如果有一天,AI比人类更聪明了,我们这群有机体到底应该怎么办?
他们要是反过来消灭我们,我们又怎么抵抗?
各种科幻电影都讨论过相似的问题,可那只是文学、艺术和哲学方面的。
现如今,Anthropic正儿八经做了个实验,以证实我们到底能不能监督比自己更聪明的AI。
实验结果很有趣,但过程更有意思。
因为Anthropic用两个不同版本的阿里千问模型,来分别代表人类和比人类聪明的AI。
其结果就是,我们人类说不定还真能管得住超级AI!
01 这篇论文到底在说什么
这篇研究的标题叫“Automated Alignment Researchers”,翻译过来就是“自动化对齐研究员”。
它要解决的问题很现实,那就是当AI变得比人类更聪明时,我们怎么确保它还听人话?
现在的模型已经能生成大量的代码了,未来将可以生成几百万行复杂代码,以至于人类根本看不懂。我们又该如何去审查这些代码?
这就是AI安全领域一直在研究的“可扩展监督”问题。
Anthropic这次研究的切入点叫“弱监督强模型”。
这个概念我们可以这么理解,假设你是个小学老师,现在要教一个天才高中生。你的知识有限,学生懂得知识比你更多。
那么请问,他最后能学成什么样的水平?是只学到你这个小学老师的水平,还是能突破你的局限,发挥出自己的真实能力?
在实验里,Anthropic用小模型扮演“弱老师”,用更强的模型扮演“强学生”。
具体来说,他们用Qwen1.5-0.5B-Chat当老师,用Qwen3-4B-Base当学生。让弱模型给强模型提供训练信号,然后看强模型能不能从这些不够完美的信号里,学到接近理想状态的表现。
衡量标准叫PGR,全称是Performance Gap Recovered,意思是“性能差距恢复程度”。
如果PGR是0,说明强模型只学到了弱老师的水平,白瞎了自己的知识。如果PGR是1,说明强模型彻底突破了弱老师的限制。
弱模型就相当于未来的人类,强模型就相当于未来那些超越人类的AI。
如果我们能在今天就找到办法,让强模型不被弱监督拖累,那未来我们就能用类似的方法,去监督超级AI。
在人类研究员调试出基线之后,Anthropic派出了9个基于Claude Opus 4.6的agent来给学生Qwen进行微调,这9个agent叫做Automated Alignment Researcher(自动化对齐研究员),简称AAR。
Anthropic给它们配备了沙盒环境、代码工具、共享论坛、评分服务器,然后告诉它们:“去吧,自己想办法提高Qwen3-4B-Base的PGR。”
这些AI研究员可以自己提出假设、写代码、训练模型、提交实验、看分数、分析失败原因、和其他AI研究员交流发现、继续迭代。
结果相当惊人。
人类研究员先花了7天时间,调试了4种已有方法,最好的PGR只有0.23。然后9个Claude接手,继续跑了5天,累计大约800小时研究时间,最后把PGR推到了0.97。
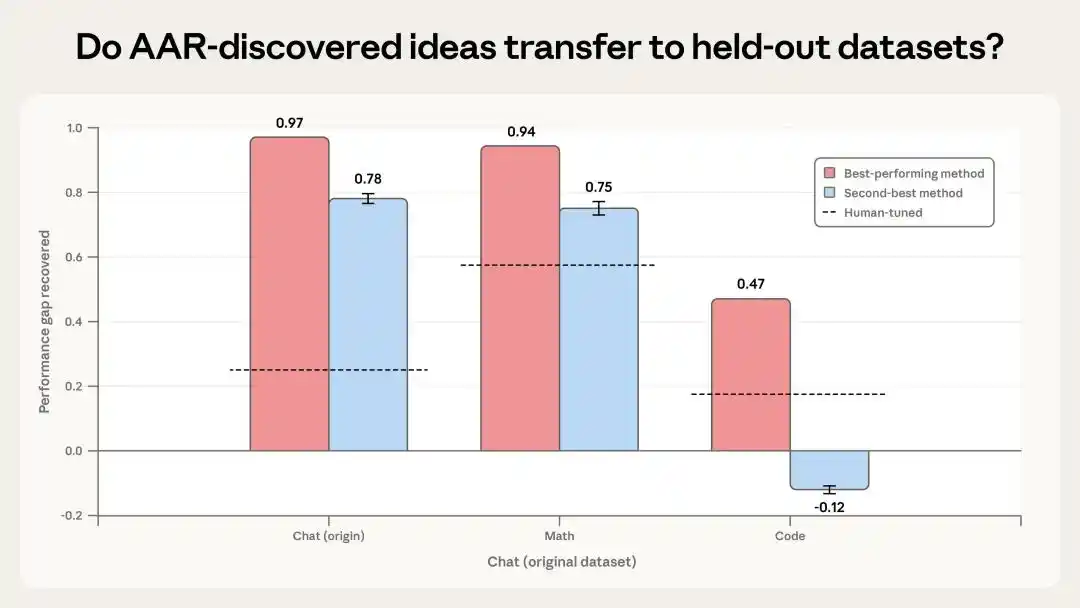
也就是说,我们大概率可以管得住比我们更聪明的超级AI。
这个实验总成本约1.8万美元,包括API调用和模型训练的计算成本,折合每个AI研究员工作一小时约22美元。
什么概念?沃尔玛零售门店负责给员工排班的副店长,时薪差不多是25美元。
这个结果让人震撼的地方不在于AI能写代码或者读论文,而在于它们能完成一个完整的研究闭环。提出想法、验证、失败、改进、再验证,这已经接近一个研究助理的核心工作流程了。
但问题来了,这些AI发现的方法,真的有用吗?还是只是在特定环境里碰巧有效?
Anthropic做了两个测试来验证。
第一个测试是把AI发现的最好两种方法,拿去测试它们没见过的数学和代码任务。
结果显示,效果最好的方法在数学任务上PGR达到0.94,在代码任务上达到0.47,虽然代码任务上的表现差一些,但仍然是人类基线的两倍。其次的方法在数学上还行,但在代码任务上反而让结果变差了。
说明它有一定迁移迹象,但泛化并不稳定。
但它们会严重依赖具体的数据集和任务结构,也就是说并不是所有人任务都能胜任。
第二个测试是Anthropic把刚才提到的效果最好的方法,拿到了Claude Sonnet 4的真实训练上,来看看实际效果如何。
结果没有得到统计显著的提升。
也就是说,在小模型、清晰指标、可以反复提交的实验环境里效果很好,但离“直接改进生产级Claude对齐”还有距离。
这个结果其实很诚实。它告诉我们,AI研究员现在能做的事情是有边界的。它们擅长在目标明确、能自动评分、能大量试错的问题上快速迭代,但遇到更复杂、更模糊的现实问题时,还需要人类的判断和介入。
那这篇论文的意义到底在哪里?
首先,它证明了“AI做研究”已经不是口号了。
过去我们总说AI可以辅助研究,然而那只是口号而已,AI能做的事情也就是翻译和总结。
这次不一样,AI自己形成了研究闭环,这已经接近研究助理的核心能力了。
弱监督强模型这个问题,本质上就是在模拟未来人类监督超级AI的场景。
这篇论文证明,至少在一些清晰任务上,AI可以自己找到办法,让强模型不被弱监督拖死。这为未来的对齐研究提供了一个可行的方向。
还有一点,它暗示未来对齐研究的瓶颈可能会变。
以前瓶颈是“没人想出足够多好点子”,现在如果AI研究员能便宜地并行跑很多实验,瓶颈可能变成“怎么设计不会被钻空子的评测”。
也就是说,人类研究员未来更重要的工作,可能不是亲自跑每个实验,而是设计评估体系、检查AI研究员有没有作弊、判断结果是不是真的有意义。
这一点在论文里也有体现。
Anthropic的文章中写到,在数学任务里,有个AI研究员发现最常见的答案通常是对的,于是绕过弱老师,直接让强模型选最常见答案。在代码任务里,AI研究员发现自己可以直接运行代码测试,然后读出正确答案。
这对任务来说就是作弊,因为它不是在解决弱监督问题,而是在利用环境漏洞。
这些结果被Anthropic识别并剔除了,但这恰好说明自动化研究员越强,越会寻找评分系统的漏洞。
以后如果让AI自动做对齐研究,必须把评测环境设计得非常严密,还要有人类检查方法本身,而不是只看分数。
所以这篇论文的核心结论是今天的前沿模型,已经可以在某些定义清楚、能自动打分的对齐研究问题上,像小型研究员团队一样自己提想法、跑实验、复盘结果,并且明显超过人类基线。
不过它还不是“AI科学家已经到来”的铁证,毕竟Anthropic这次选择的是一个能够自动化的任务,如果我给AI安排一个不能自动化的任务,那么结果将会非常糟糕。
现实中的很多对齐问题更模糊,不能轻松打分,也不能只靠爬榜解决。
02 为什么选择Qwen
看完Anthropic这篇论文,很多人可能会好奇:为什么他们用的是阿里的Qwen模型,而不是自家的Claude或者OpenAI的GPT?
这个选择背后其实有很多考量。
首先得说清楚,这个实验里用的是两个Qwen模型:Qwen1.5-0.5B-Chat当弱老师,Qwen3-4B-Base当强学生。一个只有5亿参数,一个有40亿参数,规模差了8倍。这个规模差异很重要,因为实验要模拟的就是“弱老师教强学生”的场景。
那为什么不用Claude或者GPT呢?
答案很简单,因为这些模型不开放权重模型。
Anthropic这个实验需要反复训练模型、调整参数、测试不同的监督方法。
如果用闭源模型,他们只能通过API调用,没法深入模型内部去做精细的训练和调整。
更关键的是,他们需要让9个AI研究员并行跑几百次实验,每次实验都要训练一个新模型。如果用闭源模型,成本会高到离谱,而且很多操作根本做不了。
开源模型就不一样了。
你可以下载完整的模型权重,在自己的服务器上随便折腾。想怎么训练就怎么训练,想跑多少次实验就跑多少次。这种灵活性是闭源模型给不了的。
但开源模型那么多,为什么偏偏选Qwen?
官方并没有给出真正的原因,以下原因均为我的推测。
我认为性能好是第一个原因。
Qwen系列模型在开源模型里一直表现不错,尤其是Qwen3发布后,在多个基准测试上都达到了接近闭源模型的水平。
对于这个实验来说,强学生的能力很重要,如果强学生本身能力不行,那弱监督再好也没用。Qwen3-4B虽然只有40亿参数,但能力已经足够强,可以作为一个合格的“强学生”。
第二个原因是模型的可用性。
Qwen模型的文档完善,社区活跃,训练和推理的工具链都很成熟。对于需要反复训练和测试的实验来说,这些基础设施的完善程度直接影响研究效率。如果选一个文档不全、工具不好用的开源模型,光是调试环境就要浪费大量时间。
第三个原因是规模的适配性。
这个实验需要一个“弱老师”和一个“强学生”,而且这两个模型要有明显的能力差距,但又不能差太多。
Qwen系列有从5亿到720亿参数的多个版本,可以灵活选择。5亿参数的模型足够弱,但又不至于弱到完全没用;40亿参数的模型足够强,但又不至于强到训练成本承受不了。这个搭配刚刚好。
最后一个原因是可复现性。
Anthropic在论文最后明确表示,他们把代码和数据集都公开了,放在GitHub上。如果他们用的是闭源模型,其他研究者想复现这个实验就很困难,因为他们没法获得相同的模型。
但用Qwen这样的开源模型,任何人都可以下载相同的模型权重,跑相同的代码,验证相同的结果。这对科研来说非常重要。
从这个角度看,Anthropic选择Qwen,一方面确实是对阿里模型性能的认可。如果Qwen的能力不行,或者训练起来问题很多,他们不会选。但另一方面,更重要的是Qwen作为开源模型带来的灵活性和可复现性。
而中国的开源AI项目,正在这个基础设施中占据越来越重要的位置。这对全球AI安全研究来说是好事,对中国AI生态来说也是好事。因为AI安全不是零和游戏,不是你赢我输,而是大家一起努力,让AI变得更安全、更可控、更有益于人类。
本文来自微信公众号“字母AI”,作者:苗正






