Satu baris import, fine-tuning model besar MoE 3.7 kali lebih cepat.
Hasil penelitian terbaru NVIDIA kini tersedia sumber terbuka: NeMo AutoModel, dirancang khusus untuk membangun dan melakukan fine-tuning model AI generatif skala besar.
Dengan dasar Hugging Face Transformers v5, NeMo AutoModel mampu melakukan fine-tuning model MoE lebih cepat hanya dengan menambahkan satu baris import, tanpa mengubah kode atau API.

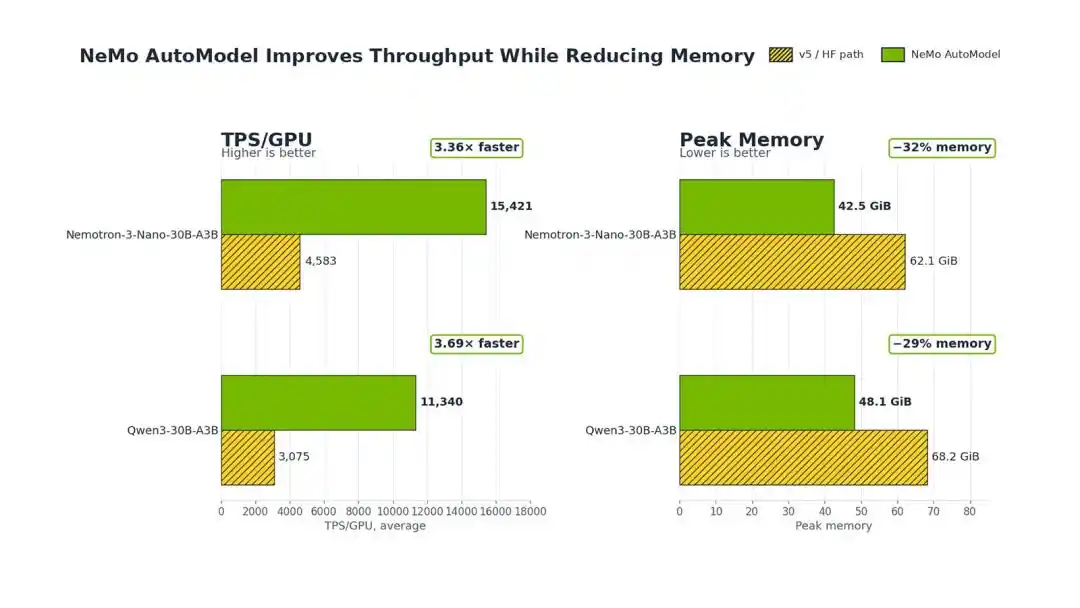
Eksperimen menunjukkan, dibandingkan dengan versi asli Hugging Face Transformers v5, NVIDIA NeMo AutoModel dapat mencapai peningkatan throughput pelatihan sebesar 3.4-3.7 kali dalam fine-tuning MoE, serta mengurangi penggunaan memori GPU sebesar 29%-32%.
Pada node tunggal dengan 8xH100 GPU 80GB, dengan contoh Qwen3-30B-A3B, NeMo AutoModel langsung meningkatkan TPS/GPU (throughput per detik per GPU) dari 3075 menjadi 11340, peningkatan mencapai 3.69 kali.
Analisis Inti Teknologi
MoE telah menjadi arsitektur utama model terkini, namun MoE juga membawa tantangan baru untuk pelatihan yang efisien:
Expert Parallelism, fusi komunikasi, optimisasi kernel... infrastruktur pendukung diperlukan untuk semua rekayasa kompleks ini.
HuggingFace Transformers v5 saat ini adalah "landasan umum" untuk pelatihan MoE yang banyak digunakan. V5 meningkatkan dukungan native untuk MoE, memperkenalkan kemampuan dasar MoE seperti expert backends, dynamic weight loading, dan eksekusi terdistribusi.

Kali ini, pendekatan NVIDIA adalah berdiri di atas pencapaian sebelumnya, kompatibel dengan API HuggingFace Transformers, sehingga memungkinkan pengguna untuk tidak banyak mengubah kode, namun mendapatkan throughput pelatihan yang lebih tinggi dan penggunaan memori yang lebih rendah dalam fine-tuning MoE.
Secara spesifik, NeMo AutoModel menambahkan Expert Parallelism (EP), DeepEP, dan TransformerEngine di atas Transformers v5.
Expert Parallelism (Paralelisme Ahli)
Teknologi Expert Parallelism terutama digunakan untuk mengurangi tekanan memori.
EP mendistribusikan bobot expert ke beberapa GPU, setiap GPU tidak lagi menyimpan seluruh parameter expert, tetapi hanya sebagian dari mereka.
Sebagai contoh, pada 8 GPU dengan ep_size=8, bobot expert didistribusikan ke 8 GPU, penggunaan memori MoE per GPU dapat turun menjadi 1/8 dari aslinya.
Dari hasil eksperimen, untuk Qwen3, teknologi ini dapat menurunkan memori puncak dari 68.2GiB menjadi 48.1GiB, penurunan 29%.
Untuk model Nemotron Nanomo, penggunaan memori turun dari 62.1 GiB menjadi 42.5 GiB, penurunan 32%.
Ruang yang dibebaskan dapat digunakan untuk mendukung ukuran batch yang lebih besar atau urutan yang lebih panjang.
DeepEP
DeepEP mencapai fusi komputasi dan komunikasi.
Dalam metode tradisional, ada biaya komunikasi yang jelas antara distribusi token dan komputasi expert. DeepEP mengintegrasikan operasi distribusi dan penggabungan token ke dalam kernel GPU yang dioptimalkan, mencapai tumpang tindih antara proses komunikasi dan komputasi expert.
TransformerEngine
Kernel TransformerEngine memberikan akselerasi untuk berbagai operasi inti.
Teknologi ini menyediakan implementasi fused untuk mekanisme perhatian, lapisan linier, dan RMSNorm, tidak hanya mempercepat lapisan MoE tetapi juga lapisan Transformer biasa.
Satu Baris 'import', Peningkatan Kecepatan 3 Kali Lipat
Kesimpulannya, bagi pengguna yang sudah menggunakan Transformers v5, NVIDIA NeMo AutoModel menawarkan solusi upgrade tanpa rasa sakit:
Cukup tambahkan satu baris kode import, untuk mendapatkan peningkatan kecepatan fine-tuning MoE 3 kali lipat.

Pada Qwen3-30B-A3B dan Nemotron 3 Nano 30B-A3B, dibandingkan dengan Transformers v5, solusi ini dapat mencapai peningkatan throughput pelatihan 3.4-3.7 kali, sambil mengurangi konsumsi memori sebesar 29%-32%.
NVIDIA juga menunjukkan hasil fine-tuning parameter penuh untuk Nemotron 3 Ultra 550B A55B pada 16 node H100 dengan 128 GPU.
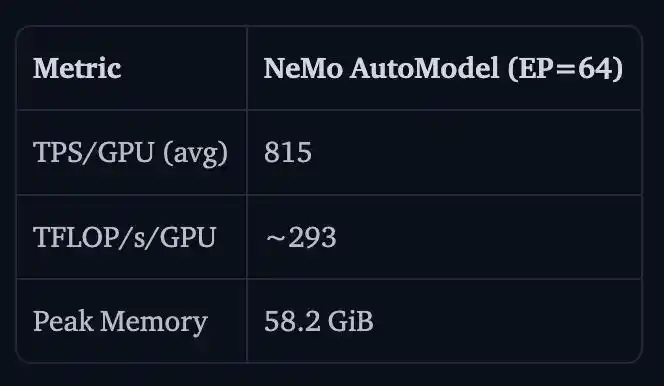
TPS/GPU adalah 815, TFLOP/s/GPU sekitar 293, memori puncak adalah 58.2GiB.
Alasan tidak ada perbandingan dengan v5 di sini adalah karena Transformers v5 pada skala ini akan langsung membuat memori meluap ̄_(ツ)_/ ̄
Jika tertarik, NVIDIA telah menyediakan kode, konfigurasi, dan skrip benchmark di GitHub: https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
Panduan penggunaan spesifik ada di sini: https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
Artikel ini berasal dari akun WeChat publik "Qubit", penulis: Yu Yang






