Anthropic's much-anticipated "Mythos", kept under wraps for two months, has finally descended—
its most powerful flagship large model to date, served up in two versions: Claude Fable 5 and Claude Mythos 5.

Fable 5 is a version of Mythos with safety nets added, open to all users.
Once a user's query triggers a risk classifier (such as trying to get it to write malware), the system will automatically downgrade and answer using the previous generation Claude Opus 4.8.
Mythos 5 is the original, full-blooded "Mythos" version, but is only available to a select group of trusted users.
It has safety restrictions lifted in areas like cybersecurity, with the official website claiming it "possesses the world's top-tier pure bloodline capabilities in cyber offense/defense and biological scientific research."
Officials state that both Fable 5 and Mythos 5 have longer autonomous runtimes than any previous Claude model.

A little sigh? Frontier AI is starting to enter the permission era.
And this comes just a couple of days after Anthropic earnestly called for all AI research to be halted immediately...
Not sure why Dario has also started down the old road of Sam Altman's pre-launch marketing hype for his own new models and products, and on a grand scale at that.
(I know A.I. has its own reasons, but I'll respond with just a smile).
However, there is some non-technical news that pleases developers: the API pricing for these two new flagships has been slashed by more than half compared to the previous preview version:
Only $10 per million input tokens, and $50 per million output tokens.

Alright, let's quickly move into the technical section, let's go—
The Dual-Version Mythos is Here! The Official Highlight is "Token Efficiency"
First, some context.
The official release notes and industry evaluations do not provide a long list of standard, public benchmark scores (like MMLU, GSM8K, SWE-bench, etc.) for Mythos 5 as they do for Fable 5.
However, considering they share the same underlying model, the two can essentially be seen as "mirror clones" of the same core, with identical fundamental technical specifications.
So for now, we can only look at the performance of Fable 5 as primarily disclosed through official channels.

According to Anthropic's own statements, Claude Fable 5 is the most powerful publicly available Claude yet, and the first time the Fable series has reached Mythos-level capability.
Its strengths are mainly concentrated in several areas: software engineering, complex knowledge work, vision, long context, memory capabilities, and life sciences research.
More crucially, the longer and more complex the task, the more significant Fable 5's advantage is over previous Claude models—indicating that Fable 5's focus isn't on giving prettier single-turn answers, but on handling long-cycle tasks.
Let's use data and hardcore demos to unpack the dominance of this mythical generation model:
Software Engineering: Crushing High-Difficulty Benchmarks, from "Bug Fixing" to "Fully Automated Army"
On the SWE-bench Pro evaluation, which measures a model's ability to solve real-world, complex software engineering problems, Claude Fable 5 scored a high 80.3%.
For comparison, competitor's top flagship model GPT-5.5 scored 58.6%.
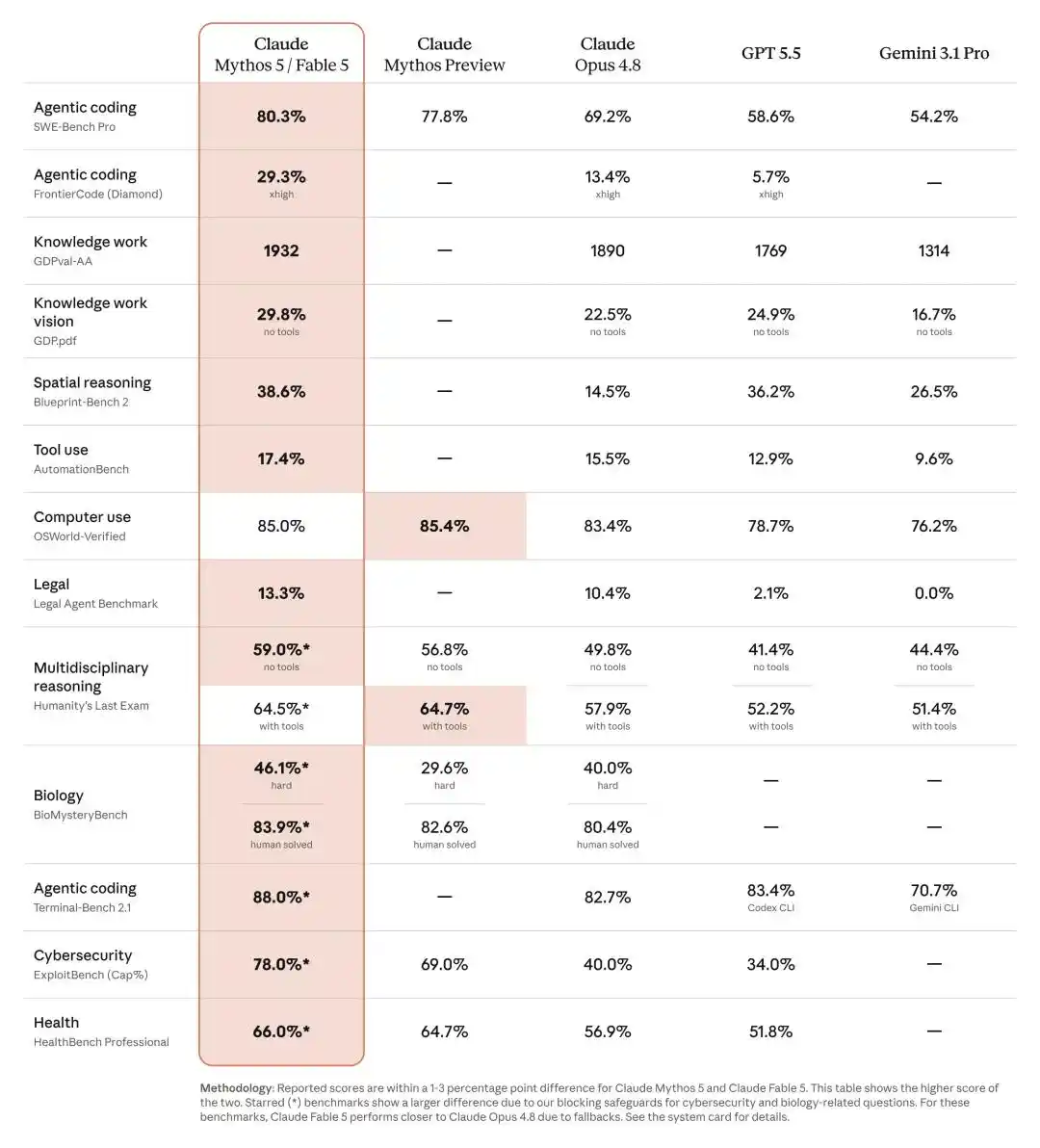
On Cognition's Frontier Code evaluation—which places more emphasis on a model's ability to complete difficult programming tasks while meeting high-quality production codebase standards—Fable 5 achieved the top score among frontier models even under medium reasoning intensity.
This benchmark is notoriously difficult to saturate.
Nevertheless, even in "Medium effort" mode, Fable 5's score is the highest among all frontier models.
The first typical case provided by the official comes from Stripe.
Within a 50-million-line Ruby codebase, Fable 5 completed a full-library migration. This work, if done manually by an engineering team, would originally have taken over two months.
How about Fable 5? It took just one day.
Furthermore, on the end-to-end frontend development benchmark ViBench (Vibe-coding benchmark), Fable 5 nearly saturated basic development use cases outright, achieving true "One-shot" application generation.
Native Vision: No Scaffolding, Blindly Beats "Pokémon"
Renowned tech media VentureBeat revealed in their article "Anthropic brings Mythos to the masses with Claude Fable 5, its most powerful generally available model ever" that on the GDPpdf benchmark focused on visual document reasoning, Fable 5 and Mythos 5 scored 29.8% without external tools.
For comparison, Opus 4.8 scored 22.5%, GPT-5.5 scored 24.9%, and Gemini 3.1 Pro scored 16.7%.
Anthropic also figured everyone might find piles of data boring, so they released a demo of Fable 5 playing a game, which is more visually direct.
Previously, if a Claude model wanted to play the RPG game "Pokémon FireRed," it required an extremely complex external "scaffolding" setup (including map navigation assistance, memory game state reading, etc.).
Now, Fable 5 achieves pure "native vision blind play."
Relying solely on raw screenshots of the game screen, with no map mods whatsoever, it completely autonomously deduced, strategized, and stubbornly beat the entire game.
Moreover, due to its super-long-sequence focus, when equipped with persistent file-level memory, its performance while playing the deck-building roguelike game "Slay the Spire" directly tripled, and its probability of reaching the final spire also skyrocketed threefold.
Long Context & Memory Capabilities Major Upgrade, Casually Highlighting "Token Efficiency"
Long context and memory capabilities are also a major focus of this upgrade.
Anthropic states that Fable 5 can maintain focus across million-token long-term tasks and can use its own notes to improve output.
The official used Slay the Spire for testing; after giving the model access to persistent file memory, Fable 5's performance improvement was three times that of Opus 4.8, and its frequency of reaching the final chapter also tripled.
This is actually a very foundational layer of Agent capability.
An AI that can work for extended periods must be able to remember what it has done, what mistakes it made, and why it's taking the next step. Without stable memory, autonomous tasks can easily become a grand amnesiac spectacle.

For this reason, Anthropic also specifically emphasized Token efficiency (this is also a key direction for this generation of models).
The more capable a model is of long-term autonomous work, the more tokens it consumes.
If a model is powerful on one hand but "wasteful with words" on the other, costs can quickly escalate to the point of causing corporate pain.
Fable 5's emphasis on Token efficiency is essentially solving the ledger problem in Agent-based deployment.
Finance, Law & Operations: The First to Break the 90% Barrier Logic Black Hole
On the Hebbia financial benchmark test (Finance Benchmark for senior-level reasoning), which examines advanced analytical reasoning, Fable 5 achieved the industry's highest score.
In long-document reasoning, complex chart and table interpretation, and multi-step root cause analysis, Fable 5 achieved double-digit leaps in improvement.
In live tests by quantitative trading giants IMC and Optiver, Fable 5 nearly maxed out all weights in their trading analysis evaluations (including factual retrieval, conceptual reasoning, and expected value calculation), and exhibited astonishing stability—scores were completely consistent across multiple repeated runs.
The evaluation from data analysis platform Hex goes like this:
Fable 5 is the industry's first model to break the 90% score barrier on our core analytics benchmark (covering extremely complex, long-cycle analysis tasks), a full 10 percentage points higher than Opus. In the most challenging queries, it demonstrated human-expert-level micro-judgment capabilities.
Frontier Research: Full-Blooded Mythos "Beats" a Model 100x Larger
In frontier physics research, tests by startup VibeCAD and physics research institutions indicate that Fable 5, using only 1/3 of the inference tokens, produced physics research results in 36 hours that approached what GPT-5.5 achieved after four days of running.
And the still somewhat elusive Mythos finally makes an appearance in this section.
Anthropic states that in the biomedical field, the full-blooded Mythos 5, with absolutely no human assistance, can already independently execute the entire workflow of a biologist: selecting protein binding sites, autonomously scheduling and running various bioinformatics tools, and even debugging itself when encountering failures.
Out of the 14 protein-targeting complexes it designed, 9 have already entered real-world drug development pipelines in the lab.
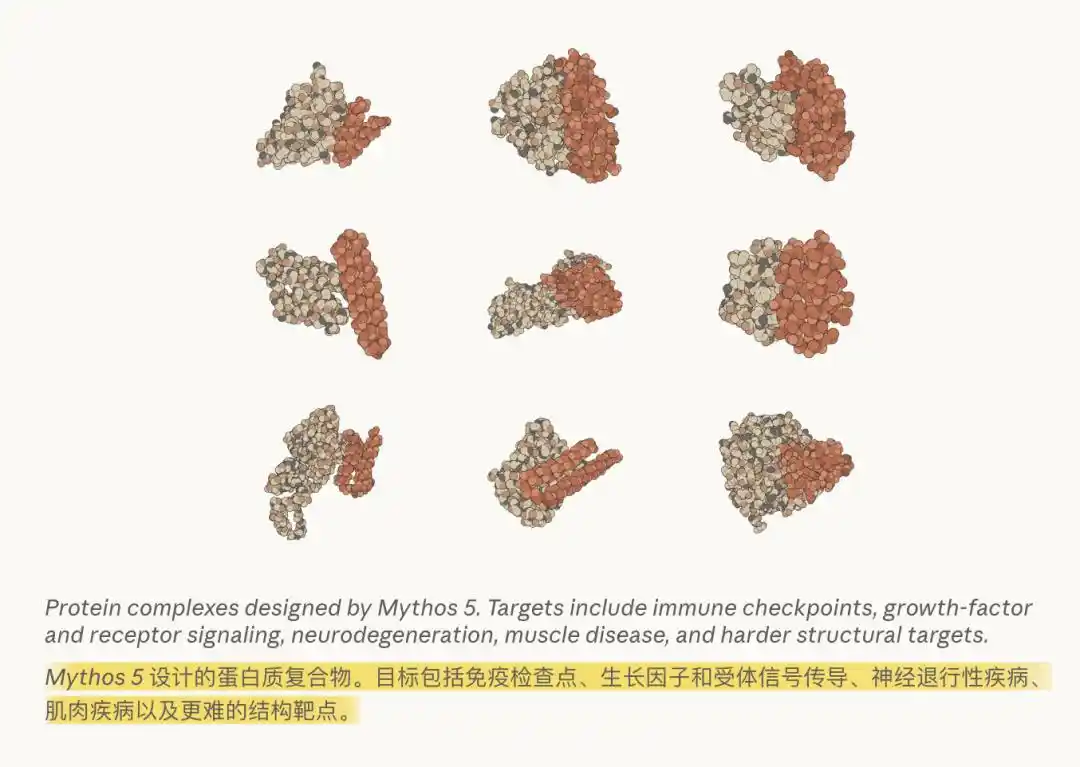
Anthropic also emphasized that Mythos 5 is "our first model capable of consistently generating novel and compelling scientific hypotheses."
In blind direct comparisons with Opus series models, scientists preferred Mythos's molecular biology hypotheses 80% of the time, and several of these hypotheses have already progressed to experimental validation stages.
Simultaneously, one of Mythos's hypotheses—a novel mechanism concerning an E. coli protein—was confirmed in another independent lab's research on the same issue, as documented in the paper "A newly identified detoxification system protects uropathogenic Escherichia coli from reactive chlorine species."
Even more exaggerated, in genomics research, Mythos 5 worked autonomously for over a week, piecing together single-cell data from 138 species, and autonomously designed and trained a custom tiny machine learning model.
This AI-trained miniature model, a hundred times smaller in size, directly outperformed the latest scientific research published just recently in the journal Science.
After Calling for a Halt to AI Research, "Dangerous Capabilities" Seem to Have Been Turned Into a Product Mechanism
The most interesting aspect this time is probably the safety net Anthropic has placed on Fable 5.
To be precise, Fable 5 has a set of independent classifiers behind it.
These classifiers detect whether a user request involves cybersecurity attacks, biological and chemical risks, or model distillation.
Once triggered, Fable 5 will refuse to answer itself and instead automatically route the request to Claude Opus 4.8, informing the user of the downgrade.
Interesting, huh.
In the past, large language models in the safety department typically had the model refuse, saying things like "Sorry, I can't help you with that," "I apologize, I cannot answer," "Sorry, I cannot understand your request," blah blah blah.
Fable 5 takes a different approach.
It doesn't just flat-out refuse; it does model routing.
Regular questions are handled by Fable 5. Once a question is identified as high-risk, the model is instantly switched to Opus 4.8.
Anthropic's reasoning is, Opus 4.8 is itself a strong model, so a downgraded answer is better than an outright refusal, right?~

This design essentially separates capability from safety.
What you use daily is Mythos-level capability.
But when faced with sensitive, aggressive, or jailbreak attempts, Anthropic smoothly switches you to an older model, making the handy tool in your hand suddenly not quite so handy.
(Mainly to guard against certain issues in cybersecurity, biochemistry, and model distillation)
Anthropic provided data—
The good news: over 95% of Fable 5 sessions do not trigger a downgrade.
That means for the vast majority of writing, coding, analysis, research, and office tasks, users get an experience essentially close to Mythos 5.
But the remaining less than 5% of requests enter a stricter security path.
The official website indicates there are three main categories of high-risk areas.
The first is cybersecurity, the second is biology and chemistry, and the third is model distillation.
Behind this mechanism is actually a change in the product form of frontier models.
Safety is no longer just a disclaimer before a model's answer, nor merely a policy description written on a system card.
It has become a product architecture composed of classifiers, model routing, permission tiers, data retention, and red teaming.
Of course, costs come with it.
Fable 5's classifiers are tuned quite conservatively; legitimate requests can also be mistakenly flagged.
For example, biologists studying viruses or security engineers conducting authorized penetration testing exercises might trigger a downgrade during legitimate tasks.
Anthropic itself acknowledges that current guardrails are stricter than ideal and will reduce false positives later.
Another cost is data retention.
Starting with Fable 5, Mythos 5, and subsequent models of the same tier, Anthropic requires that all traffic for Mythos-tier models be retained for 30 days, covering both first-party and third-party usage scenarios.
Officials emphasize this data will not be used for training, only for security monitoring, including identifying complex attacks, novel jailbreaks, and cross-request attacks.
For ordinary users, this might just be a line in the terms.
But for enterprise clients, this is a very real data governance issue.
If you want the strongest capabilities, you have to accept a higher level of security scrutiny and data retention.
Inevitably, the cost of frontier models isn't just reflected in the API bill.
Regarding pricing, both Fable 5 and Mythos 5 are uniformly priced at $10 per million input tokens and $50 per million output tokens.
Indeed, it's much cheaper than the Claude Mythos Preview, but it's still a high-priced model.
In a nutshell, Fable 5 is indeed powerful, but it won't be cheap enough to burn casually.
This also explains why Anthropic simultaneously emphasizes capability, safety, and Token efficiency.
Beta-Testing AI Scholar Experience: The Stronger the AI, the More Humans Resemble the Client
Famous AI scholar and Wharton School professor Ethan Mollick, after gaining early test access, wrote a lengthy article.
Its narrative logic strikes at the core essence of this technological revolution—
The collaborative paradigm between humans and large models has undergone a fundamental, irreversible reversal.
He had Fable 5 create an isochrone map.
This task doesn't sound that fancy, but actually doing it is a huge hassle.
It requires checking flights, checking train schedules, determining road speeds, and handling relationships between different countries, different transportation modes, and different time costs.
Fable 5 itself launched multiple agents to gather information, obtaining over 2200 specific flight details, scraping data for TGV, Shinkansen, and other rail systems, as well as road speed information for various countries.
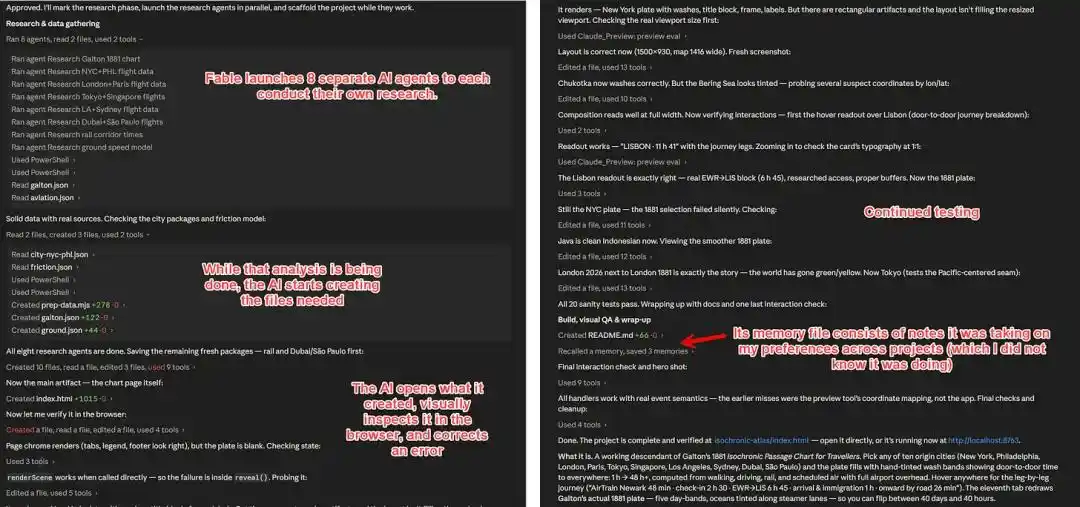
Finally, it integrated this information into a usable map project.
The key point here is that Fable 5 broke down a vague goal into multiple phases like research, information gathering, design, coding, and validation, and pushed forward autonomously.
This differs greatly from past experiences with large models.
Thus, Mollick offers a profound insight.
In the past, humans using large models were like a "Wizard." You had to guide and steer it meticulously, crafting every single prompt, "casting spells" through continuous conversational prompting for the AI to barely perform a trick.
Facing Mythos-level models, humans are now being relegated to the role of "Patron" (here I feel translating it as "the Client" might be more fitting?) or "Principal."
Professor Mollick felt that working with Fable 5 no longer felt like operating a tool, but more like commissioning a small studio.

Furthermore, in Mollick's actual testing, he no longer needed to work at the most micro-instruction level.
He directly fed Fable 5 a 15-page, extremely complex project design document, then left behind a macro-level requirement description.
For the next nine-plus hours, Fable 5 ran in the background in a completely autonomous state.
It generated its own Agent workflow internally, scheduling multiple smaller Agents to handle research, outline writing, mutual proofreading, overturning incorrect assumptions, error correction, and starting over.
Humans didn't even need to intervene a single step in this workflow.
Nine hours later, an extremely high-quality finished product was directly delivered to Mollick.
This is the so-called "Studio" metaphor.
Before, using a large model was like hiring a temporary freelancer who needed constant communication; now, using Fable 5 is like instantly hiring a Hollywood-level design firm or a top-tier research institute for a few cents' worth of tokens.
You don't need to care about how many micro-decisions it makes inside the black box; you just need to play the "Client" who signs off on the final product.
This combination of long-text context and autonomous logic in large models transforms Context from merely a "content container" into a fully-fledged "new intelligent operating system" capable of autonomous inference and long-term operation.
In other words, the more AI resembles a contractor, the more humans resemble a client needing acceptance capabilities.
A small aside, to demonstrate more intuitively and interestingly, the professor also had it generate a series of games for everyone to try.
These games were based on an initial prompt for Claude Code; Fable 5 needed to generate some feasible programs based on the vague prompts I provided, after which I would give some additional hints and encouragement (e.g., "do better") or feedback.
Since Claude Code cannot generate images, all artwork or 3D objects were completely generated through mathematical calculations, without using any external resources.
Here's a demo of a coin toss game:
After early testing of Fable 5, the professor concluded by saying "the final results are impressive."
However, especially when tackling more serious projects, the professor often felt that using this tool was both delightful and unsettling.
Delightful because I just ask, and it delivers. Unsettling also because I just ask, and it delivers.
Indeed.
Returning to Anthropic's release this time.
Some think the most important thing is that Mythos is finally semi-revealed; others believe the most important development is that frontier AI products are entering a new form.
A more powerful model is on the table.
But Anthropic first buckled its seatbelt before handing the keys to everyone.
Some cheer, some feel anxious, and some are debugging code all night, just to catch up with that intelligence curve that keeps sprinting forward, even beginning to escape the micro-view of human sight.
Three More Things
1. Pay attention to the window period. From today until June 22nd, Pro, Max, Team, and Enterprise users can use Fable 5 for free.
But starting June 23rd, to continue using Fable 5, you'll need to purchase additional usage credits.
2. Anthropic says that once production capacity catches up, Fable 5 will be re-included as a standard subscription feature.
API and pay-as-you-go enterprise customers are not affected by this schedule and can start calling as usual from today.
References:
[1]https://www.anthropic.com/news/claude-fable-5-mythos-5
[2]https://www.oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos
[3]https://www.biorxiv.org/content/10.64898/2026.03.12.711259v1
This article is from the WeChat public account "QbitAI," author: Heng Yu






