La conferencia de desarrolladores Google I/O 2026 dejó una única impresión: arrogancia.
No solo integró agentes de IA como relleno, incrustándolos sin fisuras en todas las principales puertas de entrada de tráfico como búsqueda, navegador, teléfono móvil, gafas inteligentes, sino que también lanzó de forma consecutiva tres bombazos: Gemini 3.5 Flash, el modelo de video Omni y el nuevo asistente de IA Spark.
Después de mostrar músculo, Sundar Pichai incluso anunció de manera presuntuosa que los usuarios activos mensuales de Gemini superaron los 900 millones; y anunció simultáneamente una importante reducción de precios.
El mensaje no podría ser más claro:Soy mejor que tú y además más barato.
¿Qué es esto si no es una declaración de guerra?
01
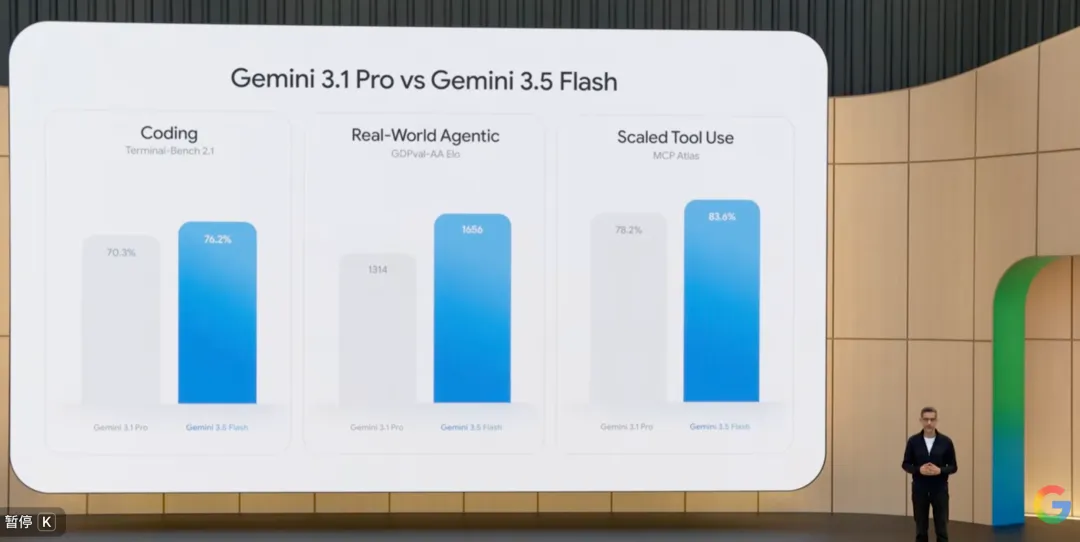
Lo más impresionante de la conferencia fue, sin duda, la aparición de Gemini 3.5 Flash.
Normalmente, "Pro" representa la fuerza principal, "Flash" representa ligereza y velocidad.
En términos de parámetros del modelo, 3.5 Flash es efectivamente más pequeño que 3.1 Pro, pero en casi todas las pruebas de referencia de razonamiento y codificación, el rendimiento del primero fue superior:
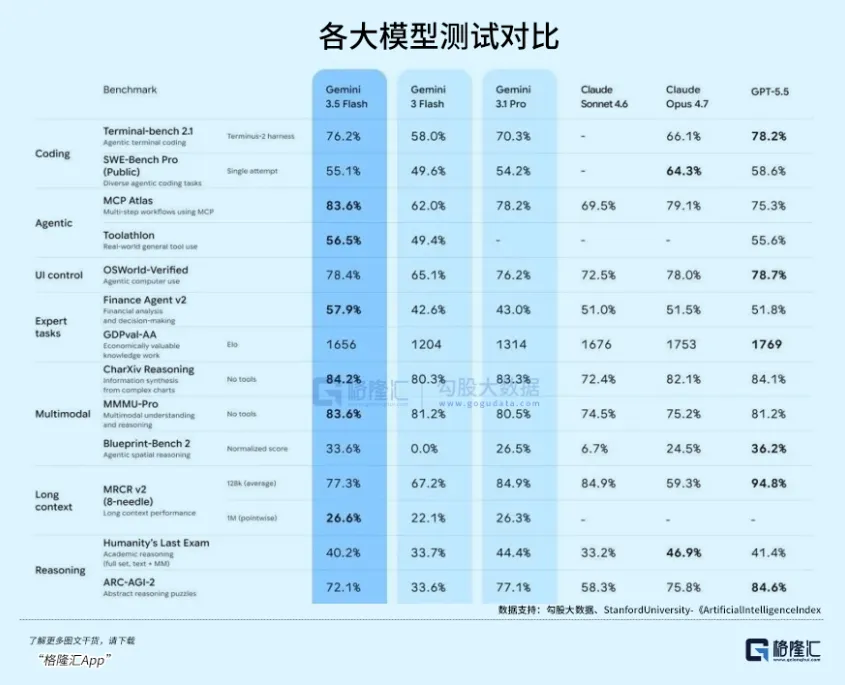
En la prueba GSM8K de razonamiento matemático complejo, 3.5 Flash obtuvo un 95,8%, superando el 93,2% de 3.1 Pro; en la versión completa de SWE-bench para capacidad de generación de código, la tasa de resolución de 3.5 Flash alcanzó el 38,4%, superando ampliamente el 32,1% de 3.1 Pro...
¿Por qué?
Según el "Gemini 3.5 Technical Report" publicado por DeepMind, hay dos tecnologías centrales clave.
Destilación de conocimiento extrema: Google esta vez no entrenó Flash simplemente apilando potencia de cálculo, sino que utilizó el nunca antes revelado "Gemini 3.5 Ultra" como modelo maestro, realizando una destilación de reducción de dimensionalidad en Flash.
Según el análisis del tuit del científico jefe de DeepMind, Jeff Dean, la proporción de ajuste fino de 3.5 Flash en conjuntos de datos de cadena lógica de alta calidad aumentó en un 400% en comparación con la generación anterior.
Esto significa que heredó el "cerebro lógico" del modelo supergrande, no una "base de conocimiento" memorizado.
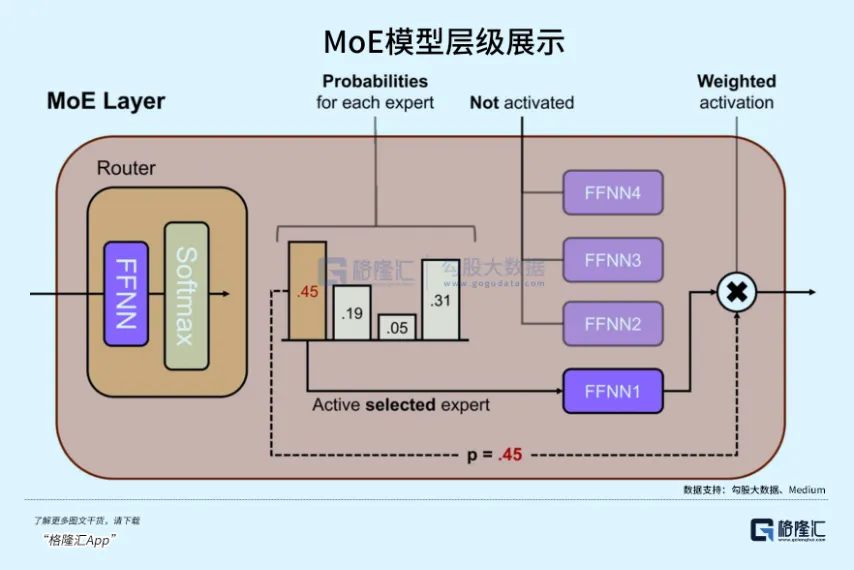
Nueva arquitectura MoE (Modelo Mixto de Expertos): Dentro de 3.5 Flash, Google adoptó redes de expertos de granularidad más fina.
El MoE tradicional podría tener solo 8 o 16 expertos, activando solo 1-2 cada vez, suficiente para soportar modelos a escala de billones de parámetros.
Según el análisis del memorando de inversión en infraestructura de IA de a16z de 2026, 3.5 Flash adoptó 256 micro expertos, activando los 4 más eficientes en cada inferencia.
Por eso puede mantener un volumen de parámetros activados extremadamente bajo mientras cubre un espacio de características multimodales extremadamente amplio.
En el indicador TTFT (Tiempo hasta el Primer Token), 3.5 Flash ya alcanza los 65 milisegundos.
Mientras que un parpadeo humano requiere entre 100 y 150 milisegundos.
En resumen, cuando funciona como un agente inteligente, desde la perspectiva fisiológica humana, es imposible detectar cualquier pausa.
Para los desarrolladores que necesitan llamar a herramientas con frecuencia, realizar múltiples rondas de reflexión y tener una latencia extremadamente baja, este es el sustrato perfecto para un súper agente.
Solo apoyándose en una optimización de ingeniería tan extrema es posible establecer un poder dominante de "implementación en el dispositivo" en un entorno altamente competitivo.
Primero, Gemini Omni Flash multimodal nativo.
Omni significa omnipotente, rivalizando directamente con el anterior GPT-4o. Solo con el nombre, se puede sentir la intensidad de la pólvora.
Al menos en términos de rendimiento, Gemini Omni Flash está mucho más calificado para usar el carácter "o" que GPT-4o.
Los primeros Sora o Gemini 1.5 eran básicamente engendros cosidos, convirtiendo voz a texto, y luego texto a visión.
Pero el Omni lanzado esta vez es una verdadera alineación multimodal de extremo a extremo nativa. No solo entiende de forma nativa la coherencia temporal y las leyes físicas en el video, sino que la latencia también se redujo del promedio de la industria de 400-600 ms a 120 ms.
Un ejemplo de la conferencia: un usuario con una cámara llenando un vaso, y cuando el vaso está casi lleno, Omni puede decir "¡Para, para, para!" 0,5 segundos antes de que el agua se desborde.
Este tipo de inferencia en tiempo real del estado físico del mundo real parece simple, pero es de gran importancia: La IA ha evolucionado oficialmente de un chatbot en pantalla a una herramienta auxiliar en el mundo real.
Aunque solo en una etapa inicial.
Segundo, el asistente inteligente Spark.
Según la revelación en una entrevista de The Verge con el vicepresidente de ingeniería de Android, a Spark se le otorgó control nativo a nivel de API del sistema Android 17.
En resumen, los flujos complejos que antes requerían abrir muchas aplicaciones, ahora no necesitan que muevas un dedo, solo tienes que ordenar a Spark y él lo manejará todo, incluso puede enviar mensajes, organizar correos, resumir agendas, rastrear dinámicas web, identificar cargos ocultos en facturas, procesar documentos por lotes, etc., según tu tono y preferencias...
En otras palabras, con el asistente de IA, básicamente ya no necesitaremos aplicaciones, cualquier operación compleja se simplifica en una única interacción.
Tercero, las gafas inteligentes.
¿Por qué gafas de nuevo?
Al menos en opinión de Google, la integración perfecta de visión y audición es el huésped final para los grandes modelos multimodales.
Estas gafas no tienen una apariencia llamativa, se enfocan completamente en la capacidad práctica:
Lentes de guía de onda Micro-OLED a todo color de solo 4 gramos de peso, con una tasa de transmisión de luz de hasta el 85%;
Equipado con el chip propio Gemini optimizado para dispositivos, latencia de inferencia local ≤12ms, capaz de realizar traducción en tiempo real, reconocimiento de imágenes, análisis de escenas sin necesidad de conexión a Internet;
Integración nativa con el agente inteligente Spark, sincronizando datos del teléfono y la nube, logrando servicios personalizados como recordatorios de agenda, traducción en tiempo real, alertas ambientales.
En resumen, es traspasar la pantalla del teléfono e incrustar el agente inteligente en la primera perspectiva humana a través de las gafas.

Hay demasiado contenido. Google parece haber vaciado de una vez todas sus grandes bazas, declarando una verdad al mercado:
Un algoritmo sin punto de entrada no es nada.
La era de competir en parámetros de modelos grandes y puntuaciones de referencia ha terminado. Los proveedores puros de modelos ya no tienen barreras defensivas. El futuro es una guerra cuatridimensional de "dispositivo + nube + ecosistema + hardware".
Integrar la IA en el paquete familiar está remodelando la lógica de distribución del tráfico de Internet: pasando de "búsqueda/clics activos del usuario" a "distribución activa de servicios por parte del agente inteligente de IA".
Para la gran mayoría de desarrolladores y pequeñas y medianas empresas, esto es excelente, ya que el cómputo subyacente y los modelos se vuelven extremadamente baratos, y todos pueden concentrarse en la innovación a nivel de aplicación.
Pero otros competidores probablemente solo quieran maldecir en este momento.
02
Cuando Sundar Pichai anunció con despreocupación en el escenario que "los usuarios activos mensuales de Gemini superaron oficialmente los 900 millones", causó un gran revuelo entre la audiencia.
900 millones, más que todos los MAU de los competidores estadounidenses combinados.
¿Cómo se logró?
La respuesta es simple y brutal: integración forzada.
Google no necesita gastar en publicidad para adquirir usuarios como lo haría una empresa de IA independiente, solo necesita agregar un ícono al lado de la barra de direcciones del navegador Chrome, integrar un acceso directo de activación en la barra de navegación inferior de los 3.000 millones de teléfonos Android, enviar actualizaciones masivas en Google Workspace...
El costo de adquisición de usuarios es básicamente igual a cero.
Más crucial es que, durante el próximo período, los gestos de los 900 millones de usuarios activos diarios al mirar productos con las gafas inteligentes, las lógicas corregidas al procesar asuntos con Spark, y las interacciones con el modelo visual Omni, generarán enormes cantidades de datos de retroalimentación de alta calidad, multimodales y del mundo real, que se convertirán en nutrientes para alimentar a Gemini 4.
Esta es una barrera extremadamente sólida: Cuanto mejor es el modelo -> más personas lo usan -> más datos se generan -> el modelo se vuelve mejor.
Para fortalecer rápidamente este ciclo, Google anunció directamente una guerra de precios a todos sus competidores: el paquete AI Ultra se redujo de $249.99/mes a $99.9/mes.
3.5 Flash llegó a un precio de entrada de 1 millón de tokens de $0.02, y un precio de salida de 1 millón de tokens de $0.08.
¿Qué clase de precio celestial es este?
Comparando, los precios promedio de la industria para modelos de nivel similar son respectivamente $0.15-$0.2 y $0.6-$1.
Sundar Pichai calculó: los clientes principales procesan aproximadamente 1 billón de tokens por día. Transferir el 80% de la carga de trabajo a Gemini 3.5 Flash durante un año puede ahorrar más de $10 mil millones.
¿Por qué se atreven a vender la IA a precios de ganga?
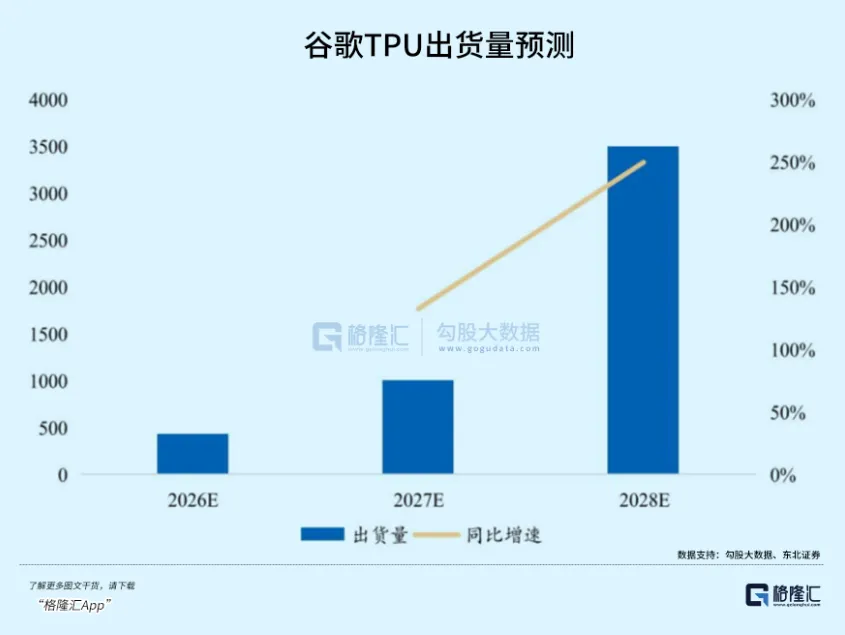
El mayor apoyo es: infraestructura de cómputo integrada verticalmente.
Incluyendo gigantes como OpenAI, Anthropic, que parecen exitosos, son esencialmente "inquilinos de cómputo", necesitan comprar cómputo a Microsoft, Amazon, y estos últimos a su vez pagan a Nvidia.
Mientras que Google tiene sus propios TPU, más la eficiencia de activación dispersa extremadamente anormal de 3.5 Flash MoE, que comprime el costo de cómputo al máximo.
Puede utilizar completamente su ventaja de activos pesados para lanzar un ataque de reducción dimensional contra empresas de puros algoritmos.
La lógica es clara.
Los modelos básicos grandes se están mercantilizando rápidamente. Como el agua y la electricidad, ¿has visto alguna empresa de agua con beneficios exorbitantes?
A Google no le preocupa que el modelo grande en sí no sea rentable, porque puede recuperar el dinero a través de anuncios de búsqueda, servicios en la nube y comisiones del ecosistema Android.
Pero para aquellos que dependen puramente de vender la API del modelo grande para vivir, como OpenAI, Anthropic, Cohere, Mistral, esto es imposible.
Los inversores probablemente quieran presionar a Sam Altman y preguntar: "El precio de la API de Google es solo una décima parte del tuyo, y el rendimiento es mejor que el tuyo, ¿dime, cómo se sostiene tu modelo de negocio?"
El panorama competitivo de múltiples industrias entrará así en un período de reestructuración acelerada.
Los fabricantes de IA no necesitan decirlo, deben encontrar rápidamente fuentes de cómputo más baratas, o empezar a hacer sus propios chips.
Luego está Apple, que todavía trabaja en secreto.
La combinación de gafas inteligentes + modelo de video grande Omni + integración nativa a nivel de sistema Spark amenaza claramente al iPhone.
Según el "Informe de predicción de tendencias de electrónica de consumo" de Macquarie: en los próximos tres años, se espera que la proporción de tiempo de interacción sin pantalla basada en visión/voz aumente del 8% actual al 35%.
Si los usuarios se acostumbran a completar el trabajo y el entretenimiento diario con gafas y voz, el tiempo de uso de la pantalla inevitablemente se comprimirá significativamente.
Si Apple no presenta un dispositivo portátil lo suficientemente impresionante para contraatacar (Vision Pro es demasiado pesado y caro, destinado a ser solo un juguete para unos pocos), su monopolio de la entrada en la era de Internet móvil enfrentará un desafío sin precedentes.
Esto no es una iteración, es una revolución.
Google ha lanzado un desafío a todos sus oponentes con tres armas: tecnología, tráfico y precio.
¿En este momento, alguien todavía se burla de que sufre de burocracia empresarial?






