Недавно компания Anthropic опубликовала статью под названием «Когда ИИ строит себя» (When AI Builds Itself), которая быстро вызвала широкое обсуждение. В статье раскрываются поразительные внутренние данные: по состоянию на май 2026 года более 80% кодовой базы Anthropic было написано Claude, а объем кода, ежедневно объединяемого инженерами, в 8 раз превышает уровень 2024 года; в одном из внутренних тестов Claude ускорил выполнение одного фрагмента тренировочного кода примерно в 52 раза по сравнению с базовым уровнем, тогда как опытному исследователю-человеку обычно требуется от 4 до 8 часов, чтобы добиться ускорения в 4 раза.
Anthropic направляет этот путь к более глубокой цели: «рекурсивное самоулучшение» — системы ИИ самостоятельно проектируют, строят и обучают свои последующие версии, человек больше не управляет каждым шагом. Примечательно, что компания также призвала к координации в отрасли, чтобы в момент наступления рекурсивного самоулучшения иметь возможность приостановить или даже временно остановить разработку передовых ИИ. И Anthropic уже делает это: ограничивает использование последней Claude Fable 5 для разработки передовых ИИ.
А теперь Recursive Superintelligence объявляет о том, что сделала первый шаг к автоматизации исследований ИИ.
Эта новая компания, соучредителем которой является Тянь Юаньдун, вышла из режима скрытого существования всего месяц назад, и уже представила свой первый публичный технологический результат. Они создали открытую систему автоматического открытия знаний и достигли результатов SOTA на трех эталонных тестах. Проще говоря, им удалось заставить ИИ проводить эксперименты за вас.

https://x.com/tydsh/status/2065062838255649082
Первый результат: заставить ИИ проводить эксперименты за вас
Первый публичный технологический результат Recursive называется «Первый шаг к автоматизированным исследованиям ИИ» (First Steps Toward Automated AI Research).

Твит: https://x.com/Recursive_SI/status/2064980090702962699
Репозиторий: https://github.com/recursive-org/first-steps-toward-automated-ai-research
Блог: https://www.recursive.com/articles/first-steps-toward-automated-ai-research
Если описать одной фразой, суть этой работы такова: создана система, способная автономно продвигать исследовательский цикл ИИ, и она обновила лучшие результаты на трех эталонных тестах.
Прежде чем детально разбирать результат, необходимо понять логику проектирования этой системы.
Традиционный процесс исследования ИИ представляет собой высокозависимый от человека замкнутый цикл «генерировать идеи — писать код — проводить эксперименты — анализировать результаты — снова генерировать идеи». Его узкое место — не в вычислительных мощностях, а в человеке. Во всем мире есть лишь единицы исследователей, способных проектировать передовые тренировочные процессы, и каждая итерация эксперимента требует их активного участия.
Система Recursive пытается автоматизировать этот замкнутый цикл.
Она работает следующим образом: для четко определенной цели оптимизации система автоматически генерирует идеи экспериментов, реализует код, запускает проверку, извлекает из этого знания и затем решает, как продолжать поиск. Несколько исследовательских направлений могут продвигаться параллельно, эффективные находки могут быть повторно использованы в разных задачах, а механизмы обнаружения «взлома вознаграждения» (reward hacking) встроены во весь цикл, чтобы предотвратить «использование лазеек» системой для накрутки метрик оценки без реального улучшения чего-либо.
Это не специализированный инструмент, настроенный для единственной проблемы, а универсальная инфраструктура для автоматизации исследований в разных областях. Recursive продемонстрировала это на трех значительно различающихся тестовых сценариях.
Три поля битвы, три новых рекорда
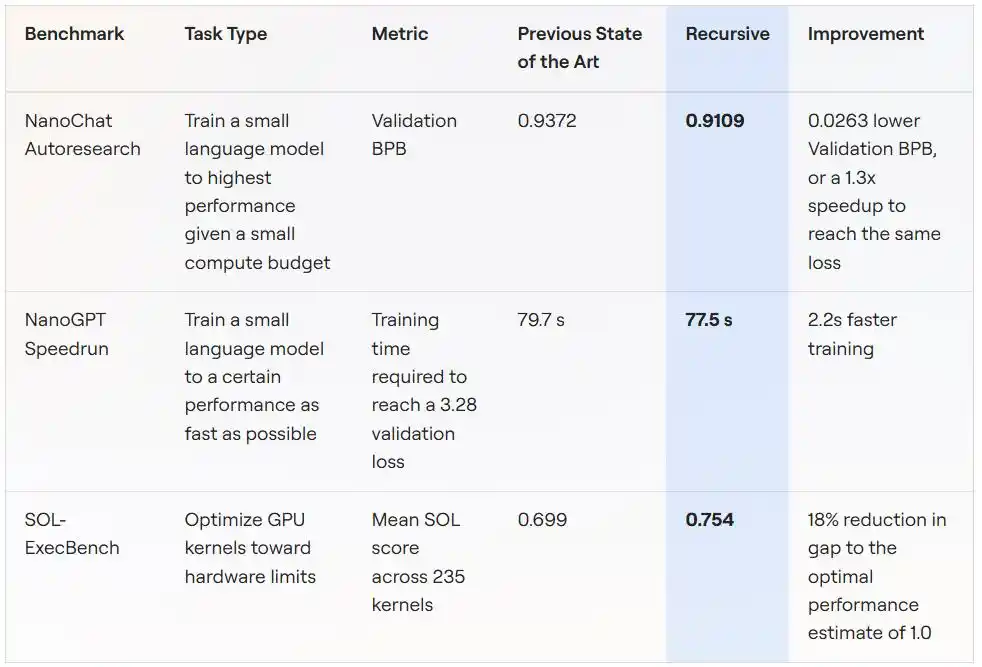
Сценарий 1: Обучение небольшой модели с фиксированным вычислительным бюджетом (NanoChat Autoresearch)
Правила этого эталонного теста взяты из проекта autoresearch, запущенного Андреем Карпати (автором GPT-2, соучредителем OpenAI): на одном GPU с фиксированным пятиминутным бюджетом на обучение обучить небольшую языковую модель до минимальной потерь валидации (измеряется в BPB, чем ниже, тем лучше).
Этот сценарий естественно подходит для автоматизированных исследований: короткий цикл экспериментов, низкая дисперсия метрики, относительно легко обнаружить мошенничество. Именно поэтому сообщественный проект под названием «autoresearch@home» уже давно работает над этим эталоном — десятки исследователей-людей и сотни агентов ИИ сотрудничают, постоянно улучшая показатель.
Система Recursive, стартовав с того же исходного кода, в конечном итоге улучшила значение BPB валидации с лучшего общественного показателя 0.9372 до 0.9109, снизив на 0.0263 BPB. Иначе говоря: для достижения того же качества обучения, решение Recursive требует в 1.3 раза меньше времени обучения, чем у конкурента.
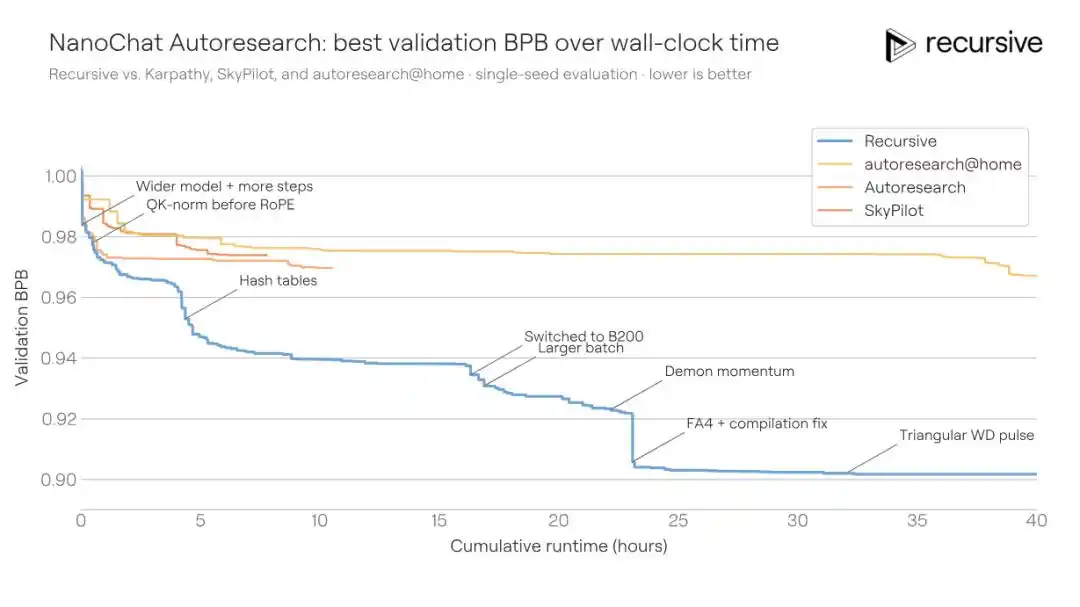
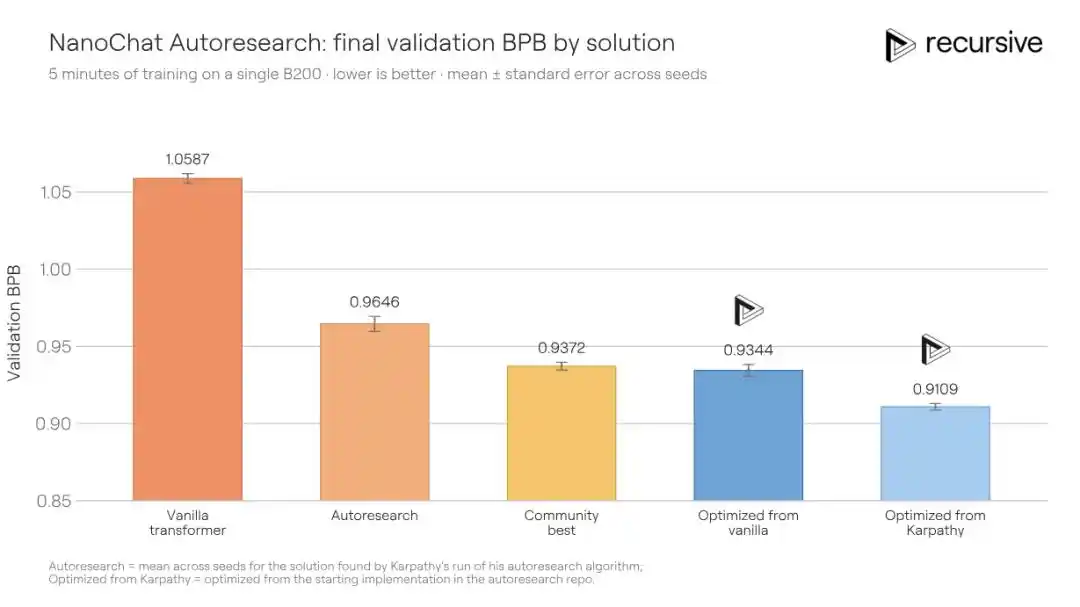
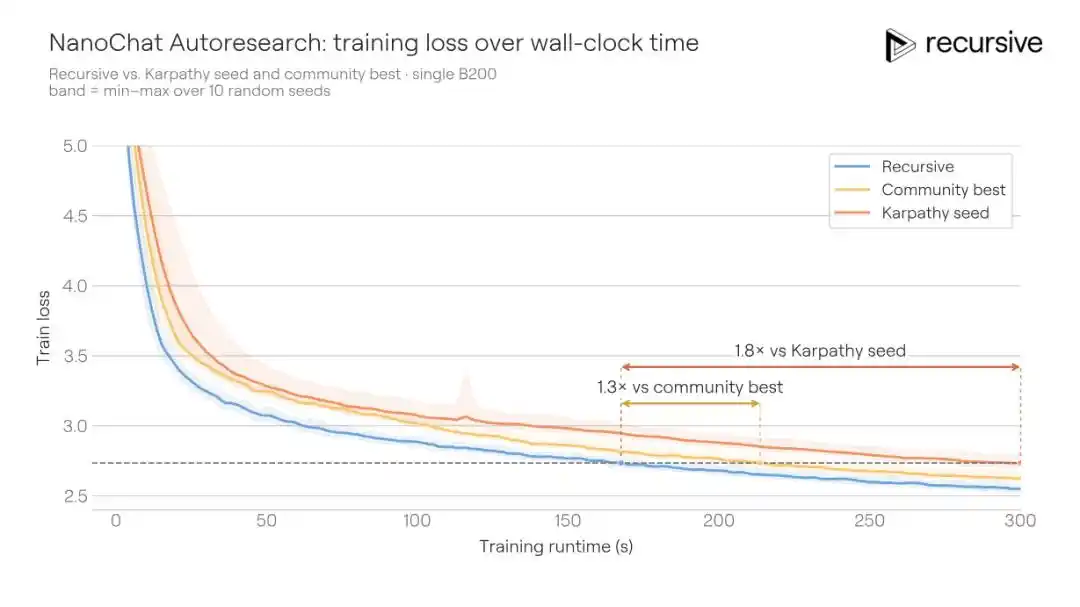
Улучшения, найденные системой, не были единичным трюком. Она скомбинировала изменения в архитектуре, вспомогательных функциях потерь, механизме внимания, поведении оптимизатора, графике затухания весов, настройках компилятора и многое другое. Ключевым открытием стал более богатый механизм памяти для короткого контекста: в value-пути механизма внимания с помощью хэш-таблицы одновременно встраивается информация о биграммах (пары соседних слов) и триграммах (тройки), а также используется обучаемый гейтинг для взвешенного смешивания. Разные слои Transformer используют разные хэш-функции, что снижает вероятность межслойных коллизий.
Эта техника концептуально связана с такими работами, как DeepSeek Engram, но система развернула ее в определенном варианте, ранее не встречавшемся в публичной литературе, в сценарии с фиксированным бюджетом.
Сценарий 2: Скоростное обучение на пределе (NanoGPT Speedrun)
Если предыдущий сценарий — это «шаг вперед» на основе результатов активного сообщества, то этот значительно сложнее.
NanoGPT Speedrun — еще один эталон, запущенный Карпати и оптимизируемый сообществом более двух лет: минимальное время, необходимое для обучения модели GPT до потерь валидации 3.28 на 8 GPU H100. С середины 2024 года сообщество за 83 задокументированных вклада сократило время с примерно 45 минут до 79.7 секунд. Каждое новое решение требует выжать время из уже предельно оптимизированного кода, что чрезвычайно сложно.
Система Recursive, начав с существующего оптимального решения, снова сократила время обучения до 77.5 секунд, сэкономив 2.2 секунды. Это сопоставимо с улучшениями, которые недавно могли делать человеческие участники, или даже лучше.
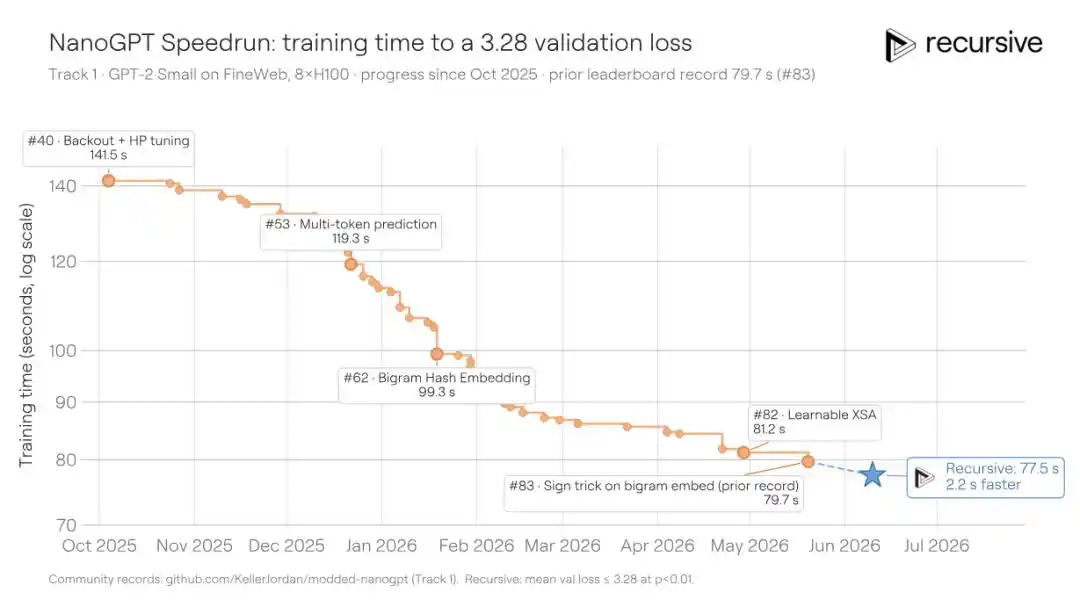
Основные техники, найденные системой на этот раз, включают:
Вычисления внимания с точностью FP8. Решение сообщества использовало FP8 (8-битное число с плавающей запятой) только в последнем слое модели (языковой головке), а система расширила использование FP8 на матричные операции в слоях внимания: прямое распространение использует FP8 для удвоенной пропускной способности Tensor Core, обратное распространение сохраняет BF16 для стабильности.
Отжигаемый исследовательский шум в оптимизаторе. Система внедрила в шаги обновления оптимизатора NorMuon гауссовский шум с нулевым средним, амплитуда которого линейно уменьшается до нуля по ходу обучения. Это похоже на придание оптимизатору режима поведения «сначала смелое исследование, потом уверенная сходимость», помогающего конечному решению оказаться в более плоском минимуме функции потерь.
Более лаконильное слитное MLP-ядро. Система переписала ядро для GPU на Triton, так что прямое распространение сохраняет только значения активации после возведения ReLU в квадрат, а обратное распространение пересчитывает промежуточные результаты (без возведения в квадрат) внутри ядра, экономя на одной полной пересылке тензора активаций между высокоскоростной памятью GPU — это прямое аппаратное ускорение.
Три улучшения относятся к трем различным профессиональным областям: стратегии точности, проектированию оптимизаторов, программированию GPU-ядер. То, что система нашла пространство для улучшения после двух лет оптимизации сообществом, само по себе говорит о многом.
Сценарий 3: Оптимизация GPU-ядер (SOL-ExecBench)
Первые два сценария работали на уровне обучения моделей, третий же углубляется на более низкий уровень: оптимизация GPU-вычислительных ядер.
SOL-ExecBench — это эталонный тест, представленный NVIDIA, содержащий 235 задач написания ядер, охватывающих такие реальные нагрузки, как матричное умножение, редукция, слои нормализации, компоненты внимания, процедуры квантизации, слитые блоки и др. Критерий оценки — SOL-балл: 0.5 соответствует базовой реализации PyTorch, 1.0 — теоретическому аппаратному пределу. Предыдущий лучший публичный результат составлял 0.699.
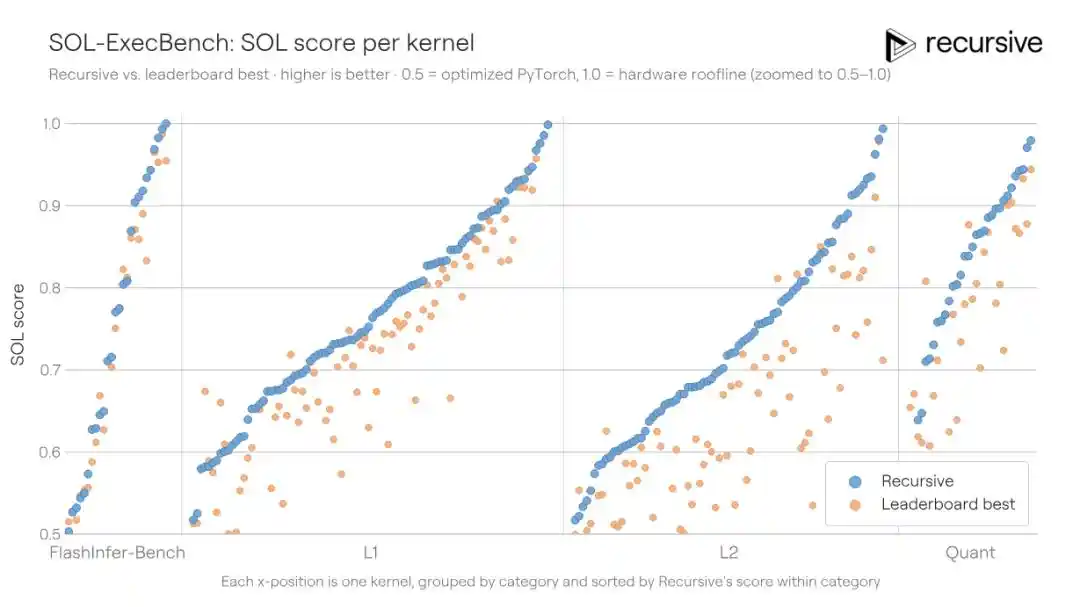
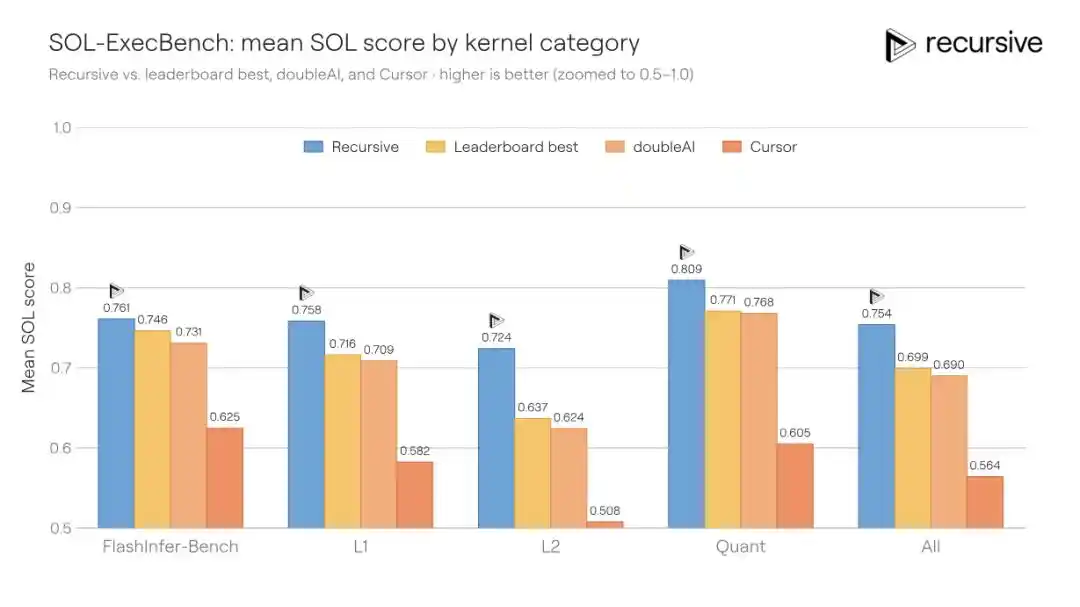
Система Recursive работала со всеми 235 ядрами, позволяя повторно использовать найденные паттерны оптимизации (например, стратегии работы с памятью, способы разбиения на блоки, техники редукции) между задачами, и в итоге повысила общий балл до 0.754, сократив разрыв с аппаратным пределом на 18%.
Этот сценарий особенный, потому что ядерная инженерия — область чрезвычайно высокой специализации — инженеров, способных писать эффективные ядра на Triton/CUDA, во всем мире единицы. Команда Recursive в блоге призналась, что они сами не являются экспертами в области ядер: «Эти идеи пришли от самой системы, а не от нашего профессионального опыта.»
Recursive: использование ИИ для рекурсивного улучшения ИИ
Компания Recursive Superintelligence, опубликовавшая этот результат, была основана в конце 2025 — начале 2026 года, вышла из режима скрытого существования в прошлом месяце. Основатели, помимо бывшего директора по научным исследованиям в Meta FAIR Тянь Юаньдуна, также включают:
Ричард Сохер, CEO Recursive, бывший главный научный сотрудник Salesforce
Алексей Досовицкий, бывший научный сотрудник Google DeepMind и первый автор Vision Transformer, более 160 000 цитирований в Google Scholar
Тим Роктэшель, бывший Principal Scientist в DeepMind и профессор ИИ в UCL
Питер Норвиг, бывший директор по исследованиям Google, соавтор (вместе со Стюартом Расселом) известного учебника по ИИ «Искусственный интеллект: современный подход»
Цаймин Сюн, бывший вице-президент по ИИ в Salesforce
Тим Ши, бывший исследователь OpenAI, соучредитель и CTO компании корпоративного ИИ Cresta
Джош Тобин, CTO Recursive, бывший руководитель исследований в OpenAI и Uber ATG
Джефф Клун, бывший вице-президент по исследованиям в Google DeepMind, профессор компьютерных наук в Университете Британской Колумбии, Канада
И эта стартап-компания, даже не имея публичного продукта, уже привлекла финансирование в размере 6.5 миллиардов долларов при оценке в 46.5 миллиардов долларов. Раунд возглавили GV (Google Ventures) и Greycroft, с участием NVIDIA и AMD Ventures.
Основная миссия компании прямо соответствует ее названию: создание систем ИИ, способных рекурсивно улучшать собственные исследовательские способности, чтобы ИИ участвовал и ускорял сам процесс разработки ИИ, в конечном итоге формируя замкнутый цикл непрерывного самоусиления.
Подробнее см. в репортаже «После ухода из Meta, Тянь Юаньдун только что официально объявил о запуске стартапа».
Конечно, на треке Recursive не одинока. AMI Labs Янна Лекуна привлекли финансирование в размере 10 миллиардов долларов в марте этого года, а Ineffable Intelligence Дэвида Сильвера в апреле получили начальное финансирование в 11 миллиардов долларов — оба указывают в схожем направлении: дать системам ИИ возможность автономно генерировать знания, уменьшая участие человека в исследовательском процессе. Но по темпу представления публичных результатов, этот «первый шаг» Recursive, вероятно, на данный момент является одной из самых конкретных и воспроизводимых технических демонстраций среди подобных компаний.
Рассвет рекурсивной парадигмы
Публикация этого результата Recursive, в более широком контексте отрасли, представляет собой первоначальную реализацию новой парадигмы разработки ИИ: системы ИИ сами берут на себя роль субъекта исследования.
Логика такого «рекурсивного ИИ» не сложна: ИИ улучшает исследовательские способности ИИ, а улучшенный ИИ, в свою очередь, может более эффективно улучшать себя, и так по кругу. Он не зависит от единичного прорыва, а зависит от системы, непрерывно генерирующей прорывы.
Такой подход имеет важное значение для экономики самих исследований ИИ. Тренировочные процессы передовых моделей по-прежнему в высокой степени зависят от небольшого числа исследователей, обладающих специфическими навыками, и во всем мире таких людей не более нескольких тысяч. Если системы автоматизации исследований смогут взять на себя хотя бы часть этой работы, кривые скорости прогресса ИИ и затрат изменятся.
Это суждение перекликается с другими недавними высказываниями в отрасли. Например, упомянутая в начале статьи работа Anthropic «Когда ИИ строит себя», звучит нелегко — она призывает к координации в отрасли, чтобы в момент наступления рекурсивного самоулучшения иметь возможность приостановить или даже временно остановить разработку передовых ИИ, чтобы дать время социальным структурам и исследованиям по согласованию догнать темп. Подробнее см. «Слишком быстрая самоэволюция ИИ: Anthropic призывает к глобальной приостановке разработки».

https://www.anthropic.com/institute/recursive-self-improvement
Два события, происходящих одновременно, заставляют задуматься. С одной стороны, Anthropic документирует и предупреждает о направлении этого пути, с другой — такие команды, как Recursive, шаг за шагом превращают этот путь в реальность.
Конечно, Recursive сама признает, что это все еще «первый шаг»: текущая система лучше всего работает в сценариях с четкими метриками, быстрой обратной связью и обнаруживаемым мошенничеством; до автономного продвижения открытых научных вопросов еще далеко. Борьба с «взломом вознаграждения» останется ключевой проблемой на пути к масштабированию.
Но замкнутый цикл уже запущен. Остается лишь вопрос, как быстро он будет вращаться.
Эта статья взята с официального аккаунта WeChat «Сердце машины» (ID: almosthuman2014), автор: рекурсивно эволюционирующее Сердце машины, редактор: Panda








