2026 год. Конференция разработчиков Google I/O оставила только два впечатления: дерзость.
Они не только как насильно запихивают ИИ-агентов во все ключевые точки входа — поиск, браузер, смартфоны, умные очки — но и один за другим выкидывают три козырных карты: Gemini 3.5 Flash, видео-модель Omni и совершенно нового ИИ-помощника Spark.
Продемонстрировав мускулы, Сундар Пичаи даже хвастливо заявил, что ежемесячная активная аудитория Gemini превысила 9 миллиардов, и одновременно объявил о значительном снижении цен.
Посыл предельно ясен: Я лучше тебя и дешевле.
Разве это не объявление войны?
01
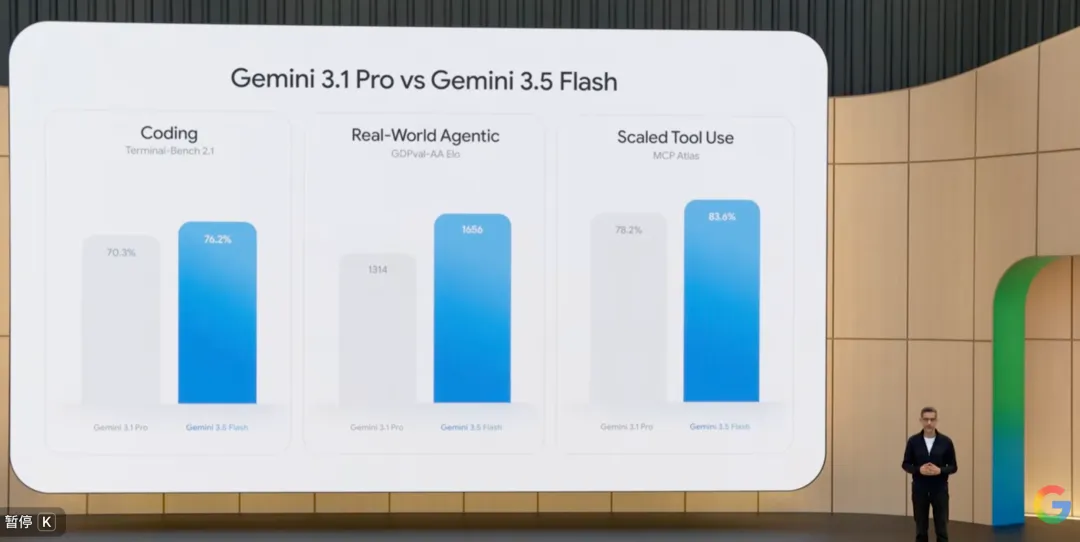
Без сомнения, самой впечатляющей частью конференции стал анонс Gemini 3.5 Flash.
Обычно «Pro» представляет основную силу, а «Flash» — облегченную и быструю версию.
По количеству параметров модели, 3.5 Flash действительно меньше, чем 3.1 Pro, но по результатам почти всех тестов на рассуждение и кодирование первый показывает более высокие результаты:
Тест GSM8K на сложное математическое рассуждение: 3.5 Flash получил 95.8%, превзойдя 93.2% у 3.1 Pro; Полная версия теста на генерацию кода SWE-bench: скорость решения у 3.5 Flash достигла 38.4%, значительно превысив 32.1% у 3.1 Pro......
Почему?
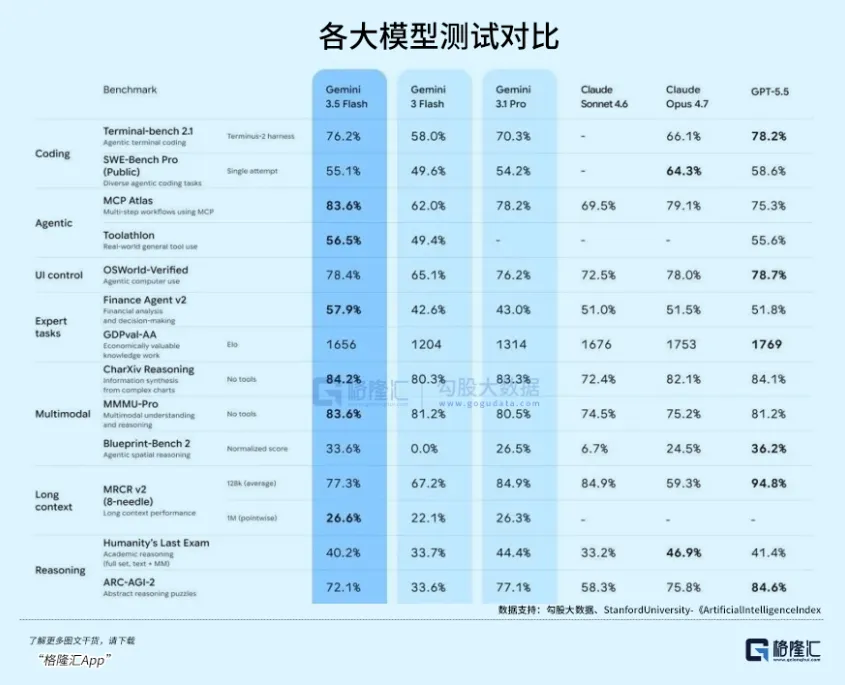
Согласно «Gemini 3.5 Technical Report», опубликованному DeepMind, ключевых технологий две.
Предельное дистиллирование знаний: На этот раз Google не просто наращивал вычислительные мощности для обучения Flash, а использовал ранее не раскрытую модель-учителя «Gemini 3.5 Ultra» для дистилляции пониженной размерности в Flash.
Согласно разбору в твите главного научного сотрудника DeepMind Джеффа Дина, доля тонкой настройки 3.5 Flash на высококачественных наборах данных с цепочками рассуждений увеличилась на 400% по сравнению с предыдущим поколением.
Это означает, что он унаследовал «логический мозг» огромной модели, а не мертвую «базу знаний» для заучивания.
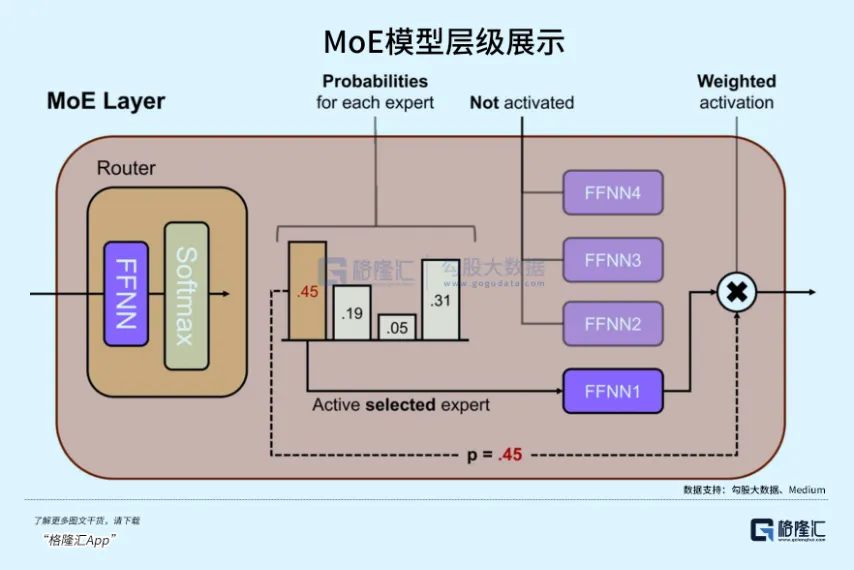
Новая архитектура MoE (Mixture of Experts, смесь экспертов): Внутри 3.5 Flash Google использует сети экспертов с более мелкой гранулярностью.
Традиционный MoE может иметь только 8 или 16 экспертов, активируя 1-2 за раз, что достаточно для поддержки моделей триллионного масштаба параметров.
Согласно анализу меморандума об инвестициях в ИИ-инфраструктуру a16z за 2026 год, 3.5 Flash использует 256 микро-экспертов, активируя 4 наиболее эффективных из них в каждом выводе.
Поэтому он может поддерживать чрезвычайно низкий объем активированных параметров, покрывая при этом огромное многомодальное пространство признаков.
По показателю TTFT (Time to First Token, время до первого токена) 3.5 Flash достиг менее 65 миллисекунд.
А человеку, чтобы моргнуть, нужно 100-150 миллисекунд.
Проще говоря, когда он работает как агент, с физиологической точки зрения человека невозможно заметить никакой задержки.
Для разработчиков, которым требуется частое использование инструментов, многократное обдумывание и чрезвычайно низкая задержка, это действительно идеальная супер-агентская основа.
Только опираясь на такую предельную инженерную оптимизацию, можно установить доминирование в «развертывании на стороне устройства» в условиях острой конкуренции.
Первый, нативный многомодальный Gemini Omni Flash.
Omni означает «всеобъемлющий», что соответствует предыдущему GPT-4o; одно только название передает интенсивность конкурентной борьбы.
По крайней мере, по производительности Gemini Omni Flash гораздо больше заслуживает символ «o», чем GPT-4o.
Ранние версии вроде Sora или Gemini 1.5 были по сути «сборными», преобразуя речь в текст, а текст — в визуал.
Но выпущенный Omni — это истинное нативное сквозное многомодальное выравнивание. Он не только нативно понимает временную согласованность и физические законы в видео, но и задержка снизилась со среднего по отрасли уровня 400-600 мс до 120 мс.
Пример с конференции: пользователь наливает воду с надетой камерой, чашка почти полная, Omni говорит «Стоп, стоп, стоп!» за 0.5 секунды до переполнения.
Такое реальное время выводов о физическом состоянии реального мира кажется простым, но имеет большое значение: ИИ официально эволюционировал из чат-бота на экране во вспомогательный инструмент реального мира.
Хотя и на начальной стадии.
Второй, ИИ-помощник Spark.
Согласно интервью The Verge с вице-президентом по инжинирингу Android, Spark наделен нативными правами управления API на системном уровне в Android 17.
Короче говоря, сложные процессы, для которых раньше требовалось открывать много приложений, теперь не требуют ручных действий. Достаточно дать команду Spark, и он все сделает: отправит сообщения, отсортирует почту, соберет расписание, отследит изменения на веб-страницах, выявит скрытые списания по счетам, пакетно обработает документы и т.д. и т.п., даже с учетом вашего тона и предпочтений...
Другими словами, с ИИ-помощником приложения нам в основном не понадобятся, любая сложная операция сводится к одному.
Третий, умные очки.
Почему снова очки?
По крайней мере, с точки зрения Google, бесшовная интеграция зрения и слуха является окончательным хостом для многомодальных больших моделей.
Эти очки не имеют никакого броского дизайна, все сосредоточено на практических возможностях:
Полноцветные волноводные линзы Micro-OLED весом всего 4 грамма, коэффициент пропускания света до 85%;
Оснащены собственным облегченным чипом Gemini для работы на устройстве, задержка локального вывода ≤12 мс, без подключения к сети может выполнять перевод в реальном времени, распознавание изображений, анализ сцен;
Нативно интегрирован с агентом Spark, синхронизирует данные с телефоном и облаком, предоставляет персонализированные услуги: напоминания о встречах, перевод в реальном времени, предупреждения об окружении и т.д.
Проще говоря, они обходят экран телефона и помещают агента через очки в первое поле зрения человека.

Контента действительно слишком много. Кажется, Google единовременно использовал все свои главные козыри, объявив рынку одну истину:
Алгоритм без точки входа — ничто.
Эпоха гонки за параметрами больших моделей и тестовыми баллами прошла. У чистых поставщиков моделей больше нет защитного рва. Будущее — это четырехмерная война: «устройство + облако + экосистема + железо».
Запихивание ИИ во все продукты — это фактически переформатирование всей логики распределения интернет-трафика: от «пользователь активно ищет/кликает» к «ИИ-агент активно предоставляет услуги».
Для разработчиков и малого бизнеса это прекрасно, потому что базовые вычислительные мощности и модели становятся чрезвычайно дешевыми, и все могут сосредоточиться на инновациях на уровне приложений.
Но другим конкурентам, вероятно, сейчас хочется только ругаться.
02
Когда Сундар Пичаи непринужденно объявил со сцены: «Ежемесячная активная аудитория Gemini официально превысила 9 миллиардов», в зале произошел немалый переполох.
9 миллиардов — больше, чем общая MAU всех американских конкурентов.
Как это сделали?
Ответ прост и груб: принудительное внедрение.
Google не нужно тратить деньги на рекламу для привлечения пользователей, как независимым ИИ-компаниям. Достаточно добавить значок рядом со строкой адреса браузера Chrome, встроить ярлык вызова в нижнюю панель навигации 3 миллиардов Android-смартфонов, выпустить полномасштабное обновление в Google Workspace...
Стоимость привлечения клиентов практически равна нулю.
Что еще важнее, в ближайшее время огромное количество высококачественных, многомодальных данных реального мира, генерируемых 9 миллиардами активных пользователей — их взгляды при просмотре товаров через умные очки, логика, которую они корректируют при обработке дел с помощью Spark, взаимодействие с видео-моделью Omni — все это станет питательной средой для воспитания Gemini 4.
Это чрезвычайно прочный барьер: чем лучше модель -> тем больше пользователей -> тем больше генерируется данных -> тем лучше становится модель.
Чтобы быстро усилить этот цикл, Google прямо объявляет ценовую войну всем конкурентам:AI Ultra пакет снижен с 249.99 долларов США в месяц до 99.9 долларов США в месяц.
3.5 Flash цена ввода на миллион токенов упала до 0.02 доллара, цена вывода на миллион токенов — 0.08 доллара.
Что это за фантастическая цена?
Для сравнения, средняя цена по отрасли для моделей аналогичного уровня составляет 0.15-0.2 доллара и 0.6-1 доллар соответственно.
Пичаи подсчитал: ведущие клиенты обрабатывают около 1 триллиона токенов в день. Переключение 80% рабочей нагрузки на Gemini 3.5 Flash на год сэкономит более 10 миллиардов долларов.
Почему они могут продавать ИИ по цене капусты?
Главная опора: вертикально интегрированная вычислительная инфраструктура.
Такие гиганты, как OpenAI, Anthropic, внешне процветают, но по сути являются «арендаторами вычислительных мощностей», им нужно покупать мощности у Microsoft, Amazon, а те, в свою очередь, платят NVIDIA.
А у Google есть собственные TPU, плюс чрезвычайно изощренная эффективность разреженной активации MoE в 3.5 Flash, что сводит к минимуму вычислительные затраты.
Они могут полностью использовать преимущества тяжелых активов для атаки по принципу «сверху вниз» на чистые алгоритмические компании.
Логика ясна.
Базовые большие модели быстро становятся товаром. Как вода и электричество — видели ли вы когда-нибудь сверхприбыльные водопроводные компании?
Google не боится, что сами большие модели не приносят прибыли, потому что деньги можно заработать на поисковой рекламе, облачных услугах и отчислениях от экосистемы Android.
Но для OpenAI, Anthropic, Cohere, Mistral, которые живут исключительно за счет продажи API больших моделей, это невозможно.
Инвесторы, вероятно, сейчас хотят схватить Сэма Альтмана за голову и спросить: «API Google стоит в десять раз дешевле твоего, а производительность лучше. Скажи мне, как твоя бизнес-модель будет работать?»
Конкурентная ситуация во многих отраслях ускорит процесс перераспределения.
ИИ-производители должны как можно скорее найти более дешевые источники вычислительных мощностей или сами заняться созданием чипов.
Далее, все еще работающая втайне Apple.
Комбинация умных очков + видео-модель Omni + нативное системное управление через Spark, несомненно, представляет угрозу для iPhone.
Согласно «Отчету о прогнозах тенденций в потребительской электронике» Macquarie: в течение следующих трех лет доля времени взаимодействия без экрана, основанного на зрении/голосе, по прогнозам, вырастет с нынешних 8% до 35%.
Если пользователи привыкнут использовать очки и голос для повседневной работы и развлечений, время использования экрана неизбежно значительно сократится.
Если Apple не сможет представить достаточно впечатляющие носимые устройства для контратаки (Vision Pro слишком тяжелый и дорогой,注定只是 игрушка для избранных), ее монополия на точки входа в эпоху мобильного интернета столкнется с беспрецедентными вызовами.
Это не итерация, а революция.
Google бросил вызов всем соперникам тремя мечами: технологией, трафиком и ценой.
Кто сейчас посмеет смеяться над его «болезнью крупной корпорации»?






