Setelah menunda pembaruan blog selama tiga tahun, Lilian Weng akhirnya mempublikasikannya.
Baru saja, artikel panjang yang telah ditunda selama lebih dari tiga tahun oleh mantan Wakil Presiden OpenAI, Lilian Weng, menjadi viral.
Dalam blog berjudul "Scaling Laws, Carefully" ini, dia membongkar Scaling Laws dari awal hingga akhir—
Hukum yang telah dipertaruhkan oleh industri AI dengan ratusan miliar dolar ini, ternyata jauh lebih rapuh daripada yang dibayangkan siapa pun.
Sekilas Satu Menit: Apa yang Dibahas dalam Artikel Panjang Ribuan Kata Ini
Satu rumus mengatur seluruh industri selama lima tahun. Scaling Laws mengatakan "semakin besar model, semakin banyak data, semakin kuat komputasinya, kinerja akan meningkat sesuai proporsi tetap". Ini mengubah AI dari ilmu gaib menjadi bisnis yang dapat dihitung, secara tidak langsung mengarahkan aliran ratusan miliar dolar.
OpenAI dan DeepMind memberikan jawaban berlawanan. Untuk pertanyaan yang sama "bagaimana mengalokasikan anggaran komputasi", tahun 2020 OpenAI mengatakan model harus tumbuh lebih cepat daripada data, tahun 2022 DeepMind mengatakan keduanya harus tumbuh bersamaan. Kemudian ditemukan, akar perbedaan adalah perbedaan dalam statistik satu parameter, ditambah dengan skala eksperimen yang tidak cukup besar.
Rumus pemenang juga menyembunyikan bug. Proporsi optimal yang telah disalin seluruh industri selama dua tahun dari DeepMind, pada tahun 2024 ketika direplikasi baris demi baris, ditemukan: fungsi loss diambil rata-rata (mean) bukan penjumlahan (sum), menyebabkan optimizer berhenti prematur, parameter yang dihasilkan sama sekali bukan solusi optimal.
Hati-hati menggunakan pola model kecil untuk memprediksi model besar. Kurva ini dipasang (fit) pada model yang relatif kecil, ketika diekstrapolasi ke level triliunan parameter, perbedaan pembulatan saja dapat membuat kesimpulan meleset jauh. Blog ini menyertakan simulator interaktif, cukup geser slider untuk melihatnya sendiri.
Ada masalah yang lebih mendasar: data hampir habis. Rumus mengasumsikan data dapat dipasok tanpa batas, tetapi teks berkualitas tinggi terbatas. Inilah mengapa seluruh industri beralih secara kolektif ke reinforcement learning, komputasi saat pengujian (test-time computation), dan data sintetis.
Satu Garis Lurus, Ratusan Miliar Dolar
Seperti diketahui, inti dari Scaling Laws dapat disimpulkan secara sederhana dalam satu kalimat—
Semakin besar model, semakin banyak data, semakin kuat komputasinya, kinerjanya semakin baik. Dan "semakin baik" ini bukan acak, ia memiliki pola matematika yang presisi.
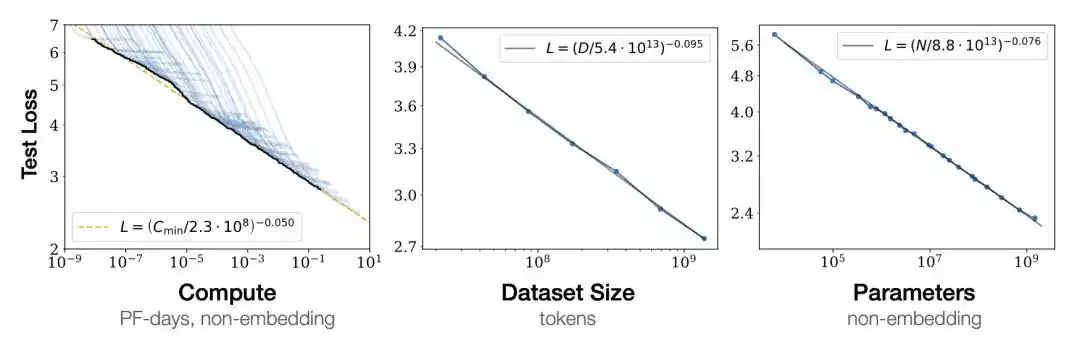
Ketika loss pelatihan model diplot pada skala logaritmik, ia turun mengikuti garis lurus seiring dengan peningkatan jumlah parameter model N, jumlah data D, dan daya komputasi C.
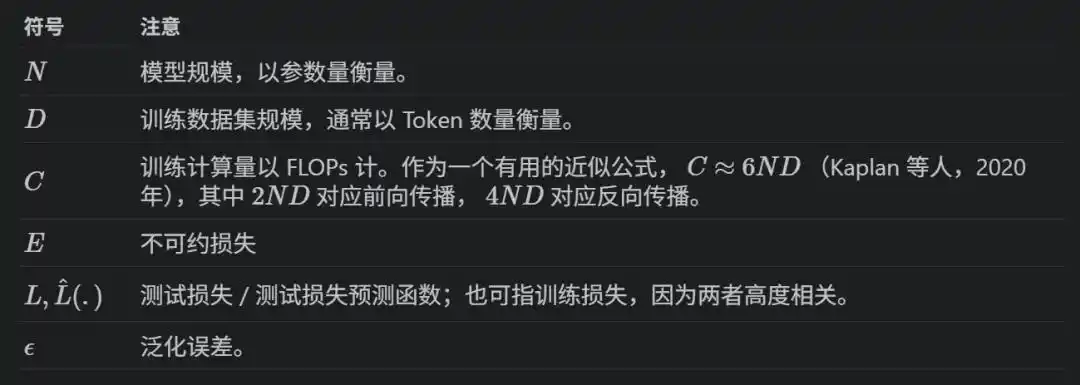
Ditulis dalam rumus adalah L(x) = E + A/x^α, di mana x dapat berupa N, D, atau C, E adalah loss teoritis optimal (entropi data itu sendiri), A dan α adalah konstanta hasil fitting.
Melatih model dengan N parameter pada D token, total daya komputasi C ≈ 6ND—forward propagation 2ND, backward propagation 4ND.
Garis lurus ini berarti peningkatan kinerja dapat diprediksi.
Cukup jalankan beberapa model kecil, pasangkan garis lurus itu, ekstrapolasi ke kanan, dapat memperkirakan kinerja model besar setelah dilatih. Tidak perlu benar-benar menghabiskan ratusan juta dolar untuk melatih model besar baru tahu kinerjanya.
Sebelumnya, deep learning selalu dicemooh sebagai "alkimia", tahu apa yang efektif, tidak tahu mengapa efektif.
Tahun 2020, tim Kaplan dari OpenAI mempublikasikan hukum pangkat (power law) ini, pertama kali menarik ilmu gaib ke wilayah "dapat diprediksi".
Inilah dasar keberanian semua perusahaan model besar untuk menanamkan uang.
Tapi saran paling krusial yang diberikan formula, dengan anggaran komputasi tertentu, bagaimana mengalokasikan antara model dan data, OpenAI dan DeepMind memberikan jawaban yang berlawanan.
Soal yang Sama
OpenAI dan DeepMind Menghasilkan Jawaban Berlawanan
Kesimpulan tim Kaplan dari OpenAI tahun 2020 adalah: Ukuran model optimal N_opt ∝ C^0.73.
Diterjemahkan: daya komputasi naik 10 kali, 5.5 kali untuk model, 1.8 kali untuk data—model harus tumbuh jauh lebih cepat daripada data.
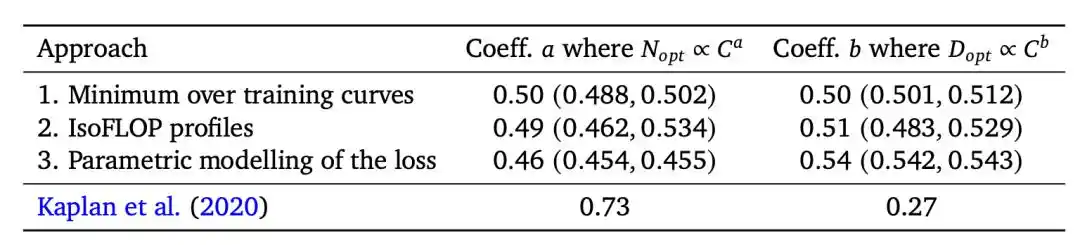
Ini langsung memandu skema pelatihan GPT-3.
Model 175 miliar parameter, hanya diberi makan 300 miliar token (token adalah unit terkecil teks yang diproses model, kira-kira satu kata setara dengan 1-2 token).
Menurut standar kemudian, ini termasuk latihan yang sangat tidak cukup (severely undertrained).
Tahun 2022, tim Chinchilla dari DeepMind mencapai kesimpulan berlawanan: N_opt ∝ C^0.50, model dan data harus tumbuh secara proporsional.

Insinyur kemudian menyaringnya menjadi angka yang mudah diingat: Rasio optimal token dan parameter sekitar 20:1.
Kemudian DeepMind melakukan pertandingan langsung.
Gopher mereka sendiri, 280 miliar parameter dengan 300 miliar token. Chinchilla, 70 miliar parameter dengan 1.4 triliun token. Kedua model menggunakan daya komputasi yang sama.
Chinchilla mengalahkan secara total.
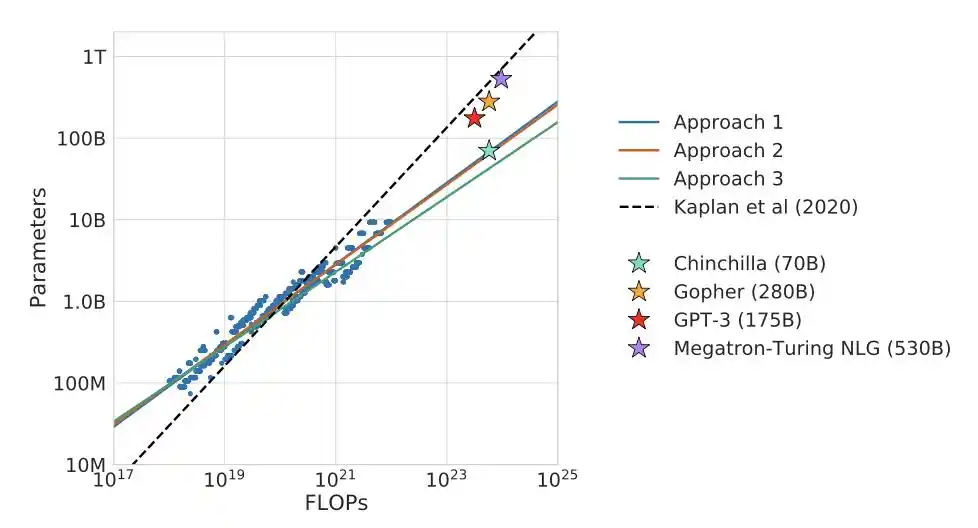
Model yang lebih kecil namun "banyak makan", mengalahkan lawan yang lebih besar namun "lapar".
Konsensus seluruh industri berbalik: dari "membuat model besar" menjadi "kebanyakan model kurang dilatih".
0.73 vs 0.50, soal yang sama, jawaban berlawanan, akan membuat Anda mengalokasikan anggaran komputasi ke dua arah yang sama sekali berbeda.
Penyebabnya Ternyata Masalah "Pencatatan"
Tahun 2024, dua peneliti menerbitkan makalah rekonsiliasi di jurnal puncak TMLR, menelusuri perbedaan ini hingga ke akarnya.
Kesimpulannya lucu dan menyedihkan.
Penyebab pertama: cara menghitung parameter berbeda.
Ada lapisan parameter dalam model yang disebut embedding, bertugas mengubah teks menjadi vektor angka yang dapat dipahami model. Pada model kecil, lapisan ini proporsinya sangat besar, model beberapa puluh juta parameter bisa mencapai sepertiga dari total.
Kaplan saat menghitung jumlah parameter mengecualikan embedding, sedangkan Chinchilla menghitungnya.
Hanya perbedaan statistik satu parameter ini, sudah cukup mendistorsi eksponen hukum pangkat (power law exponent) yang dihasilkan.
Mereka memberikan formula koreksi sederhana: N = N_\E + ω·N_\E^(1/3), di mana N_\E adalah jumlah parameter tanpa embedding, ω adalah konstanta. Pada model kecil, suku kedua proporsinya besar, pengaruh embedding signifikan; semakin besar model, suku kedua mendekati nol, kedua cara penghitungan bertemu.
Penyebab kedua: skala eksperimen Kaplan terlalu kecil.
Model terbesar yang diuji Kaplan hanya 1.5 miliar parameter, sedangkan eksperimen Chinchilla mencapai 16 miliar lebih. Dalam skala logaritmik, deviasi fitting kecil saat diekstrapolasi akan diperbesar secara drastis.
Mereka menggunakan statistik parameter yang seragam untuk menurunkan ulang formula Chinchilla, menemukan pola kunci—
Eksponen hukum pangkat akan berubah seiring meningkatnya skala komputasi. Dalam rentang eksperimen kecil Kaplan, eksponen memang mendekati 0.73; tetapi saat skala meningkat, eksponen konvergen ke 0.50.
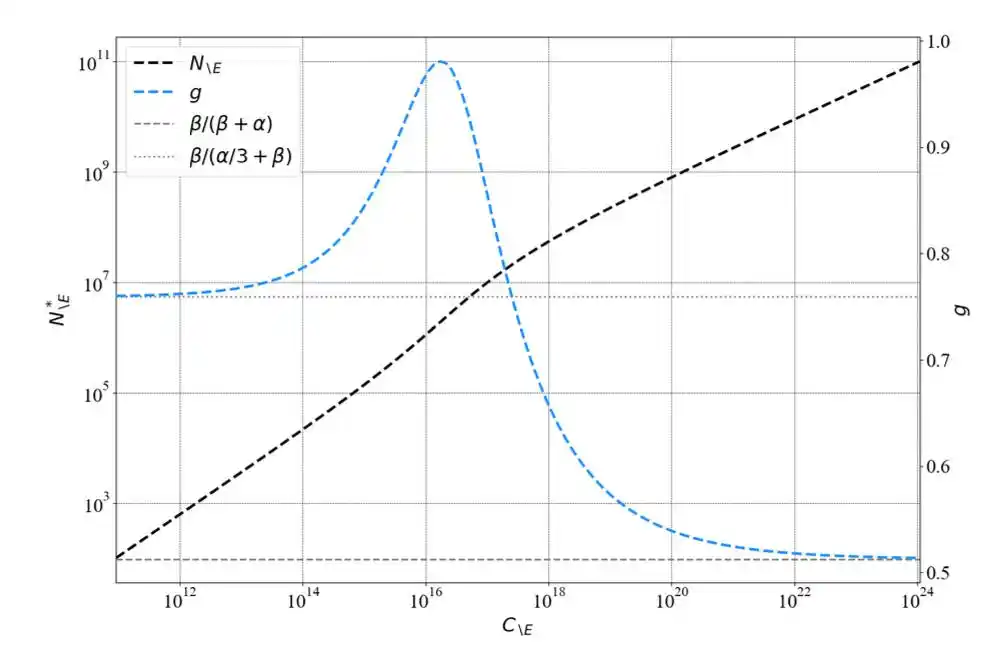
Kaplan tidak "salah", dia benar dalam rentang eksperimennya sendiri.
Tapi dia meng-ekstrapolasi pola yang berlaku lokal, menjadi kesimpulan global.
Masalah pencatatan bagaimana parameter dihitung, ditambah dengan skala eksperimen yang tidak cukup besar, membuat dua tim top memberikan saran alokasi sumber daya yang berlawanan.
Seluruh industri menyesuaikan resep pelatihan berdasarkan kesimpulan ini selama dua tahun.
Bahkan Pemenang Pun Ada Bug
Kaplan dikoreksi oleh Chinchilla, ini narasi standar yang diketahui semua orang.
Tapi Weng melangkah lebih jauh—Metodologi Chinchilla sendiri, juga bermasalah.
Makalah Chinchilla menggunakan tiga metode independen untuk memvalidasi silang kesimpulannya:
Metode 1: Ukuran model tetap, ubah jumlah data
Metode 2: Gambar kurva daya komputasi sama (IsoFLOP profiles)
Metode 3: Langsung lakukan fitting parameter pada rumus loss L(N,D) = E + A/N^α + B/D^β
Tiga jalan menunjuk ke kesimpulan yang sama, tampak sangat solid.
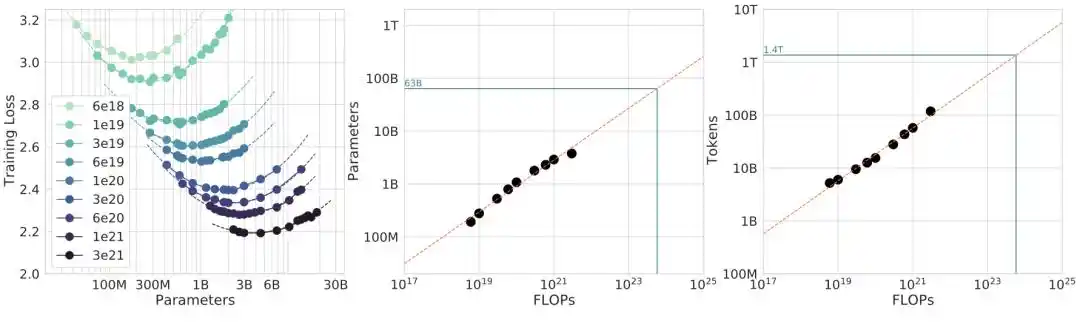
Turunan matematika Metode 3 sangat elegan: dalam kendala C ≈ 6ND, optimalkan L(N,D), dapat diperoleh solusi tertutup N_opt ∝ (C/6)^(β/(α+β)). Ketika α ≈ β, eksponen sekitar 0.5, artinya model dan data tumbuh secara proporsional. Ini adalah asal matematis 0.50.
Tahun 2024, tim dari lembaga penelitian AI, Epoch AI, mengekstrak titik data mentah dari grafik makalah Chinchilla secara manual, menjalankan kembali fitting Metode 3.
Dua bug, satu lebih tidak masuk akal dari yang lain.
Bug 1: Fungsi loss diambil rata-rata (mean) bukan penjumlahan (sum).
Saat fitting kelima parameter ini, Chinchilla perlu meminimalkan selisih antara loss prediksi dan loss aktual.
Tujuan optimisasi lengkapnya adalah: min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ), di mana Huber Loss adalah fungsi loss yang tidak sensitif terhadap outlier (δ = 10⁻³), dikombinasikan dengan optimizer L-BFGS-B untuk mencari solusi optimal.
Masalahnya ada pada detail: Mereka mengambil rata-rata (mean) untuk setiap sampel Huber Loss, bukan penjumlahan (sum). Ratusan sampel dirata-ratakan, nilai loss dikompresi ke tingkat yang sangat kecil.
Optimizer L-BFGS-B memiliki kriteria konvergensi bawaan. Ketika nilai loss cukup kecil, otomatis berhenti. Ia melihat nilai sekecil ini, mengira sudah konvergen, langsung berhenti.
Optimizer sebenarnya tidak selesai dijalankan. Parameter yang dihasilkan bukan nilai optimal sebenarnya.
Bug 2: Parameter kunci hanya dipertahankan dua desimal.
Dalam makalah Chinchilla ada dua eksponen inti yang mengontrol bentuk hukum pangkat, hanya dipertahankan hingga dua desimal.
Terlihat seperti pembulatan tidak berbahaya.
Tapi saat menurunkan konstanta lain dari dua angka kasar ini, error diperbesar secara eksponensial. Interval kepercayaan akhir menjadi terlalu sempit, sempit hingga membutuhkan presisi yang hanya dapat dicapai dengan lebih dari 600 ribu eksperimen, padahal mereka hanya melakukan kurang dari 500.
Formula yang dijadikan pedoman oleh seluruh industri, di belakangnya menyembunyikan bug fungsi loss yang tidak selesai dijalankan, dan bug ini tersembunyi selama dua tahun penuh.
Weng dalam blognya menyertakan simulator interaktif, tiga slider masing-masing mengontrol akurasi loss, noise loss, dan rentang fitting.
Setiap digeser, Scaling Law yang dihasilkan berubah bentuk.
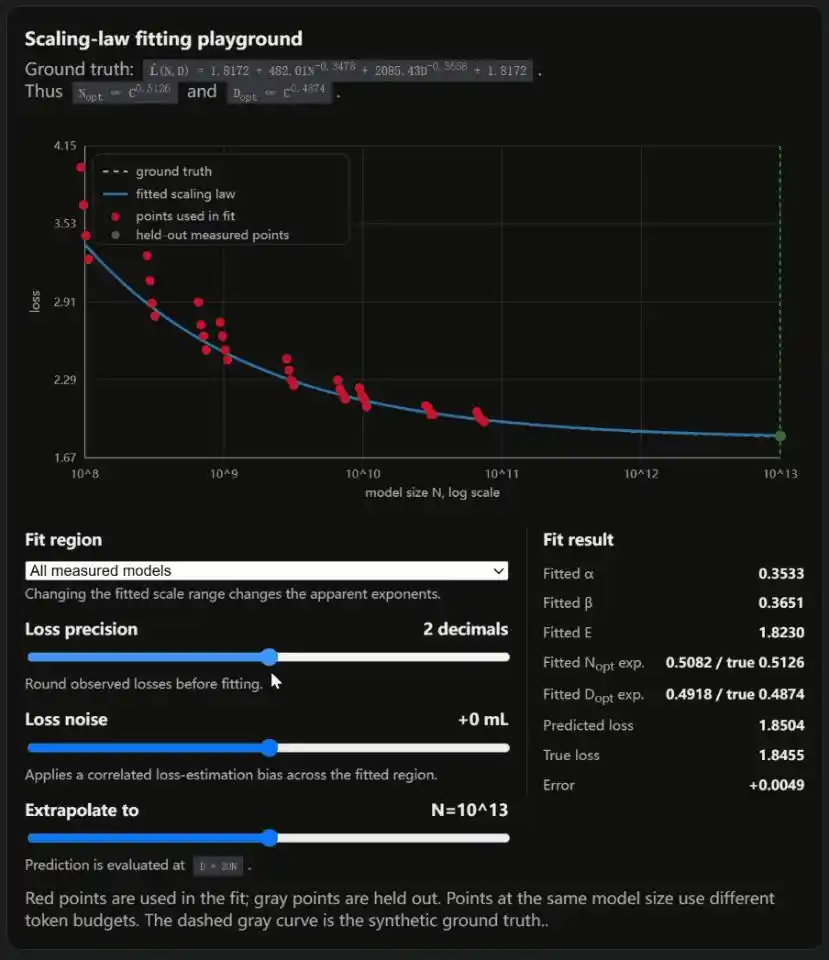
Kesimpulan OpenAI memiliki bias lokal, kesimpulan DeepMind memiliki cacat metodologi. Debat akademis terpenting industri AI, kedua belah pihak memiliki celah.
Data Hampir Habis Terbakar
Tiga bagian sebelumnya membahas masalah metode fitting, bagaimana parameter dihitung, bagaimana loss dihitung, presisi diambil berapa digit.
Tetapi bahkan jika semua masalah ini diperbaiki, Scaling Laws klasik masih memiliki kelemahan yang lebih mendasar—
Ia mengasumsikan setiap data pelatihan adalah unik, tidak berulang, tidak dilatih beberapa putaran, menganggap Anda memiliki data tak terbatas.
Kenyataannya, data teks berkualitas tinggi diperkirakan antara tahun 2026 hingga 2028 akan habis disapu oleh laboratorium besar.
Pelatihan data berulang tidak dapat dihindari, premis formula klasik sedang runtuh.
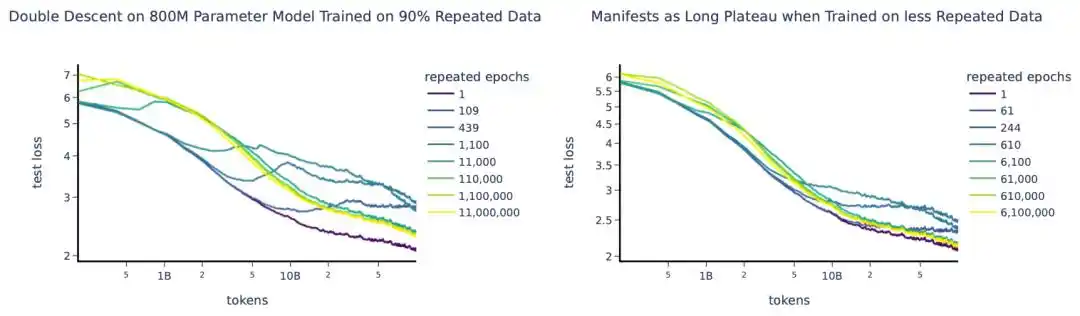
Eksperimen skala besar tahun 2023 melatih sekitar 400 model, dari puluhan juta hingga 9 miliar parameter, pelatihan berulang maksimal 1500 putaran.
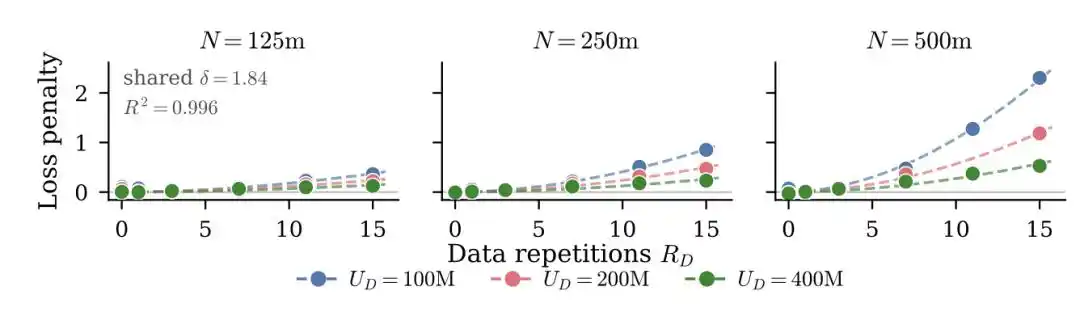
Inti pikirannya adalah memperkenalkan konsep "jumlah data efektif" untuk menggantikan jumlah data aktual—
Jika Anda memiliki U data unik yang diulang R putaran, jumlah data efektif bukan U×R, melainkan dikonversi sesuai kurva peluruhan eksponensial D_eff = U·(1 - e^(-R)). Pengulangan pertama masih dapat mempelajari banyak hal baru, tetapi pada putaran kelima, kesepuluh, manfaat pembelajaran marjinal mendekati nol.
Mereka juga menemukan kesimpulan kontra-intuitif: Parameter berlebih "terdepresiasi" lebih cepat daripada data berulang. Artinya, dengan anggaran terbatas, daripada memperbesar model, lebih menguntungkan menjalankan beberapa putaran pelatihan tambahan.
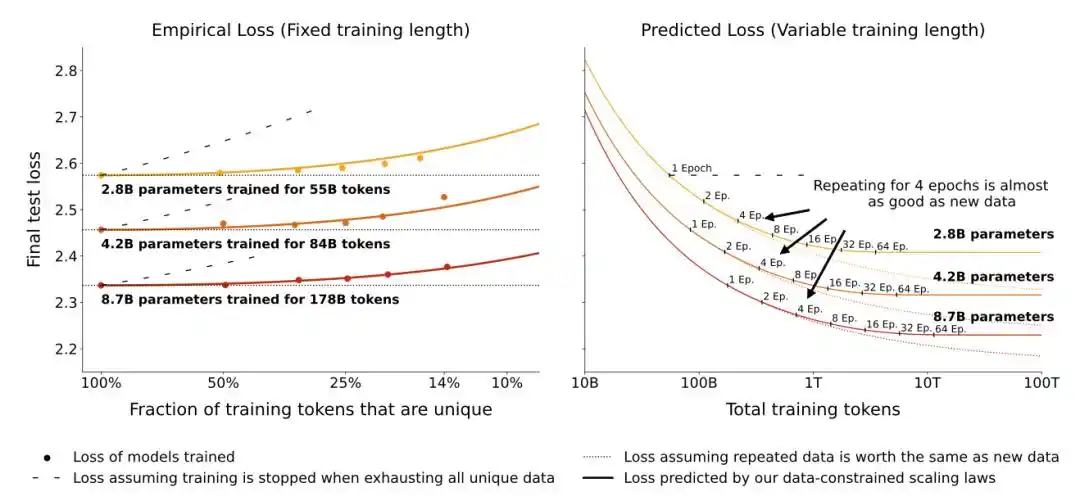
Makalah baru Mei 2026 mengambil pendekatan berbeda.
Mereka tidak mengkonversi jumlah data efektif, tetapi langsung menambahkan istilah penalti overfitting eksplisit di belakang rumus loss klasik—semakin sering model melihat data yang sama, penalti semakin besar, dan penalti ini terkait dengan ukuran model.
Rumus lengkap mereka seperti ini:
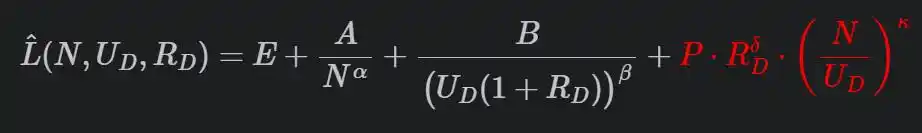
Istilah penalti merah terakhir adalah kuncinya.
R adalah jumlah pengulangan, N/U adalah rasio parameter model terhadap jumlah data unik (seberapa "berlebih" model relatif terhadap data), P, δ, κ adalah parameter yang di-fit dari eksperimen. Semakin banyak pengulangan, semakin besar model, penalti semakin berat.
Temuan inti makalah ini adalah: Model besar lebih sensitif terhadap pengulangan data. Data yang sama dilatih 10 putaran, model 500 juta parameter mungkin masih tahan, tetapi penurunan kinerja model 5 miliar parameter akan jauh lebih parah.
Temuan lain yang langsung berguna dalam rekayasa: Memperkuat weight decay dapat secara signifikan meredam overfitting akibat pelatihan berulang.
Inilah mengapa tahun 2025 hingga 2026, perhatian seluruh industri beralih secara kolektif ke tiga jalan untuk melewati tembok data—
Reinforcement learning, DeepSeek R1, OpenAI o-series, membuat model saling bermain dalam tugas yang dapat diverifikasi seperti matematika dan pemrograman, menghasilkan sinyal pelatihan.
Komputasi saat pengujian (test-time computation), tidak menambah biaya pelatihan, membuat model "berpikir" beberapa langkah lebih banyak saat menjawab pertanyaan untuk mendapatkan kinerja lebih baik.
Data sintetis, menggunakan model kuat yang ada untuk menghasilkan data baru untuk melatih generasi model berikutnya.
Subteks ketiga jalan sama: Hukum pangkat yang murni mengandalkan "menumpuk skala", sudah tidak cukup lagi.
Dari Peking University ke OpenAI ke Perusahaan Sendiri
Lilian Weng, sarjana Peking University, doktor dari Indiana University Bloomington.
Yang menarik, arah doktoralnya bukan deep learning, tetapi Network Science dan Complex Systems, mempelajari bagaimana informasi menyebar dalam jaringan sosial.
Setelah lulus, dia pertama kali bekerja di Dropbox sebagai data scientist, kemudian di perusahaan fintech Affirm, baru bergabung dengan OpenAI tahun 2018.
Tiba di OpenAI, proyek pertama Weng adalah robotika. Tangan robotik Dactyl yang menghabiskan dua tahun belajar menyelesaikan kubus Rubik, dia adalah kontributor intinya.
Kemudian beralih ke membangun tim penelitian aplikasi, setelah peluncuran GPT-4 ditugaskan membentuk tim Safety Systems, saat dia meninggalkan OpenAI, tim ini sudah memiliki lebih dari 80 ilmuwan, insinyur, dan ahli kebijakan.
Agustus 2024 jabatan naik menjadi VP of Research and Safety, tiga bulan kemudian mengumumkan keluar.

Tahun 2017, Weng baru mengenal deep learning, membuka blog pribadi bernama Lil'Log, awalnya hanya untuk mengatur catatan belajarnya.
Dia pernah berkata, "Menjelaskan konsep dengan jelas adalah cara terbaik untuk menguji apakah diri sendiri benar-benar memahaminya".
Hasilnya, menulis selama sembilan tahun, reinforcement learning, model difusi, agent model besar, setiap artikel dimulai dari prinsip dasar, puluhan halaman artikel panjang dilengkapi diagram buatan sendiri.
Blog ini kemudian menjadi salah satu blog teknologi pribadi yang paling banyak dikutip di bidang AI, banyak universitas langsung menjadikannya sebagai buku teks.
Februari 2025, dia dan mantan CTO OpenAI, Mira Murati, mendirikan Thinking Machines Lab, co-founder termasuk juga co-founder OpenAI John Schulman, mantan VP penelitian Barret Zoph dan Luke Metz. a16z memimpin putaran seed 20 miliar dolar, valuasi 120 miliar.
Dan sambil perusahaan berjalan dengan kecepatan tinggi, dia meluangkan waktu menyelesaikan artikel panjang tentang Scaling Laws yang telah ditunda tiga tahun ini.
ChatGPT, Claude, Gemini yang Anda gunakan setiap hari, di belakangnya formula-formula ini yang menentukan bagaimana generasi berikutnya dilatih.
AI generasi berikutnya bagus atau tidak, tidak tergantung siapa yang memiliki GPU lebih banyak, tetapi tergantung siapa yang menangani detail-detail ini dengan lebih presisi.
Referensi:
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
Artikel ini berasal dari akun WeChat "Xin Zhi Yuan", penulis: ASI Qishilu, editor: Moshe


![Menilai Penurunan Harga 12% Sonic [S] dan Mengapa Penjualan Lebih Lanjut Kemungkinan Akan Menyusul](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)




