjadi partisipan aktif.
Persis di momen inilah, JD.com mengopen source-kan JoyAI-VL-Interaction, model interaksi visual-bahasa real-time global pertama yang sepenuhnya open-source di seluruh stack, yang mampu menilai secara mandiri kapan harus merespons, kapan harus diam, dan kapan harus menyerahkan tugas kompleks ke model backend dalam aliran video yang berkelanjutan.
JoyAI-VL-Interaction ingin membuktikan: AI yang benar-benar memasuki dunia fisik tidak seharusnya terus menunggu untuk ditanya, ia harus belajar melihat, menilai secara aktif, dan memberikan bantuan pada momen yang tepat.
Ini juga adalah sinyal yang lebih besar yang dilepaskan oleh AI JD.com: dari kemampuan model ke skenario industri, kompetisi AI sedang bergerak dari tanya jawab di dalam layar, menuju dunia nyata.
Mengapa Interaksi Visual-Bahasa?
Di dunia fisik yang nyata, sejumlah besar informasi kunci terjadi pada momen di mana pengguna tidak sempat bertanya. Perasaan "tidak sempat" ini, kadang-kadang adalah masalah pengalaman, lebih sering adalah batas kemampuan yang disebabkan oleh paradigma model.
Industri bukan tidak menyadari keterbatasan ini.
Pada paruh pertama tahun 2026, interaksi real-time menjadi kata kunci paling populer untuk AI multimodal. Industri umumnya bergerak maju mengikuti dua jalur: satu adalah membuat percakapan bergiliran lebih cepat, yang lain adalah membuat panggilan suara lebih alami.
Yang pertama menekankan latensi rendah atau input/output bebas, tetapi intinya tetap "baru dijawab kalau ditanya"; yang kedua memungkinkan model untuk mendengar dan berbicara bersamaan, dapat disela kapan saja, pengalamannya lebih mendekati panggilan manusia nyata, tetapi fokusnya tetap pada skenario suara.
Masalahnya adalah, banyak perubahan di dunia nyata tidak akan berubah menjadi sebuah kalimat terlebih dahulu. Kebakaran, jatuh, kendaraan mendekat, perubahan konten layar, anomali jalur produksi, semuanya muncul dalam bentuk gambar sebelum bahasa. Jika AI hanya bisa menunggu orang berbicara, akan sulit baginya untuk benar-benar "hadir".
Yang benar-benar membuat penilaian yang sama dengan JD.com hampir bersamaan, adalah Thinking Machines Lab yang didirikan oleh Mira Murati. Pada 11 Mei, perusahaan ini mengusulkan konsep interaction models (model interaksi), dan merilis beberapa pratinjau penelitian Demo, menunjukkan bahwa paradigma respons mandiri model interaksi, dibandingkan dengan paradigma tanya-jawab tradisional, memiliki ruang imajinasi kerja sama Human-AI yang lebih besar.
Kedua tim hampir pada waktu yang sama, menyimpulkan pada arah pemikiran yang sama, itu sendiri adalah sebuah sinyal: menjadikan interaktivitas sebagai kemampuan model itu sendiri untuk diskalakan, adalah arah yang tidak dapat dihindari industri dalam beberapa tahun ke depan.
Perbedaannya adalah, JD.com menempatkan visual-bahasa pada posisi yang lebih inti, memisahkan suara menjadi I/O yang dapat dipasang, menjadikan visual-bahasa sebagai "modalitas penggerak utama" untuk pengambilan keputusan mandiri model.
Artinya, dari saat kamera dihidupkan, JoyAI-VL-Interaction akan terus "menonton" perubahan gambar dunia fisik, dan secara mandiri menilai apakah harus berbicara, apa yang harus dikatakan, dan apakah harus menyerahkan tugas.
Ini juga adalah daya imajinasi interaksi visual: dapat digunakan untuk perawatan lansia dan anak-anak, bantu tunanetra, kacamata AI, komentar pertandingan, inspeksi toko, logistik gudang, kolaborasi robot, dan skenario lainnya. Pengguna tidak perlu merangkai pertanyaan menjadi sebuah kalimat terlebih dahulu, AI sudah dapat menangkap kebutuhan dari perubahan lingkungan.
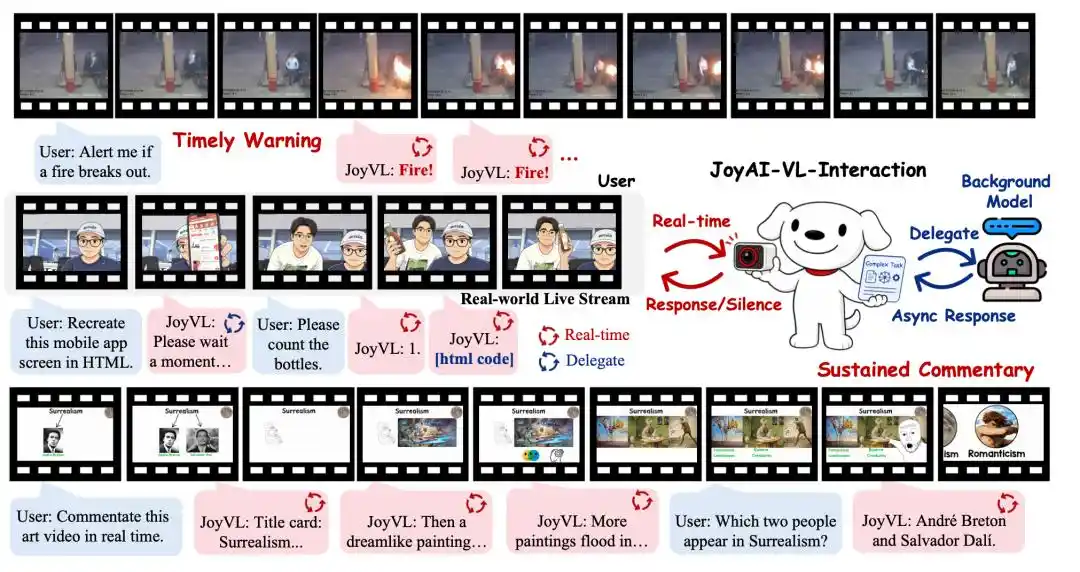
Oleh karena itu, visual bukan hanya cara input lain, melainkan saluran persepsi yang tidak tergantikan bagi AI menuju "memprediksi keadaan fisik berikutnya".
Dalam laporan teknis JoyAI-VL-Interaction JD.com juga ditegaskan, laporan menunjukkan, dalam enam skenario streaming nyata, JoyAI-VL-Interaction melawan model top domestik memiliki tingkat kemenangan 77,6%, melawan model luar negeri 87,9%; dalam skenario peringatan pemantauan yang paling menguji kemampuan penangkapan peristiwa, tingkat kemenangan mencapai 100%. Laporan berpendapat, perbedaannya tidak hanya pada kualitas jawaban, tetapi pada kemampuan untuk bertindak pada momen yang tepat.
Hanya saja, menyelesaikan interaksi visual aktif memang lebih sulit.
Pengambilan data interaksi suara relatif langsung, sejumlah besar dataset perintah suara memungkinkan model untuk mempelajari kapan manusia berbicara, bagaimana menyela, bagaimana menanggapi, data yang dibutuhkan interaksi visual sangat berbeda. Model harus belajar, dalam aliran gambar yang terus berubah, sinyal apa yang layak ditanggapi, sinyal apa yang harus diam.
Hambatan yang lebih dalam adalah kemampuan definisi skenario. Dalam skenario, interaksi suara memiliki batas pemicu alami, pengguna membuka mulut adalah awal interaksi. Interaksi visual tidak memiliki awal dan akhir yang jelas, model harus menilai batasnya sendiri dalam aliran informasi tanpa batas.
Keunikan JD.com juga ada di sini: perusahaan ini tidak mencari skenario dari laboratorium abstrak, tetapi secara alami beroperasi dalam jaringan bisnis nyata seperti ritel, logistik, kesehatan, industri, dll.
Ini berarti, AI JD.com menghadapi bukan pintu masuk obrolan tunggal, melainkan sejumlah besar tugas nyata: bagaimana barang mengalir, bagaimana perangkat berkolaborasi, bagaimana robot bekerja sama dengan manusia, bagaimana anomali ditemukan lebih awal. Model dapat belajar dalam kebutuhan nyata, beriterasi dalam umpan balik nyata.
Meskipun ada pertimbangan dalam rute teknologi, bentuk interaksi AGI umum di masa depan pasti adalah kecerdasan aktif, agen harus memiliki siklus lengkap persepsi lingkungan, pengambilan keputusan mandiri, dan respons real-time. Oleh karena itu, banyak perusahaan bukan tidak ingin membuat model besar interaksi visual, tetapi saat ini masih kurang tanah subur untuk menumbuhkan interaksi visual. Inilah mengapa modal dan daya komputasi lebih dulu mengalir ke jalur interaksi suara.
Jadi, pilihan JD.com untuk masuk dari visual bukan hanya pilihan rute teknologi, tetapi juga ditentukan oleh posisi strategisnya. Dibandingkan dengan banyak pemain model besar, JD.com lebih dekat dengan lokasi operasi dunia fisik, dan juga lebih membutuhkan AI yang mampu merasakan secara aktif dan merespons secara real-time.
Agar hari ini datang lebih cepat, perlu ada yang berangkat lebih awal.
Ringan, Open Source, Dapat Dideploy
Apa artinya global pertama yang sepenuhnya open-source di seluruh stack?
Mendefinisikan ulang paradigma interaksi terdengar megah, tetapi saat diterapkan dalam aplikasi nyata, hambatan pertama sangat sederhana: AI tidak boleh selalu mengganggu orang, juga tidak boleh diam saat harus mengingatkan.
Orang biasanya berharap AI semakin bisa berbicara semakin baik, tetapi dalam skenario interaksi visual real-time, model yang terus-menerus menyela tidaklah cerdas. Kemampuan yang benar-benar berharga adalah muncul secara aktif pada momen kritis, dan tetap diam pada momen yang tidak relevan.
Oleh karena itu, JoyAI-VL-Interaction melatih "diam" juga sebagai sebuah kemampuan. Model perlu menguasai tiga penilaian: dalam skenario apa harus merespons secara aktif, dalam skenario apa harus tetap diam, dalam skenario apa harus membagikan tugas, menyerahkannya ke model lain.
Kemampuan ini jika hanya bisa berhenti di makalah, nilainya terbatas. JD.com kali ini menekankan "sepenuhnya open-source di seluruh stack", kuncinya adalah membuka model, sistem inferensi, dan jalur pembangunan aplikasi bersama-sama, memungkinkan pengembang benar-benar dapat menjalankannya, mengubahnya, menggunakannya.
Pilihan JD.com adalah rute rekayasa yang lebih mudah menyebar: model 8B parameter, hanya dengan satu kartu grafis 3090 dapat menyelesaikan deployment. Pada parameter ini, pengembang pribadi dapat menjalankan, perangkat keras kelas konsumen dapat menanggung, perangkat ujung dapat diimplementasikan.
Untuk interaksi visual real-time, ringan seperti ini tidak berarti kemampuan menyusut, tetapi pembagian kerja lebih jelas.
JoyAI-VL-Interaction lebih seperti lapisan interaksi depan, bertanggung jawab melihat lingkungan, menilai waktu, menyelesaikan komunikasi singkat, jika bertemu tugas kompleks yang memerlukan penalaran mendalam, otomatis didistribusikan ke agen backend pilihan pengguna seperti OpenClaw, Codex, Claude Code, dll., jadi model 8B sudah cukup.
Misalnya, model dapat mengatakan kepada pengguna "Saya akan berpikir dulu", lalu menyerahkan masalah sulit ke backend, dirinya sendiri terus tetap hadir; setelah backend mengembalikan hasil, lalu menyinkronkan jawaban ke pengguna. Dalam proses ini, ia dapat terus membantu pengguna menyelesaikan interaksi instan lainnya.
JD.com juga telah merancang sistem dasar menjadi lebih ringan: melalui pengkodean video, memori jangka panjang, dan kompresi konteks, model dapat terus menonton aliran video panjang dengan biaya rendah, dan mengontrol latensi end-to-end pada tingkat sub-detik. Bagi pembaca biasa, poin utamanya bukan istilah teknis ini, tetapi hasilnya: AI dapat bertahan lebih lama, dengan ambang batas lebih rendah, di dalam skenario nyata.
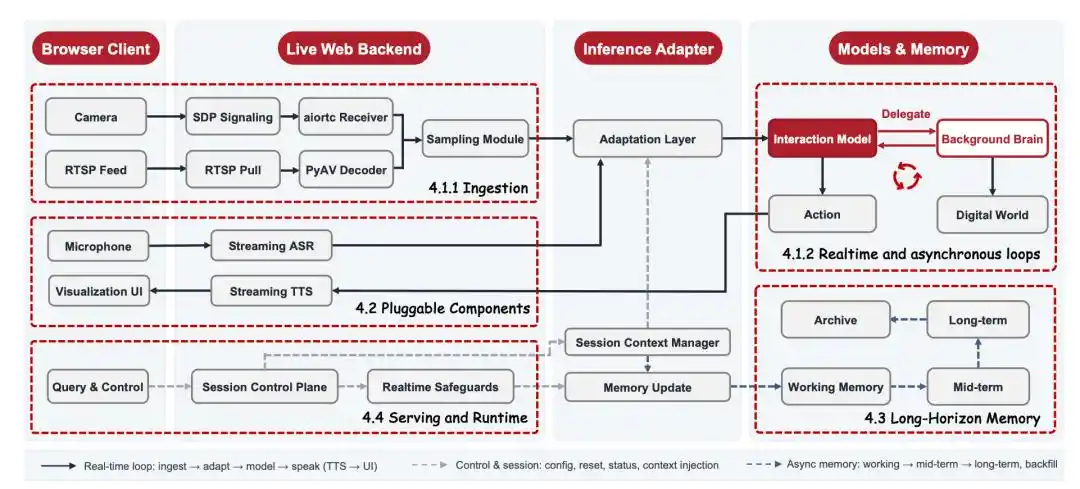
Pilihan dengan rasio biaya-kinerja tinggi, dapat diimplementasikan, juga langsung mengarah pada strategi open-source JD.com. Hanya dengan model yang cukup ringan, sistem yang cukup lengkap, ambang batas deployment yang cukup rendah, interaksi visual real-time baru mungkin berevolusi dari eksperimen tim minoritas, menjadi ekosistem aplikasi yang dieksplorasi bersama oleh lebih banyak pengembang dan perusahaan.
JD.com telah mengopen source-kan sistem inferensi ini, tujuannya jelas: memungkinkan siapa pun yang memiliki kartu grafis 3090 atau lebih tinggi dan kamera, dapat dengan cepat membangun aplikasi interaksi visual real-time miliknya sendiri.
JoyAI-VL-Interaction mendapatkan dukungan day-0 dari vLLM-Omni, telah diintegrasikan secara native ke dalam mainline vLLM-Omni.
Membawa AI Kembali ke Dunia Fisik
Tujuan open source adalah menyerahkan imajinasi aplikasi ke pasar yang lebih besar. Karena nilai terobosan teknologi pada akhirnya masih harus diuji oleh dunia nyata.
Imajinasi aplikasi pertama JoyAI-VL-Interaction sudah sangat intuitif: dalam siaran langsung pertandingan, AI dapat otomatis memberikan komentar pada saat gol kunci atau momen menentukan; saat mengawasi pergerakan saham, dapat terus mengamati perubahan layar dan mengingatkan anomali; dalam perawatan keluarga, dapat aktif memberikan peringatan saat lansia jatuh, anak mendekati area berbahaya; dipasangkan dengan kacamata AI, dapat membantu pengguna mengenali jalan, barang, layar, dan lingkungan sekitar; saat melayani tunanetra, dapat mengubah informasi visual menjadi bantuan real-time.
Bagi JD.com, yang lebih diharapkan adalah dapat diterapkan pada robot: model yang memahami kapan harus berbicara, kapan harus diam, kapan harus meminta bantuan sistem backend, dapat membuat robot lebih efisien, juga lebih mendekati asisten pintar "memiliki rasa perhitungan" yang diharapkan orang.
Alasan mendasar JD.com berani "mengaduk" bidang ini pada momen ini, adalah karena ia memegang aset data dunia fisik yang tidak dimiliki oleh pemain model besar lainnya.
Ditempatkan dalam koordinat industri tahun 2026, bobot aset data dunia fisik sangat berat.
Tahun 2026 disebut industri sebagai "tahun pertama data kecerdasan embodied", dan di bawah latar belakang yang luas, sebuah kontradiksi tajam adalah: data interaksi fisik berkualitas tinggi sangat langka, jauh tidak memenuhi kebutuhan pelatihan skala besar, hambatan iterasi algoritme secara komprehensif bergeser dari sisi model ke sisi data.
Pada momen waktu ini, JD.com mengumumkan akan mengakumulasi 10 juta jam data video skenario nyata berkualitas tinggi dalam dua tahun, mengerahkan 600.000 orang untuk berpartisipasi dalam pengumpulan.
JD.com memiliki lebih dari 3000 skenario bisnis nyata, mencakup bidang ritel, logistik, kesehatan, industri, dll., tahun ini juga telah berinovasi di Suqian dengan mode pengumpulan grid komunitas, melakukan deployment massal terminal head-mounted JoyEgoCam yang dikembangkan sendiri, mengerahkan perusahaan kecil dan menengah serta penduduk sekitar untuk mengumpulkan dalam skenario operasi nyata.
Kecepatan penataan cepat. Maret, JD.com mengumumkan membangun pusat pengumpulan data kecerdasan embodied global pertama di Suqian; April, merilis infrastruktur data embodied pertama industri yang mencakup seluruh alur pengumpulan, penyimpanan, pelabelan, pelatihan, evaluasi, simulasi, pengujian; Mei, JoyEgoCam mencapai produksi massal, terus mengumpulkan data sudut pandang pertama.
Data ini adalah bahan bakar paling langka untuk melatih model embodied dan model interaksi visual. Dengan penambahan data embodied ke dalam pelatihan, nilai JoyAI-VL-Interaction juga akan berkembang dari "model yang dapat melihat secara aktif", lebih lanjut diterapkan pada ruang fisik yang lebih konkret seperti robot, kendaraan tanpa awak, gudang, toko, dan rumah tangga.
Antara model dan aplikasi, JoyAI-Echo yang diopen source-kan JD.com pada 3 Juni juga memainkan peran kunci. Echo unggul dalam generasi real-time video panjang, Interaction unggul dalam pemahaman dan interaksi real-time, dua model diopen source-kan berturut-turut dalam satu bulan, berarti JD.com telah membuka kedua ujung input dan output multimodal video, dan menempatkan invasi AI ke dunia fisik pada posisi yang lebih jangka panjang.
Dalam konferensi pers peluncuran 618 tahun ini, JD.com mengatakan ingin menjadi "pusat operasi dunia fisik terbesar global".
Di era interaksi manusia-mesin, industri semakin memperhatikan bagaimana AI memahami dunia fisik, logika pemecahan masalah JD.com berbeda dari kebanyakan pemain model besar: perusahaan ini memang beroperasi di dalam dunia fisik.
Gudang, pengiriman, ritel, kesehatan, industri, semuanya adalah arena pelatihan dan uji coba AI dan kecerdasan embodied. Hanya logistik JD.com saja, dalam lima tahun ke depan berencana menginvestasikan 3 juta robot, 1 juta kendaraan tanpa awak, 100.000 drone, perangkat keras ini juga akan menjadi tempat penggunaan JoyAI-VL-Interaction.
Baik suara maupun visual, pada dasarnya model interaksi adalah untuk menghubungkan dunia fisik dan dunia digital, memahami dunia fisik, menjadwalkan dunia digital.
Open source, adalah jendela pertama JD.com membuka ke luar. Dalam jalur di mana permintaan mendorong teknologi ini, JD.com mengeluarkan model, data pelatihan, dan sistem lengkap bersama-sama, bertaruh pada hal yang lebih jauh: membuat interaksi aktif dari penilaian tim minoritas, menjadi jalur utama AI menuju dunia fisik.
Selamat datang untuk pengalaman menarik layanan dengan sekali klik di vLLM-Omni, atau memulai dengan sekali klik di repositori:
Alamat kode: https://github.com/jd-opensource/JoyAI-VL-Interaction
Alamat model: https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Alamat dataset: https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Alamat laporan teknis: https://huggingface.co/papers/2606.14777