
Google Research publicó recientemente un artículo cuyo argumento central se puede resumir en una frase: En lugar de empeñarse en "hacer que la IA lo sepa todo", es mejor enseñarle a decir "No estoy seguro".
Este artículo, titulado "Hallucinations Undermine Trust; Metacognition is a Way Forward" y realizado conjuntamente por Google Research y la Universidad de Tel Aviv, ha sido aceptado en el ICML 2026 Position Track. El documento propone que el enfoque principal de la industria de la IA para combatir las "alucinaciones" podría estar fundamentalmente equivocado: todos están ocupados infundiendo más conocimiento a los modelos, pero ignoran una capacidad más crucial y subestimada: permitir que la IA perciba y exprese su grado de certeza sobre cada respuesta.
(Dirección del artículo: [2605.01428] Hallucinations Undermine Trust; Metacognition is a Way Forward)
Impuesto a la utilidad: el verdadero costo de eliminar las alucinaciones
Empecemos con una escena que todos hemos experimentado.
Le haces una pregunta a un asistente de IA, y él responde con un tono de total certeza, con un lenguaje preciso y una lógica completa, aparentemente impecable. Después verificas, y la respuesta es completamente inventada. Lo que más molesta es que no dudó en absoluto al decirlo, como si lo hubiera visto con sus propios ojos.
Esto es una "alucinación" de la IA: el modelo produce contenido factualmente incorrecto, pero se lo presenta al usuario de una manera que no admite dudas. Este problema es particularmente crítico en escenarios de alto riesgo, como la medicina, el derecho y la investigación científica.
El enfoque de la industria para abordar las alucinaciones se reduce esencialmente a dos vías. La primera: hacer que la IA sepa más, ampliando los datos de entrenamiento y aumentando los parámetros del modelo para cubrir más hechos. La segunda: hacer que la IA se abstenga de responder cuando no esté segura, rechazando directamente las preguntas sobre las que no tenga certeza.
Ambas vías tienen limitaciones evidentes. Los hechos del mundo son infinitos, un modelo no puede recordar todo, por lo que la primera vía siempre tendrá puntos ciegos. El problema de la segunda vía es que, una vez que la IA comienza a rechazar respuestas a gran escala, pasa de ser un "asistente útil" a un "inútil que no se atreve a decir nada"; el usuario hace diez preguntas, ocho son rechazadas, la experiencia es pésima.
El artículo le da un nombre preciso al costo de la segunda vía: "Impuesto a la utilidad" (utility tax) — para reducir la tasa de alucinaciones, debes sacrificar una gran cantidad de información que podría haber respondido correctamente.
¿Por qué este impuesto es tan alto? La raíz está en que a la IA le falta una habilidad clave. Para que la estrategia de "rechazar respuestas" sea precisa, el modelo necesita distinguir con precisión entre "acerté esta pregunta" y "me equivoqué en esta pregunta" — rechazar solo las incorrectas, conservar las correctas. Pero en realidad, los modelos no pueden hacer esta distinción precisa. El artículo diferencia dos conceptos fácilmente confundibles pero con significados completamente distintos para explicar este problema.
Calibración (calibration) mide si el nivel general de confianza de la IA coincide con su tasa general de aciertos. Por ejemplo, si la IA responde 100 preguntas, cada vez diciendo "Estoy 60% seguro", y de las 100 preguntas acierta exactamente 60, eso es una calibración perfecta.
Discriminación (discrimination) mide si la IA puede distinguir con precisión, en cada pregunta específica, entre "acerté" y "me equivoqué". Una IA que da un 60% de certeza a todas las preguntas, con una tasa de aciertos general del 60%, tiene una calibración perfecta, pero una discriminación de cero — es completamente incapaz de distinguir cuáles creer y cuáles desconfiar. Una buena calibración no equivale a una discriminación fuerte, este es el meollo del problema.
Tras revisar numerosa literatura, el artículo descubrió que los principales modelos de gran tamaño actuales en tareas de preguntas y respuestas de conocimiento real tienen índices de discriminación (AUROC) que oscilan entre 0.70 y 0.85. Este número suena decente, pero en realidad está lejos de ser suficiente. El artículo realizó una simulación usando AUROC=0.71 como parámetro, y los resultados son alarmantes: suponiendo una tasa de error base de la IA del 25%, para reducir la tasa de error al 5%, la IA debe rechazar más del 52% de las preguntas correctas. Incluso si la discriminación mejora a 0.85, un nivel cercano al techo reportado en la literatura, aún se debe abandonar el 28% de las respuestas correctas. Solo cuando la discriminación alcanza 0.95 o más, el costo se vuelve insignificante — y actualmente ningún método se acerca a este número en tareas intensivas en conocimiento.
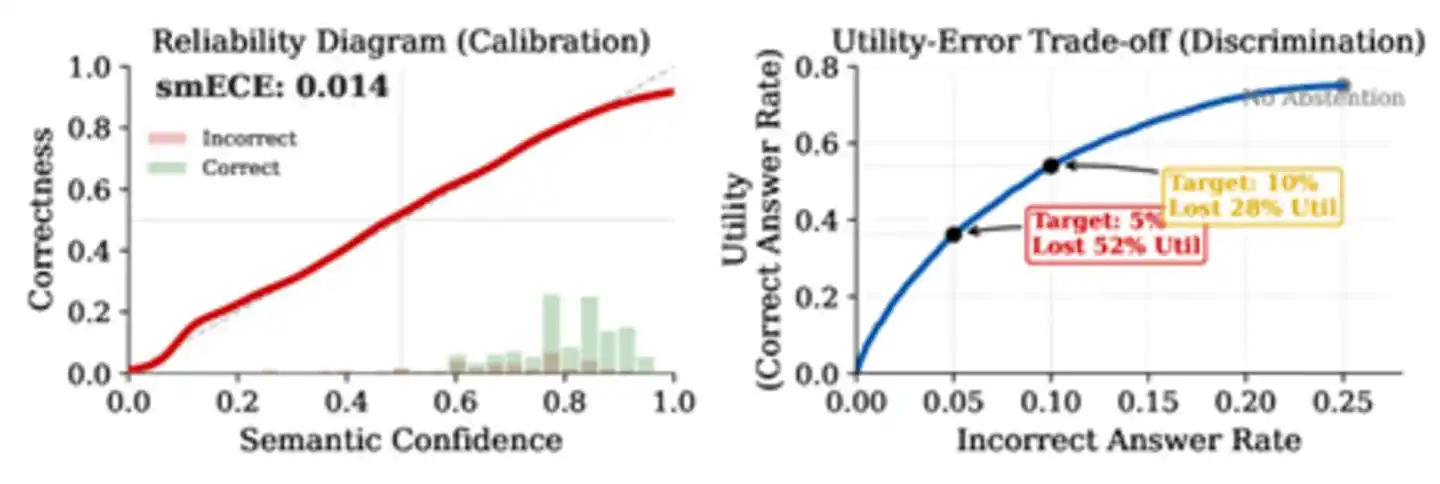
Figura: Diferencia entre calibración y discriminación. El gráfico izquierdo muestra que el modelo está bien calibrado (la línea roja se acerca a la diagonal), el gráfico derecho revela la cruda realidad — incluso con una calibración perfecta, para reducir la tasa de error del 25% al 5%, se debe sacrificar el 52% de las respuestas correctas.
Los datos reales confirman esta conclusión. El artículo analizó el rendimiento de varios modelos de vanguardia en la prueba de referencia SimpleQA Verified, y los resultados son claros y algo crueles: la mayoría de los modelos se distribuyen a lo largo de la diagonal "más respuestas, más errores"; unos pocos modelos que buscan alta precisión logran una mayor precisión por pregunta al rechazar muchas respuestas, pero a un enorme costo de utilidad. Esa región ideal en la "esquina superior derecha" — responder mucho y errar poco — actualmente está vacía. Este vacío es precisamente la "brecha de discriminación" mencionada en el artículo.
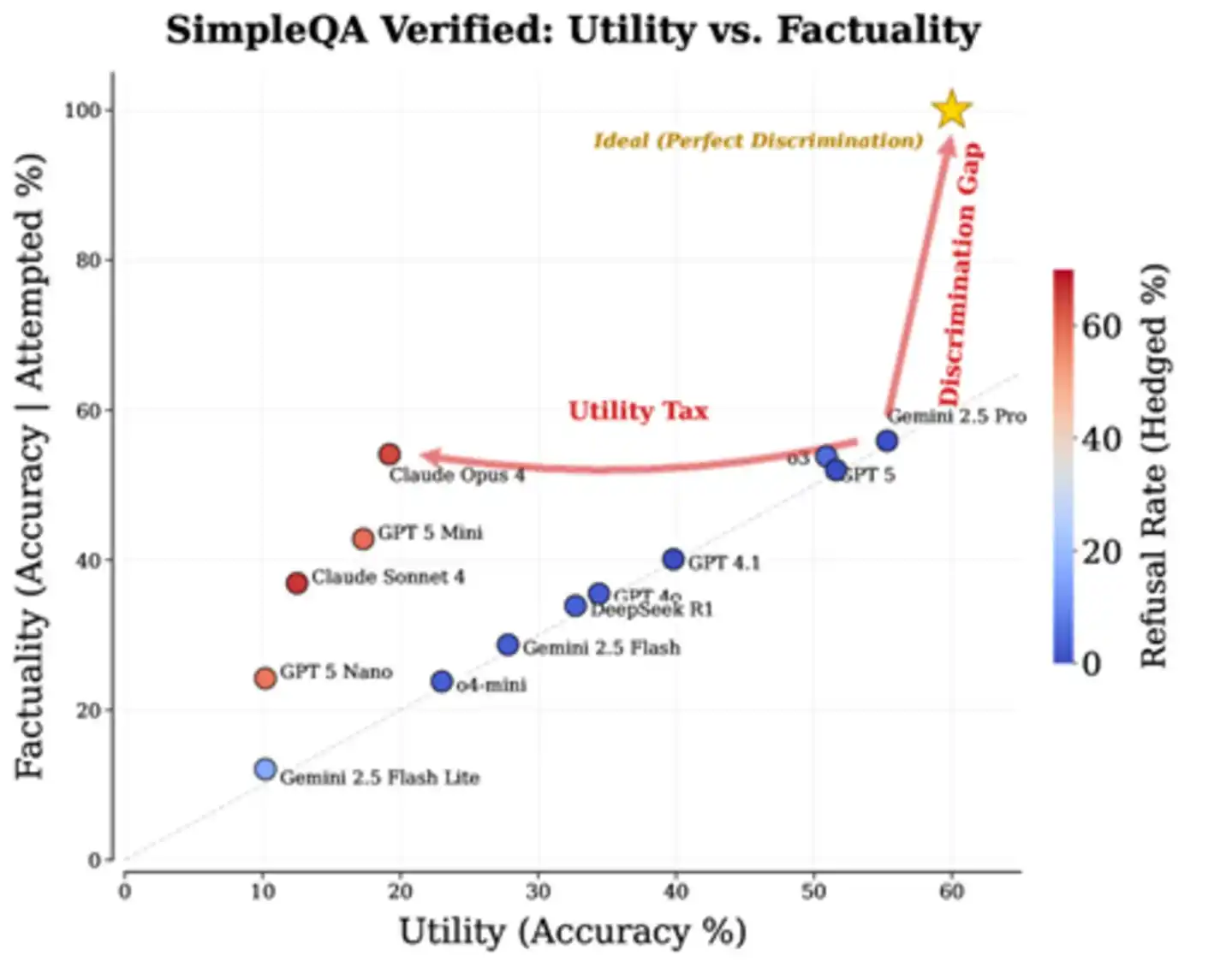
Figura: Rendimiento medido de los principales modelos en SimpleQA Verified. La estrella de cinco puntas en la esquina superior derecha es el objetivo ideal; "Discrimination Gap" marca el abismo entre los modelos existentes y el ideal; "Utility Tax" marca el costo de utilidad que paga Claude Opus 4 para obtener alta precisión.
Ya que "infundir más conocimiento" tiene puntos ciegos, y "abstenerse si no está seguro" es demasiado costoso, ¿existe una tercera vía?
Redefiniendo la alucinación: no es "decir algo incorrecto", sino "afirmar con certeza sin tener derecho a hacerlo"
La contribución central del artículo no está en diagnosticar el problema, sino en redefinir el problema mismo.
Durante mucho tiempo, la industria definió la "alucinación" como "la IA produce información errónea", lo que implica una premisa: eliminar alucinaciones = eliminar todos los errores. Pero el artículo propone verlo desde otro ángulo — la alucinación no es "la IA dice algo incorrecto", sino "la IA no tiene derecho a estar segura, pero da información errónea con un tono de certeza".
Esta distinción parece sutil, pero sus implicaciones son profundas. Por ejemplo: un médico, tras ver un informe, dice "tienes la enfermedad X". Si en realidad solo lo está adivinando por intuición, eso es irresponsable. Pero si dice "los síntomas actuales apuntan a X, pero se necesita más confirmación", incluso si el diagnóstico preliminar es incorrecto, esta forma de expresarse es honesta — le está diciendo al paciente "tome este juicio con precaución". El error no es inaceptable; lo inaceptable es fingir certeza cuando no la hay.
Basándose en esta nueva definición, surge la tercera vía: Incertidumbre Fidedigna (faithful uncertainty) — hacer que el grado de certeza expresado por la IA a nivel lingüístico corresponda fielmente al grado de certeza de su estado interno.
Concretamente, la "incertidumbre interna" de la IA se puede medir objetivamente mediante muestreo repetido: hacer la misma pregunta cien veces; si cada vez da la misma respuesta, significa que está segura internamente; si las respuestas son variadas, significa que internamente está indecisa. La "incertidumbre lingüística" es la sensación de certeza reflejada en la redacción de la IA — "4 de agosto de 1961" y "Creo recordar que fue 1961, pero no estoy completamente seguro" dan señales completamente diferentes al lector.
La Incertidumbre Fidedigna requiere que ambas se alineen: cuando internamente está indecisa, su redacción debe dejar margen; solo cuando internamente está segura debe usar un tono definitivo. El artículo enfatiza que este objetivo es más factible que "eliminar todos los errores". La razón es que la Incertidumbre Fidedigna solo requiere que la salida lingüística de la IA corresponda con su estado interno — este es un problema de circuito cerrado, la señal está dentro del modelo, no depende de la verdad externa. Eliminar errores requiere que la salida de la IA corresponda completamente con la verdad del mundo externo; el problema de la parada y la teoría de la computación citadas en el artículo indican que existen limitaciones teóricas fundamentales para esto.
El artículo resume esta capacidad en un concepto superior: Metacognición (metacognition) — la IA puede tanto percibir su propia incertidumbre como ajustar su comportamiento basándose en esa percepción. Este concepto está tomado de la psicología, donde significa "el conocimiento sobre los propios procesos cognitivos". En el contexto de la IA, significa que la IA tiene una conciencia clara de lo que sabe y lo que no sabe.
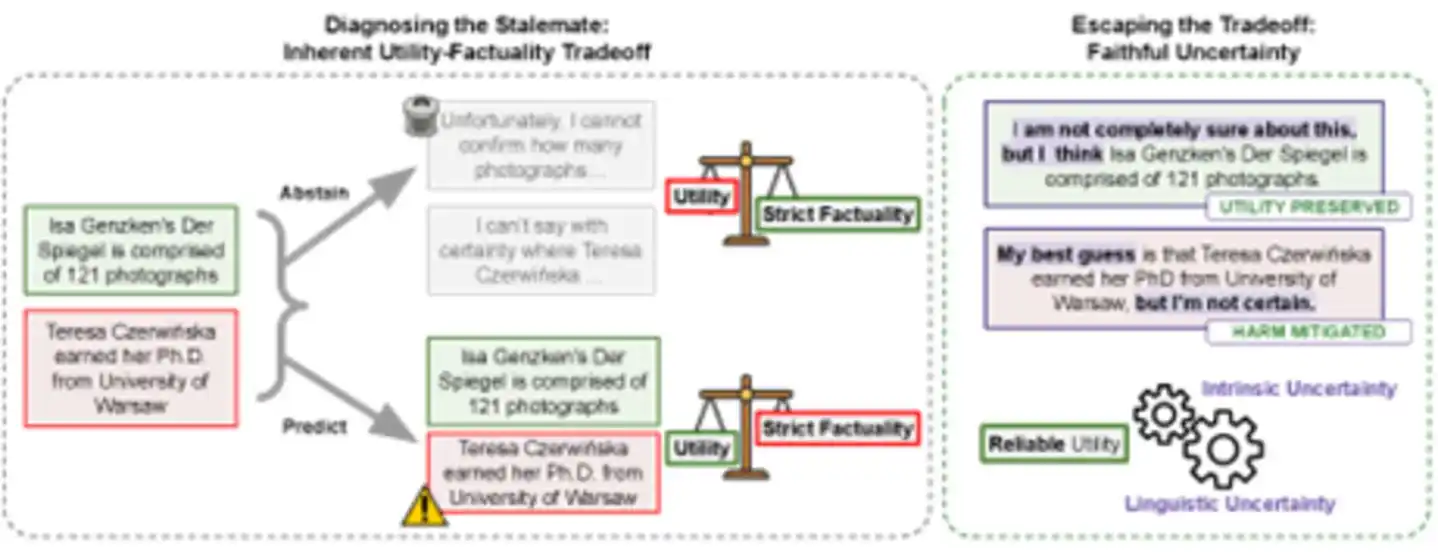
Figura: A la izquierda, el dilema tradicional — "responder" conlleva riesgo de alucinación, "rechazar respuesta" tiene un costo de utilidad. A la derecha, la nueva vía — al expresar fielmente la incertidumbre, se conserva la información útil y se minimiza el daño de la información errónea, logrando una "utilidad confiable".
La era de los agentes de IA: un Agent sin metacognición está "volando a ciegas"
El valor de la metacognición no se limita a escenarios de diálogo. En la era de los Agentes de IA (Agent), se vuelve aún más crítico.
Superficialmente, equipar a la IA con un motor de búsqueda resolvería el problema de la falta de conocimiento — si no sabe, que busque, ¿qué miedo a las alucinaciones? Pero el artículo señala que las herramientas no introducen una "solución de almacenamiento", sino un "problema de control".
Con herramientas, la IA enfrenta una serie de nuevas decisiones: ¿Yo sé esto? ¿Necesito buscar? ¿La información encontrada es confiable? Si los resultados de la búsqueda contradicen mi información, ¿a quién le hago caso? ¿Cuándo debo dejar de buscar?
Todas estas decisiones dependen de que la IA perciba con precisión su grado interno de certeza. Un Agente de IA sin capacidad metacognitiva es como un piloto sin panel de instrumentos — el motor ya está dando la alarma, y él sigue acelerando.
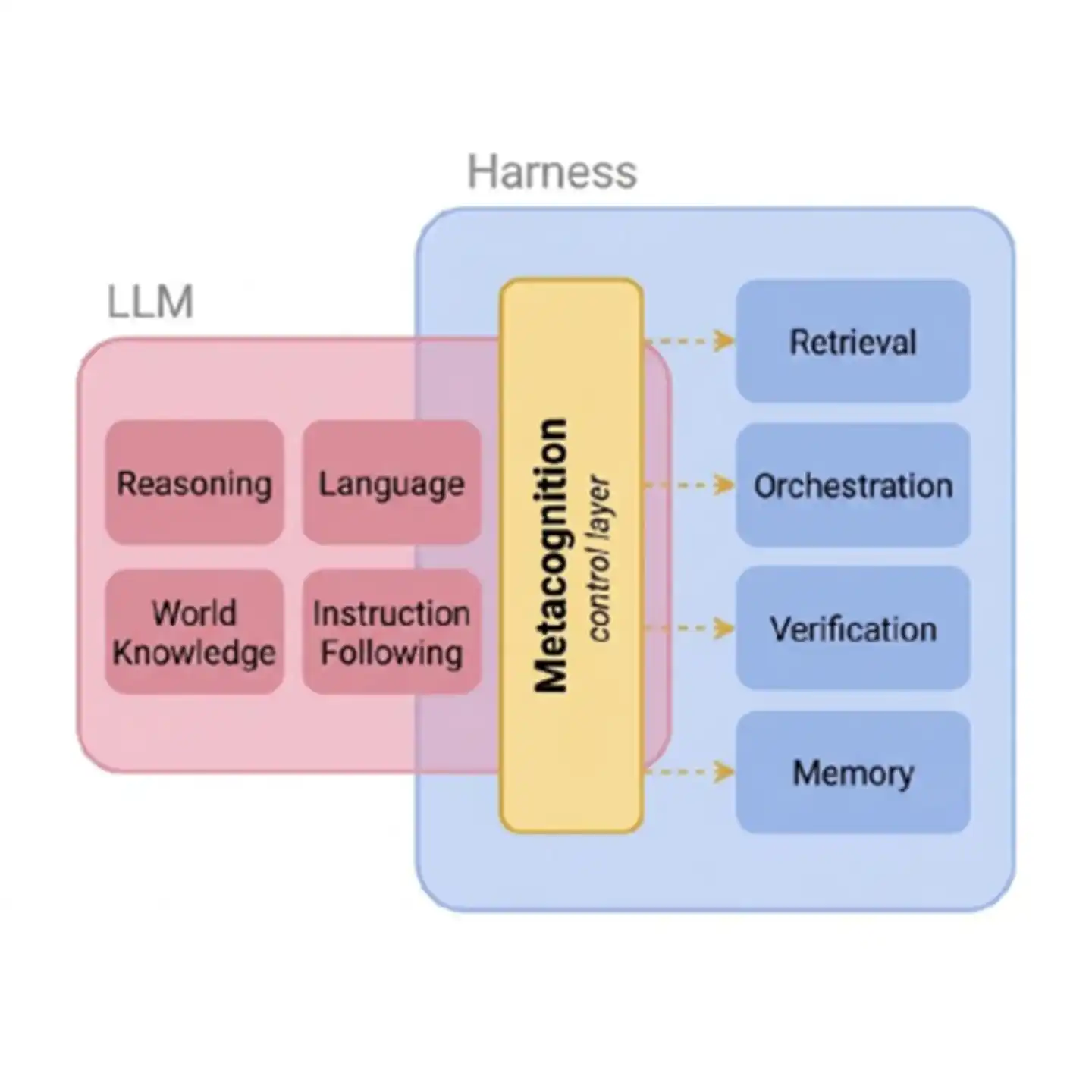
Figura: La capa de control metacognitivo como puente entre las capacidades básicas de la IA y el sistema de herramientas externas. Sin esta capa, la gestión de herramientas externas por parte del Agent es como "volar a ciegas" — no sabe si debe buscar, si debe creer lo encontrado, o en qué grado creerlo.
La investigación citada en el artículo muestra que los agentes de IA potenciados por búsqueda actuales sufren comúnmente de abuso de herramientas — buscan incluso preguntas que no requieren búsqueda, siendo ineficientes e introduciendo ruido innecesario. La razón es simple: una IA sin metacognición simplemente no puede juzgar "¿necesito información adicional?".
En el camino hacia la metacognición, aún quedan algunos desafíos difíciles
El artículo también señala honestamente los desafíos clave en el camino de implementación.
"Paradoja del autocarga (bootstrapping)": Enseñar a la IA a expresar incertidumbre requiere datos de entrenamiento que ejemplifiquen "dudar cuando corresponde", pero los límites del conocimiento de la IA son dinámicos. Una muestra de datos etiquetada como "No estoy seguro" podría convertirse, tras la evolución del modelo, en algo que sabe con certeza. Enseñar una capacidad dinámica con datos estáticos entrenará a una IA que "finge incertidumbre". Esto requiere desarrollar una infraestructura de datos dinámica que refleje los límites actuales del conocimiento del modelo.
"Destrucción de señales de alineación (alignment)": Los estudios encuentran que, después del pre-entrenamiento, la IA ya posee una señal de incertidumbre interna bastante buena — su estado interno puede distinguir entre "esta pregunta la tengo clara" y "esta pregunta no estoy tan seguro". Pero entrenamientos como RLHF (Reinforcement Learning from Human Feedback) desgastan esta señal. La razón es que las preferencias humanas favorecen respuestas con tono seguro, lo que obliga a la IA a aprender a proyectar seguridad externamente sin importar cuán indecisa esté internamente.
"Evaluación de causalidad": Un problema más profundo es cómo asegurar que la IA realmente esté leyendo sus señales internas, y no simplemente haya aprendido un patrón superficial como "cuando vea una palabra rara, diga 'No estoy seguro'". Distinguir entre "metacognición real" y "representación de la metacognición" es un problema fundamental de evaluación científica.
El artículo también hace recomendaciones específicas a la comunidad investigadora: Dejar de evaluar métodos contra alucinaciones usando solo un número único de precisión. Deberían visualizarse las curvas completas de "compensación utilidad-tasa de error", para ver claramente si un método realmente mejora la capacidad de discriminación subyacente, o simplemente ajusta el umbral de rechazo en la misma curva. También se debe detectar el "daño colateral" — para reducir la tasa de error en preguntas de conocimiento, ¿se ha pagado un precio inesperado en tareas de razonamiento, programación o escritura?
En última instancia, el mensaje central que este artículo quiere transmitir es: La IA no tiene que ser omnisciente, pero debe tener un conocimiento honesto de lo que sabe y lo que no sabe, y comunicar ese conocimiento al usuario.
Confiamos en los profesionales, no porque nunca cometan errores, sino porque pueden distinguir honestamente entre "Estoy seguro" y "Estoy adivinando" — es esta distinción la que marca la diferencia entre lo profesional y lo no profesional. La IA también debería transitar este camino. En lugar de perseguir interminablemente la ilusión de ser perfecta e infalible, es mejor enseñarle a la IA algo más práctico: saber cuándo está diciendo tonterías, y decírselo honestamente al usuario. (Este artículo se publicó por primera vez en Titanium Media APP, autor | Silicon Valley Tech_news, editor | Jiao Yan)






