Penulis: Li Fei-Fei
Diterjemahkan oleh: Jiayang
“Model dunia” mungkin adalah konsep yang paling panas dan paling kacau di bidang AI sejak tahun 2025. Ketika Sora diluncurkan, OpenAI menyebutnya simulator dunia; Genie yang memungkinkan Anda berjalan-jalan di dalam gambar yang dihasilkan, juga disebut model dunia; perusahaan robotik mengatakan mereka sedang membangun model dunia, NVIDIA mengatakan Omniverse adalah infrastruktur untuk model dunia, bahkan game engine pun ditarik ke dalam narasi ini. Semua orang menggunakan istilah yang sama, tetapi masing-masing merujuk pada hal yang berbeda.
Hari ini, Li Fei-Fei menerbitkan artikel baru di Substack pribadinya, yang mengklarifikasi konsep ini. Dia pertama-tama kembali ke diagram klasik dalam buku teks reinforcement learning (POMDP closed-loop: agent→action→state→observation→agent), lalu menunjukkan bahwa hal-hal yang saat ini disebut "model dunia" sebenarnya adalah tiga proyeksi berbeda dari loop tertutup ini. Yang mengeluarkan piksel (observasi) adalah renderer, yang mengeluarkan keadaan adalah simulator, dan yang mengeluarkan tindakan adalah planner. Kriteria klasifikasinya sangat sederhana: berdasarkan bagian mana dari loop tertutup yang dikeluarkan.

(Sumber: MIT Technology Review)
Dia menilai, di antara ketiganya, renderer adalah yang paling matang secara komersial tetapi memiliki batas atas (bagus secara visual belum tentu benar secara fisik), planner paling menarik tetapi paling jauh dari penerapan nyata (kesenjangan antara demonstrasi lab dan kegunaan praktis masih sangat besar), sedangkan simulator adalah hub kunci yang sangat diremehkan. Karena simulator bekerja pada tingkat geometri, fisika, dan dinamika, ia dapat memproyeksikan ke atas menjadi piksel untuk dikonsumsi manusia, dan juga dapat menyimpulkan konsekuensi tindakan untuk digunakan robot. Menguasai simulasi berarti sekaligus memiliki dasar untuk rendering dan perencanaan; sebaliknya tidak.
Artikel ini tentu juga merupakan pernyataan produk dari World Labs. Marble mereka sudah dapat mengeluarkan Gaussian splat dan collision mesh secara bersamaan, mencoba menyatukan renderer dan simulator ke dalam satu model. Akhir artikel menggambarkan sebuah final di mana ada model dasar dunia yang terpadu, yang dapat beralih bebas antara rendering, simulasi, dan perencanaan sesuai kebutuhan hilir. Apakah visi ini akan terwujud adalah cerita lain, tetapi sebagai kerangka analisis, pembagian tiga bagian renderer/simulator/planner mungkin memang dapat membantu menembus sebagian kebisingan konsep "model dunia" saat ini.
Terjemahan lengkapnya adalah sebagai berikut.
"Dunia adalah jumlah dari semua yang terjadi." — Wittgenstein, Tractatus Logico-Philosophicus, 1921
Dunia tidak terbuat dari kata-kata.
Dalam artikel sebelumnya, kami mengusulkan bahwa kecerdasan spasial adalah frontier AI berikutnya, dan model dunia adalah jalur menujunya. Di sini, tim World Labs dan saya ingin menggali lebih dalam: di antara banyak hal yang sekarang diberi label "model dunia", modul fungsi mana yang benar-benar membangun kemampuan ini? Untuk apa masing-masing digunakan?
Model bahasa memberikan mesin kendali yang kuat atas konsep, kosakata, dan penalaran, tetapi dunia fisik, baik virtual maupun nyata, beroperasi pada dasar yang sama sekali berbeda. Model bahasa mempelajari struktur statistik teks, model dunia mempelajari struktur statistik ruang dan waktu: bagaimana cahaya jatuh pada suatu permukaan, bagaimana tampilan taman dari sudut yang belum pernah diambil kamera, bagaimana objek merespons gaya dan mengikuti hukum fisika.
Ini menjadikan "model dunia" sebagai salah satu istilah terpenting dan sekaligus paling disalahgunakan di bidang AI saat ini. Computer vision, robotika, reinforcement learning, dan AI generatif semuanya mengklaim membangun model dunia, tetapi masing-masing merujuk pada hal yang sangat berbeda. Model video yang dapat menghasilkan api yang indah tetapi secara fisik tidak mungkin, model bahasa yang secara spontan menghasilkan game yang dapat dimainkan, mesin fisika yang secara akurat mensimulasikan proses pembakaran, semuanya disebut dengan nama yang sama.
Orang Yunani kuno tidak pernah bisa menyepakati apa yang membentuk dunia, apakah itu api, air, atau atom yang tidak terbagi, karena "dunia" tidak pernah menjadi satu hal. Itu selalu adalah kata pengganti yang digunakan seorang pemikir untuk bernalar tentang suatu totalitas. AI mewarisi masalah yang sama, dan itu terjadi tepat pada saat bidang ini paling membutuhkan ketepatan.
Loop Tertutup di Balik Taksonomi
Untuk mengklarifikasi kekacauan ini, kita bisa mulai dari diagram yang lebih tua dari semua teknologi di atas. Semua buku teks reinforcement learning, termasuk klasik Sutton dan Barto, selama beberapa dekade telah menggunakan varian dari diagram yang sama untuk menggambarkan bagaimana agen berinteraksi dengan dunia. Nama resminya adalah Partially Observable Markov Decision Process (POMDP), dan definisi awal istilah "model dunia" milik tradisi ini.
Sebuah agen (bisa manusia, robot, atau sistem perangkat lunak) melakukan tindakan. Tindakan ini mengubah keadaan dunia. Tetapi agen tidak pernah bisa melihat keadaan itu sendiri secara langsung, yang diterimanya adalah observasi: foton yang jatuh di retina, pembacaan sensor, piksel dalam bingkai video. Observasi baru memandu tindakan baru, dan seterusnya.
Kata "state" perlu dilihat lebih dekat, karena maknanya bergeser di berbagai bidang. Ini bukan keadaan ahli kimia, bukan perbedaan padat, cair, dan gas. Ini adalah keadaan fisikawan dan ahli robotika: deskripsi lengkap tentang segala sesuatu yang terjadi di dunia pada suatu saat, termasuk setiap objek, setiap posisi, setiap kecepatan, setiap atribut. Keadaan adalah realitas dasar dunia, secara prinsip lengkap, tetapi tidak dapat diamati secara langsung oleh agen mana pun yang berada di dalamnya. Observasi adalah perspektif lokal agen terhadap realitas ini. Tindakan adalah respons agen berdasarkan itu.
Loop tertutup ini (agen→action→state→observation→agent) adalah struktur yang memberikan makna teknis pada istilah "model dunia". Frasa ini sendiri lebih tua, dapat ditelusuri kembali ke usulan Kenneth Craik pada tahun 1943 bahwa pikiran bernalar dengan menjalankan "model skala kecil" realitas, dan pada akhir 1980-an dan awal 1990-an, konsep ini diperkenalkan ke bidang jaringan saraf. Loop tertutup ini juga menjelaskan apa yang dimaksud orang saat mereka menggunakan istilah ini hari ini. Hal-hal yang sekarang disebut model dunia sebenarnya adalah proyeksi berbeda dari loop tertutup yang sama, masing-masing mengeluarkan bagian yang berbeda dari loop.
Tiga Fungsi Model Dunia
Model dunia pertama adalah renderer. Renderer mengeluarkan observasi, khususnya piksel untuk mata manusia, dan metrik kualitas terpenting adalah kesetiaan visual. Model video yang mengubah teks prompt menjadi rekaman aerial tingkat film adalah renderer; sistem interaktif seperti Genie 3 dari Google atau RTFM World Labs sendiri juga renderer, yang menghasilkan gambar secara real-time berdasarkan input pengguna. Model semacam ini tidak memiliki pemahaman eksplisit tentang struktur 3D. Ia menghasilkan apa yang akan dilihat pengamat, bukan seperti apa sesuatu itu sebenarnya. Gedung dalam rekaman aerial mungkin tampak sempurna dari udara, tetapi coba berjalan di kota di bawahnya, mereka akan runtuh.
Yang kedua adalah simulator. Simulator mengeluarkan state: representasi dunia yang setia secara geometri, fisika, atau dinamika, di mana manusia dan program komputer dapat berhitung dan berinteraksi. Kontrak renderer murni visual, sedangkan kontrak simulator struktural, membutuhkan geometri yang dapat diuji, fisika yang mengikuti hukum Newton, perilaku dinamika yang sesuai dengan ekspektasi hukum fisika. Simulator melayani dua jenis pengguna sekaligus. Profesional seperti arsitek, desainer, pembuat film, pengembang game membutuhkan akurasi yang melampaui kredibilitas visual. Program komputer seperti agen reinforcement learning, pengendali robot, kendaraan otonom menggunakan simulator sebagai tempat latihan, berinteraksi dengan dunia secara besar-besaran, menguji skenario yang berbahaya, mahal, atau tidak mungkin dilakukan di dunia nyata.
Yang ketiga adalah planner. Planner mengeluarkan tindakan. Diberikan observasi dan tujuan, planner menjawab pertanyaan: apa yang harus dilakukan agen selanjutnya. Dalam banyak hal, planner adalah proses kebalikan dari renderer. Renderer mengambil tindakan sebagai input, menghasilkan observasi; planner mengambil observasi sebagai input, menghasilkan tindakan, sehingga menutup loop persepsi-aksi. Model Visi-Bahasa-Tindakan (VLA), sistem berbasis model, dan gelombang baru World Action Models, semuanya adalah upaya berbeda untuk planner: membuat sistem dapat memutuskan apa yang harus dilakukan robot di dunia yang tidak terstruktur.
Ketiga kategori di atas mencakup sebagian besar pekerjaan yang saat ini sedang diimplementasikan, dan perbedaannya berguna dalam praktik. Namun ketiga kategori ini tidak terpisah secara fundamental. Mereka berbagi pengetahuan dasar yang sama tentang bagaimana dunia bekerja: geometri, fisika, dinamika. Model yang dapat merender cangkir dari sudut mana pun, pada prinsipnya juga harus dapat mensimulasikan apa yang terjadi jika cangkir didorong, dan merencanakan tangan untuk mengambilnya. Semakin banyak penelitian yang paling menarik dengan sengaja mengaburkan batas antara ketiganya.
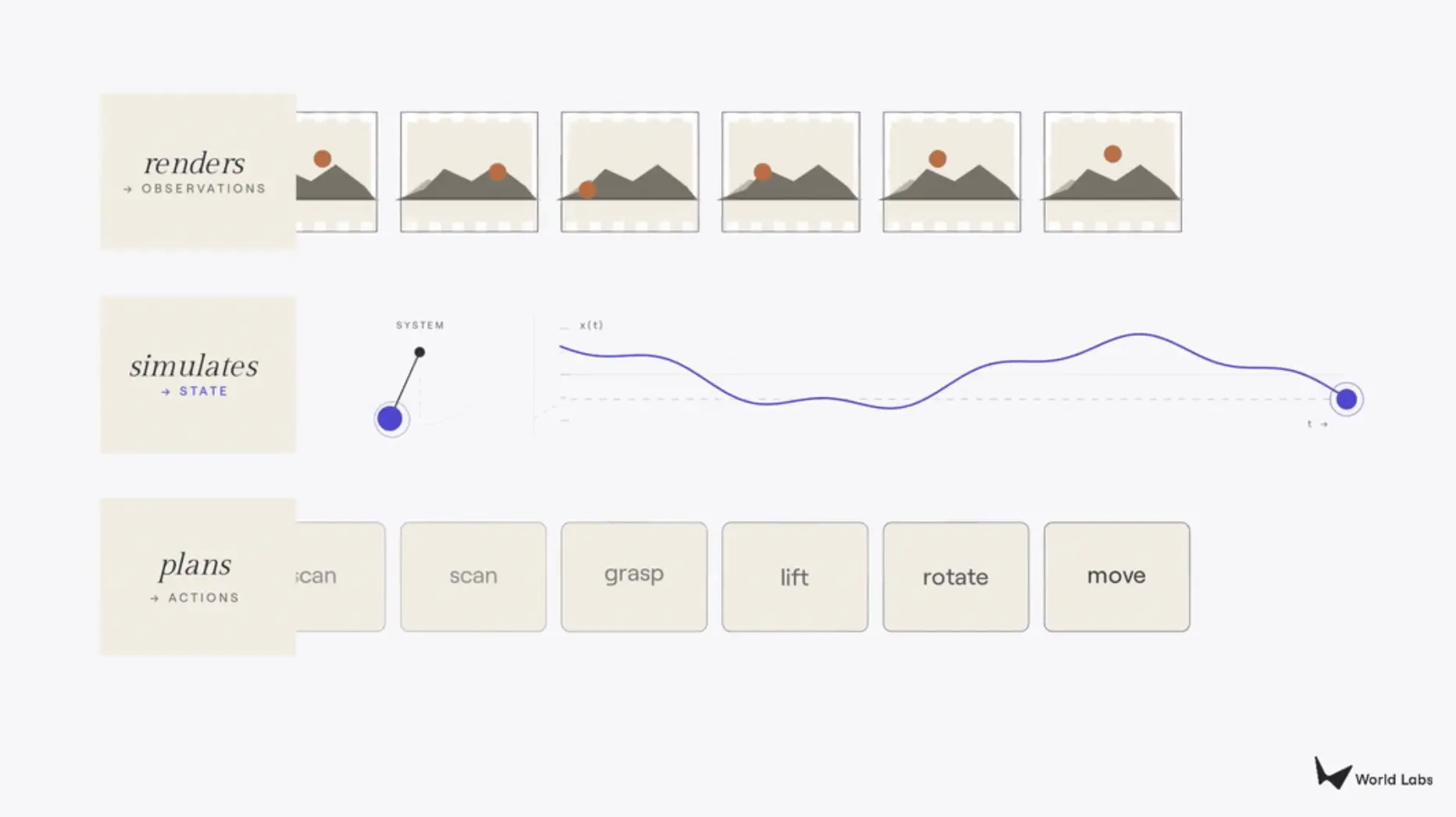
Gambar丨Tiga Jenis Model Dunia (Sumber: Substack)
Mengapa Simulasi Adalah Hub Kunci
Dari tiga kategori, simulator menerima perhatian publik paling sedikit, tetapi adalah yang paling penting di antara ketiganya. Artikel ini ingin memperbaiki asimetri ini.
Renderer saat ini adalah yang paling matang secara komersial. Banyak produk pembuat gambar atau teks-ke-video berkembang pesat di pasar konsumen dan perusahaan. Model Nano Banana Google membawa kemampuan pembuatan gambar tingkat renderer ke tangan mungkin ratusan juta pengguna. Teknologinya nyata, pasarnya juga nyata. Namun, tujuan pengoptimalan renderer adalah kredibilitas visual, bukan akurasi fisik, batas atas ini penting. Output mereka indah, tetapi Anda tidak dapat menggunakannya untuk mendesain bangunan atau melatih robot.
Planner adalah yang paling menarik dan paling belum matang, terkait erat dengan bidang pembelajaran robotika yang berkembang cepat. Dua tahun terakhir, bidang ini menghasilkan banyak demonstrasi robot yang terlihat mengesankan di video, tetapi kita perlu jujur tentang apa yang ditunjukkan demonstrasi ini. Hampir semua demonstrasi terbatas pada lingkungan lab yang sangat terbatas, dengan jenis objek terbatas dan durasi tugas singkat. Tidak ada yang telah diuji dengan kompleksitas, keragaman, dan durasi terus-menerus yang dibutuhkan oleh penerapan dunia nyata. Kesenjangan antara video demo yang menarik dan robot yang dapat bekerja andal di dapur, gudang, atau ruang operasi masih sangat besar.
Meski begitu, taruhan komersialnya tetap besar. Gelombang pendatang baru yang didanai dengan baik sedang berlomba-lomba meluncurkan sistem perencanaan umum, sementara pemain infrastruktur besar sedang membangun kemampuan perencanaan di atas tumpukan simulasi yang lebih luas.
Simulasi adalah jembatan yang menghubungkan keduanya. Jika bahasa adalah abstraksi dunia, piksel adalah proyeksi dunia, maka geometri, fisika, dan dinamika adalah dunia itu sendiri. Simulator harus bekerja pada tingkat ini: itu adalah kerangka struktural, di mana representasi visual (untuk digunakan renderer) dan konsekuensi tindakan (untuk digunakan planner) dapat disimpulkan.
Model yang menguasai simulasi dapat memproyeksikan pemahamannya menjadi piksel untuk dikonsumsi manusia, dan juga menjadi prediksi tindakan untuk digunakan agen berwujud. Model yang hanya menguasai rendering atau hanya menguasai perencanaan tidak dapat melakukan keduanya. Ruang komersial di sini sangat luas. Hanya Omniverse NVIDIA saja, pasar sasarannya diperkirakan perusahaan tersebut melebihi triliunan dolar, mencakup pabrik, gudang, rantai pasokan, dan kembaran digital. Pelatihan robot, pengujian kendaraan otonom, visualisasi arsitektur, desain teknik, penemuan obat, semuanya bergantung pada beberapa bentuk simulasi.
Pertanyaan terbuka yang paling sulit di bidang ini juga terkonsentrasi di sini. Data 3D dengan geometri eksplisit, atribut material, dan anotasi fisik beberapa kali lebih langka daripada video internet yang digunakan untuk pelatihan renderer. Kesenjangan sim-to-real (perbedaan perilaku objek dalam simulasi dengan perilaku di dunia nyata) masih ada. Simulator generatif juga memperkenalkan risiko baru: geometri yang dihasilkan AI mungkin terlihat benar, tetapi sebenarnya mengandung masalah seperti perpotongan sendiri atau proporsi yang salah, menyebabkan simulasi fisik menghasilkan hasil yang tidak masuk akal. Biaya komputasi untuk simulasi multi-fisika skala besar (benda tegar, benda dapat berubah bentuk, fluida, kain semua berinteraksi bersamaan) masih beberapa kali lipat lebih tinggi daripada simulasi domain tunggal.
Di World Labs, Marble adalah langkah pertama kami ke arah ini. Ia menerima input multimodal (teks, gambar, video, atau sketsa spasial), menghasilkan lingkungan 3D yang dapat dieksplorasi, sekaligus mengeluarkan Gaussian splats untuk eksplorasi visual dan collision mesh untuk dioperasikan oleh mesin fisika. Tetapi Marble hanyalah bab pertama dari garis panjang. Saat batas antara rendering, simulasi, dan perencanaan mulai memudar, seluruh bidang sedang menulis cerita ini.
Batas Mulai Memudar, dan Apa yang Akan Terjadi Selanjutnya
Tren terpenting saat ini di bidang ini adalah ketiga kategori mulai menyatu. Konsensus yang mendasarinya adalah: pengetahuan yang dibutuhkan untuk merender dunia, mensimulasikannya, dan bertindak di dalamnya sebagian besar sama. Mengikuti contoh sebelumnya, model yang benar-benar memahami bagaimana cangkir diletakkan di atas meja (bentuk geometrinya, sifat materialnya, responsnya terhadap gaya, dll.) seharusnya dapat merender cangkir itu dari sudut mana pun, mensimulasikan apa yang terjadi jika cangkir didorong, dan merencanakan tangan untuk mengambilnya. Ketiga kategori adalah tiga proyeksi dari pemahaman dasar yang sama.
Misalnya, baru-baru ini ada sedikit tetapi pekerjaan yang berkembang dari berbagai lab robotika, menunjukkan kemungkinan yang setidaknya secara konseptual layak: renderer video yang telah dilatih sebelumnya dapat berfungsi sebagai backbone network untuk prediksi dunia dan prediksi tindakan bersama, memungkinkan model tunggal sekaligus membayangkan "apa yang akan terjadi" dan "apa yang harus dilakukan", sehingga menjembatani renderer dan planner. Marble dari World Labs sudah dapat mengeluarkan Gaussian splats dan collision mesh dari model tunggal, menghilangkan batas antara renderer dan simulator. Setiap lapisan beralih dari output pasif ke sistem interaktif: renderer menjadi responsif terhadap kondisi tindakan, dunia yang dihasilkan simulator menjadi lebih terkendali dan dapat diedit, planner mulai melakukan penalaran yang hati-hati, bukan hanya bereaksi.
Tujuan logisnya adalah model dunia yang terpadu: model dasar yang dapat merender tampilan yang fotorealistis, menghasilkan struktur yang akurat secara fisik, merencanakan urutan tindakan, dan beralih di antara modalitas output yang berbeda sesuai kebutuhan pengguna hilir. Kita masih akan menghadapi serangkaian tantangan berat. Lanskap data sangat tidak seimbang, renderer memiliki banyak video internet, sementara simulator dan planner menghadapi kelangkaan data aset 3D dan demonstrasi robotik yang parah. Pengoptimalan untuk estetika visual dapat mengorbankan presisi yang dibutuhkan oleh robotika atau simulasi high-fidelity. Merekonsiliasi ketegangan ini dalam satu arsitektur adalah masalah terbuka inti dari penelitian model dunia saat ini, dan juga yang World Labs berusaha selesaikan saat Marble terus berkembang.
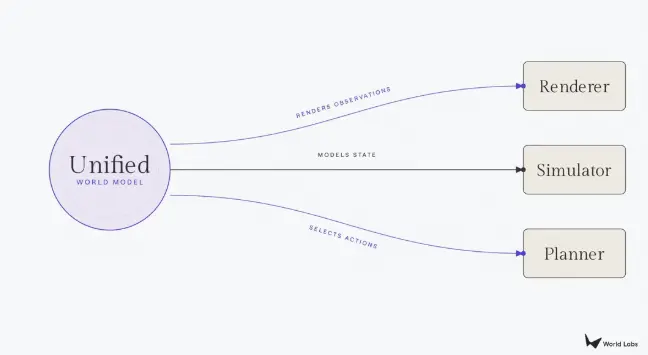
(Sumber: Substack)
Tetapi arah besarnya sudah jelas. Dari akhir 1980-an hingga sekarang, bidang ini selalu bertaruh pada hal yang sama: selama model dunia cukup kaya, semua yang dibutuhkan agen untuk melihat dunia, membangun dunia, dan bertindak di dalamnya ada di dalamnya. Taruhan ini sekarang mendorong penelitian satu generasi. Dan yang benar-benar memberikan bobotnya adalah fusi yang sudah terjadi: rendering, simulasi, perencanaan, tiga garis, masing-masing sudah mendukung industri bernilai miliaran dolar, mereka awalnya adalah arah penelitian independen, sekarang mulai menyatu. Ketika batas hilang, penyatuan ketiganya akan mendefinisikan ulang hal yang lebih besar: hubungan antara kecerdasan mesin dan dunia fisik yang dihuninya, yaitu arah jangka panjang kecerdasan spasial.
Bahasa memberi mesin cara untuk membicarakan dunia ini. Model dunia, adalah cara mesin akhirnya memahami, membayangkan, bernalar, dan berinteraksi dengannya.
Referensi:1.https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models







