原文标题:DeepSeek's 10 trillion USD grand strategy
原文作者:@bookwormengr
原文编译:Peggy,BlockBeats
编者按:过去一年,围绕 DeepSeek 的讨论大多集中在模型性能、开源策略和价格战上。但如果只从「卖不卖订阅」「有没有多模态」「能不能做 coding agent」来理解 DeepSeek,可能低估了它真正想改变的东西。
这篇文章提出了一个更激进的判断:DeepSeek 的目标未必是短期通过应用层变现,而是通过一系列底层架构创新,重塑 AI 训练与推理的成本结构,并间接推动一个新的硬件生态形成。从 MoE、MLA 到 DSA、CSA、mHC、Engram,再到 Dual Path 和 TileLang,DeepSeek 的技术路线始终围绕一个核心问题展开:在 HBM、先进制程、封装和 CUDA 生态都受限的情况下,如何用更少的高端算力跑出更强的模型。
文章最值得关注的,不是「DeepSeek 是否能靠 API 或订阅赚到几亿美元」,而是它是否正在把模型能力、内存体系和国产硬件生态绑定到一起。KV Cache 压缩降低了对 HBM 的依赖,NAND 和 SSD 可以承接长时间缓存,LPDDR 可以用于权重流式加载和 Engram 存储,TileLang 则试图削弱 CUDA 护城河。这些创新如果持续扩散,受益者就不只是 DeepSeek 本身,还包括存储、ASIC、GPU、网络芯片以及整个 AI 基础设施链条。
当然,文中关于「10 万亿美元产业生态」和「1 万亿美元估值」的判断,仍带有较强推演色彩。但它提供了一条理解 DeepSeek 的重要路径:开源并不一定意味着放弃商业化,低价也不一定只是补贴市场。对 DeepSeek 来说,真正的生意可能不在应用层,而在帮助更多硬件变得可用、让更低成本的 AI 供给成为可能。换句话说,它卖的未必是模型本身,而是下一代 AI 基础设施的可行性。
以下为原文:

你有没有想过,DeepSeek 到底要怎么赚钱,而且可能赚很多钱?
它没有像 GLM、MoonShot 和 MiniMax 那样推出有竞争力的编程订阅方案;也没有多模态、音频、视频模型。到目前为止,它甚至还没有自己的 harness,也就是用于模型调用、工具接入和任务执行的外层运行框架——虽然他们最近已经开始招聘相关岗位,准备搭建这一体系。
与此同时,DeepSeek 似乎还长期坚定地站在开源一边,甚至很乐意公开分享自己的「秘诀」。这难道不是疯狂吗?不是在白白烧钱吗?那些准备向它投资 100 亿美元的投资人,难道是在把钱扔进下水道吗?
我个人认为,答案恰恰相反。
接下来,我会基于 DeepSeek 迄今为止已经做过的事情,提出一些观察,并分析它似乎正在遵循的一套战略。DeepSeek CEO 梁文锋的目标,可能远不止眼前的模型竞争。他瞄准的或许是一个更大的奖项:DeepSeek 有机会冲击 1 万亿美元估值,同时推动一个规模达 10 万亿美元的新产业形成。

TechInAsia 关于 DeepSeek 最新一轮融资的报道
重访 DeepSeek 的「英雄之旅」
DeepSeek 一直在逆风而行。它没有选择不断推出稍微更强一点的模型,然后急于把它们包装成可直接变现的应用,比如编程订阅方案。2025 年 1 月 27 日,我曾发过一条传播很广的推文,讲述我眼中 DeepSeek 的「英雄之旅」。如今,这个故事变得更加有趣了。
当其他人还在尝试构建密集模型时,DeepSeek 选择了更难训练的专家混合模型(Mixture of Experts,MoE)。
他们采用「第一性原理」的方法,发明了新的 GRPO 算法,用来替代当时主流但实现成本更高的 PPO 强化学习算法。
他们发现,基于可验证奖励的强化学习(Reinforcement Learning from Verified Rewards,RLVR),是提升模型推理能力的关键策略。
他们还通过「多 Token 预测」(Multi Token Prediction)提出了一种简单的推测解码策略,同时也让训练信号变得更加密集。
他们完善了「零气泡」(ZERO bubble)流水线,以提高有限 GPU 资源的利用效率。
他们发布了专家负载均衡器,使所有人都能更容易地部署 MoE 模型。尤其是通过「宽专家并行」(Wide Expert Parallel)策略,模型可以以更大的 batch 进行服务,从而大幅降低推理成本。
他们发明了 MLA、DSA、CSA、HCA 等机制,用于减少 KV Cache 的需求,并让随着上下文长度增长而增加的计算需求尽可能保持接近恒定。
他们发明了 Engram,用内存换取计算效率。
他们还发明了 mHC,使模型规模扩大时依然能够实现稳定训练。类似的例子还有很多。
在「英雄之旅」这一最普遍的叙事结构中,英雄从来不会一开始就决定自己的旅程究竟通向哪里。他是在一路学习中,逐渐发现自己真正伟大的使命,并在重重阻碍之下完成它。他会遇到许多质疑者,但他选择无视他们。他也会遇到许多恶意行动者。他有明显的缺陷或短板,但最终会克服这些问题,完成自己的使命。他面对看似无法跨越的挑战,却能找到结盟的方法,并学会如何明智地使用有限而珍贵的资源。正是这一点,让观众愿意为英雄加油。这也是 DeepSeek 赢得追随者、全球尊重以及反对者的原因。
正如我接下来会详细说明的,DeepSeek 已经在这条路上走了很久,并且逐渐发现了自己的终极命运:它的目标不是出售编程订阅方案,而是推动一个规模达 10 万亿美元的中国 AI 硬件生态,并让自身实现 1 万亿美元估值。在这个过程中,它也将为西方硬件生态中的许多新进入者创造机会。

先从一些有趣的 KV Cache 计算开始
请看 @SemiAnalysis_ 最近这条很及时的推文:
DeepSeek 已经比任何人都更好地解决了这个问题!
我们先来做一点有趣的 KV Cache 计算。别担心,就算你不喜欢数学也没关系。我们会使用最近发布的 KV Cache 计算器,来看看 DeepSeek V4 Pro 能带来多少 KV Cache 节省,并将它与最新的 GLM 和 Qwen 模型进行对比。
这里我以 100 万上下文长度进行计算,假设 KV 精度为 8 bit,索引器精度为 16 bit。你也可以自己打开这个计算器试一试:https://kvcache.ai/tools/kv-cache-calculator/
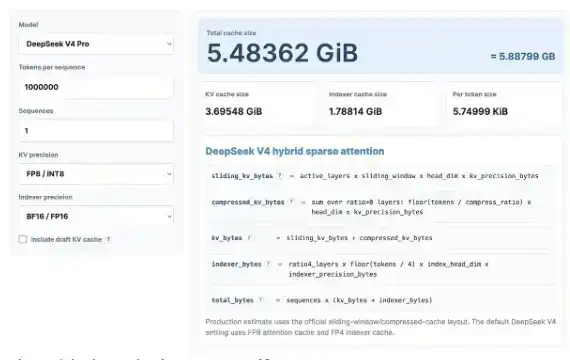
你也可以自己打开计算器试试看!
在 100 万上下文长度下:
·DeepSeek V4 只需要 5.48GB HBM;
·GLM-5 需要 60GB HBM;
·Qwen3-235B-A22B 则需要高达 89GB HBM。
要注意的是:
·DeepSeek 是一个 1.6 万亿参数模型;
·GLM-5 大约是 7000 亿参数,并且已经采用了 DeepSeek 的 MLA 和 DSA,不过还没有使用最新的压缩注意力机制;
·Qwen3-235B-A22B 大约是 2350 亿参数,采用的是 GQA 注意力机制。
DeepSeek 在缓解内存压力方面,已经做出了基础性贡献。如果这类创新被广泛采用,将大幅降低长周期 Agent 的运行成本,并解锁下一批新的应用场景。
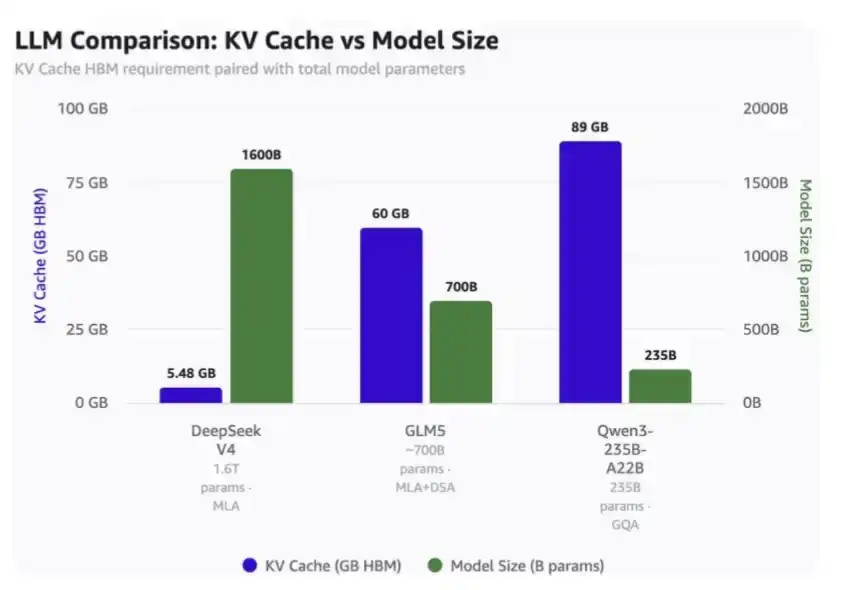
100 万 Token 上下文与模型规模下的 KV Cache 占用对比
「疯狂」背后的方法论
KV Cache 体积之所以能做到这么小,同时又不牺牲模型质量,正是 DeepSeek 能够以极低价格提供长时间缓存的原因——其价格甚至不到 Sonnet 4.6 缓存命中价格的 3%,而且 DeepSeek 可以将缓存保留数小时。
对于长周期任务来说,较小的 KV Cache 意味着可以更经济地将其卸载到 SSD 中,并在需要时重新加载。这样一来,就能减少对 HBM 的依赖。站在中国 AI 硬件产业的角度看,HBM 不仅供应紧张,也是最难制造的内存类型之一。
此外,DeepSeek 还开发了从 SSD 更快加载 KV Cache 的技术,这一点在其 Dual Path 论文中已有描述。
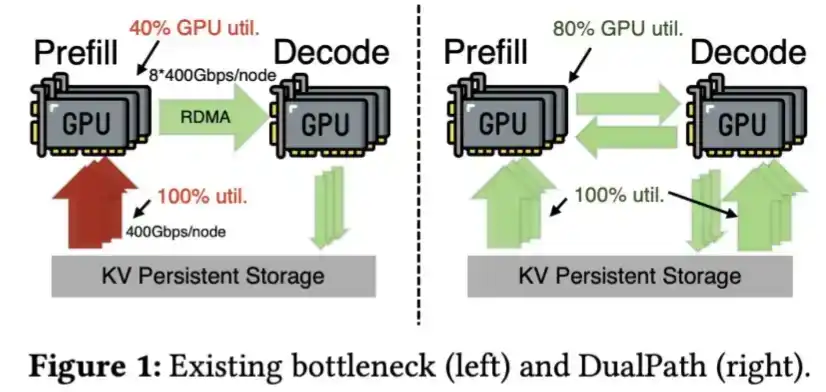
DeepSeek V4 对 KV Cache 的压缩幅度非常大,以至于这一步甚至可能都不再必要。
那么,KV Cache 压缩最直接的受益者是谁?
谁在大规模供应 SSD?别忘了,YMTC(长江存储)正在成长为 3D NAND 领域的巨头。NAND 可以帮助 DeepSeek 避免重复计算 KV。反过来,DeepSeek 也为 NAND 和 SSD 创造了一个巨大的市场——这不仅会让长江存储受益,也会让其他相关厂商受益。

不过,这不仅仅关乎 NAND 和 SSD。
LPDDR 内存同样有巨大潜力。它可以作为存放模型权重的地方,并在需要时将这些权重流式传输到 HBM 中,从而缓解对 HBM 的需求压力。SGLang 团队曾发布过一篇很好的博客对此进行介绍。下面这张图展示了这一方案的工作原理。
虽然 DeepSeek 并没有专门为这一方案做什么特定设计,但它的 MoE 架构、本身拥有大量专家模型,以及 4 bit 权重的特性,都让这一方案更容易落地。
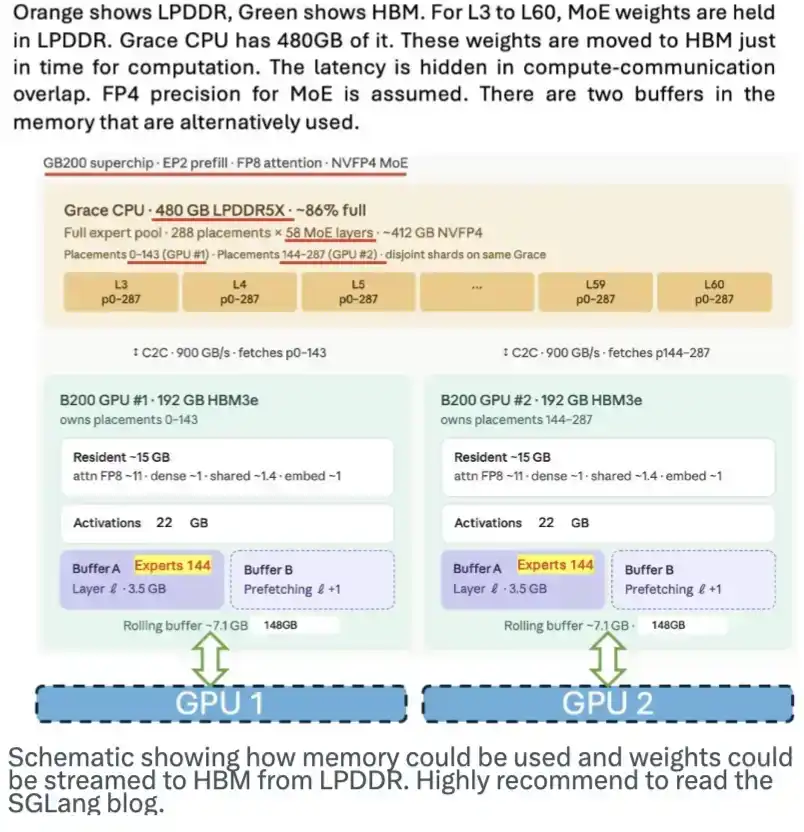
这张示意图展示了内存可能如何被使用,以及模型权重如何从 LPDDR 流式传输到 HBM 中。强烈推荐大家阅读 SGLang 的那篇博客。
这项创新如果与极其紧凑、且无损的 KV Cache 结合起来,将显著降低对 HBM 的需求。
那么,中国谁在生产 LPDDR?答案是 CXMT,也就是长鑫存储。它们在 LPDDR 速度上只落后约半代,在密度上落后一代,差距并不算大。
除了充足的 NAND 之外,中国 AI 生态在不久的将来,也将拥有充足的 LPDDR 供给。这能缓解算力压力吗?答案是:可以。继续往下看。

智能使用内存,同样可以减轻 GPU / ASIC 的压力
使用 NAND 来存放 KV Cache 的作用其实很容易理解:它可以让 KV Cache 保留更长时间,降低对 HBM 的压力,同时避免重复计算 KV Cache,从而减轻 GPU 和 ASIC 的计算负担。
那么,LPDDR 是否也能以类似方式发挥作用?除了作为一个可以「按需即时」将权重流式传输到 HBM 的存储位置之外,它还能进一步降低计算压力吗?
答案是:可以。
LPDDR 可以用来存放大量被称为 Engram 的内容。在 DeepSeek 的 Engram 论文中,他们指出,MoE 可以通过条件计算来扩展模型容量,但 Transformer 本身缺少一种原生的「知识查找」机制。因此,Transformer 往往不得不通过计算来低效地模拟检索过程。
为了解决这个问题,DeepSeek 提出了 Engram 模块。它将经典的 N-gram embedding 现代化,改造成一种基于哈希的 O(1) 查找机制,从而创造出一条互补的稀疏化路径,他们称之为 条件记忆(conditional memory)。
这种方式可以节省计算,但也需要内存来承载 embedding table,而这个表本身可能非常庞大。
本质上,这是一种典型的「以内存换计算」的方案。但其关键洞察在于:从每 bit 数据读取成本来看,「内存」这一侧要便宜得多——一次 LPDDR 查找,远比让数据完整经过多层 Transformer 做一次前向计算便宜。因此,在大规模场景下,这是一笔非常划算的交换。
这就是 DeepSeek 通过牺牲部分内存、换取计算节省的方式。
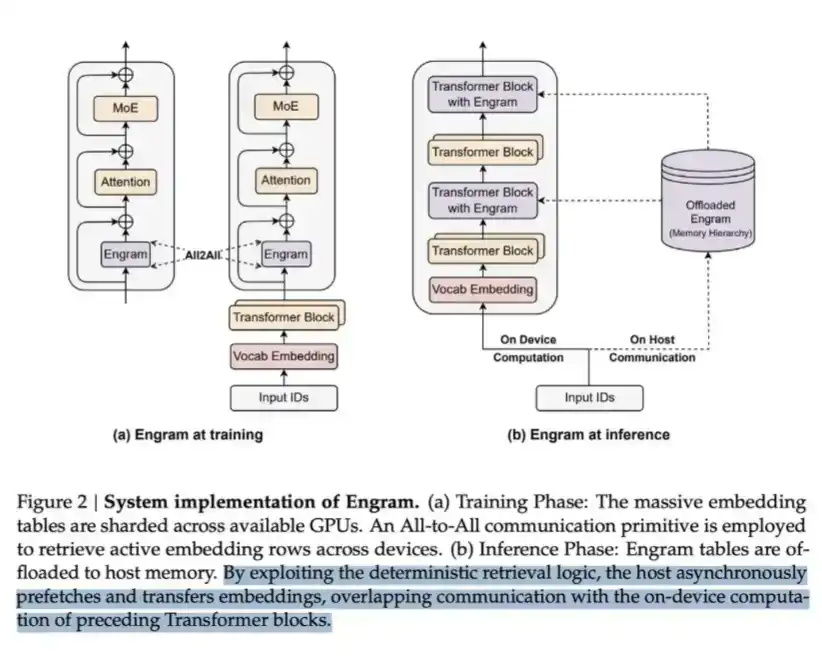
值得做出的取舍
由于没有同等水平的芯片晶体管密度,也没有 EUV,中国 GPU 和 ASIC 在原始 FLOPs 算力上,很可能长期落后于西方 GPU。它们在先进封装方面也仍有明显差距。因此,这类取舍非常值得做,尤其是在中国能够大量生产 NAND 和 LPDDR 内存的前提下。
回顾 DeepSeek 的长期战略
从这些创新来看,DeepSeek 的目标似乎并不是眼下赚几亿美元利润。它过去做出的很多选择都说明了这一点:到现在还没有多模态,没有语音模型,视频模型更是谈不上。
它真正参与的,是一场耐心的、规模可能达到 10 万亿美元 的长期游戏:推动一个替代性 AI 硬件生态的形成。
这不仅是为了让中国内存厂商在中国乃至全球 AI 硬件市场中成为关键玩家,更是为了从根本上降低资源需求,让 AI 模型的训练和服务变得更具成本效率。这样一来,许多 GPU、ASIC 厂商,以及网络芯片厂商,都有机会成为可行选项。
与此同时,这些创新也将惠及西方开源生态,以及新一代硬件制造商。
所有迹象其实都已经出现了。我们不妨详细回顾一下 DeepSeek 至今提出的这些创新:
1、DeepSeek V2 中引入的专家混合模型(MoE)和 MLA
DeepSeek 在 V2 中引入了 MoE 和 MLA。MoE 让训练高智能模型所需的计算量减少了约 40% 到 50%;MLA 则使 KV Cache 减少了 90%。
这让将 KV Cache 卸载到 SSD 上变得相当高效。
这些想法最早出现在 DeepSeek 于 2024 年 5 月发布的 DeepSeek V2 论文中。后来,它们也为 DeepSeek V3 的训练奠定了基础。当时,DeepSeek 仅使用 2048 张被削弱性能的 H800 GPU,就训练出了一个性能接近闭源模型水平的系统。
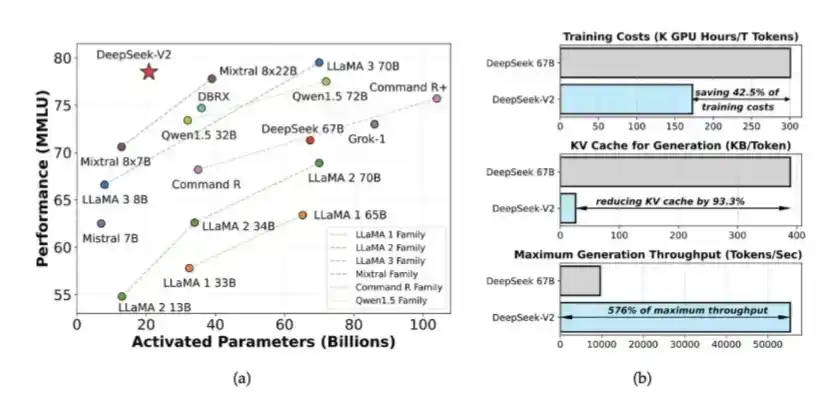
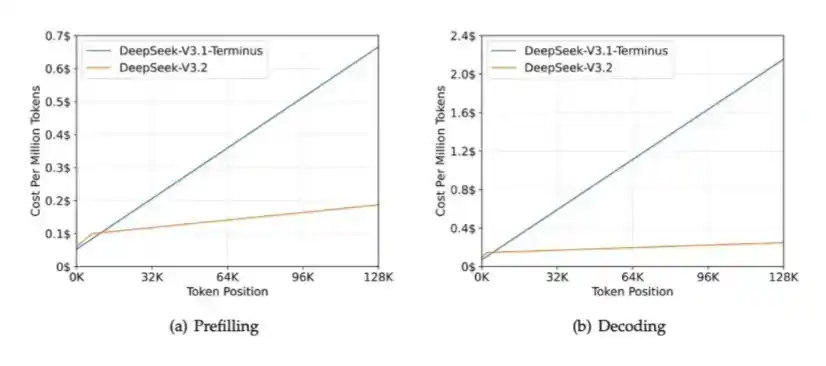
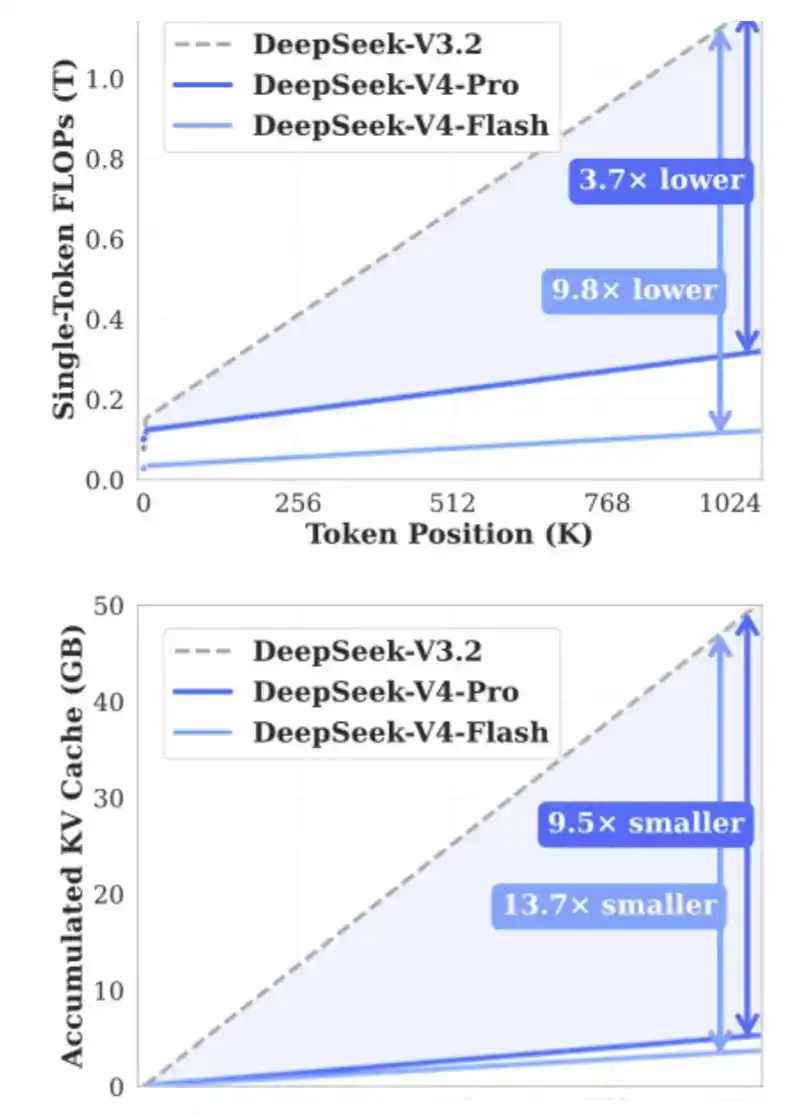
2、DSA:在 DeepSeek V3.2 Exp 中引入,用于降低长上下文场景下的计算开销,同时缓解 HBM 带宽压力。
DSA 的核心作用,是确保计算量不会随着上下文长度的增加而持续增长。可以看下面的图表:随着上下文长度增加,DeepSeek-V3.2 的处理时间基本保持平稳。
3、mHC:DeepSeek 于 2025 年 12 月在论文《mHC: Manifold-Constrained Hyper-Connections》中提出。
mHC 是 DeepSeek 在宏观架构层面的一项创新,它重新设计了 Transformer 层之间的信息流动方式。
过去,从 ResNet 以来,模型通常使用标准残差连接,也就是 x + F(x)。而 mHC 的做法,是把残差流扩展成多条并行的信息通道,并允许模型在这些通道之间进行可学习的混合。关键在于,它会将混合矩阵约束为双随机矩阵,也就是通过 Sinkhorn-Knopp 投影将其限制在 Birkhoff 多面体上。这样一来,从数学上可以保证,无论模型堆叠到多深,信号幅度都能保持稳定。
这解决了此前无约束 Hyper-Connections 所面临的灾难性不稳定问题。Hyper-Connections 最初由字节跳动提出,但在没有约束的情况下,信号放大会在 270 亿参数规模上暴涨至 3000 倍,最终导致训练完全崩溃。
mHC 的计算成本很低:它只带来约 6.7% 的实际训练耗时开销,因为它并没有改变注意力层或 FFN 层的 FLOPs,只是改变了这些层的输出在层间的路由方式。
但它带来的性能提升相当明显:在 270 亿参数规模下,mHC 在 BIG-Bench Hard 推理任务上提升 7.2 分,在 DROP 上提升 3.2 分,在 GSM8K 数学任务上提升 2.8 分,在 MMLU 通用知识任务上提升 1.4 分。而这些提升都是在相同模型规模、几乎相同计算预算下实现的。
本质上,mHC 是通过为网络提供一种更丰富、更具表达能力的跨层信息路由拓扑,在几乎不增加额外 FLOPs 的情况下,实现了更高的单位参数智能。
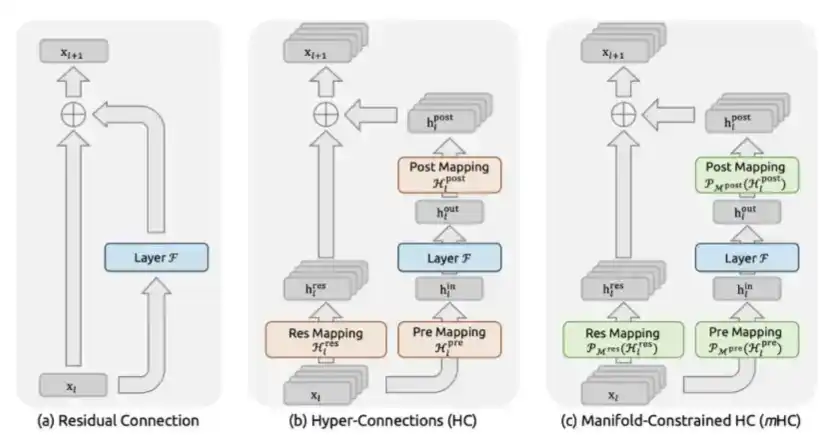
mHC 是一种复杂的架构设计,但它能够带来更稳定的训练过程,以及更高的单位参数智能。
4、CSA、HSA:DeepSeek 于 2026 年 4 月在 V4 中引入。
CSA 和 HSA 的目标,是通过压缩 KV Token,将 KV Cache 需求再降低 90%,同时大幅减少所需 FLOPs,从而同时缓解 HBM 以及 GPU / ASIC 的压力。
5、Engram:DeepSeek 于 2026 年第一季度引入,本质上是在某种程度上用内存,也就是 LPDDR 内存,来换取计算效率。
如下方这张详细图表所示,在总参数预算相同的情况下,Engram 带来了明显的性能提升。
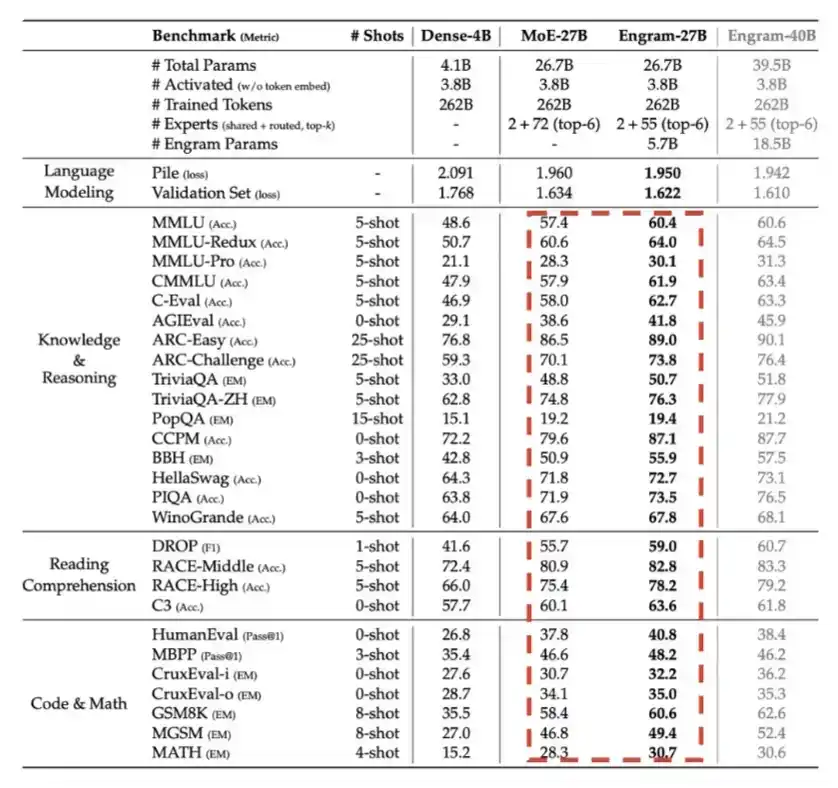
6、Engram:DeepSeek 于 2026 年第一季度引入,本质上是在某种程度上用内存,也就是 LPDDR 内存,来换取计算效率。
如下方这张详细图表所示,在总参数预算相同的情况下,Engram 带来了明显的性能提升。

这是 DeepSeek 在 V4 论文中分享给硬件厂商的建议。我很确定,在线下交流中,他们给出的反馈只会更多。
7、对 TileLang 的投入,也指向了同一个方向:DeepSeek 不是只在解决自己的算力瓶颈,而是在推动中国硬件生态具备与西方生态竞争的能力。
借助 TileLang,开发者可以只编写一次 kernel,也就是用于计算的底层代码,然后让它在多个硬件平台上成功运行,前提是这些平台已有对应的 TileLang 后端支持。
我预计,其他中国 AI 实验室也会陆续加入进来。这将帮助中国硬件厂商以一种间接方式应对所谓的「CUDA 护城河」。同时,它也会释放更多西方硬件的潜力,比如 AMD。
需要说明的是,中国不少 AI 硬件平台已经提供 CUDA 兼容能力,或 CUDA 转译层。例如,摩尔线程、沐曦、壁仞和天数智芯,都是通过转译层实现 CUDA 兼容度较高的中国芯片厂商。因此从理论上说,它们并不一定需要 TileLang。

大规模强化学习与 RSI
随着 DeepSeek 获得更多算力来源,也就是可选硬件变多,同时模型本身对计算资源的需求下降,它就能够推进更有野心的训练项目,尤其是强化学习后训练。
强化学习需要生成大量轨迹,也就是生成数万亿 Token。这个过程很快就会变得极其昂贵。更进一步,如果要训练 100 万上下文长度的模型,就需要生成同样长度的轨迹。只有在这种超长轨迹上训练模型,才能真正支持长周期任务。
此外,由于硬件选项增加,DeepSeek 可调用的硬件资源也会更多,这将推动自动化研究,也就是 RSI。RSI 指的是 AI 自己设计并执行实验。这种方法会涉及大量试错,成本也会迅速上升。但 RSI 对探索完整的模型设计空间至关重要。在走向 AGI、乃至随后走向 ASI 之前,DeepSeek 必须具备 RSI 能力。
DeepSeek 今天做的事,整个行业明天都会跟上
DeepSeek 围绕专家混合模型、MLA、DSA 等方向的创新,已经被全球和中国的其他 AI 实验室陆续采用。
例如,GLM 系列模型的开发方 ZAI 就使用了 MLA 和 DSA。Kimi,也就是 Moonshot,也采用了 MLA,并且毫不避讳地表示,其架构是基于 DeepSeek 架构设计的。反过来,DeepSeek 也使用了 Muon 优化器,而 Muon 最早是由 Kimi(Moonshot)在大规模训练中采用的。
需要说明的是:
MoE 最早由 Google 在 2017 年提出,关键作者是 Noam Shazeer。DeepSeek 的贡献在于将 MoE 大规模应用,并发明了自己的配套技巧。
Muon,也就是 MomentUm Orthogonalized by Newton-Schulz 优化器,由机器学习研究员 Keller Jordan 于 2024 年底提出。Kimi(Moonshot)团队是第一个将其用于大规模训练的团队。
那赚钱的问题怎么办?
我们可以看看 OpenAI 这个有趣的例子。
OpenAI 获得了以较低价格购买 AMD 和 Cerebras 股票的认股权证 / 期权,这些权益与其算力消费里程碑挂钩。对 AMD 和 Cerebras 来说,这是一笔非常划算的交易。因为一旦 OpenAI 承诺使用它们的硬件,它们长期成功的可能性就会大幅提高。
AMD 公告中有这样一段话:
「作为协议的一部分,为了进一步协调双方战略利益,AMD 向 OpenAI 发行了最多可购买 1.6 亿股 AMD 普通股的认股权证,并将根据特定里程碑的达成逐步归属。第一批将在初始 1 吉瓦部署完成时归属,后续批次则会随着采购规模扩大至 6 吉瓦而逐步归属。归属条件还与 AMD 达成特定股价目标,以及 OpenAI 实现让 AMD 大规模部署所需的技术和商业里程碑挂钩。」

我预计,DeepSeek 也会与多家中国内存、ASIC、CPU 和网络技术栈厂商达成类似协议,并与它们深度合作,使这些厂商的硬件栈能够胜任领先 AI 工作负载。
考虑到所有西方,包括东亚盟友在内的 AI 股票总市值已经远超 10 万亿美元,这种「通过合作获得股权回报」的方式,将让 DeepSeek 有机会帮助中国打造一个同样巨大的产业,并在其中分得自己的蛋糕,最终实现自身 1 万亿美元估值。
这不仅会让 DeepSeek 赚到远超传统应用订阅业务的钱,同时也能实现它所说的「让 AGI 惠及每个人」的目标。梁文锋是 Jim Simons 的忠实粉丝,也是足够聪明的资本玩家,他不可能错过这一点。
如果你回头看 DeepSeek 至今所做的一切,只有这一种解释最说得通。
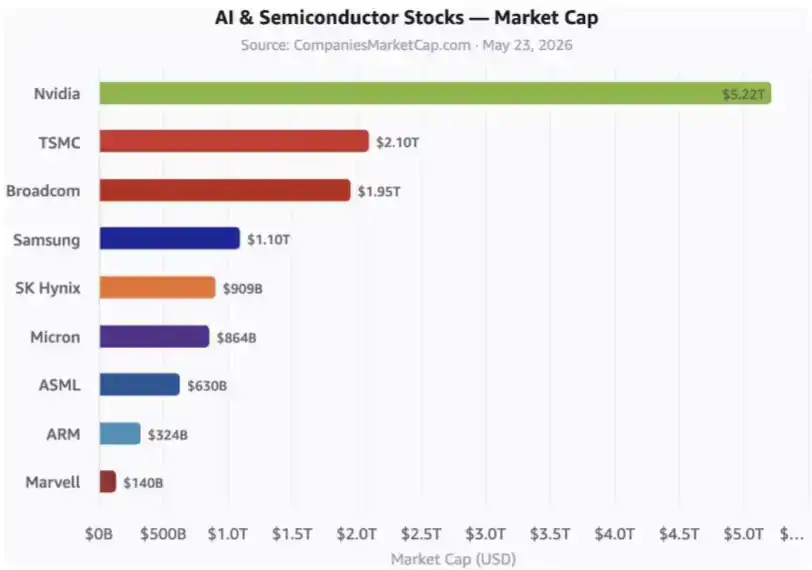
这些是关键 AI 股票。图中还没有包括 hyperscalers,也就是超大规模云厂商,以及许多其他相关公司。
原文链接








