2026 год стал знаковым переломным моментом в развитии глобального искусственного интеллекта — капитальные затраты на инференс у сверхмасштабных облачных провайдеров впервые в истории превысили капитальные затраты на обучение. Отраслевой фокус сместился с «создания больших моделей» на «использование больших моделей», а структура спроса на вычислительные ресурсы претерпела фундаментальный переворот.
В эпоху обучения ключевым противоречием вычислительной мощности была «двойная точность с плавающей запятой и масштаб кластера»; с наступлением эры инференса центральным противоречием стали «пропускная способность памяти и задержки связи».
Узким местом инференса больших моделей перестали быть только вычисления — веса модели, промежуточные активации и KV Cache нуждаются в частом обмене между внешней DRAM (например, HBM) и GPU. Чем больше модель, тем выше энергопотребление и задержки при перемещении данных, которые в конечном итоге значительно превышают энергопотребление самих вычислений, формируя тем самым «стену памяти».
GPU NVIDIA, построившие крепкую крепость на основе CUDA и NVLink, все же не могут избежать простоев GPU, вызванных узкими местами в пропускной способности.
Китайская компания, работающая с большими моделями, Zhipu, провела простой эксперимент: в кластере инференса на 512 GPU, оставив GPU, модель и код неизменными, просто повысив лимит пропускной способности сети с 200 ГБ/с до 400 ГБ/с, пропускная способность инференса сразу выросла на 10%, а задержка выдачи первого токена снизилась на 19% — принцип прост: стоит лишь расширить дорогу, и машины смогут ехать быстрее.
Однако архитектуры, отличные от GPU, представленные такими компаниями, как Cerebras, похоже, пробивают брешь в этой «стене памяти».

Сравнение размеров чипа Cerebras WSE-3 и GPU NVIDIA B200
Сущность Cerebras: вычислительная машина на основе SRAM с памятью рядом с ядром
Cerebras Systems была основана в Кремниевой долине Эндрю Фельдманом и другими, а первые члены команды основателей все были из компании SeaMicro, занимавшейся низкопотребляющими микросерверами, которая позже была приобретена AMD, после чего:
2015: команда основателей определила направление «вычислений на уровне пластины»;
2016: завершена регистрация, привлечен раунд финансирования A, начат скрытый этап разработки;
2019: выпущен первый продукт — чип WSE-1 и система CS-1, на основе технологии TSMC 16 нм;
2021: выпущено второе поколение продуктов на основе технологии TSMC 7 нм;
2024: выпущено третье поколение продуктов (WSE-3 / CS-3) на основе технологии TSMC 5 нм; чип и система полностью произведены в США, являясь подлинными чиповыми системами чисто американского производства.
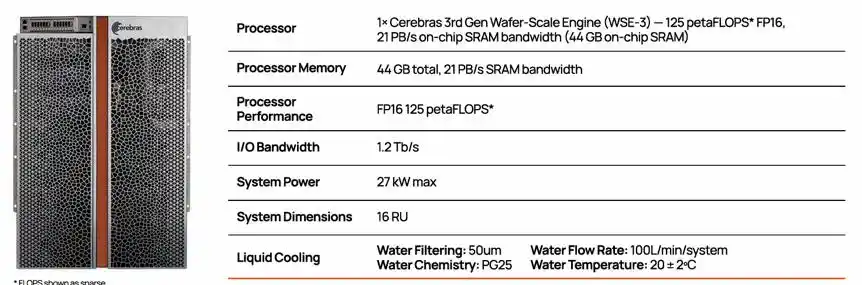
Конфигурация системы CS-3, содержащей один чип WSE-3
Архитектурная философия процессора на уровне пластины (Wafer-Scale Engine, WSE) от Cerebras проста, прямолинейна и бьет точно в болевую точку: обменом на предельное увеличение физического пространства достигается предельное сокращение задержек при перемещении данных.
Обычные чипы режут пластину на множество маленьких кристаллов, как, например, делает NVIDIA со своими GPU. Cerebras поступает наоборот: не резать, а сделать из почти целой пластины один гигантский чип, называемый Wafer-Scale Engine (WSE).
Традиционные чипы формируются путем разрезания целой 300-миллиметровой пластины на сотни маленьких кристаллов; Cerebras же выбирает сохранить целую пластину, используя ее непосредственно как цельный чип. Новейший WSE-3 содержит 4 триллиона транзисторов, 900 тысяч AI-ядер, каждое из которых оснащено 48 КБ локальной SRAM, что обеспечивает общий объем внутрикристальной SRAM в 44 ГБ, предоставляя пропускную способность внутрикристальной памяти 21 ПБ/с и пропускную способность коммутационной сети 214 Пбит/с, что в тысячи раз превышает пропускную способность традиционной HBM.
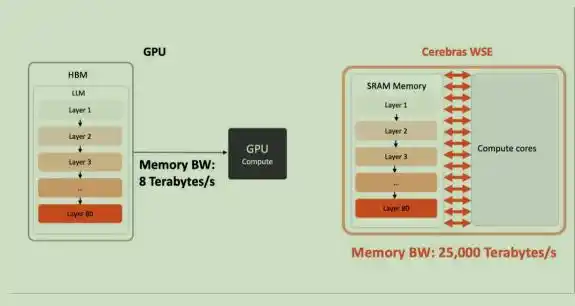
Пропускная способность памяти Cerebras WSE в 2625 раз выше, чем у упакованного чипа NVIDIA B200, что ломает барьер пропускной способности памяти в сценариях инференса больших моделей.
В архитектуре Cerebras веса модели никогда не хранятся в SRAM на кристалле, а находятся во внешней памяти MemoryX и передаются слой за слоем на большой чип. Реализация заключается в раздельном хранении весов нейронной сети и вычислительных блоков.
Все веса модели хранятся внешне в модуле расширения памяти MemoryX, и веса, необходимые для вычисления каждого слоя сети, передаются в систему CS-3 по требованию, слой за слоем. Веса хранятся в DRAM и флэш-памяти MEMORY X и передаются в систему CS-3 на полной скорости пропускной способности. Эти веса не сохраняются в системе CS-3, даже временно не кэшируются; CS-3 полагается на базовый механизм потоковой передачи данных в ядре для выполнения вычислений.
Благодаря архитектуре на уровне пластины, Cerebras демонстрирует непреодолимые барьеры, подобные удару с более высокого измерения, в инференсе LLM, ограниченном пропускной способностью памяти. При генерации токена за токеном веса потоково передаются слой за слоем с внешнего MemoryX в CS-3; скорость обработки токенов для разных моделей в 1.5 - 5 раз выше, чем у NVIDIA B200.
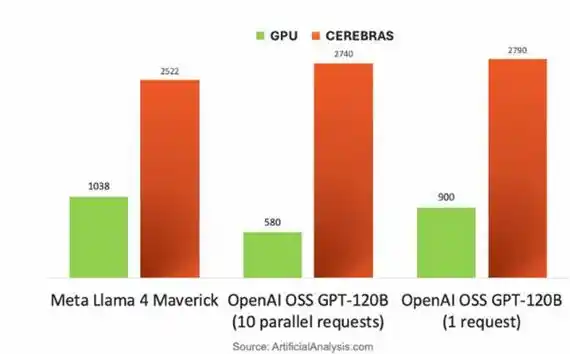
Сравнение скорости обработки токенов GPU NVIDIA DGX B200 и чипа Cerebras CS-3 на разных больших моделях
Ключевое преимущество заключается в следующем: 44 ГБ внутрикристальной SRAM CS-3 обеспечивают сверхвысокую пропускную способность в 21 ПБ/с (в 2625 раз больше, чем у B200) и внутреннюю коммутацию в 214 Пбит/с, что позволяет потоковой передаче весов избавиться от ограничений интерфейса HBM. Поэтому особенно заметно превосходство в TTFT (Time To First Token, время от отправки запроса до возврата первым токеном моделью), при длинном контексте и рабочих нагрузках агентов.
Хотя веса хранятся внешне в MemoryX и загружаются слой за слоем по требованию без кэширования на кристалле, CS-3, полагаясь на базовый механизм потоков данных в ядрах, выполняет вычисления с полной точностью FP16 без потерь в SRAM; благодаря линейному масштабированию производительности, он также демонстрирует впечатляющую общую пропускную способность при конкурентном инференсе для нескольких пользователей.
Кроме пропускной способности, есть и преимущество в энергопотреблении. В недавнем выступлении председателя правления компании Zhongji InnoLight Лю Шэна также упоминалось, что требования клиентов к оптическим модулям составляют 1 пДж/бит, в то время как сейчас это 10 пДж/бит. В чипе Cerebras энергопотребление коммутации составляет всего 0.15 пДж/бит, тогда как энергопотребление коммутации текущих GPU составляет 10 пДж/бит.
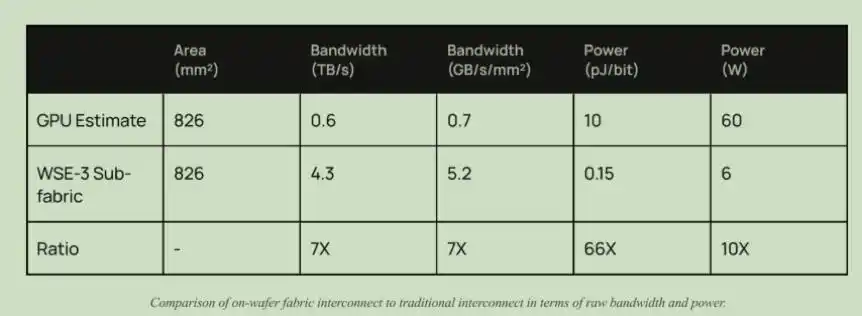
Сравнение пропускной способности и энергопотребления архитектур коммутации Cerebras и GPU
Таким образом, если архитектура крупночиповых решений на уровне пластины от Cerebras станет мейнстримом для инференса или даже обучения AI, это, возможно, окажет значительное сдерживающее и структурно изменяющее влияние на объемы поставок традиционных оптических модулей и CPO (со-упакованной оптики). Основная логика заключается в следующем: высокий спрос на оптические модули и CPO по своей сути направлен на решение проблемы узких мест в пропускной способности «межчиповой» и «межузловой» коммутации в GPU-кластерах; архитектура же Cerebras как раз решает проблему путем «устранения распределенной коммутации».
Контр-интуиция: «истинные» и «ложные» недостатки крупночиповых решений на уровне пластины
В основе чипа всегда лежит принцип Trade Off (искусство компромиссов). Cerebras, добиваясь предельной пропускной способности внутрикристальной SRAM, также сталкивается с некоторыми проблемами.
Низкий выход годных?
Наоборот, размер одного AI-ядра уменьшен до 0.05 кв. мм (1% от размера одного вычислительного ядра H100), поэтому выход годных, наоборот, выше. Благодаря внутрикристальной маршрутизации можно отключать и обходить дефектные ядра, что повышает устойчивость к дефектам в 100 раз по сравнению с традиционными многоядерными процессорами. Фактически на чипе 1 миллион AI-ядер, но с учетом выхода годных, публично заявляется о 900 тысячах AI-ядер.
Специализируется только на инференсе, а не на обучении?
В течение нескольких лет после основания Cerebras обучение было основной темой, поэтому компания всегда много работала вокруг обучения. Просто после взрывного роста спроса на инференс все увидели, что ее преимущества в инференсе более очевидны.
На самом деле, упрощенные распределенные вычисления также приносят ряд преимуществ: снижение сложности кода и уменьшение накладных расходов на связь.
Для обучения модели с 175 миллиардами параметров на 4000 GPU обычно требуется около 20 тысяч строк кода для распределенного обучения.
Cerebras добилась эквивалентного обучения на 565 строках кода — вся модель может разместиться на пластине, и не требуется обработка сложностей распараллеливания данных.
Масштабирование SRAM закончилось, ключевые преимущества достигли физического потолка.
Продукт третьего поколения, основанный на 5 нм TSMC, имеет объем SRAM всего на 10% больше, чем продукт второго поколения на основе 7 нм TSMC; после 5 нм площадь ячейки SRAM практически не уменьшается с прогрессом технологического процесса.
Это означает, что Cerebras больше не сможет, как раньше, значимо увеличивать свое ключевое преимущество (объем SRAM) за счет перехода на более совершенные технологические процессы TSMC (например, с 5 нм на 3 нм).
Из-за ограничений по размеру пластины, возможностям охлаждения и производственной себестоимости ресурсы хранения, такие как внутрикристальная SRAM, не могут линейно масштабироваться синхронно с вычислительными ядрами, и соотношение ресурсов сталкивается с узким местом. Это практически блокирует ее путь эволюции.
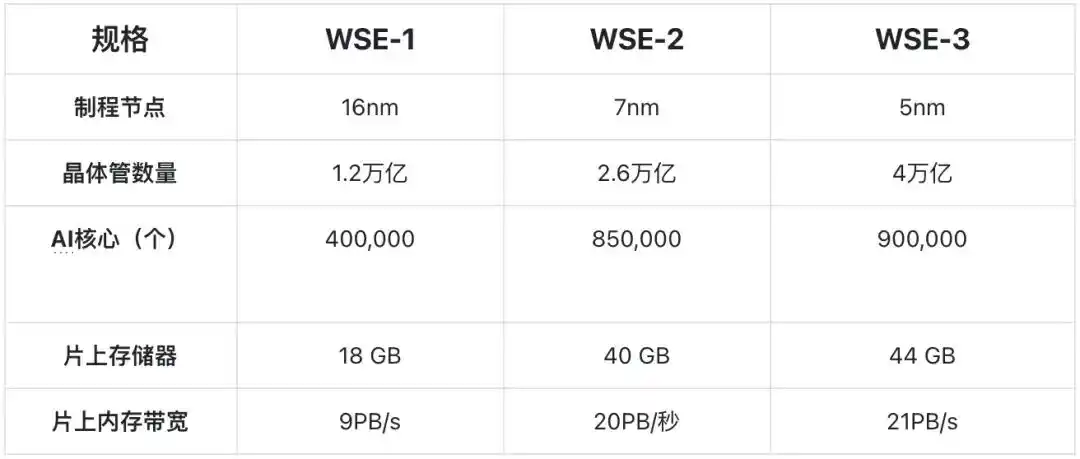
Технические характеристики трех поколений продуктов Cerebras
Тройное испытание: охлаждение, технология и экосистема.
Концентрированное тепловыделение на всей пластине приводит к высокой плотности теплового потока, что требует использования специальных дата-центров и систем жидкостного охлаждения. Кроме того, универсальность экосистемы означает, что клиенты должны адаптироваться к ее кастомизированному программному стеку; совместимость с существующими универсальными фреймворками программирования, такими как CUDA, слабая, а затраты на портирование и адаптацию ПО высоки.
Низкая внешняя пропускная способность, ведущая к «изолированности» масштабирования.
Из-за ограничений физического проектирования на уровне пластины количество I/O-контактов, которые можно вывести на краях WSE, крайне ограничено, что приводит к I/O-пропускной способности всего в 150 ГБ/с. По сравнению с двунаправленной пропускной способностью NVLink от NVIDIA, достигающей 1.8 ТБ/с, это похоже на улитку. Это означает, что WSE чрезвычайно сложно масштабировать вовне с высокой скоростью. Хотя межсистемное соединение SwarmX от Cerebras работает неплохо, перед лицом очень больших моделей, требующих высокоскоростного межчипового взаимодействия, крайне низкая внешняя пропускная способность становится структурным физическим ограничением.
Борьба направлений: собственные разработки крупных компаний, сколько осталось времени у Cerebras?
У крупных компаний есть не один способ решения проблемы «инференсу нужна более высокая пропускная способность + меньшая задержка», они ведут наступление по трем параллельным направлениям, осаждая технологические преимущества стартапов.
1. Собственные ASIC-чипы
Google TPU v8 уже разделился на две версии: training-specific и inference-specific; AWS Trainium 4 в пути; Microsoft Maia уже используется внутри Azure, построен на основе технологии TSMC 3 нм, имеет нативные тензорные ядра FP8/FP4, переработанную систему памяти, оснащен 216 ГБ HBM3e, 272 МБ внутрикристальной SRAM; даже Anthropic начала оценку собственного inference chip.
Вероятность развития по этому пути очень высока, что напрямую приведет к сжатию TAM (общего доступного рынка) «закупок инференса у сторонних производителей» к 2028 году на 10% до 25%.
2. Технологическая универсализация пути стандартной упаковки (Packaging)
Это прямое сдерживание Cerebras с более высокой позиции.
SoW (System-on-Wafer) от TSMC уже широко доступна клиентам, CoWoS 9.5x interposer также будет запущена в 2027 году.
То, что делают эти два продукта — объединение нескольких кристаллов на уровне пластины — по сути является технологической универсализацией и демократизацией физической технологии Cerebras.
Vera Rubin от NVIDIA войдет в эту экосистему во второй половине 2026 года.
Хотя собственное cross-reticle stitching от Cerebras является эксклюзивным, максимальный срок его эксклюзивности составляет всего 2-3 года. После 2027-2028 годов его технологический барьер будет размыт передовыми решениями TSMC в области упаковки.
3. Прорыв в области оптической коммутации/оптических вычислений
Пределы коммутации электронных чипов и стены памяти достигнуты; высокая пропускная способность, низкая задержка и нулевые перекрестные помехи фотоники являются окончательным решением.
Оптические направления, представленные такими компаниями, как Lumentum, набирают силу. Самое большое преимущество wafer-scale — это вычисления на кристалле, но модели неизбежно будут становиться все больше, и высокоскоростная коммутация за пределами wafer scale — это насущная необходимость.
По мере созревания CPO (со-упакованной оптики) и оптических соединений (Optical Interconnects), весьма вероятно, что в будущем мы увидим прямое внедрение оптического ввода-вывода в пластину WSE, ломающее оковы электрической коммутации; NVIDIA также может путем приобретения компаний, обладающих определенными архитектурными преимуществами (например, LPU, таких как Groq), в сочетании с оптической коммутацией разработать системы на уровне пластины, совместимые с существующим ПО сверхузлов NV.
Забег на краю пропасти: бизнес и поставки Cerebras
В настоящее время Cerebras сталкивается с забегом на краю пропасти, подстегиваемым огромными объемами заказов.
Сделки с ведущими крупными клиентами, такими как OpenAI, вынудили Cerebras трансформироваться из чиповой компании в нового типа облачного провайдера. Она больше не просто продает оборудование, ей необходимо в короткие сроки закрепить и построить огромные объемы энергетических мощностей и инфраструктуры для дата-центров.
Согласно требованиям контрактов, Cerebras должна поставлять мощность дата-центров в размере 250 МВт ежегодно в период с 2026 по 2028 год. Однако требования систем на уровне пластины к машинным залам чрезвычайно высоки, их нельзя просто впихнуть в традиционные IDC с воздушным охлаждением. В настоящее время прогресс Cerebras в подготовке мощностей дата-центров уже заметно отстает от требований контрактов.
От выпуска инженерных образцов до строительства заводов, от согласования энергоснабжения до развертывания систем охлаждения — это трясина капиталоемких и долгосрочных проектов.
Эпилог: Налево или направо?
Возвращаясь к первоначальному тезису, когда переломная точка в вычислительных мощностях для инференса уже наступила, ядро архитектуры вычислений всегда заключается в компромиссе.
Нет абсолютно правильного или ошибочного пути, есть лишь относительно оптимальное решение для самой важной рабочей нагрузки. А нагрузки уже меняются.
Cerebras идет налево, выбирая предельную физическую оптимизацию, обменивая целую пластину и огромный объем SRAM на предельно низкую задержку для одной задачи, что непобедимо в сценариях, крайне чувствительных к задержке первого токена.
NVIDIA идет направо, выбирая сохранение универсальности, используя HBM + NVLink + огромную пропускную способность кластера, чтобы справиться с тысячами изменений в нагрузках, оставаясь неизменной перед лицом перемен.
Бушующие ветра перемен, неясный путь вперед. Именно эта двойная неопределенность — технологическая и коммерческая — и рождает возможность для подрывных изменений. В потоке вычислительных мощностей, ведущих к AGI, еще рано делать окончательные выводы — потому что именно неопределенность создает возможности.
Эта статья взята с официального аккаунта WeChat «Исследовательский институт чесночных гранул», автор: ПиЛи Юся (Pili Youxia)






