众所周知,大模型训练成本极高。
但大家又知道,降低训练精度能够显著降低训练成本。DeepSeek-V3 用 FP8 训练把成本打到了 560 万美元,已经让全行业侧目。
在 FP8 成功后,行业仍然在不断探索低精度的边界:从 FP8 降到 FP4,训练成本还能再降多少?
理论上,FP4 的计算吞吐可以是 FP8 的两倍。NVIDIA Blackwell 和 AMD MI350 系列都已经在硬件层面原生支持了 FP4 运算,前者在 B200 上标称 FP4 算力可达 4500 TOPS(稀疏)。硬件已经准备好了,但软件和算法那一侧,一直卡在一个问题上:
用 FP4 从头训练大模型,训练过程非常不稳定。
过去两年里,LLM-FP4、NVFP4 预训练等工作陆续尝试了这条路,但鲜有方案能在 4 比特精度下干净利落地跑通全流程预训练,同时保持接近 FP8 的收敛质量。
更棘手的是,崩溃的原因一直不清楚,分析认为,FP4 训练不稳定的原因很可能来自随机性不足。
但就在最近,AMD 联合宾夕法尼亚州立大学发布了一篇论文,颠覆了传统的认知,为原生 FP4 训练给出了一个全新的清晰诊断。

- 论文标题:Pretraining large language models with MXFP4 on Native FP4 Hardware
- 论文链接:https://arxiv.org/abs/2605.09825
这篇论文在 AMD Instinct MI355X GPU 上,用 MXFP4 格式完成了 Llama 3.1-8B 的全流程预训练,端到端训练速度比 FP8 基线快 9-10%,token 开销仅多 8-9%。这是目前第一个在原生 FP4 硬件(非软件模拟)上完成大模型预训练的完整实验。
更重要的是,论文揭示了核心问题:FP4 训练的不稳定性的来源不是随机性不足,是结构性微缩放误差沿敏感梯度路径累积放大。
MXFP4 是什么
在拆解论文之前,有必要先理解 MXFP4 这个数据格式。
传统的整数量化通常对整个张量使用一个缩放因子。MXFP4 的核心设计叫「微缩放」(Micro-scaling):把一个张量切成小块(比如每 32 个元素一组),为每个小块分配一个共享指数(E8M0 格式),块内的每个元素用 4 比特浮点数表示。重建公式可以写成:
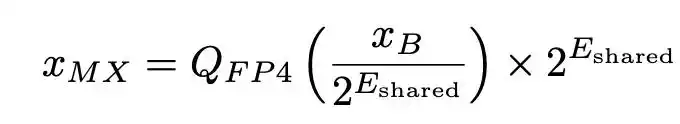
其中 E_shared 是块内最大指数,Q_FP4 是最近舍入到 4 比特浮点可表示值。
微缩放的好处在于:每个小块有自己的动态范围,不会被全局异常值「绑架」。这让 4 比特浮点数的表示质量比朴素的全局量化好很多。
但即便有了微缩放,FP4 训练依然不稳定。
排查实验:不稳定的根源
研究团队先设计了一个逐步排查的控制实验。
一次完整的 Transformer 线性层计算,涉及三个通用矩阵乘法操作:
Fprop(前向传播):计算 Y = XW^T,产出激活值
Dgrad(激活梯度):计算 ∇X = ∇Y · W,将梯度回传给输入
Wgrad(权重梯度):计算 ∇W = (∇Y)^T · X,产出用于更新权重的梯度
研究团队保持其他所有因素不变,逐步把这三个操作从 FP8 替换成 MXFP4,观察每一步对收敛的影响。所有实验都在 AMD Instinct MI355X 上用原生 FP4 tensor core 执行,不依赖软件模拟。
训练任务是 MLPerf 标准设置,在 C4 数据集上预训练 Llama 3.1-8B,收敛目标是验证集困惑度达到 3.3。
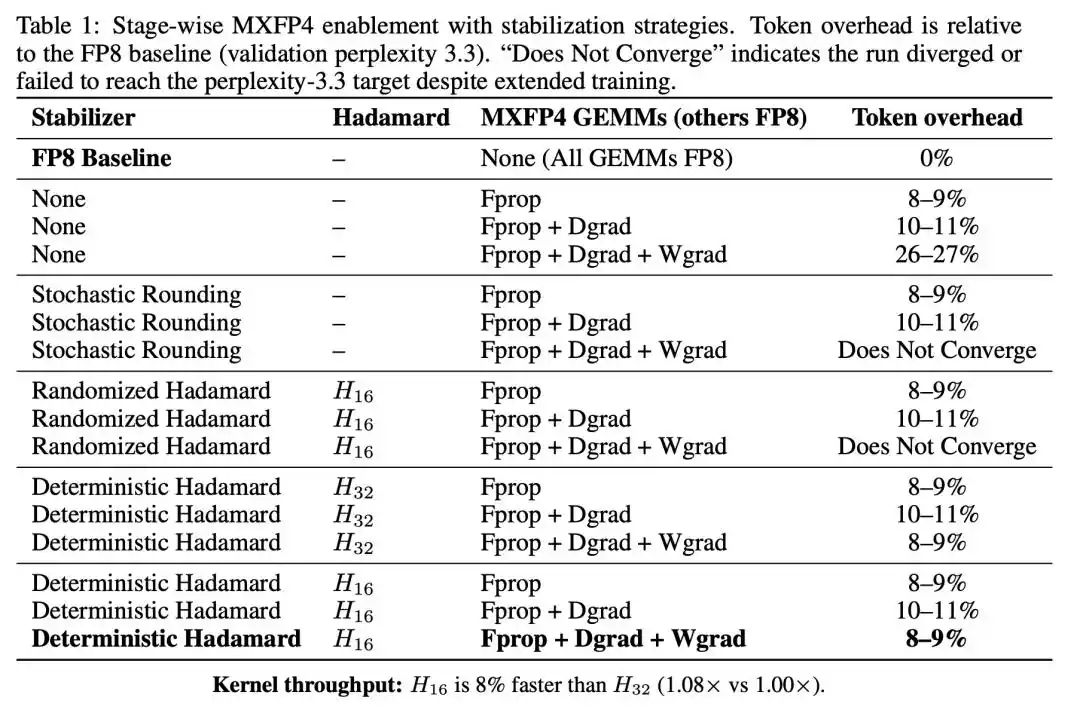
前两步只带来了温和的额外 token 开销,但一旦把 Wgrad 也换成 MXFP4,开销直接跳到 26-27%。
Wgrad 是 FP4 训练的瓶颈所在。 前向传播和激活梯度对 FP4 量化有相当的容忍度,但权重梯度一旦被量化到 4 比特,收敛质量就出现了显著退化。
业界此前的主流直觉是:FP4 量化误差本质上是噪声问题,因此可以通过注入随机性来「平滑」误差分布。两种常见策略是:
随机舍入(Stochastic Rounding):在量化时引入随机性,使舍入误差的期望值为零
随机 Hadamard 旋转(Randomized Hadamard):在量化前用带随机符号翻转的 Hadamard 变换打散数据分布
当 Wgrad 被量化后,两种随机性策略不仅没有稳定训练,反而直接导致了不收敛。随机性非但没有帮忙,还在关键的梯度路径上引入了更多有效量化误差。
相比之下,确定性 Hadamard 旋转一把将全流程 token 开销从 26-27% 压回到 8-9%,训练轨迹紧密跟踪 FP8 基线。
这是一个非常有诊断价值的结果。随机和确定性 Hadamard 旋转都是正交变换,都能打散异常值的能量分布,理论上对量化误差的缓解效果应该类似。但它们在 Wgrad 场景下的表现截然相反,这揭示了问题的本质:
FP4 训练的不稳定性,是由 MXFP4 微缩放在敏感梯度路径上产生的结构性误差驱动的。 随机性策略失败是因为它们在每一步引入了不同的误差模式(pattern),而这些变化的误差模式沿梯度路径累积,反而放大了不稳定性。确定性旋转之所以有效,恰恰因为它在每一步施加相同的变换,让误差模式保持一致,避免了误差累积。
端到端效率:训练步吞吐 +20%,综合加速 9-10%
把确定性 Hadamard 旋转加上全流程 MXFP4 之后,效率数据如下:

训练步吞吐提升了 20%,扣掉多出的 8-9% token 开销之后,端到端综合加速仍有 9-10%。
考虑到这是把精度从 8 比特直接砍到 4 比特,这个收敛质量和加速幅度都相当可观。
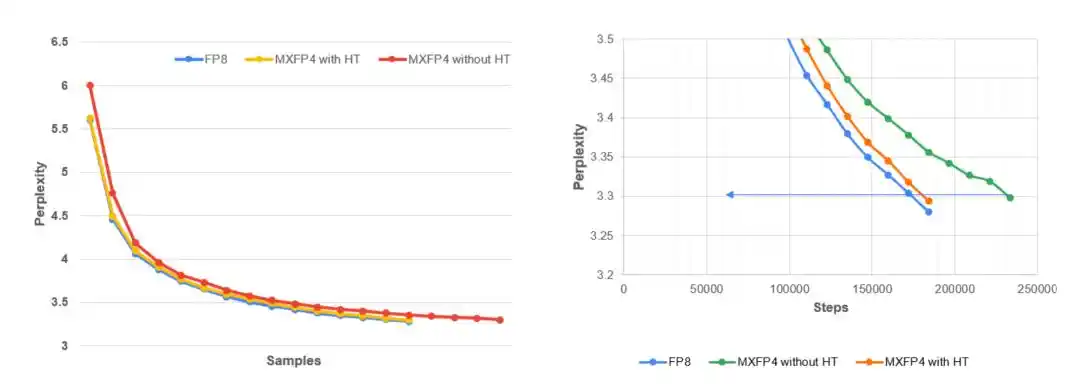
左图:在 C4 数据集上进行 MLPerf 预训练时,Llama 3.1–8B 的验证困惑度随训练 token 数变化的曲线。结果显示,MXFP4 + 确定性 Hadamard 与 FP8 的表现非常接近,而未进行稳定化处理的全流程 MXFP4 收敛速度更慢,训练稳定性也更差。右图:训练后期的局部放大视图。MLPerf 的目标困惑度为 3.3。与未稳定化的 MXFP4 运行相比,确定性 Hadamard(H16)能够与 FP8 基线保持更紧密的一致性。
值得注意的是,作者在论文中明确强调了一项重要限制:这套 FP4 训练方案(MLPerf C4 数据集 + Llama 3.1-8B)的效果已经得到验证,但不能直接假设它能无缝迁移到所有模型、所有数据集和所有训练方法。FP4 训练的行为可能是高度设置依赖的,具体的稳定策略需要根据场景重新验证。
结语
把这篇论文放到更大的产业脉络里,至少有三层意义。
第一层:它回答了一个根本性的「为什么」。 过去的 FP4 训练工作大多聚焦于「怎么让它不崩」,这篇论文第一次给出了清晰的因果诊断:崩溃源于 Wgrad 路径上的结构性微缩放误差,而非随机性不足。这个诊断本身就具有方法论价值,它告诉后续研究者:在低精度训练中遇到不稳定性时,应该优先排查结构性误差源,而非盲目增加随机性。
第二层:它把 FP4 从「推理专属」推向了「训练可用」。此前行业共识是 FP4 只适合推理量化,训练至少要用 FP8。NVIDIA 在 Blackwell 上主推 FP4 推理而非训练,也反映了这一判断。这篇论文在原生 FP4 硬件上跑通了全流程预训练,意味着 MI355X 和 Blackwell 上那些为推理准备的 FP4 算力,理论上也可以用来训练。如果 FP4 训练在更大模型和更多场景上被验证可行,等于现有硬件的可用训练算力直接翻倍。
第三层:它使用了 OCP 开放标准。 MXFP4 是 OCP Microscaling 格式标准的一部分,背后有 AMD、NVIDIA、Intel、Meta、Microsoft、Arm、Qualcomm 七家公司联合支持。基于开放标准意味着这套方法在不同厂商的硬件上都有可移植性,不会被锁定在单一生态里。
从 FP16 到 FP8,DeepSeek-V3 已经证明精度减半可以大幅降低训练成本。从 FP8 到 FP4,这篇论文迈出了关键的第一步。精度每砍一刀,整个大模型训练的经济性都在发生转变。
本文来自微信公众号 “机器之心”(ID:almosthuman2014),编辑:冷猫








