Menyimpan tidak sama dengan memiliki, menyoroti tidak sama dengan memahami.
Artikel-artikel mendalam yang membuat hati Anda berdebar-debar jam dua pagi, tautan dua arah yang begitu padat di Obsidian, database yang ditata dengan rapi di Notion—semuanya adalah "Mumi Siber" yang terbaring di aplikasi catatan.
Grafik pengetahuan terlihat megah, padahal sudah membusuk.
Ini adalah kegagalan sistemik dari era kelebihan informasi.
Andrej Karpathy, insinyur Anthropic saat ini, mantan salah satu pendiri OpenAI, mantan direktur AI Tesla, tidak tahan lagi. Dia melemparkan sebuah bom.

Pintu masuk: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Dia tidak mengumumkan model baru, tidak merilis framework baru. Dia hanya berkata: Anggap catatan Anda sebagai kode sumber yang tidak dapat diubah, biarkan LLM menjadi kompilernya.
Dua bulan berlalu, dokumen ini telah memicu migrasi diam-diam namun dahsyat di komunitas Obsidian, Claude, dan Cursor.
Beberapa orang telah memperluas Wiki mereka menjadi ratusan halaman, puluhan ribu kata.
Plugin otomatis mulai bermunculan. Peneliti akademik, wirausahawan mandiri, dan pembelajar seumur hidup secara kolektif beralih ke hubungan produksi pengetahuan yang sama sekali baru.
Senja RAG, Pemuatan Informasi Tak Menyelamatkan Pikiran Anda
Sebelum LLM-WIKI muncul, solusi utama adalah RAG (Retrieval-Augmented Generation).
Sederhananya, beri model besar seorang "pencari": saat Anda bertanya, ia mencari beberapa cuplikan di catatan Anda, lalu merangkai jawaban.
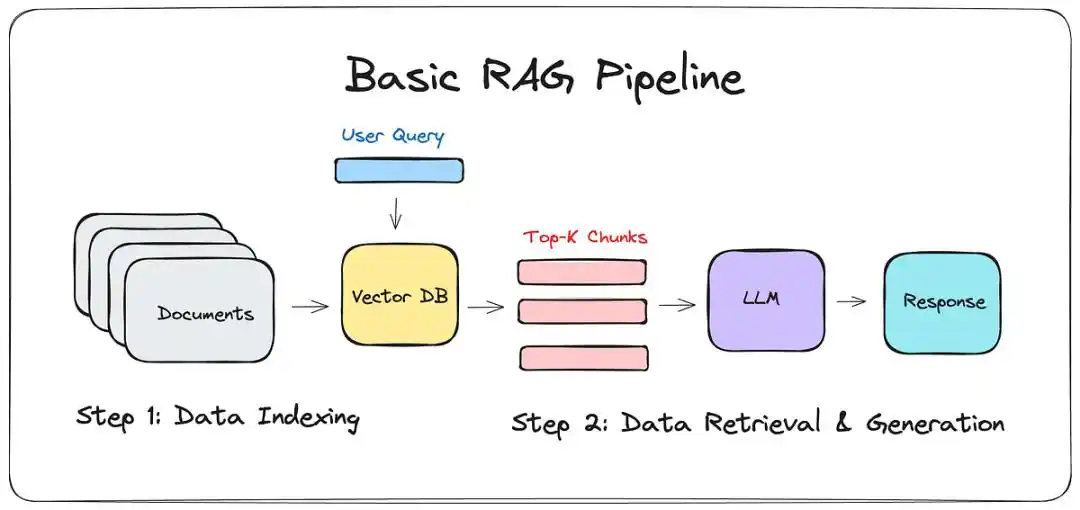
Terdengar indah, tapi mereka yang pernah menggunakannya tahu kesenjangan antara "iklan" dan "kenyataan".
Ia hanyalah pemindah barang: RAG hanya bisa menangani bagian, tidak memahami keseluruhan.
Ia bisa memberitahu Anda bahwa catatan ke-5 menyebutkan A, tapi ia tidak bisa memberitahu Anda logika mendasar yang diarahkan oleh 500 catatan ini bersama-sama.
Ia akan mengalami "split personality": Jika setengah tahun lalu Anda berpikir A benar, tapi kemarin Anda menulis catatan yang membantah A, RAG sering kali terjebak dalam kontradiksi diri, mengeluarkan omong kosong yang kacau.
Grafik yang membusuk: Tautan pengetahuan yang dipelihara secara manual seperti kode tanpa fungsi pembersihan otomatis. Lama kelamaan, tautan mati ada di mana-mana, efisiensi pencarian menurun secara eksponensial.
Intuisi Karpathy sangat tajam: Pencarian dan pengambilan adalah manifestasi ketidakmampuan manusia. Yang kita butuhkan adalah "konsensus", "struktur", "kebenaran".
Anggap Pengetahuan Sebagai Kode Sumber, Biarkan LLM Jadi Kompiler
Jawaban Karpathy berasal dari tindakan yang setiap hari dilakukan programmer, tapi tak pernah terpikir untuk diterapkan pada pengetahuan: kompilasi.
Anda menulis kode sumber, tidak setiap kali menjalankan program membaca ulang kodenya.
Anda mengompilasinya menjadi file biner. Kompilasi kali ini melelahkan, tapi setiap kali dijalankan setelahnya sangat cepat. Biaya kompilasi, terbagi oleh ribuan kali penggunaan setelahnya.
Kenapa pengetahuan tidak bisa seperti ini?
Karpathy berkata, anggap catatan mentah Anda sebagai kode sumber yang tidak dapat diubah, anggap LLM sebagai kompiler, biarkan ia sekaligus "mengompilasi" tumpukan bahan berantakan ini menjadi Wiki yang terstruktur dan saling tertaut.
Setiap kali menambah materi baru, AI melakukan fusi: memperbarui halaman entri terkait, merevisi ikhtisar, menandai tempat di mana data baru dan kesimpulan lama bertentangan, sekaligus menguatkan atau menantang penilaian yang ada.
Perbedaan kunci di sini: Pengetahuan dikompilasi sekali, lalu terus segar, bukan dibangun kembali sementara setiap kali ditanya.
Saat Anda bertanya, referensi silang sudah ada di sana, kontradiksi sudah ditandai, ikhtisar sudah mencerminkan semua yang Anda baca.
Anda tidak mengompilasi ulang kode sumber setiap kali menjalankan program. Lalu kenapa setiap kali bertanya, harus menyuruh AI membaca ulang catatan Anda?
Perpindahan Mendasar Hubungan Produksi Kognitif
Dalam framework LLM-WIKI-nya, catatan bukan lagi teks mati, melainkan "kode sumber".
Model besar bukan lagi penerjemah yang mencari kamus, melainkan "kompiler".
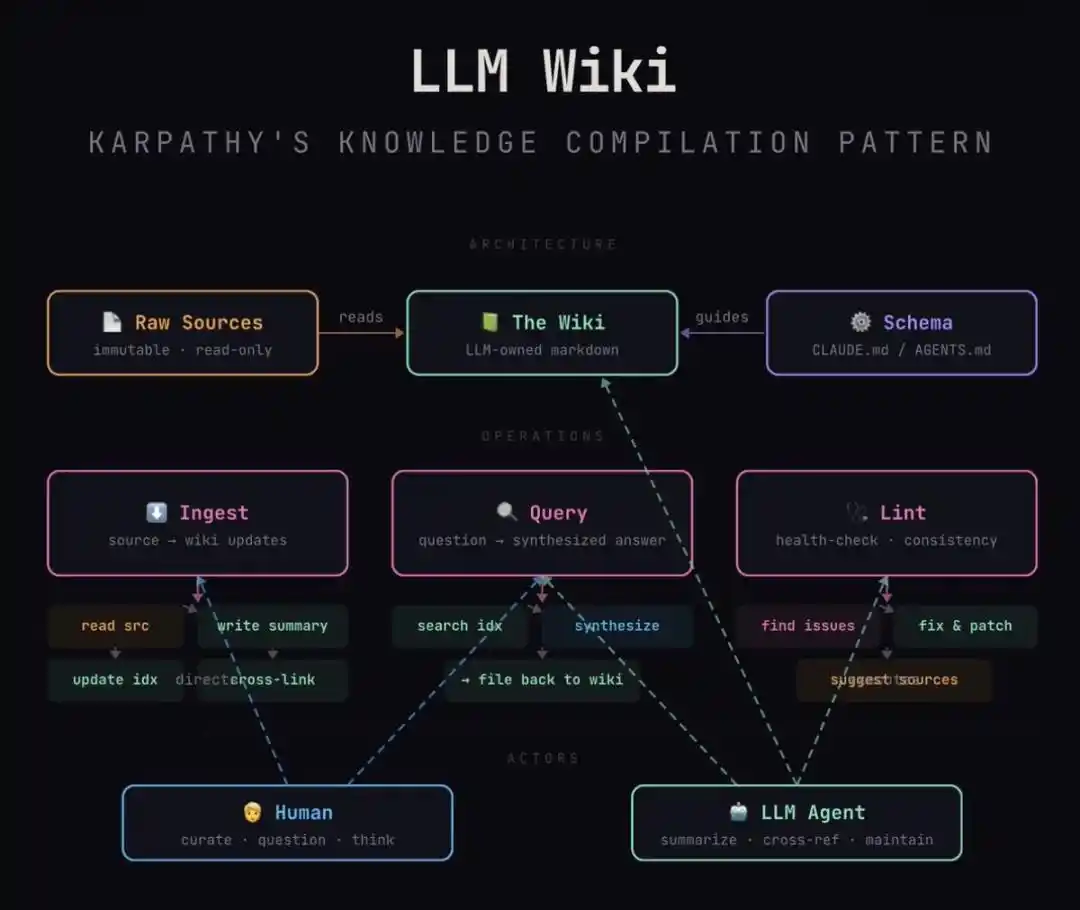
Arsitektur ini dengan sangat cerdik menerapkan tiga lapisan pemisahan:
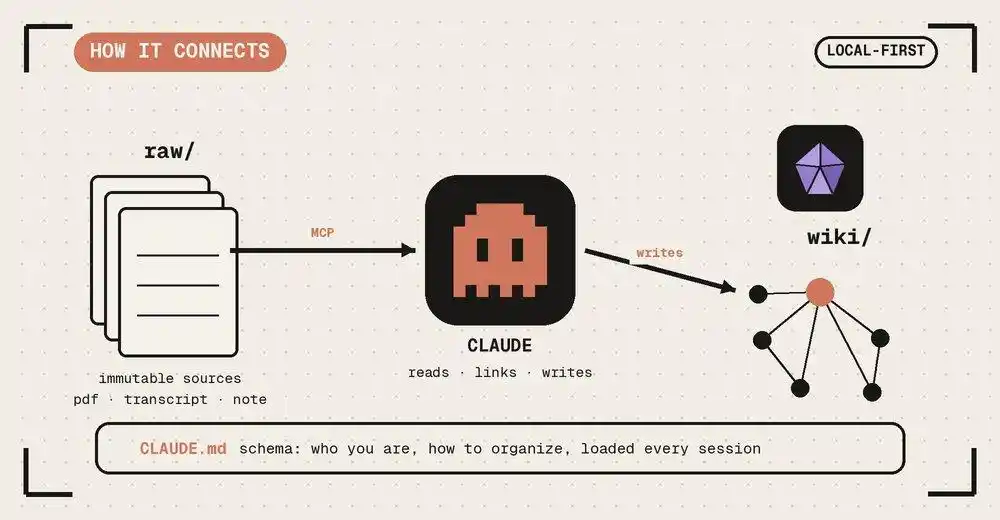
1. Lapisan Raw (Bahan Mentah): Ini adalah bijih inspirasi Anda. Wawasan yang Anda catat sembarangan, artikel yang Anda klip, notulen rapat. Ini "tidak dapat diubah", menjaga keaslian dan kekacauan input manusia.
2. Lapisan Schema (Konstitusi Pengetahuan): Ini adalah "aturan perang" yang Anda tulis untuk AI. Misalnya, Anda menetapkan: setiap entri tokoh harus mengandung "motivasi, keterbatasan, pencapaian kunci"; setiap tumpukan teknologi harus menjelaskan "kelebihan/kekurangan".
3. Lapisan Wiki (Produk Terkompilasi): Ini adalah area yang sepenuhnya dikelola AI. Berdasarkan Schema Anda, ia mengompilasi tumpukan Raw yang berantakan itu menjadi halaman ensiklopedia yang terstruktur, tertaut silang, dan koheren secara logika.
Aktivitas sehari-hari hanya tiga gerakan:
1. Ingest (Memasukkan): Masukkan satu bahan baru, AI membacanya, membahas poin-poin penting dengan Anda, menulis ringkasan, menyapu seluruh perpustakaan untuk memperbarui halaman terkait—satu sumber, bisa mempengaruhi belasan halaman.
2. Query (Bertanya): Langsung tanyakan Wiki yang sudah terkompilasi, jawab dengan kutipan. Yang paling hebat: jawaban yang bagus bisa langsung diarsipkan menjadi halaman baru, setiap eksplorasi Anda juga menghasilkan compound interest.
3. Lint (Pemeriksaan): Secara berkala, minta AI memeriksa dirinya sendiri seperti review kode—cari kontradiksi, cari pernyataan kedaluwarsa, cari halaman terisolasi yang tidak tertaut, cari celah yang harus diisi. Bersihkan sejak dini, jangan biarkan perpustakaan tumbuh dan membusuk.
Anda bukan lagi pemindah pengetahuan, melainkan arsitek dari imperium kebijaksanaan ini.
Anda hanya bertanggung jawab atas input dan tinjauan akhir, AI bertanggung jawab atas semua "pekerjaan kasar": mengatur, menyelaraskan, membuat tautan silang, mendeteksi kontradiksi.
Ini adalah perpindahan mendasar hubungan produksi kognitif.
Ini bukan chatbot lain. ChatGPT mengenal internet, LLM-Wiki mengenal Anda—tepatnya, hal-hal yang Anda ajarkan padanya.
Setiap jawaban membawa [tautan-wiki] kembali ke grafik pengetahuan Anda. Setiap balasan adalah titik awal sebuah jalur eksplorasi, bukan titik akhir.
Penemuan yang Terlambat 80 Tahun
Sampai di sini, Anda mungkin berpikir ini hanya alur kerja yang cerdas?
Bukan cuma itu.
Di akhir gist-nya, Karpathy dengan ringan menyebut satu nama: Vannevar Bush, dan esainya tahun 1945, "As We May Think".

1945, Perang Dunia II baru saja berakhir, tokoh besar komunitas sains AS ini membayangkan sebuah mesin bernama "Memex":
Sebuah meja mekanis, bisa menyimpan semua buku, catatan, komunikasi Anda, dan di antara entri terkait, membangun "jalur asosiatif"—koneksi antar-dokumen, sama berharganya dengan dokumen itu sendiri.
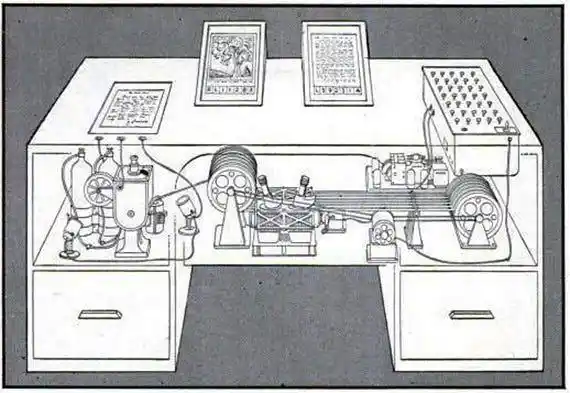
Terdengar familiar? Ini hampir deskripsi harfiah dari LLM-Wiki.
Visi Bush sebenarnya lebih mendekati hal ini daripada World Wide Web yang muncul kemudian: jaringan pengetahuan yang pribadi, dikurasi tangan sendiri, di mana koneksi adalah nilai.

Lalu kenapa Memex tidak terwujud selama delapan puluh tahun?
Karena Bush terjebak pada masalah yang tidak bisa dia selesaikan—siapa yang akan memeliharanya?
Setiap jalur asosiatif harus dibangun secara manual. Setiap referensi silang harus ditautkan oleh seseorang.
Bush membayangkan ada "operator" khusus yang membangun jalur kecil dalam pengetahuan untuk Anda.
Tapi kenyataannya, tidak ada seorang pun yang bisa bertahan melakukan pekerjaan membosankan ini dalam skala besar. Manusia akan menyerah memelihara, karena biaya pemeliharaan selalu tumbuh lebih cepat daripada nilai yang dihasilkannya.
Kalimat Karpathy ini adalah inti dari seluruh paradigma: Bagian yang paling melelahkan dalam memelihara basis pengetahuan bukanlah membaca, melainkan pencatatan.
Memperbarui referensi silang, menjaga ringkasan tetap segar, menandai konflik antara data baru dan kesimpulan lama, menjaga konsistensi di antara puluhan halaman. Kebosanan ini cukup untuk menghalangi siapa pun.
Dan model besar tidak akan lupa memperbarui satu referensi silang, bisa mengubah 15 file sekaligus.
Ia tidak lelah. Tidak bosan. Tidak hancur oleh larut malam. Biaya pemeliharaan, ditekan hingga hampir nol.
Maka, mesin yang membuat manusia terhenti selama delapan puluh tahun itu, tiba-tiba berputar.
Yang Dibebaskan, Adalah Perhatian Manusia
Melihat ke belakang, LLM-Wiki adalah potongan ketiga Karpathy tentang "kolaborasi manusia-mesin", dan yang paling terkendali.
Potongan pertama, Vibe Coding (Februari 2025): Menerima kode yang ditulis AI, tidak meninjau baris demi baris, percaya model, uji hasilnya.
Potongan kedua, Agentic Engineering (Januari 2026): Manusia menyusun agen cerdas AI, bukan mengetik kode sendiri.
Potongan ketiga, LLM Knowledge Bases (April 2026): Yang dikelola AI bukan lagi hanya kode, melainkan pengetahuan itu sendiri.
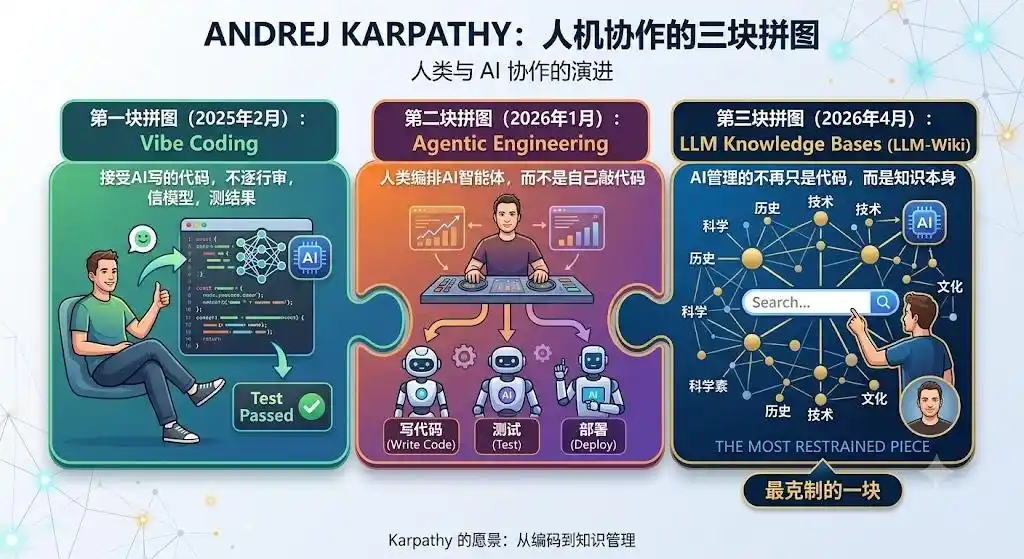
Dalam paradigma baru ini, yang dilepaskan dari manusia adalah pekerjaan kasar yang tidak disukai siapa pun: menyimpan, mengatur, menautkan, mencatat.
Yang tersisa untuk manusia, hanya dua hal: memutuskan apa yang harus dibaca, dan, memahami apa arti semua ini. Inilah dua hal yang mesin hingga kini tidak bisa lakukan, dan seharusnya tidak melakukannya untuk Anda.
Ini adalah kisah alat yang berevolusi hingga puncaknya, akhirnya berputar penuh, mengembalikan perhatian manusia pada manusia itu sendiri.
File markdown yang polos hingga memalukan itu, tidak merilis model, tidak memimpin tangga lagu.
Ia hanya mengingatkan dengan tenang: Otak Anda, seharusnya tidak digunakan untuk mencatat.
Artikel ini berasal dari akun WeChat "新智元", penulis: ASI启示录







