Авторы: Ли Хайлунь, Су Ян
6 января по пекинскому времени генеральный директор NVIDIA Дженсен Хуан снова вышел на главную сцену CES 2026 в своей знаменитой кожаной куртке.
На CES 2025 года NVIDIA продемонстрировала серийный чип Blackwell и полный стек технологий физического ИИ. На мероприятии Хуан подчеркнул, что открывается эра «физического ИИ». Он описал будущее, полное воображения: беспилотные автомобили с возможностью логического вывода, роботы, способные понимать и мыслить, AIAgent (интеллектуальные агенты), обрабатывающие длинные контекстные задачи с миллионами токенов.
Прошел год, и индустрия ИИ претерпела огромные изменения и эволюцию. Обозревая эти изменения на презентации, Хуан особо отметил модели с открытым исходным кодом.
Он сказал, что такие открытые модели логического вывода, как DeepSeek R1, заставили всю отрасль осознать: когда по-настоящему запускаются открытость и глобальное сотрудничество, скорость распространения ИИ становится чрезвычайно высокой. Хотя открытые модели по общим возможностям все еще отстают от самых современных примерно на полгода, они сокращают разрыв каждые шесть месяцев, а объемы загрузок и использования уже растут взрывными темпами.

По сравнению с 2025 годом, когда больше демонстрировались видение и возможности, на этот раз NVIDIA начала решать проблему «как реализовать» системно: вокруг логического ИИ дополнять инфраструктуру вычислений, сети и хранения, необходимую для длительной работы, значительно снижать стоимость логического вывода и внедрять эти возможности напрямую в реальные сценарии, такие как автономное вождение и робототехника.
Выступление Хуана на CES было построено вокруг трех основных направлений:
● На уровне систем и инфраструктуры NVIDIA перестроила архитектуру вычислений, сети и хранения вокруг потребностей долгосрочного логического вывода. С обновлениями, сфокусированными на платформе Rubin, NVLink 6, Spectrum-X Ethernet и платформе хранения памяти контекста логического вывода, эти обновления направлены на такие узкие места, как высокая стоимость логического вывода, трудности с поддержанием контекста и ограничения масштабируемости, решая проблемы «дать ИИ подумать подольше», «позволить ему подсчитать» и «заставить работать дольше».
● На уровне моделей NVIDIA поставила логический ИИ (Reasoning / Agentic AI) в центр внимания. С помощью таких моделей и инструментов, как Alpamayo, Nemotron, Cosmos Reason, продвигать ИИ от «генерации контента» к способности持续思考 (постоянно мыслить), от «моделей, дающих одноразовый ответ» к «интеллектуальным агентам, способным работать длительное время».
● На уровне применения и внедрения эти возможности напрямую внедряются в сценарии физического ИИ, такие как автономное вождение и робототехника. Как система автономного вождения на базе Alpamayo, так и экосистема робототехники GR00T и Jetson, через сотрудничество с облачными провайдерами и корпоративными платформами, продвигают масштабное развертывание.

01 От дорожной карты к серийному производству: Rubin впервые раскрывает полные данные о производительности
На этой выставке CES NVIDIA впервые полностью раскрыла технические детали архитектуры Rubin.
В своем выступлении Хуан начал с концепции Test-time Scaling (масштабирование на этапе логического вывода), которую можно понять как желание сделать ИИ умнее не за счет того, чтобы «заставить его больше читать», а за счет того, чтобы «дать ему подумать подольше, когда возникает проблема».
Раньше повышение возможностей ИИ в основном достигалось за счет вливания больших вычислительных мощностей на этапе обучения, делая модели все больше; теперь же новое изменение заключается в том, что даже если модель перестает расти,只要 при каждом использовании дать ей немного больше времени и вычислительной мощности на размышления, результат также может значительно улучшиться.
Как сделать «более длительные размышления ИИ» экономически feasible? Новая платформа вычислений ИИ архитектуры Rubin как раз и призвана решить эту проблему.
Хуан представил ее как полноценную систему вычислений ИИ следующего поколения, которая通过协同设计 Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, Spectrum-6 (посредством совместного проектирования Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, Spectrum-6) реализует революционное снижение стоимости логического вывода.

GPU Rubin от NVIDIA — это核心ный чип (ключевой чип) в архитектуре Rubin, отвечающий за вычисления ИИ, с целью значительного снижения удельной стоимости логического вывода и обучения.
Проще говоря, основная задача GPU Rubin — «сделать использование ИИ более экономичным и умным».
Ключевая возможность GPU Rubin заключается в том, что один и тот же GPU может выполнять больше работы. Он может обрабатывать больше задач логического вывода за раз, запоминать более длинный контекст, и общение с другими GPU также происходит быстрее, что означает, что многие сценарии, которые раньше требовали «нагромождения множества карт», теперь можно выполнить с меньшим количеством GPU.
В результате логический вывод не только становится быстрее, но и заметно дешевле.
Хуан на месте освежил в памяти аудитории аппаратные параметры архитектуры Rubin NVL72: содержит 220 триллионов транзисторов, пропускная способность 260 ТБ/с, это первая в отрасли платформа, поддерживающая конфиденциальные вычисления на уровне стойки.

В целом, по сравнению с Blackwell, GPU Rubin демонстрирует межпоколенческий скачок в ключевых показателях: производительность логического вывода NVFP4 повышена до 50 PFLOPS (в 5 раз), производительность обучения до 35 PFLOPS (в 3.5 раза), пропускная способность памяти HBM4 до 22 ТБ/с (в 2.8 раза), пропускная способность межсоединения NVLink на один GPU удвоена до 3.6 ТБ/с.
Эти улучшения, действуя совместно, позволяют одному GPU обрабатывать больше задач логического вывода и более длинный контекст, fundamentally сокращая зависимость от количества GPU.

Vera CPU — это核心ный компонент (ключевой компонент), разработанный specifically для перемещения данных и обработки Agentic, использующий 88 собственных ядер Olympus от NVIDIA, оснащенный 1.5 ТБ системной памяти (в 3 раза больше, чем у Grace CPU), и обеспечивающий согласованный доступ к памяти между CPU и GPU через технологию NVLink-C2C с пропускной способностью 1.8 ТБ/с.
В отличие от традиционных универсальных CPU, Vera专注于 (специализируется на) планировании данных в сценариях логического вывода ИИ и обработке логики многошагового логического вывода, по сути являясь системным координатором, который позволяет高效运行 (эффективно работать) «более длительным размышлениям ИИ».
NVLink 6 с пропускной способностью 3.6 ТБ/с и возможностью вычислений внутри сети позволяет 72 GPU в архитектуре Rubin работать совместно, как один супер-GPU, что является关键基础设施 (ключевой инфраструктурой) для снижения стоимости логического вывода.
Таким образом, данные и промежуточные результаты, необходимые ИИ для логического вывода, могут быстро передаваться между GPU, без необходимости反复等待, копирования или пересчета (многократного ожидания, копирования или пересчета).


В архитектуре Rubin NVLink-6 отвечает за внутренние совместные вычисления GPU, BlueField-4 — за планирование контекста и данных, а ConnectX-9承担 (берет на себя) высокоскоростное сетевое подключение системы вовне. Он确保 (гарантирует), что система Rubin может高效通信 (эффективно взаимодействовать) с другими стойками, центрами обработки данных и облачными платформами, являясь предпосылкой для顺利运行 (бесперебойного выполнения) крупномасштабных задач обучения и логического вывода.
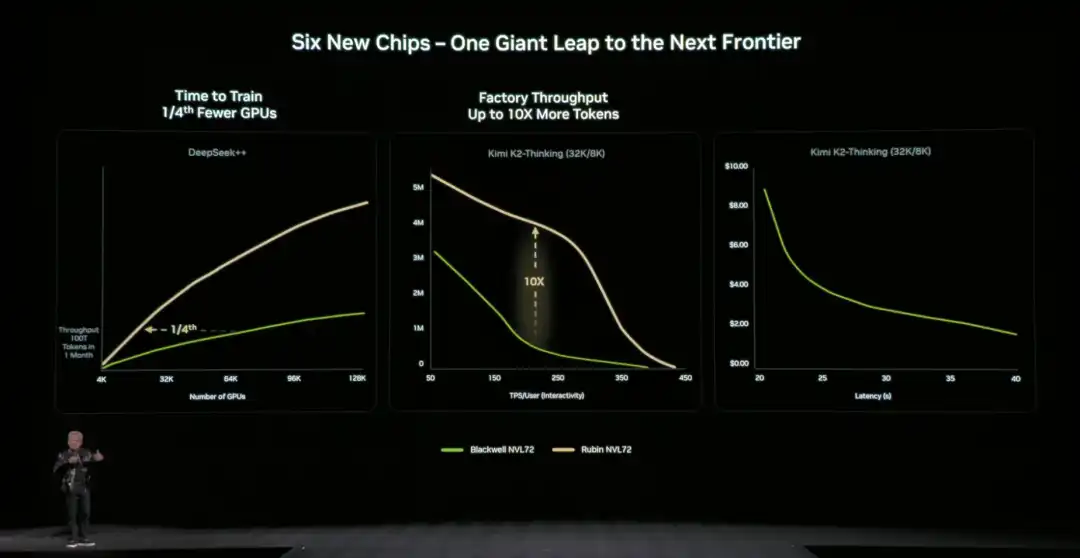
По сравнению с предыдущей архитектурой, NVIDIA также предоставляет конкретные直观的数据 (наглядные данные): по сравнению с платформой NVIDIA Blackwell, можно снизить стоимость токена на этапе логического вывода до 10 раз, а количество GPU, необходимое для обучения моделей смешанных экспертов (MoE), сократить до 1/4 от исходного.
Официальные представители NVIDIA заявили, что на данный момент Microsoft обязалась развернуть сотни тысяч чипов Vera Rubin на следующем поколении суперфабрики ИИ Fairwater, а облачные провайдеры, такие как CoreWeave, предоставят экземпляры Rubin во второй половине 2026 года. Эта инфраструктура «более длительных размышлений ИИ» переходит от технологических демонстраций к масштабному коммерческому использованию.

02 Как решается «проблема узкого места хранения»?
Перед «более длительными размышлениями ИИ» стоит еще одна ключевая техническая проблема: где размещать контекстные данные?
Когда ИИ обрабатывает сложные задачи, требующие многораундовых диалогов, многошаговых логических выводов, генерируется большое количество контекстных данных (KV Cache). Традиционная архитектура либо помещает их в дорогую и ограниченную по объему память GPU, либо в обычное хранилище (доступ слишком медленный). Если не решить это «узкое место хранения», даже самый мощный GPU будет замедлен.
Для решения этой проблемы NVIDIA на этой выставке CES впервые полностью раскрыла платформу хранения памяти контекста логического вывода (Inference Context Memory Storage Platform) на базе BlueField-4, основная цель которой — создать «третий слой» между памятью GPU и традиционным хранилищем. Достаточно быстрый, с достаточной емкостью и способный поддерживать длительную работу ИИ.
С технической точки зрения, эта платформа работает не за счет单一组件 (одного компонента), а является результатом一套协同设计 (набора совместного проектирования):
- BlueField-4 отвечает за аппаратное ускорение управления контекстными данными и доступа к ним,减少 (сокращая) перемещение данных и системные накладные расходы;
- Spectrum-X Ethernet提供 (предоставляет) высокопроизводительную сеть, поддерживающую высокоскоростной обмен данными на основе RDMA;
- Программные компоненты, такие как DOCA, NIXL и Dynamo,则负责 (в свою очередь отвечают) за оптимизацию планирования на системном уровне, снижение задержки и повышение общей пропускной способности.
Можно понять, что подход этой платформы заключается в расширении контекстных данных, которые изначально могли размещаться только в памяти GPU, до независимого, высокоскоростного, совместно используемого «слоя памяти». С одной стороны, это снимает нагрузку с GPU, с другой — позволяет快速共享 (быстро обмениваться) этой контекстной информацией между несколькими узлами и несколькими интеллектуальными агентами ИИ.
Что касается практического эффекта, официальные данные, предоставленные NVIDIA, таковы: в определенных сценариях этот метод может повысить количество обрабатываемых токенов в секунду до 5 раз и обеспечить аналогичный уровень оптимизации энергоэффективности.
Хуан多次强调 (многократно подчеркивал) в своем выступлении, что ИИ развивается от «чат-бота для одноразовых диалогов» до真正的智能协作体 (истинного интеллектуального collaborative агента): им необходимо понимать реальный мир,持续推理 (непрерывно делать логические выводы), вызывать инструменты для выполнения задач и同时保留 (одновременно сохранять) кратковременную и долговременную память. Это и есть核心特征 (ключевая характеристика) Agentic AI. Платформа хранения памяти контекста логического вывода разработана именно для такой формы ИИ, которая работает длительное время и反复思考 (многократно размышляет),通过扩大 (путем расширения) емкости контекста и ускорения межузлового обмена, делая多轮对话 (многораундовые диалоги) и多智能体协作 (collaboration множества интеллектуальных агентов) более стабильными и不再 «замедляющимися при работе».

03 Новое поколение DGX SuperPOD: совместная работа 576 GPU
NVIDIA на этой выставке CES announced выпуск нового поколения DGX SuperPOD (суперузла) на базе архитектуры Rubin, расширяющего Rubin от одной стойки до полноценного решения для всего центра обработки данных.
Что такое DGX SuperPOD?
Если Rubin NVL72 — это «суперстойка» с 72 GPU, то DGX SuperPOD — это соединение нескольких таких стоек вместе, forming更大规模的 (формируя кластер вычислений ИИ большего масштаба). Выпущенная версия состоит из 8 стоек Vera Rubin NVL72, что эквивалентно совместной работе 576 GPU.
Когда масштаб задач ИИ продолжает扩大 (расширяться), 576 GPU в одной стойке может быть недостаточно. Например, для обучения сверхбольших моделей, одновременного обслуживания тысяч агентных ИИ или обработки сложных задач, требующих миллионов токенов контекста. В этом случае требуется совместная работа нескольких стоек, и DGX SuperPOD — это стандартизированное решение, разработанное для таких сценариев.
Для предприятий и облачных провайдеров DGX SuperPOD предоставляет «готовое к использованию» решение для大规模 AI инфраструктуры (крупномасштабной инфраструктуры ИИ). Не нужно самостоятельно исследовать, как соединить сотни GPU, как配置网络 (настроить сеть),如何管理存储 (как управлять хранилищем) и другие вопросы.
Пять核心组件 (ключевых компонентов) нового поколения DGX SuperPOD:
○8 стоек Vera Rubin NVL72 — ядро,提供计算能力 (предоставляющее вычислительную мощность), по 72 GPU на стойку, всего 576 GPU;
○Расширяющая сеть NVLink 6 — позволяет 576 GPU в этих 8 стойках работать совместно, как один超大 GPU (огромный GPU);
○Расширяющая сеть Spectrum-X Ethernet — соединяет различные SuperPOD, а также подключается к хранилищам и внешним сетям;
○Платформа хранения памяти контекста логического вывода — предоставляет共享的 (общее) хранилище контекстных данных для длительных задач логического вывода;
○Программное обеспечение NVIDIA Mission Control — управляет планированием, мониторингом и оптимизацией всей системы.
В этом обновлении основой SuperPOD является система уровня стойки DGX Vera Rubin NVL72. Каждый NVL72 сам по себе является полноценным суперкомпьютером для ИИ, внутри которого 72 GPU Rubin соединены через NVLink 6, что позволяет выполнять крупномасштабные задачи логического вывода и обучения в пределах одной стойки. Новый DGX SuperPOD, в свою очередь, состоит из нескольких NVL72, forming可以长期运行的系统级集群 (формируя кластер уровня системы, способный работать длительное время).
Когда вычислительный масштаб расширяется с «одной стойки» до «нескольких стоек», возникают новые узкие места: как稳定,高效地传输 (стабильно и эффективно передавать) огромные объемы данных между стойками. В связи с этим NVIDIA на этой выставке CES одновременно выпустила коммутаторы Ethernet нового поколения на базе чипа Spectrum-6 и впервые внедрила технологию «совместно упакованной оптики» (CPO).
Проще говоря, это означает, что原本可插拔的 (изначально съемные) optical модули упаковываются непосредственно рядом с коммутационным чипом, сокращая расстояние передачи сигнала с метров до миллиметров, что значительно снижает功耗 (потребление энергии) и задержку, а также повышает общую стабильность системы.
04 «Полный комплект» ИИ с открытым исходным кодом от NVIDIA: от данных до кода
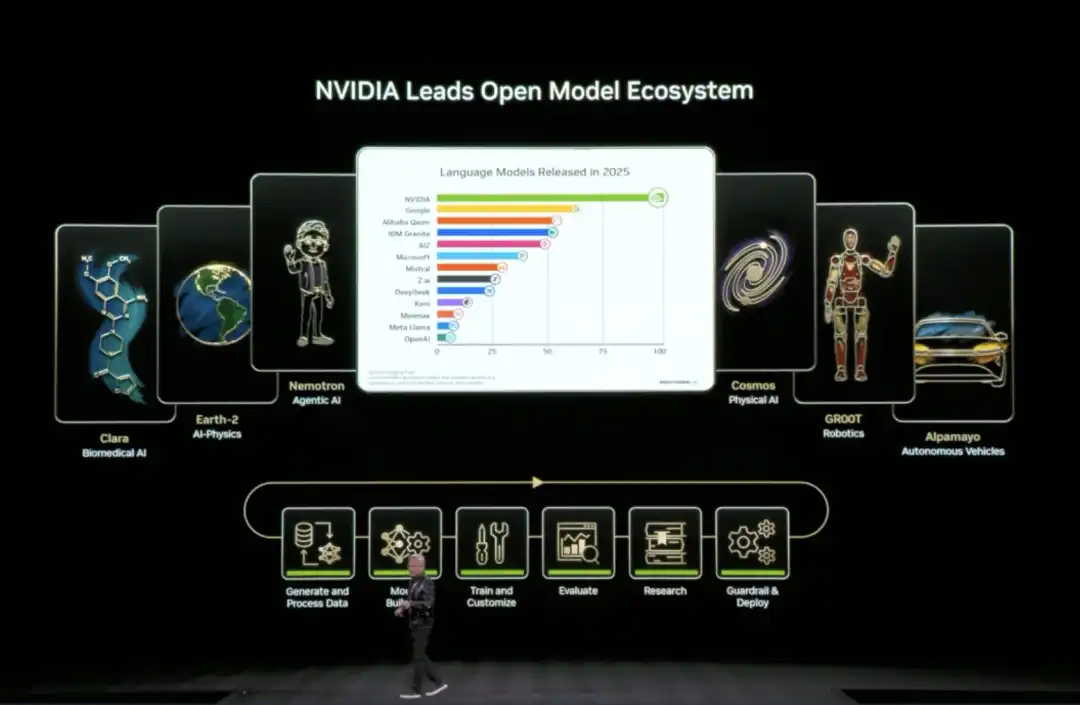
На этой выставке CES Хуан announced расширение своей экосистемы моделей с открытым исходным кодом (Open Model Universe), добавив и обновив一系列 (ряд) моделей, наборов данных, репозиториев кода и инструментов. Эта экосистема охватывает шесть областей: биомедицинский ИИ (Clara), физическое моделирование ИИ (Earth-2), Agentic AI (Nemotron), физический ИИ (Cosmos), робототехника (GR00T) и автономное вождение (Alpamayo).
Обучение модели ИИ требует не только вычислительной мощности, но и высококачественных наборов данных, предварительно обученных моделей, кода обучения, инструментов оценки и整套基础设施 (полной инфраструктуры). Для большинства предприятий и исследовательских учреждений создание всего этого с нуля занимает слишком много времени.
Конкретно, NVIDIA открыла исходный код шести уровней: вычислительные платформы (DGX, HGX и др.), обучающие наборы данных для различных областей, предварительно обученные базовые модели, библиотеки кода для логического вывода и обучения, полные скрипты流程 обучения (процесса обучения) и шаблоны端到端 решений (сквозных решений).
Серия Nemotron является重点 (главным моментом) этого обновления, охватывая четыре направления применения.
В направлении логического вывода включаются небольшие модели логического вывода, такие как Nemotron 3 Nano, Nemotron 2 Nano VL, а также инструменты обучения с подкреплением, такие как NeMo RL, NeMo Gym. В направлении RAG (извлечение с усилением генерации) предоставляются модель векторного внедрения Nemotron Embed VL, модель переранжирования Nemotron Rerank VL, соответствующие наборы данных и библиотека извлечения NeMo Retriever Library. В направлении безопасности есть модель безопасности контента Nemotron Content Safety и配套数据集 (сопутствующие наборы данных), библиотека ограничителей NeMo Guardrails.
В направлении голоса包含 (содержатся) автоматическое распознавание речи Nemotron ASR, набор голосовых данных Granary Dataset и библиотека обработки голоса NeMo Library. Это означает, что если предприятие хочет создать систему поддержки на основе ИИ с RAG, ему не нужно самостоятельно обучать модели внедрения и переранжирования, можно напрямую использовать уже обученный и открытый NVIDIA код.
05 Область физического ИИ: движение к коммерческому внедрению
В области физического ИИ также есть обновления моделей — Cosmos для понимания и генерации видео физического мира, универсальная базовая модель для робототехники Isaac GR00T, модель «зрение-язык-действие» для автономного вождения Alpamayo.

Хуан на CES заявил, что «момент ChatGPT» для физического ИИ приближается, но挑战也很多 (вызовов также много): физический мир слишком сложен и изменчив, сбор реальных данных медленный и дорогой, их永远不够用 (всегда не хватает).
Что делать? Синтетические данные — это путь. Поэтому NVIDIA推出了 (выпустила) Cosmos.
Это открытая базовая модель мира физического ИИ, в настоящее время прошла предварительное обучение на огромном количестве видео, реальных данных о вождении и роботах, а также 3D-симуляциях. Она может понимать, как устроен мир, связывать язык, изображения, 3D и действия.
Хуан表示 (отметил), что Cosmos может реализовать不少 (немало) навыков физического ИИ, такие как генерация контента, логический вывод,预测轨迹 (предсказание траектории) (даже если дать только одно изображение). Она может генерировать реалистичные видео на основе 3D-сцен, генерировать движения, соответствующие физическим законам, на основе данных о вождении, а также生成全景视频 (генерировать панорамные видео) из симулятора, multi-camera изображений или文字描述 (текстовых описаний). Даже редкие сцены也能还原出来 (также могут быть восстановлены).
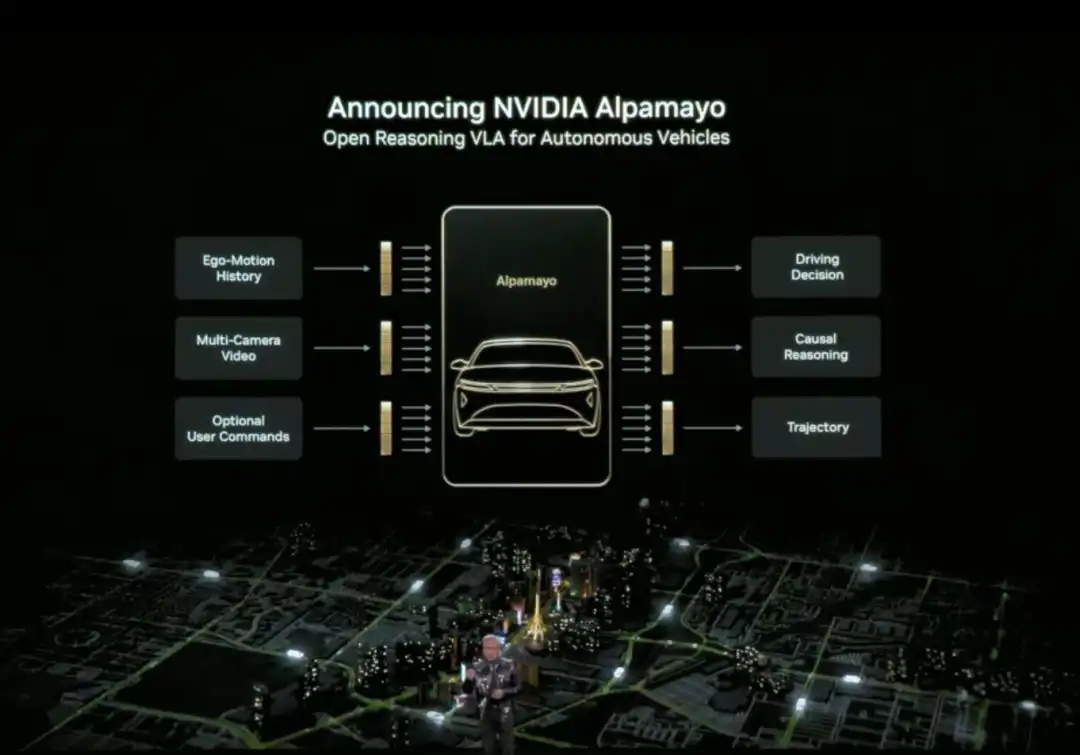
Хуан также официально выпустил Alpamayo. Alpamayo — это инструментарий с открытым исходным кодом для области автономного вождения, а также первая открытая модель логического вывода «зрение-язык-действие» (VLA). В отличие от предыдущих случаев, когда открывался только код, на этот раз NVIDIA открыла полные ресурсы разработки, от данных до развертывания.
Самый большой прорыв Alpamayo заключается в том, что это «логическая» модель автономного вождения. Традиционные системы автономного вождения имеют конвейерную архитектуру «восприятие-планирование-управление»: видят красный свет — тормозят, видят пешехода —减速 (снижают скорость), следуют预设规则 (предустановленным правилам). А Alpamayo внедряет способность «логического вывода», понимает причинно-следственные связи в сложных сценах,预测 (предсказывает) намерения других транспортных средств и пешеходов, и даже может обрабатывать решения, требующие多步思考 (многошагового размышления).
Например, на перекрестке она не просто распознает «впереди машина», а может сделать вывод: «та машина, вероятно, поворачивает налево, поэтому мне应该等它先过 (следует подождать, пока она проедет первой)». Эта способность升级 (повышает) автономное вождение от «движения по правилам» до «мышления, как человек».
Хуан announced, что система NVIDIA DRIVE официально вступает в этап серийного производства, первым применением станет новый Mercedes-Benz CLA, планируемый к выходу на дороги США в 2026 году. Этот автомобиль будет оснащен системой автономного вождения уровня L2++,采用 (используя) гибридную архитектуру «сквозная модель ИИ + традиционный конвейер».
В области робототехники также есть实质性进展 (существенный прогресс).
Хуан сообщил, что包括 (включая) мировых лидеров в робототехнике, таких как Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics и XRlabs, разрабатывают продукты на базе платформы NVIDIA Isaac и базовой модели GR00T, охватывая多个领域 (несколько областей) от промышленных роботов, хирургических роботов до человекоподобных роботов, потребительских роботов.

На现场 презентации (现场 презентации) за спиной Хуана выстроились роботы разных форм и назначений, они были集中展示 (集中展示展示) на многоуровневой сцене: от человекоподобных роботов, двуногих и колесных сервисных роботов до промышленных манипуляторов, строительной техники, дронов и хирургического辅助ного оборудования, представляя собой «картину экосистемы робототехники».
От приложений физического ИИ до вычислительной платформы RubinAI,再到 (а также) платформы хранения памяти контекста логического вывода и «полного комплекта» ИИ с открытым исходным кодом.
Эти действия, продемонстрированные NVIDIA на CES, формируют нарратив NVIDIA об инфраструктуре ИИ для эры логического вывода. Как多次强调 (многократно подчеркивал) Хуан, когда физическому ИИ необходимо持续思考 (непрерывно мыслить),长期运行 (работать длительное время) и真正进入现实世界 (по-настоящему войти в реальный мир), проблема уже не только в том, хватает ли вычислительной мощности, а в том, кто сможет真正搭起来 (по-настоящему построить) всю систему.
На CES 2026 NVIDIA уже предоставила ответ.








