Одинокий разработчик сумел пробиться в верхние строчки трендового рейтинга моделей Hugging Face среди гигантов индустрии?!
Это был обычный день, и я, как обычно, листал трендовый рейтинг на Hugging Face.
Первое место — GLM-5.2, последняя open-source модель от Zhipu AI, старый знакомый, 60+ тысяч загрузок, ничего удивительного.
Второе место — Unlimited-OCR от Baidu, недавно тихо открытый исходный код, способный обрабатывать более 40 страниц документов за раз, загрузки также достигли 70 тысяч.
Смотрю дальше и вдруг вижу личный аккаунт: yuxinlu1.
Хм... Что?!
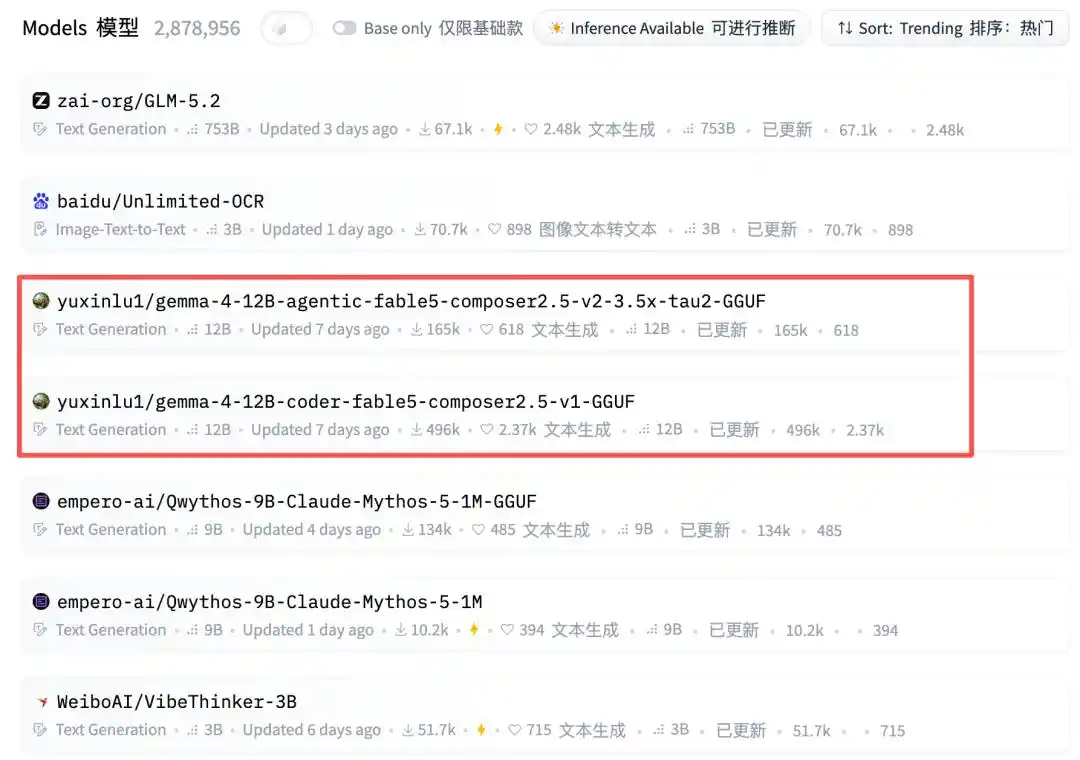
И сразу занимает две позиции.
Смотрю на количество загрузок — по последним данным уже 207 тысяч и 536 тысяч. Ничего себе, что это за волшебная модель?
Более того, неделей ранее модели этого личного разработчика даже возглавляли рейтинг Hugging Face, обгоняя GLM-5.2, и руководитель Zhipu AI даже публично рекомендовал их в X:
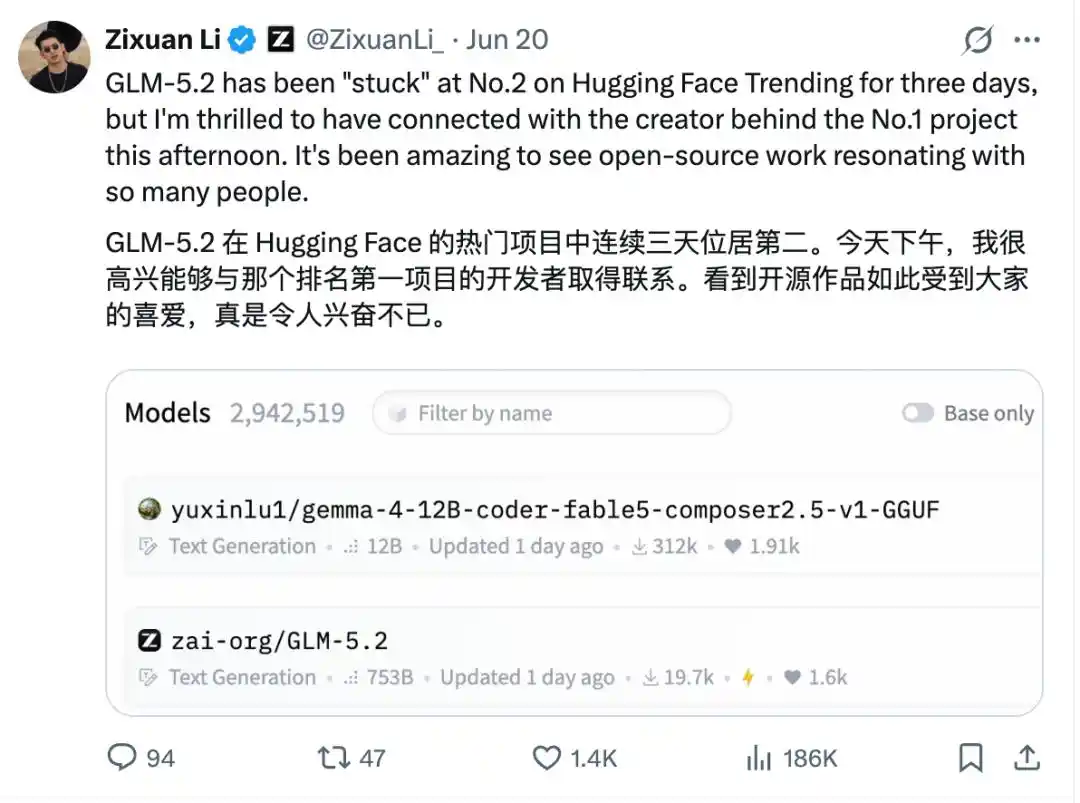
То есть среди имен вроде Zhipu, Baidu, Qwen, NVIDIA... личный аккаунт разработчика втиснулся в ТОП, да еще с такими высокими показателями загрузок.
Неудивительно, что возникает любопытство: Кто такой этот luyuxin? Откуда у него столько энергии?
«Любительская модель» взлетает в трендовом рейтинге Hugging Face
Верхние строчки трендового рейтинга Hugging Face в основном занимают крупные компании, звездные команды и популярные направления.
Например, Zhipu GLM-5.2, 753B гигантских параметров, звездная китайская большая модель; Baidu Unlimited-OCR, попавший в тренд OCR и понимания документов.
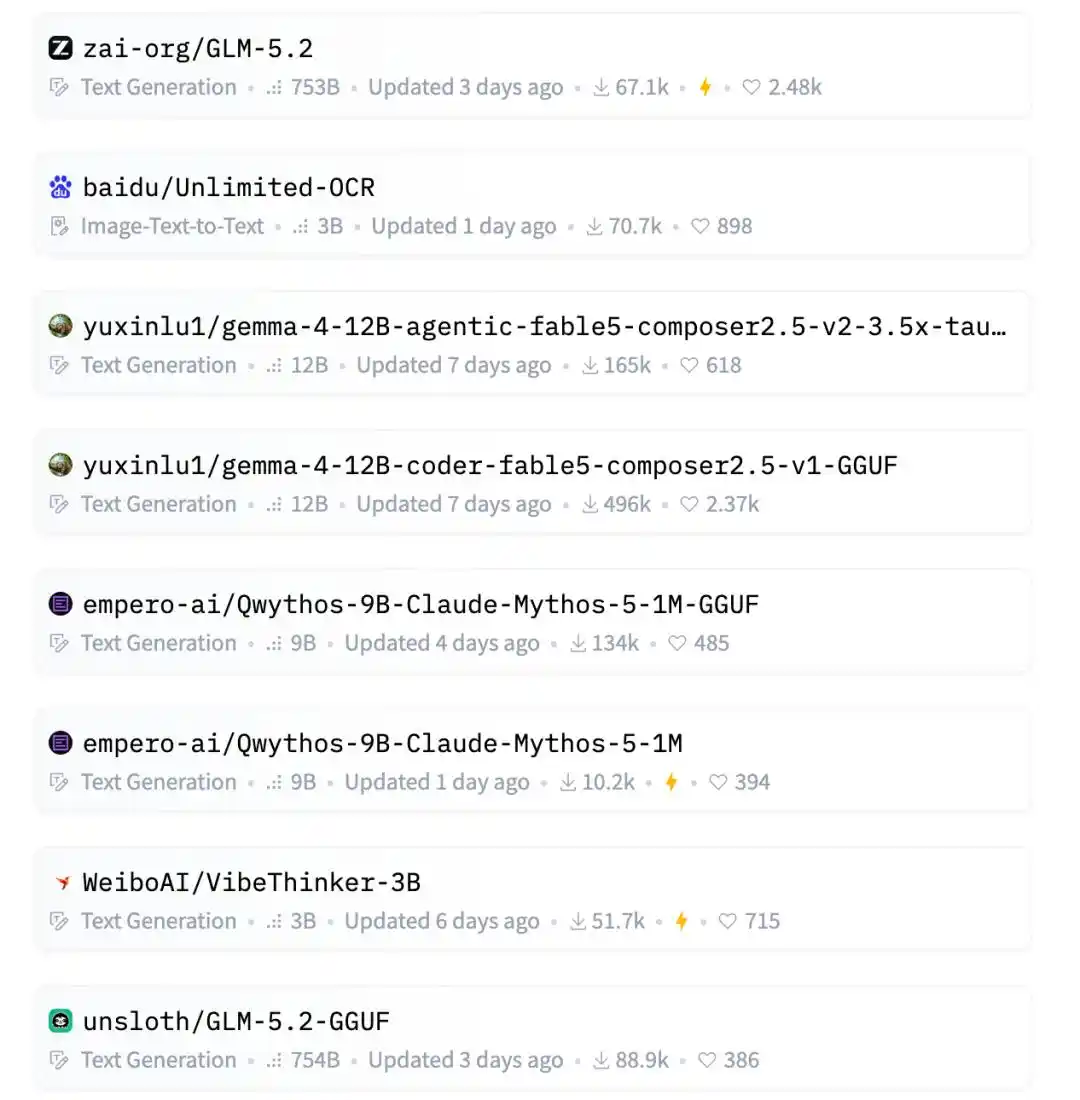
Далее идут Qwen AgentWorld, LocateAnything от NVIDIA, FastContext от Microsoft.
Знакомые лица китайских open-source больших моделей тоже в списке: MiniMax M3, Kimi-K2.7-Code, DeepSeek-V4-Pro.
В направлении генерации изображений также есть Krea, новые модели Krea-2-Turbo и Krea-2-Raw тоже в рейтинге.
А среди них затесались две 12B GGUF модели от luyuxin.
Эй... luyuxin, ну ты слишком выделяешься...
Присмотревшись, видно, что эти две новые модели в основном «дистиллировали» способности к программированию и рассуждениям Fable 5 в маленькую модель Gemma4-12B, которую можно запустить локально.
Для работы требуется всего 4.5 GB видеопамяти, локально, оффлайн, нулевая стоимость API. Обычный пользователь с потребительской видеокартой или даже Mac с унифицированной памятью может ее запустить.
Две модели имеют разную специализацию.
V1 — это Coder версия, ориентированная на написание кода, решение задач, генерацию исполняемого кода.

Согласно карточке модели, ее обучающие данные — «верифицируемые» рассуждения о коде: каждая цепочка рассуждений соответствовала коду, который действительно был запущен и протестирован, и только прошедшие тесты сохранялись.
Учительские данные в основном из Composer 2.5 от Cursor, плюс Fable 5 — задачи, с которыми не справился Composer 2.5, передавались Fable 5 для повторного анализа, генерации новых цепочек рассуждений и правильного кода.
После выпуска V1 модель несколько дней подряд возглавляла трендовый рейтинг Hugging Face.
V2 — агентская версия, с добавленной возможностью многошагового вызова инструментов, может использоваться как локальный агент, умеет самостоятельно читать, рассуждать, действовать и снова проверять.
Автор также запустил бенчмарки — на поднаборе telecom tau2-bench базовый gemma-4-12B набрал 15%, а модель версии V2 — 55%, что примерно в 3.5 раза выше базовой производительности.

Однако автор также отмечает, что это относительные значения, полученные при локальном самостоятельном тестировании в одной предметной области на 20 задачах, их нельзя напрямую сравнивать с официальным рейтингом, и он честно признает, что до frontier больших моделей еще далеко.
Автор также упоминает: позже Fable 5 была снята с доступа, и только его собственный набор данных сохранил «оригинальный» процесс рассуждений Fable 5.
А ту часть reasoning, которая отсутствовала в данных, предоставленных сообществом, он заново сгенерировал с помощью Claude Opus 4.8(xhigh), добавляя по одному.
Он также признает, что восстановленные траектории «могут отличаться от оригинального Fable 5», но на тот момент это была единственная可行的 схема.
В обсуждении он также раскрывает, что этот набор данных для тонкой настройки на самом деле содержит всего около 10 тысяч примеров. Он подчеркивает, что объем данных не так важен, как многие думают, ключевое — это качество, отбор и верификация.
Еще одна очень практичная причина такой высокой популярности этих моделей на Hugging Face: их можно запускать локально.
Обе модели представлены в формате GGUF с квантованием.
GGUF — это распространенный формат локальных моделей в экосистеме llama.cpp, пользователи могут загружать их напрямую с помощью таких инструментов, как llama.cpp, Ollama, LM Studio, Jan и др.
Это особенно привлекательно для сценариев кодинга. Ведь написание кода, просмотр репозиториев, запуск команд, отладка часто связаны с приватными проектами и локальным окружением. Возможность запуска на своей машине означает, что не нужно загружать код в облако и каждый раз платить за вызовы API.
Что еще важнее, порог входа не такой уж высокий.
В карточке модели V1 написано, что самая маленькая версия Q2_K занимает около 4.5 ГБ, для запуска приватного, оффлайн помощника по программированию достаточно около 4.5 ГБ видеопамяти или унифицированной памяти.
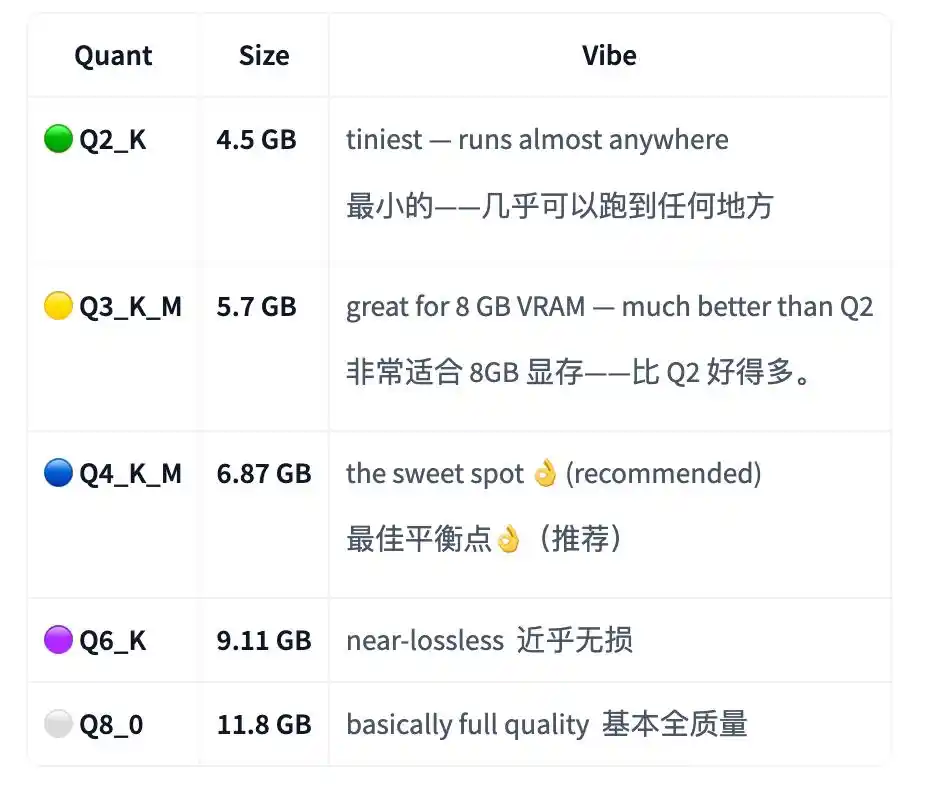
Автор рекомендует оптимальную точку — Q4_K_M, размер около 6.87 ГБ; более качественная версия Q8_0 — около 11.8 ГБ.
Для V2, которая больше ориентирована на агентские задачи, автор не выложил Q2_K. Причина — не прошла стресс-тест, недостаточно надежна.
Поэтому минимальная надежная версия V2 начинается с Q3_K_M, около 5.7 ГБ; рекомендованная Q4_K_M по-прежнему около 6.87 ГБ.
Автор также анонсировал дальнейшие планы — V3 уже в пути.
Он сообщил, что V3 продолжит развитие в направлении coding+agentic на основе той же линии 12B. Автор сказал, что не ожидал такого значительного улучшения после дообучения, поэтому будет продолжать продвигать это направление.
В частности, на telecom tau2-bench у V2 все еще есть проблемы с «излишними попытками, повторными retry», V3 продолжит исправлять это через дополнительное обучение.
С другой стороны, он также работает над более крупной версией: Qwen3.6-27B. По сути, это применение того же рецепта coding+agentic к более крупной базовой модели для пользователей с более значительными ресурсами видеопамяти.
Один человек, 40 часов, прорывается среди гигантов
Суметь в одиночку взлететь в трендовый рейтинг Hugging Face, набрав в сумме более 700 тысяч загрузок, и пробить себе место среди множества крупных компаний и организаций.
Кто же этот автор на самом деле?
Связавшись с автором, мы также узнали его историю.
Его зовут Лу Юйсинь, в настоящее время он является магистрантом, изучающим направление ИИ в одном из американских университетов, бакалавриат окончил по специальности «Данные и бизнес-анализ», а также дополнительно прошел полный курс full-stack разработки, изучив frontend, backend, разработку ПО и обработку данных.
Эти две взорвавшиеся популярностью модели не являются его основной деятельностью, это чисто личный проект, финансируемый из собственных средств.
«Open source — это на самом деле только трата денег, это не приносит никакого дохода». Он хорошо это понимает, поэтому первоначальной мотивацией для создания V1 было скорее «саморазвитие»:
Знания, преподаваемые в университете, обновляются слишком медленно, во время учебы в магистратуре профессора рассказывали о материалах двух-трехлетней давности, а ИИ развивается стремительно, поэтому он использовал этот проект, чтобы заставить себя идти в ногу с новейшими технологиями.

Для создания этих моделей он «сжег» целый тарифный план Claude Max 20×, только на V2 ушло более 40 часов.
Синтез данных по одному, ручная очистка, обучение, оценка, повторное обучение — почти все это он делал в одиночку.
Что касается аппаратного обеспечения, он использовал видеокарту RTX 5090 с 32 ГБ видеопамяти VRAM; также имеется около 96 ГБ локальных ресурсов SSD для совместного использования. Фактически доступный объем ресурсов составляет около 128 ГБ.
Для личного разработчика это неплохо, но это несопоставимо с вычислительными мощностями крупных компаний и AI Lab.
Он рассказал нам, что на самом деле больше всего времени в этом процессе заняла не тренировка, а обработка данных.
Особенно данные для агентских задач: реальные диалоги часто очень длинные, одна задача может содержать десятки шагов, тысячи или даже десятки тысяч токенов. Но из-за ограничений видеопамяти при обучении он мог за один раз подавать максимум 2048 токенов.
Поэтому он применил обработку, подобную «скользящему окну»: в каждом многораундовом диалоге, взяв последнее пользовательское сообщение в качестве якоря и сосредоточившись на одном вызове инструмента, он обрезал контекст до допустимого бюджета.
За основу для V1 и V2 была взята модель Gemma 4-12B. Выбрал он ее не потому, что с ней легко работать, как раз наоборот: формат и протоколы инструментов Gemma 4 довольно специфичны, адаптация к ним сложна, и даже поддержка со стороны многих клиентов несовершенна.
Лу Юйсинь сказал, что, с одной стороны, это вызов себе; с другой стороны, потому что размер 12B очень привлекателен.
Он подсчитал, что при квантовании примерно до 3 бит многие пользователи Mac с 8 ГБ унифицированной памяти также смогут запустить модель, оставив при этом некоторое окно контекста.
Теперь я знаю, что у многих людей компьютеры все еще с унифицированной памятью около 8 ГБ. Поэтому я хочу при максимально возможном количестве параметров дать возможность большему числу людей использовать модель.
Лу Юйсинь суммировал ценность локальных моделей двумя словами:
Конфиденциальность, бесплатность.
Он считает, что многие люди просто хотят, чтобы ИИ помог им организовать файлы, обработать данные, сделать презентацию или попробовать агента, и не обязательно готовы ежемесячно платить за Claude или GPT.
Возможно, человек просто хочет поиграть, почему это обязательно должно быть платным?
После выпуска V1 он сначала не уделял особого внимания рейтингу, просто, как обычно, написал в карточке модели: если понравится, и будет много загрузок и лайков, он продолжит делать V2.
Неожиданно через два-три дня модель внезапно поднялась с неизвестного места на восьмое; после сна — вышла на первое.
Затем хлынули комментарии и issues.
Он читал почти каждый. В пиковые дни он тратил три-четыре часа в день на просмотр комментариев на Hugging Face, ответы на вопросы, тестирование отзывов пользователей и затем сообщение им результатов.
Он сказал: «Сообщество имеет потребности, и я действительно работаю над их удовлетворением, это самое главное».
Оказывается, еще и любитель веб-романов...
На HF Лу Юйсинь опубликовал в общей сложности 9 публичных моделей. Помимо двух взорвавшихся популярностью моделей, он также делал модели, «дистиллирующие Claude напрямую».
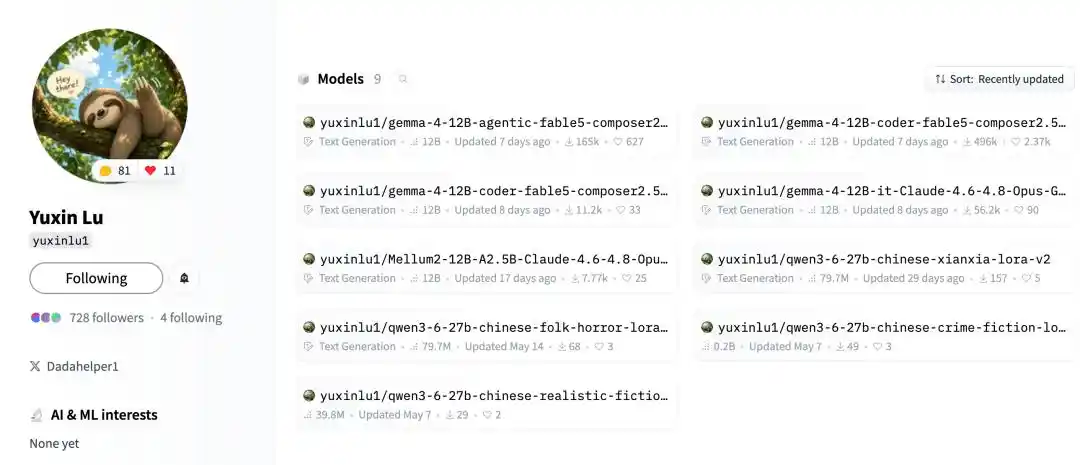
Например, gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF, которую можно понимать как модель дистилляции общей версии Gemma4-12B.
Она не ограничивается только программированием, скорее, она «впитывает» стиль ответов, привычки рассуждений, способность thinking Claude Opus в эту локальную модель на 12B.
Другая модель и вовсе взяла за основу модель программирования Mellum2 от JetBrains, специализируясь на дистилляции рассуждений.
Продолжаем смотреть дальше...
Стоп, как здесь оказались модели для тонкой настройки на веб-романы?

Ничего себе, и еще разделены на четыре жанра, все это LoRA для китайских веб-романов, и все на основе Qwen3.6.
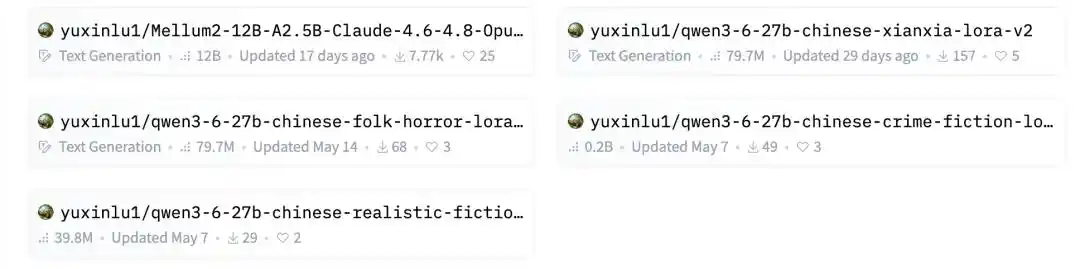
Лу Юйсинь рассказал нам, что на самом деле это был его вход в мир создания моделей на Hugging Face.
Потому что он сам любит читать романы. Когда читаешь незавершенный роман, читатель испытывает нетерпение; автору, ежедневно пишущему новые главы, тоже тяжело.
Поэтому он хотел создать целый бесплатный пайплайн для генерации романов, используя LoRA для романов на китайском языке в разных стилях, чтобы авторы могли ускорить работу с помощью ИИ, а читатели могли быстрее видеть контент.
Но LoRA для китайских романов не очень популярны на HF, позже он обнаружил, что пользователей больше интересуют coding и agentic, поэтому направление постепенно сместилось в нынешнее русло.
На вопрос о том, какие советы он мог бы дать другим личным разработчикам, Лу Юйсинь сказал: Самое важное — искренность и настойчивость.
Искренность — не преувеличивать возможности модели. Где сильные стороны, где слабые — все нужно честно рассказывать.
Нужно правдиво сообщать людям. Если я обману вас, сказав, насколько моя модель сильна, но при реальном использовании возникнет много проблем, то в следующий раз, когда я что-то выпущу, вы мне не поверите.
Настойчивость — это то, с чем автор open-source должен смириться: вы обязательно столкнетесь с негативными отзывами.
После того как модель стала популярной, Лу Юйсинь также сталкивался с сомнениями, но решил продолжать.
По его мнению, путь open source изначально сложен.
Даже возглавив трендовый рейтинг Hugging Face, вы не получите прямого дохода. Чаще всего вы тратите собственные деньги на вычислительные мощности, время на обработку данных, ответы на комментарии, исправление ошибок, а затем еще сталкиваетесь с небольшой долей негатива.
А поддерживает его на этом пути еще и очень личный рабочий ритм.
Лу Юйсинь упомянул, что у него СДВГ.
Раньше это могло означать трудности с последовательным продвижением чего-либо в долгосрочной перспективе, но в такой быстро меняющейся области, как ИИ, быстрая смена интересов, быстрое вхождение в состояние hyperfocus, наоборот, стало преимуществом.
Он даже считает: «Эпоха ИИ — это царство людей с СДВГ.» Потому что когда одно направление теряет актуальность, если продолжать углубляться только в него, а потом переключаться на изучение нового, можно опоздать.
В конце разговора мы задали тот самый первоначальный вопрос:
Как личный разработчик смог пробиться в первые ряды среди гигантов?
Ответ Лу Юйсиня был очень взвешенным.
Он считает, что крупные компании, конечно, могут сделать лучше, у них больше исследователей и более мощные вычислительные ресурсы.
Но выпуская open-source маленькие модели, крупные компании часто преследуют цели продвижения бренда, привлечения трафика к API и т.д.; а у личного разработчика нет такого багажа, поэтому он может более сфокусированно решать конкретную проблему.
Я рад, но не потому, что я действительно полностью их превзошел, а, возможно, потому, что подошел к делу более ответственно.
По его мнению, именно в этом и заключается возможность для личных open-source авторов: не обязательно делать универсальную модель, а достаточно хорошо решить одну конкретную проблему.
Если вы тоже хотите попробовать эту локальную модель, ссылка приведена ниже.
Дружеское напоминание: на данный момент наиболее подходящей платформой является llama.cpp, рекомендуем использовать ее в первую очередь~
Адрес на HF: https://huggingface.co/yuxinlu1
Эта статья из WeChat официального аккаунта «量子位» (ID: QbitAI), автор: 关注前沿科技