Written by: Tang Yitao
Edited by: Jing Yu
Source: GeekPark
On March 31, 2026, Anthropic accidentally leaked 510,000 lines of Claude Code's source code to the public npm registry due to a packaging error. The code was mirrored to GitHub within hours and could not be retrieved.
A lot of content was leaked, and security researchers and competitors took what they needed. But among all the unreleased features, one name sparked widespread discussion—autoDream, automatic dreaming.
autoDream is part of a background resident system called KAIROS (Ancient Greek for "the right moment").
KAIROS continuously observes and records while the user is working, maintaining a daily log (somewhat like a lobster). autoDream, on the other hand, only starts after the user turns off the computer, organizing the memories accumulated during the day, resolving contradictions, and converting vague observations into confirmed facts.
The two form a complete cycle: KAIROS is awake, autoDream is asleep—Anthropic's engineers have created a sleep-wake cycle for AI.
Over the past two years, the hottest narrative in the AI industry has been Agent: autonomous operation, never stopping, which is seen as AI's core advantage over humans.
But the company that has pushed Agent capabilities the deepest has precisely set rest times for AI in its own code.
Why?
The Cost of Never Stopping
An AI that never stops will hit a wall.
Every large language model has a "context window," a physical upper bound on the total amount of information it can process at any one moment. As an Agent runs continuously, project history, user preferences, and conversation records keep piling up. After exceeding a critical point, the model begins to forget early instructions, becomes inconsistent, and fabricates facts.
The tech community calls this "context corruption."
Many Agents adopt a crude coping strategy: shove all the history into the context window and hope the model can prioritize on its own. The result is that the more information there is, the worse the performance becomes.
The human brain hits the same wall.
Everything experienced during the day is quickly written into the "hippocampus." This is a temporary storage area with limited capacity, more like a whiteboard. True long-term memories are stored in the "neocortex," which has large capacity but is slow to write to.
A core task of human sleep is to empty this overloaded whiteboard, moving useful information to the hard drive.
The laboratory of Björn Rasch at the Neuroscience Center of the University of Zurich, Switzerland, named this process "active systems consolidation."
Continuous sleep deprivation experiments repeatedly prove: a brain that never shuts down does not become more efficient; memory fails first, followed by attention, and finally even basic judgment collapses.
Natural selection is extremely cruel to inefficient behaviors, but sleep has not been eliminated. From fruit flies to whales, almost all animals with a nervous system sleep. Dolphins evolved "unihemispheric sleep," where the two brain hemispheres rest alternately—it would rather invent a whole new way of sleeping than give up sleep itself.

Killer whales, belugas, and bottlenose dolphins resting at the bottom of a pool | Image source: National Library of Medicine (United States)
The two systems face the same set of constraints: instant processing power is limited, but historical experience expands infinitely.
Two Answers
In biology, there is a concept called convergent evolution: species that are distantly related, because they face similar environmental pressures, independently evolve similar solutions. The classic example is the eye.
Both octopuses and humans have camera-like eyes: a adjustable lens focuses light onto a retina, and an iris controls the amount of light entering. The overall structure is almost identical.
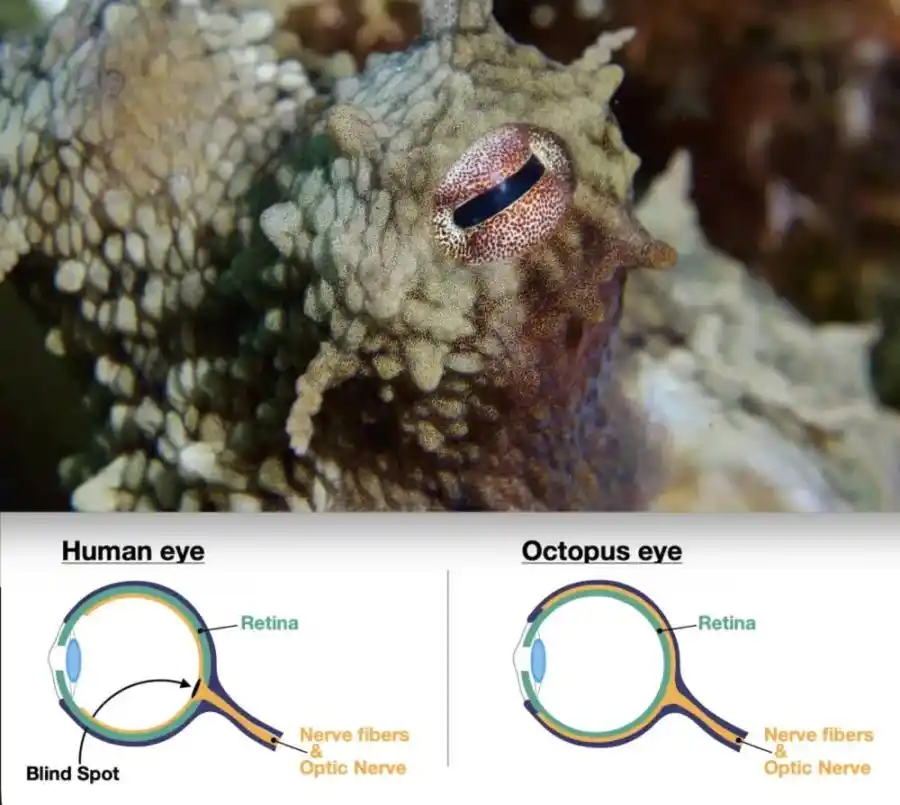
Comparison of octopus and human eye structure | Image source: OctoNation
But octopuses are mollusks, and humans are vertebrates. Their common ancestor lived over 500 million years ago, a time when there were no complex visual organs on Earth. Two completely independent evolutionary paths arrived at almost the same endpoint. Because to efficiently convert light into a clear image, the path allowed by physical laws is almost only the camera type: a lens that can focus, a light-sensitive surface to capture the image, and an aperture to regulate light intake—all indispensable.
The relationship between autoDream and human brain sleep might be of this kind—under similar constraints, the two types of systems may converge to similar structures.
The necessity to go offline is one of their most similar common points.
autoDream cannot run while the user is working. It starts independently as a forked subprocess, completely isolated from the main thread, with strictly limited tool permissions.
The human brain faces the same problem and offers a more radical solution: moving memories from the hippocampus (temporary storage) to the neocortex (long-term storage) requires a set of brainwave rhythms that only appear during sleep.
The most critical among these are the hippocampal sharp-wave ripples, responsible for packaging the day's encoded memory fragments and sending them piece by piece to the cerebral cortex; the slow oscillations of the cortex and the spindle waves from the thalamus provide precise timing coordination for the entire process.
This set of rhythms cannot form in a waking state; external stimuli disrupt it. So you don't sleep because you are tired; rather, the brain must close the front door to open the back door.
Or put another way, within the same time window, information intake and structural organization compete for resources; they are not complementary.
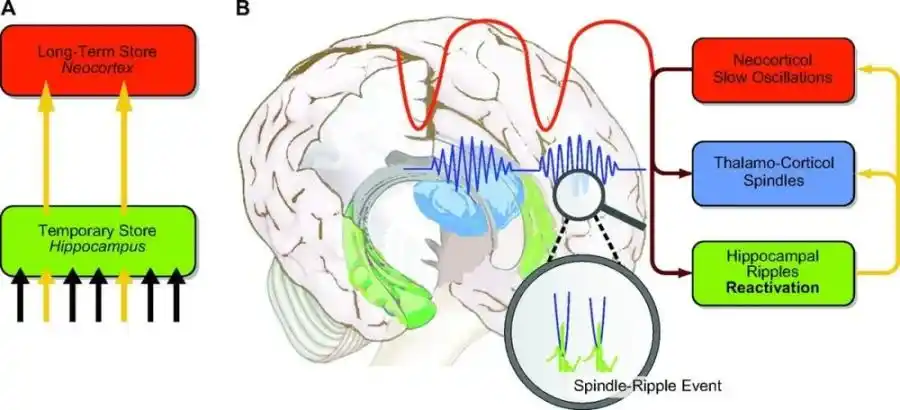
Active systems consolidation model during sleep. A (Data Migration): During deep sleep (slow-wave sleep), memories recently written to the 'hippocampus' (temporary storage) are repeatedly replayed, gradually transferred, and consolidated into the 'neocortex' (long-term storage). B (Transmission Protocol): This data transfer process relies on highly synchronized 'dialogue' between the two regions. The cerebral cortex emits slow brainwaves (red line) as the master rhythm. Driven by the wave peaks, the hippocampus packages memory fragments into high-frequency signals (green line, sharp-wave ripples), perfectly synchronized with the carrier waves (blue line, spindle waves) emitted by the thalamus. This is like embedding high-frequency memory data precisely into the gaps of the transmission channel, ensuring information is synchronously uploaded to the cerebral cortex. | Image source: National Library of Medicine (United States)
Another similarity is not making full memories, but editing them.
After starting, autoDream does not keep all logs. It first reads existing memories to confirm known information, then scans KAIROS's daily log, focusing on processing parts that deviate from previous cognition: memories that contradict what was said yesterday, or are more complex than previously thought, are prioritized for recording.
The organized memories are stored in a three-layer index: a lightweight pointer layer is always loaded, topic files are loaded on demand, and the full history is never loaded directly. Facts that can be directly looked up from the project code (like which file a function is defined in) are not written into memory at all.
The human brain does almost the same thing during sleep.
A study by Harvard Medical School lecturer Erin J. Wamsley showed that sleep preferentially consolidates unusual information, such as things that surprised you, caused emotional波动, or are related to unsolved problems. Large amounts of repetitive, featureless daily details are discarded, leaving only abstract patterns—you might not remember exactly what you saw on your way to work yesterday, but you clearly remember how to get there.
Interestingly, there is one point where the two systems made different choices. The memories produced by autoDream are explicitly labeled as "hint" rather than "truth" in the code. The agent must re-verify their validity before each use because it knows its organized content might be inaccurate.
The human brain lacks this mechanism. This is why eyewitnesses in court often give wrong testimony. They are not intentionally lying; it's because memory is temporarily pieced together from scattered fragments in the brain, and errors are the norm.
Evolution probably found no need to install an uncertainty tag for the human brain. In a primitive environment requiring quick physical reactions, believing memory enables immediate action, while doubting memory leads to hesitation—and hesitation means defeat.
But for an AI that repeatedly makes knowledge-based decisions, the cost of verification is low, while blind confidence is dangerous.
Two different contexts lead to two different answers.
Smarter Laziness
In evolutionary biology, convergent evolution means two independent lineages, without directly exchanging information, arrive at the same endpoint. There is no plagiarism in nature, but engineers can read papers.
When Anthropic designed this sleep mechanism, was it because they hit the same physical wall as the human brain, or did they reference neuroscience from the start?
The leaked code contains no citations of neuroscience literature; the name "autoDream" seems more like a programmer's joke. A stronger driver was likely the engineering constraints themselves: the context has a hard limit, long-term operation leads to noise accumulation, and online organization would pollute the main thread's reasoning. They were solving an engineering problem; biomimicry was never the goal.
What truly determined the shape of the answer was the compressive force of the constraints themselves.
Over the past two years, the AI industry's definition of "stronger intelligence" has almost always pointed in the same direction—larger models, longer context, faster reasoning, 7×24 uninterrupted operation. The direction is always "more."
The existence of autoDream suggests a different proposition: a smarter agent might be a lazier one.
An agent that never stops to organize itself will not become smarter; it will only become more chaotic.
The human brain, through hundreds of millions of years of evolution, arrived at a seemingly clumsy conclusion: intelligence must have rhythm. Wakefulness is for perceiving the world; sleep is for understanding it. When an AI company, in solving an engineering problem, independently arrives at the same conclusion, this perhaps hints at something:
Intelligence has some unavoidable basic overhead.
Perhaps, an AI that never sleeps is not a stronger AI. It is merely an AI that has not yet realized it needs to sleep.