Сохранение не равно владению, выделение не равно пониманию.
Те глубокие статьи, что волновали вас в два часа ночи, те переплетенные двусторонние ссылки, вытянутые в Obsidian, те аккуратно отформатированные базы данных в Notion — все это «кибер-мумии», лежащие в приложениях для заметок.
Графы кажутся впечатляющими, но на самом деле они давно прогнили.
Это системный провал всей эпохи информационной перегрузки.
Нынешний инженер Anthropic, бывший соучредитель OpenAI, бывший директор по ИИ Tesla — Карпати, не выдержал и бросил бомбу.

Портал: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Он не анонсировал новую модель, не выпустил новый фреймворк, он просто сказал: Считайте свои заметки неизменяемым исходным кодом, а LLM — компилятором.
Прошло два месяца, и этот документ уже вызвал тихую, но сильную миграцию в сообществах Obsidian, Claude и Cursor.
Некоторые уже расширили свою вики до сотен страниц и сотен тысяч слов.
Появились автоматизированные плагины. Исследователи, независимые предприниматели, вечные ученики коллективно переходят к новому способу организации знаний.
Закат RAG, перемещение информации не спасет ваши мысли
До появления LLM-WIKI основным решением был RAG (Retrieval-Augmented Generation — извлечение с расширением генерации).
Проще говоря, это снабжение большой модели «искателем»: когда вы задаете вопрос, она ищет в ваших заметках несколько фрагментов, а затем составляет из них ответ.
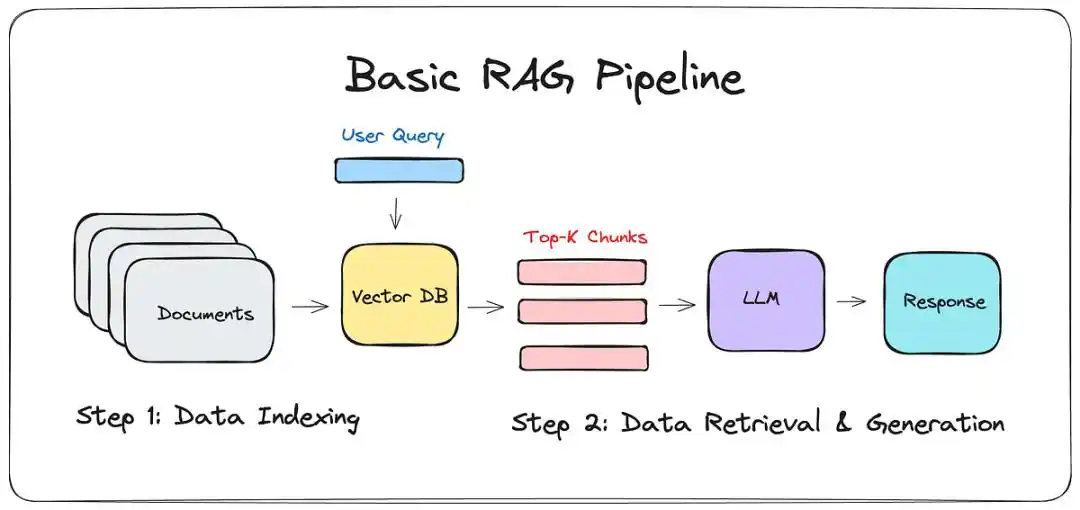
Звучит красиво, но те, кто пробовал, знают разрыв между «показом продавца» и «покупкой».
Это просто грузчик: RAG работает только локально, не понимая общей картины.
Он может сказать вам, что в 5-й заметке упоминается A, но не может раскрыть основную логику, на которую указывают все 500 заметок вместе.
У него «раздвоение личности»: Если полгода назад вы считали A верным, а вчера написали заметку, опровергающую A, RAG часто впадает в противоречие, выдавая бессвязную чушь.
Гниение графов: Ручное поддержание связей между знаниями — как код без функции автоматической очистки. Со временем повсюду появляются мертвые ссылки, эффективность поиска падает экспоненциально.
Интуиция Карпати очень остра: поиск и извлечение — проявление человеческой несостоятельности. Нам нужно «согласие», «структура», «истина».
Рассматривайте знания как исходный код, а LLM — как компилятор
Ответ Карпати пришел от действия, которое программисты делают каждый день, но никогда не задумывались применить его к знаниям: компиляция.
Написав исходный код, вы не перечитываете его каждый раз при запуске программы.
Вы компилируете его в бинарный файл, компиляция требует усилий один раз, но затем каждый запуск происходит молниеносно. Стоимость компиляции распределяется на тысячи последующих использований.
Почему знания нельзя обрабатывать так же?
Карпати говорит: считайте свои исходные заметки неизменяемым исходным кодом, LLM — компилятором, и пусть он «скомпилирует» эту кучу разнородных материалов разово в структурированную, взаимосвязанную вики.
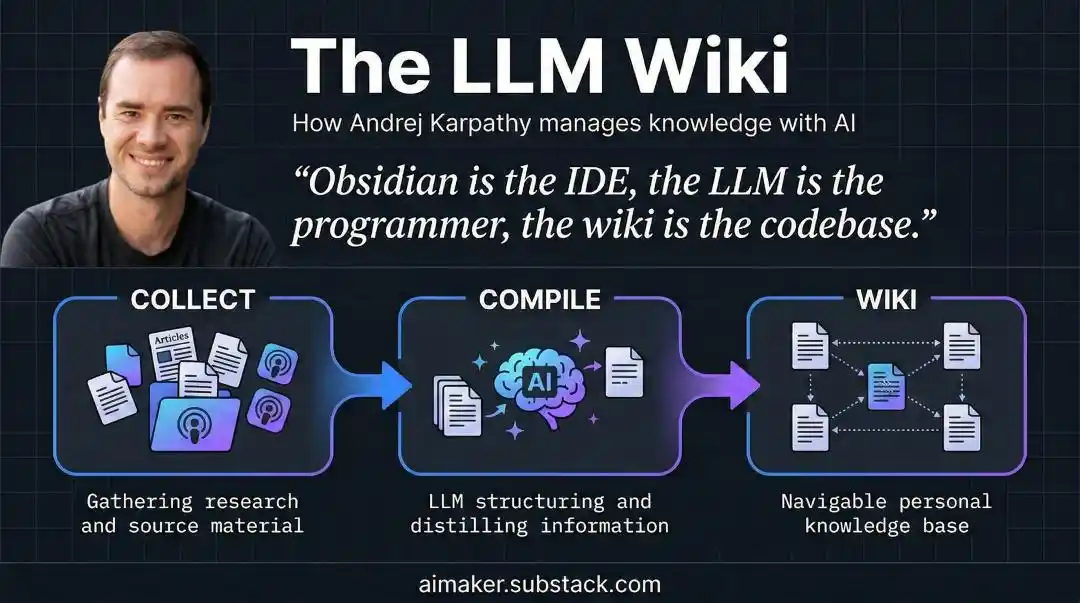
При добавлении нового материала ИИ проводит слияние: обновляет связанные страницы, пересматривает обзоры, отмечает места, где новые данные противоречат старым выводам, и попутно укрепляет или ставит под сомнение существующие суждения.
Ключевая разница здесь: Знания компилируются один раз, а затем остаются свежими, а не перестраиваются заново при каждом запросе.
Когда вы задаете вопрос, перекрестные ссылки уже есть, противоречия уже отмечены, обзоры уже отражают все, что вы прочитали.
Вы же не перекомпилируете исходный код каждый раз при запуске программы. Так почему же при каждом вопросе нужно заставлять ИИ перечитывать ваши заметки?
Фундаментальный сдвиг в когнитивных производственных отношениях
В его системе LLM-WIKI заметки перестают быть мертвым текстом, становясь «исходным кодом».
Большая модель больше не переводчик, листающий словарь, а «компилятор».
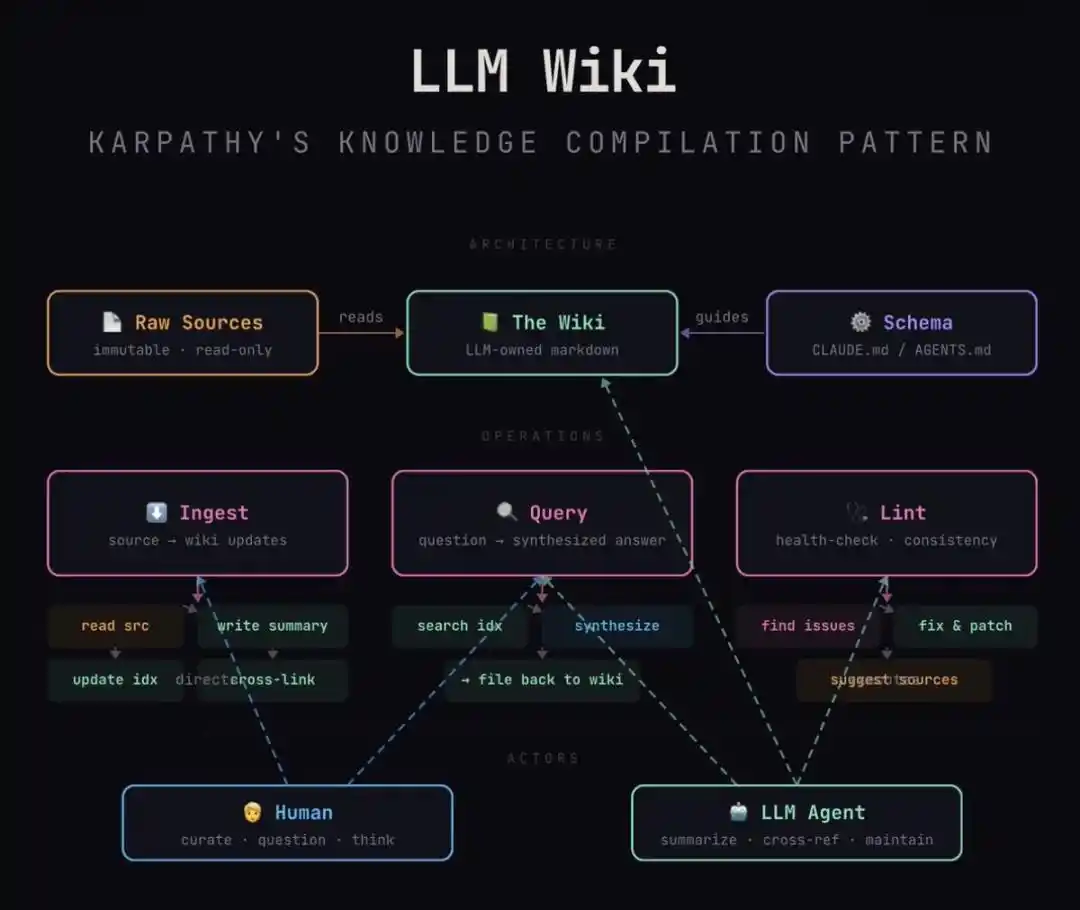
Эта архитектура изящно реализует разделение на три уровня:
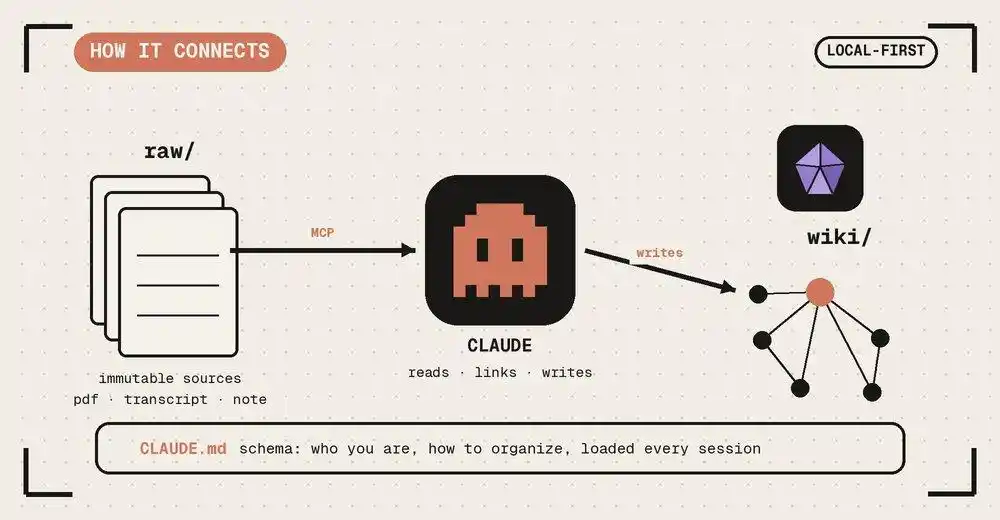
1. Сырой уровень (исходный материал): Это ваша руда вдохновения. Мимолетные мысли, сохраненные статьи, протоколы встреч. Он «неизменяем», сохраняя оригинальность и неидеальность человеческого ввода.
2. Схематичный уровень (конституция знаний): Это «устав», который вы пишете для ИИ. Например, вы определяете: каждая статья о персонаже должна содержать «мотивацию, ограничения, ключевые достижения»; каждая технологическая стека должна объяснять «преимущества и недостатки».
3. Вики-уровень (скомпилированный продукт): Это область, полностью поддерживаемая ИИ. Он, следуя вашей схеме, компилирует эту кучу сырых материалов в структурированные, перекрестно связанные, логически непротиворечивые энциклопедические страницы.
Ежедневно три действия:
1. Поглощение (Ingest): Бросить новый материал, ИИ читает его, проходит с вами по ключевым моментам, пишет резюме, прочесывает всю базу и обновляет связанные страницы — один источник может затронуть десятки страниц.
2. Запрос (Query): Задавайте вопросы непосредственно скомпилированной вики, ответы с цитатами. Самое прекрасное: хорошие ответы можно напрямую архивировать как новые страницы, ваше каждое исследование также приносит сложный процент.
3. Проверка (Lint): Периодически заставляйте ИИ проводить самопроверку, как при ревью кода — искать противоречия, устаревшие утверждения, изолированные страницы без ссылок, пробелы, которые нужно заполнить. Устраняйте проблемы на ранней стадии, не позволяя библиотеке гнить по мере роста.
Вы больше не грузчик знаний, а архитектор этой империи мудрости.
Вы отвечаете только за ввод и финальную проверку, ИИ берет на себя всю «черновую работу»: систематизацию, согласование, перекрестное связывание, обнаружение противоречий.
Это фундаментальный сдвиг в когнитивных производственных отношениях.
Это не очередной чат-бот. ChatGPT знает интернет, LLM-Wiki знает вас — точнее, то, чему вы его научили.
Каждый ответ содержит [wiki-ссылки], ведущие к вашему графу знаний. Каждый ответ — это начало пути исследования, а не конец.
Изобретение, опоздавшее на 80 лет
Здесь вы можете подумать: разве это не просто умный рабочий процесс?
Не только.
В конце своего gist'а Карпати легко упомянул имя: Ванневар Буш и его статью 1945 года «Как мы можем мыслить».

1945 год, только что закончилась Вторая мировая война, этот гигант американской науки вообразил машину под названием «Memex»:
Механический письменный стол, который может хранить все ваши книги, записи, переписку и устанавливать «ассоциативные пути» между связанными элементами — связи между документами так же ценны, как и сами документы.
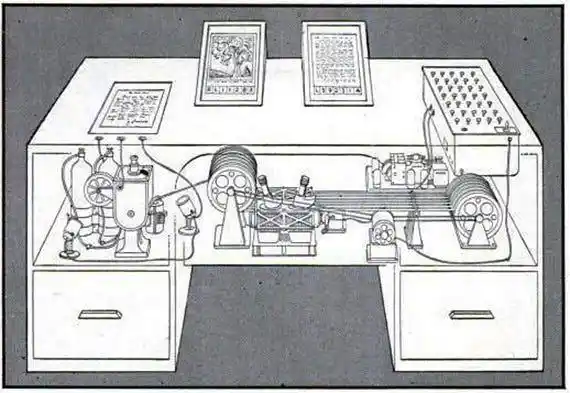
Звучит знакомо? Это почти дословное описание LLM-Wiki.
Видение Буша на самом деле было ближе к этой концепции, чем последующая Всемирная паутина: частная, лично курируемая сеть знаний, где ценность заключается в связях.

Почему Memex не была создана за восемьдесят лет?
Потому что Буш столкнулся с проблемой, которую не мог решить — кто будет поддерживать?
Каждый ассоциативный путь нужно устанавливать вручную. Каждую перекрестную ссылку нужно создавать кому-то.
Буш мечтал о специальных «операторах», которые прокладывают для вас тропинки в знаниях.
Но реальность такова, что никто не может в больших масштабах продолжать эту скучную каторжную работу. Человек откажется от поддержки, потому что стоимость поддержки всегда растет быстрее, чем приносимая ею ценность.
Эта фраза Карпати — ключ ко всей парадигме: Самая утомительная часть поддержки базы знаний — это никогда не чтение, а ведение учета.
Обновление перекрестных ссылок, поддержание свежести резюме, маркировка конфликтов между новыми данными и старыми выводами, обеспечение постоянной согласованности между десятками страниц. Эта монотонность способна отпугнуть всех.
А большая модель не забудет обновить какую-либо перекрестную ссылку, может за один раз изменить 15 файлов.
Она не устает. Не раздражается. Не сломается под ночной нагрузкой. Стоимость поддержки снижена практически до нуля.
Итак, машина, которая не давалась человечеству восемьдесят лет, вдруг заработала.
Освобождается человеческое внимание
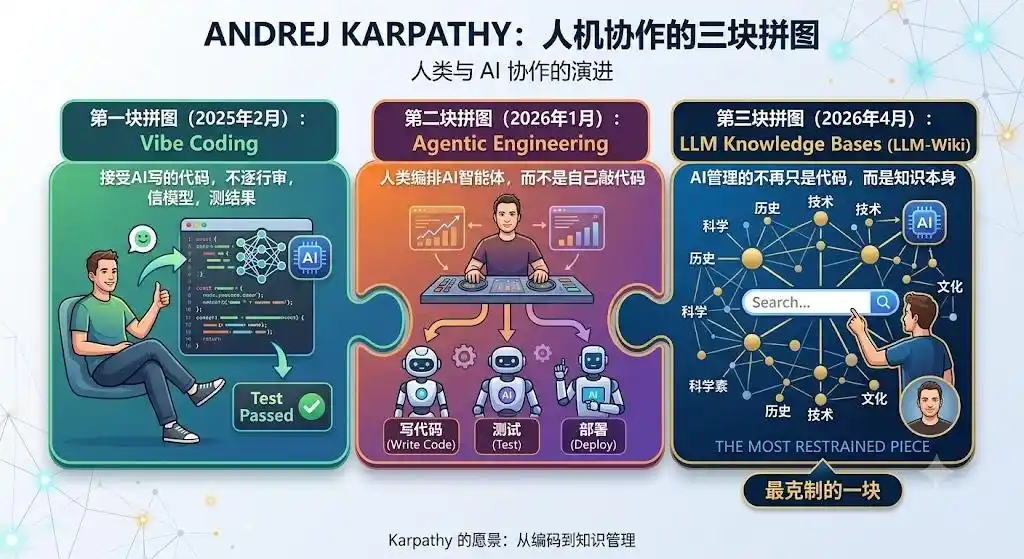
Оглядываясь назад, LLM-Wiki — это третий пазл Карпати в концепции «человеко-машинного сотрудничества», и самый сдержанный.
Первый, Vibe Coding (февраль 2025): Принять код, написанный ИИ, не проверять построчно, доверять модели, тестировать результат.
Второй, Agentic Engineering (январь 2026): Люди организуют ИИ-агентов, а не пишут код сами.
Третий, LLM Knowledge Bases (апрель 2026): ИИ управляет уже не только кодом, но и самими знаниями.
В этой новой парадигме с человека снята черновая работа, которую никто не любит: сохранение, организация, связывание, учет.
Человеку оставлены только две вещи: решать, что читать, и понимать, что все это на самом деле означает. Это как раз те две вещи, которые машина до сих пор не умеет делать и делать за вас не должна.
Это история о том, как инструмент, эволюционировав до предела, в конечном итоге по кругу вернул человеческое внимание самому человеку.
Тот непритязательный до смешного markdown-файл, не выпустивший модель, не побивший рекорды.
Он просто тихо напомнил: ваш мозг не должен был использоваться для учета.
Эта статья из WeChat Official Account «Новая эпоха искусственного интеллекта», автор: ASI Apocalypse








