This year, the three major US AI giants have been labeling their own model products with some "sci-fi" tags.
OpenAI says ChatGPT has learned to "dream"; Anthropic wants to give Claude a built-in "personal Wiki"; Google claims Gemini "natively comes with ten years of your memories".
These three statements seem unrelated, but they are actually competing for the same thing—Context.
Early on, Context was just an unremarkable technical parameter, measuring how many characters a model could process at once. Today, the meaning of Context is broadening: it is user assets, tool permissions, the real-time state of a task's progress, and ultimately, how well the AI understands you.
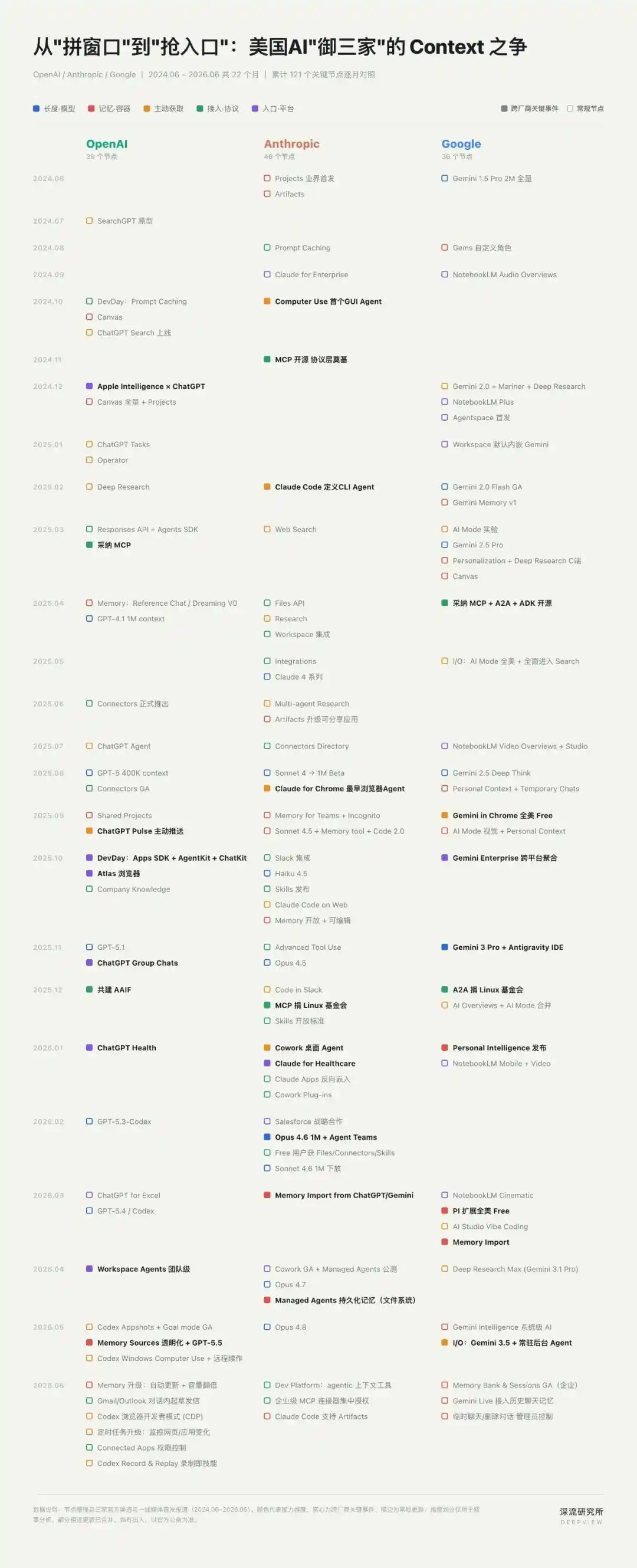
According to "Deep Flow Research Institute," since the beginning of this year, OpenAI, Anthropic, and Google have released over 40 important product and feature updates centered around Context—on average, a new capability hits the market every three to four days.
From long-context windows to cross-session Memory, to browser, desktop, and GUI capabilities, almost all the most significant changes in AI products over the past two years have revolved around Context.
A war over "Context" has already begun, which is quietly reconstructing the moats of the AI era.
1. From Long Windows to the Real Environment: Three Leaps in the Boundaries of Context
The earliest competition over Context happened in "text length."
In the Chatbot era, Context primarily meant how much information a model could ingest at one time. The longer the window, the more capable the model was at handling papers, codebases, even complete project documentation. Thus, OpenAI, Anthropic, and Google ignited an arms race in context window length.
In May 2023, Anthropic led the charge by extending Claude's context window from 9K to 100K, equivalent to about 75,000 words, making "uploading an entire book" a reality for the first time. In November 2023, OpenAI followed up with GPT-4 Turbo's 128K window. Three months later, Google pushed the window to the million-level with Gemini 1.5 Pro.
In less than a year, Context leaped from the hundred-thousand level to the million level.
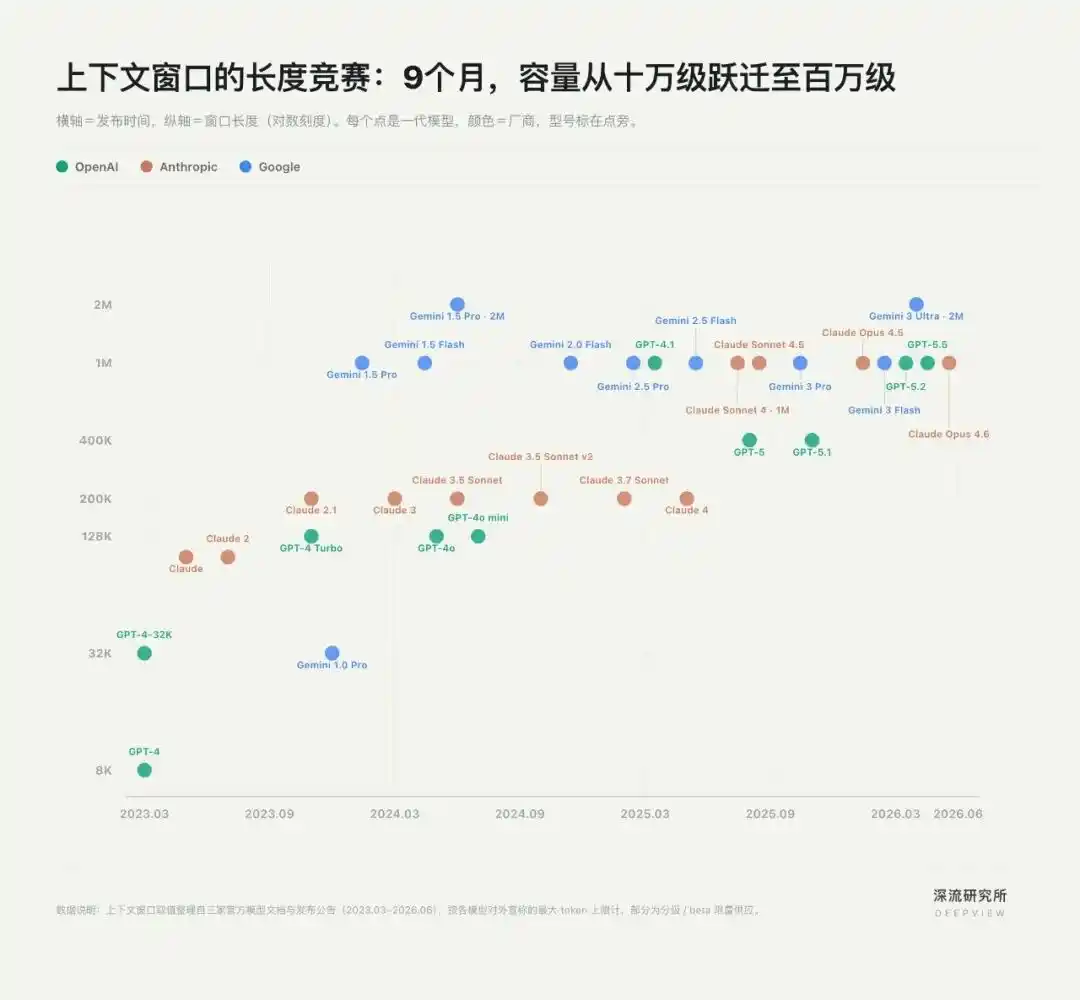
Long windows solved the AI's "throughput" problem, but this race quickly exposed its limitations: the model seeing more information doesn't necessarily mean it can better understand the task.
Especially as AI products evolved from Chatbot to Agent, the boundaries of Context began to change. It was no longer just the input text in a single conversation, but the continuously accumulating, dynamically updated state flow within the task loop.
The focus of competition shifted accordingly: from "how much the model can know at once" to "what the model can remember long-term." Memory became the typical product form of this stage.
In early 2024, OpenAI was the first to introduce cross-session memory for ChatGPT, allowing the model to remember user preferences, backgrounds, and long-term needs. Subsequently, Anthropic and Google also equipped Claude and Gemini with memory capabilities.
Context began to have a time dimension. AI no longer only processed the current input; it also started trying to establish continuity between a user's interactions today, last week, and last month. Only AI with long-term Context could string discrete interactions into an ongoing relationship.
However, Memory answers "what happened in the past," but hasn't yet touched upon an even more critical question: what is happening now?
The real watershed moment appeared in the second half of 2025.
Starting in August of that year, the three companies almost simultaneously pushed the Context front to the browser: Anthropic released Claude for Chrome, Google embedded Gemini into Chrome, and OpenAI launched the standalone AI browser ChatGPT Atlas.
The browser is a natural Context goldmine. Web content, search intent, login status, forms, history, tabs, and the tasks the user is executing are all deposited within the browser. More importantly, the Context here is more real-time, continuous, and closer to the actual task site.
Previously, the way AI obtained Context was essentially still waiting for the user to deliver materials: uploading files, inputting instructions, authorizing memory, connecting data sources.
After entering the browser, the logic changed. AI began entering the user's work environment, observing page state, understanding task progress, capturing operational intent, and executing the next step within the real interface.
This was the third leap in Context boundaries: it transformed from static data input on the model side to the dynamic state captured by Agents in GUI, web pages, and system environments.
Long windows determine how much information the model can ingest at once; Memory determines whether the model can understand the user across time; browser, desktop products, and GUI capabilities determine whether the model can enter the real task site.
Together, these three constitute the main thread of AI product competition over the past two years: Context is no longer just a model capability issue; it is gradually becoming a product entry point issue, a user relationship issue, and an asset accumulation issue.
2. Context Becomes the New Battleground: Three Paths for the US AI "Big Three"
When Context evolves from a model parameter to a user asset, the core of competition becomes: who can more stably acquire, organize, and invoke Context.
Centered on this, OpenAI, Anthropic, and Google have taken three differentiated paths.
ChatGPT is OpenAI's most core source of Context.
Memories, preferences, historical tasks, and tool usage records left by users in countless conversations gradually accumulate under the same ChatGPT account.
This account differs from traditional internet accounts. Traditional accounts record login status, subscription relationships, and payment information; ChatGPT accounts record the user's "history understood by AI."
This is an AI-native user asset. Its value lies not only in more personalized answers but also in reducing cold-start costs, continuing task states, and reusing the same set of user understanding across different product scenarios.
For OpenAI, lacking Google's native data ecosystem, it must have users continuously generate new Context within the ChatGPT system.
Therefore, OpenAI's product moves over the past two years have consistently expanded the task radius that the ChatGPT account can cover—the Apps SDK brings third-party apps into ChatGPT, Atlas brings the browser into ChatGPT, and the newly integrated Codex brings programming tasks into the same workflow.
OpenAI's unique path lies in not first controlling the entry point and then plugging AI into it; rather, it takes ChatGPT as the origin point and pulls application, browser, programming, and other scenarios back into the same account system.
ChatGPT thus is no longer just a conversational entry point but a hub for converging, invoking, and updating Context.
In contrast, Anthropic lacks both C-end entry points and large-scale existing user data.
Its path is to cut into high-value vertical scenarios like Coding and Agent and strengthen Claude's ability to actively acquire Context within these scenarios.
For Claude, Context is not a piece of text input by the user but the dynamically changing environment within the task site: codebases, file systems, terminal output, browser pages, databases, project documentation, and feedback after each execution step.
Therefore, Anthropic emphasizes the proactivity of Context acquisition more. The model should not just wait for user input; it should also actively enter the environment, read the state, and obtain feedback during task execution.
In October 2024, Anthropic launched Computer Use, allowing Claude to move the mouse, click buttons, and input text based on screen captures.
According to the official statement, Claude 3.5 Sonnet is the first frontier AI model publicly offering computer use capabilities.
This means that when Context exists in web pages, forms, backend system interfaces, and local software UIs, rather than in structured APIs, Claude can still enter the environment via GUI, observe the state, and execute operations.
A month later, Anthropic released MCP. This open protocol connecting AI assistants with external tools and data sources is officially defined as connecting AI assistants to "systems where data resides," including content libraries, business tools, and development environments.
Its value lies in allowing Claude to no longer rely on users copy-pasting but to access external tools and data sources through standardized methods.
These two types of capabilities correspond to Anthropic's two paths for acquiring Context:
Computer Use enters interfaces via GUI; MCP connects systems via protocol. One enters the task site; the other connects to external tools, collectively enabling Claude to obtain dynamic Context.
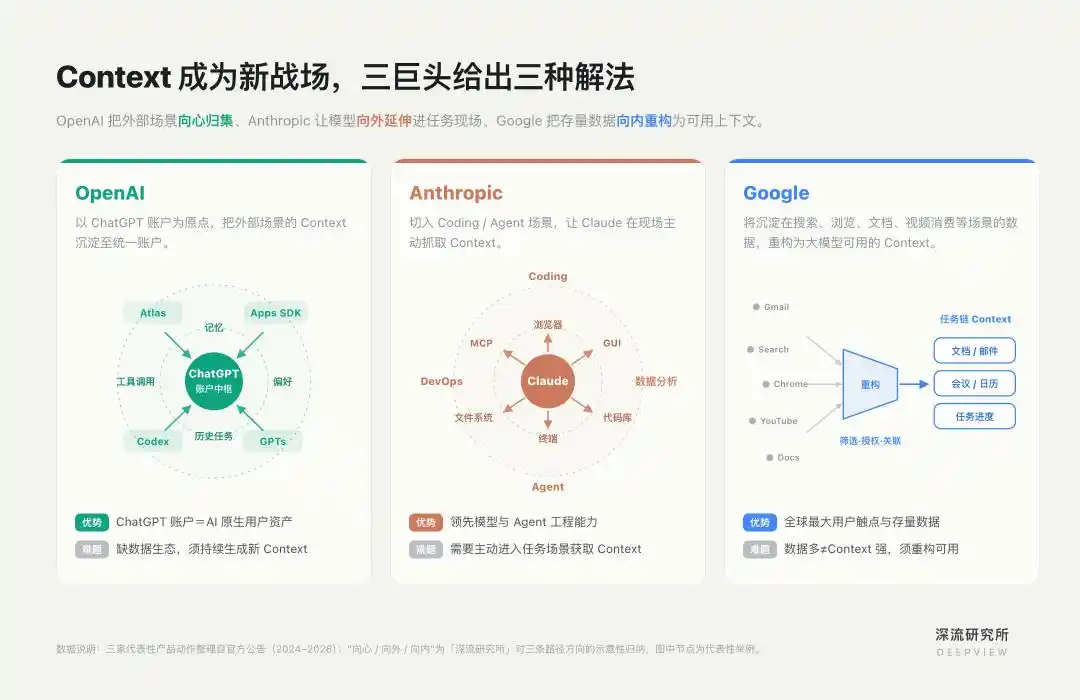
Now, looking at Google. It's often said externally that Google is one of the companies with the most Context. It lacks neither entry points nor data. Products like Chrome, Gmail, YouTube, and Search constitute one of the largest collections of user touchpoints globally.
But from an AI perspective, more data does not equal stronger Context.
What Google accumulated in the past was search, browsing, email, documents, location, video consumption, and other data, primarily serving search ranking, ad delivery, content recommendation, and office collaboration. They are essentially behavioral signals needed for system operation.
What Agents need is task background that can be understood, reasoned about, and invoked by models.
Only when a model can judge which information is relevant to the current task, which is outdated, which can be invoked, and how these pieces of information are related, does data truly become Context.
The challenge Google faces is not simply "accessing data," but a data refactoring. It needs to re-screen, correlate, authorize, and transform old data scattered across different products, serving different system goals, into personal context usable by Gemini.
The difficulty of this engineering task is no less than OpenAI re-accumulating Context or Anthropic entering the task site.
Over the past two years, Google's product moves have not been starting from scratch but reforming inward along its existing strongholds. The core of this path is organizing fragmented data into task chains.
In May 2024, Gemini 1.5 Pro entered the Workspace sidebar, allowing the model to first invoke current context within work scenarios like Gmail, Docs, and Drive.
In July 2025, the Gemini app began connecting to tools like Gmail, Drive, and Calendar, extending Context from a single application to cross-application tasks.
In January 2026, Personal Intelligence launched a test version, further incorporating personal data like Gmail and Photos into Gemini's personalized background.
Google's Context strategy is not "we have more data, so we're naturally ahead."
What it truly needs to accomplish is a data usability engineering project: transforming historically accumulated behavioral data serving system goals like search, ads, and recommendation into understandable, authorizable, actionable Context for the AI era.
3. From "Network Scale" to "Individual Depth": AI Era Moats Are Changing
Over the past two years, OpenAI, Anthropic, and Google have all accelerated the accumulation and mining of Context, building capabilities around its acquisition, organization, and invocation, attempting to form new competitive barriers.
But a seemingly contradictory change is also happening simultaneously: since this year, the three companies have coincidentally made Memory more transparent, explainable, and even migratable.
In March 2026, Anthropic and Google successively launched Memory Import, supporting users in migrating memories between ChatGPT, Gemini, and Claude.
Subsequently, OpenAI, through Memory Sources, allowed users to see which memories, historical chats, or external data sources were invoked behind a personalized answer.
If Context is the most important asset in the AI era, why are platforms starting to open its permissions?
The answer lies in the fact that Memory Import truly only opens surface-level Context: user preferences, memory summaries, compressed versions of chat history.
This information is highly structured and easily described in natural language. Migrating it is not technically difficult.
What's truly hard to migrate is another type of Context: task states, tool permissions, enterprise system integrations, real-time feedback from execution sites.
This Context is deeply embedded within product and system environments and cannot be fully moved with a prompt.
This also indicates that the competitive logic of the AI era differs from that of the internet era.
The basic form of the internet is the network. It connects people, content, goods, services, and information into nodes. The more nodes and denser the connections, the more valuable the product. Therefore, the strongest moat in the internet era was network effects; value came from more people using it.
The basic form of AI is closer to a new kind of computer, or a new information processing system.
Its primary value is not connecting more people, but understanding information, processing tasks, invoking tools, and completing actions. An AI could create enormous value even serving just one user.
Therefore, the moats of the AI era are shifting from "network scale" to "individual depth." This "individual depth" barrier primarily comes from three layers:
First, the compounding effect of Context. Every time an AI completes a task, it understands the user's expression habits, judgment standards, data sources, and workflow better. The next time it executes, the cold-start cost is lower.
Second, the embedding of permissions and toolchains. When users authorize AI to access their email, documents, codebases, etc., AI is no longer just a replaceable Q&A tool; it enters the real task site.
Third, the formation of trust relationships. The more complex and high-value the task, the less likely users are to casually hand it to an unfamiliar AI. Only an AI that has long understood them, knows their boundaries, and can continue the context will likely be allowed to execute the next step.
If internet products compete for attention entry points, then AI products compete for task entry points.
Once an AI consistently enters a user's workflow, accumulates context, and gains execution permissions, the migration cost isn't just switching an app; it's re-establishing a whole set of task relationships of being understood, authorized, and trusted.
Changes in domestic products can also be understood within this logic.
Take Tencent as an example. It accumulated relationship chains, content, service ecosystems, and high-frequency entry points in the internet era; in the AI era, the value of these assets lies in whether they can be reorganized into Context that Agents can understand, invoke, and execute.
Whether it's WorkBuddy accessing work scenarios like documents, meetings, and WeCom, or WeChat's "Xiao Wei" attempting to invoke mini-programs and services within the WeChat ecosystem, the essence is transforming content, relationships, and processes originally serving humans into task environments AI can enter.
As Tencent's Chief AI Scientist Yao Shunyu judges: Context may appear as a data asset, but essentially it is a comprehensive reflection of product capabilities, engineering capabilities, and organizational coordination capabilities.
In the internet era, moats were about scale. In the AI era, moats should be more about conversion efficiency:
Who can transform their existing ecosystem into an AI work environment faster? Who can allow AI to accumulate deeper user understanding through each task? Whoever does this is more likely to build new barriers.
This is what truly deserves attention about the Context War.
This article is from WeChat public account "Deep Flow Research Institute," author: Jiang Feng








