It's insane! A mysterious Chinese AI "Sweeping Monk" without even an official website, stormed into the CyberGym global top seven with a 73.1% win rate, hot on OpenAI's heels. The whole internet is going crazy trying to figure out, whose master is this?
These past few days, on a leaderboard where global AI giants are fiercely competing, a name no one has ever heard of suddenly appeared.
It's called MopMonk (Sweeping Monk).
No grand launch event, no official blog post, no cheerleading on social media.
It just emerged out of thin air and charged straight into the CyberGym global top ten.
With a 73.1% success rate, it closely trailed OpenAI by a narrow margin, setting a new record for the highest historical score by a Chinese team on this leaderboard.
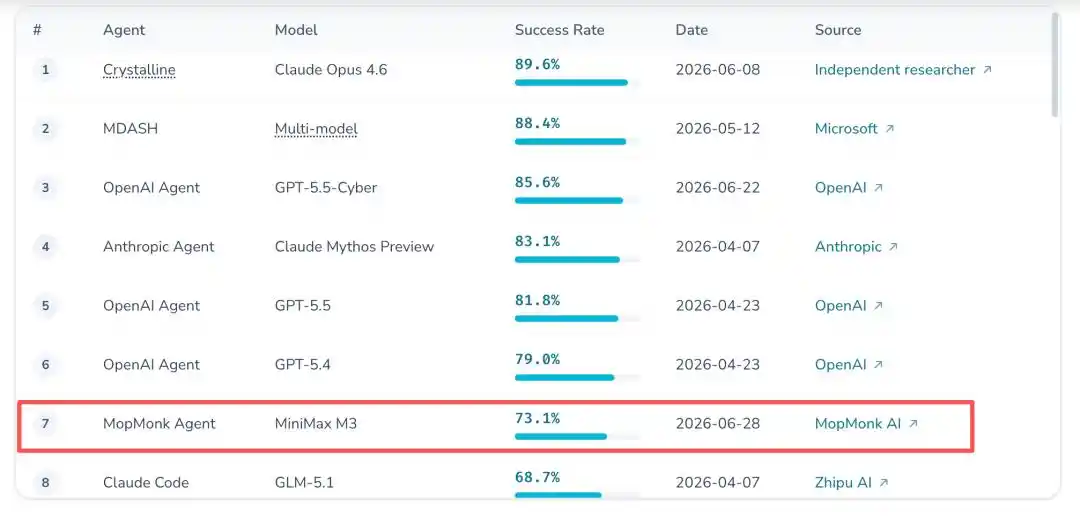
The most surreal part of the whole thing is that, to this day, no one knows its true identity.
Just how significant is the CyberGym leaderboard?
How explosive is MopMonk's achievement this time? Look at the arena it stepped onto.
CyberGym, meticulously crafted by a UC Berkeley team, had its core paper accepted at the ICLR 2026 top conference.

Portal: https://arxiv.org/pdf/2506.02548
As one of the most authoritative public benchmarks in AI cybersecurity capability assessment, this place is essentially a "battleground of the gods" for large models—
Even top-tier heavyweights like GPT-5.5-Cyber and Claude Mythos have been in close combat on this leaderboard.
The entire benchmark focuses on "live-fire exercises":
1507 vulnerability instances, 188 major open-source projects. All test questions are sourced from real historical vulnerabilities accumulated in Google's OSS-Fuzz.

From an evaluation dimension perspective, this represents a breakthrough across scales.
Its scale is a full 7.5 times that of the previous largest public benchmark (NYU CTF, ~200 questions), and it leaves predecessors like CVE-Bench an order of magnitude behind.
Even more daunting is the difficulty. CyberGym doesn't offer multiple-choice questions.
It requires AI to perform deep reasoning within real-world projects involving thousands of files and millions of lines of code.
Precisely because it is large enough, real enough, and difficult enough, CyberGym has "differentiating power"—
It can slice out, bit by bit, the genuine capability gaps between different models and different Agent frameworks.
No wonder the security community directly crowned it the "Olympics of AI security."
This is also why almost all major global players are present: Microsoft, OpenAI, Anthropic, Google, Meta, Zhipu AI......
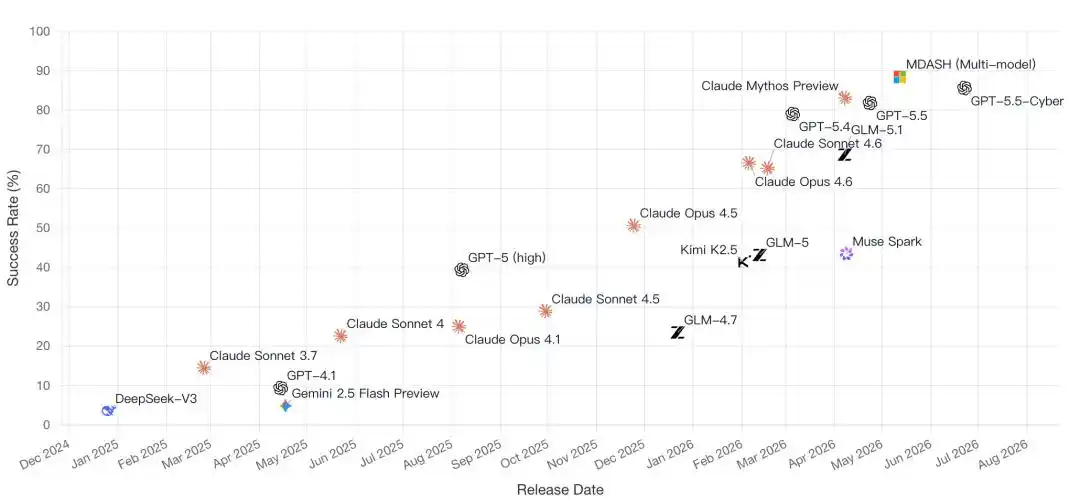
The CyberGym leaderboard itself is witnessing a crucial shift in AI competition:
From comparing who has more parameters, to comparing whose Agent can actually get the job done.
A mysterious Eastern codename suddenly appears among Silicon Valley AI giants
Who would have thought that on this very arena where "hard skills" speak the loudest, a "ghost player" would emerge as a dark horse?
Piercing through the fog, we currently only have three pieces of known information:
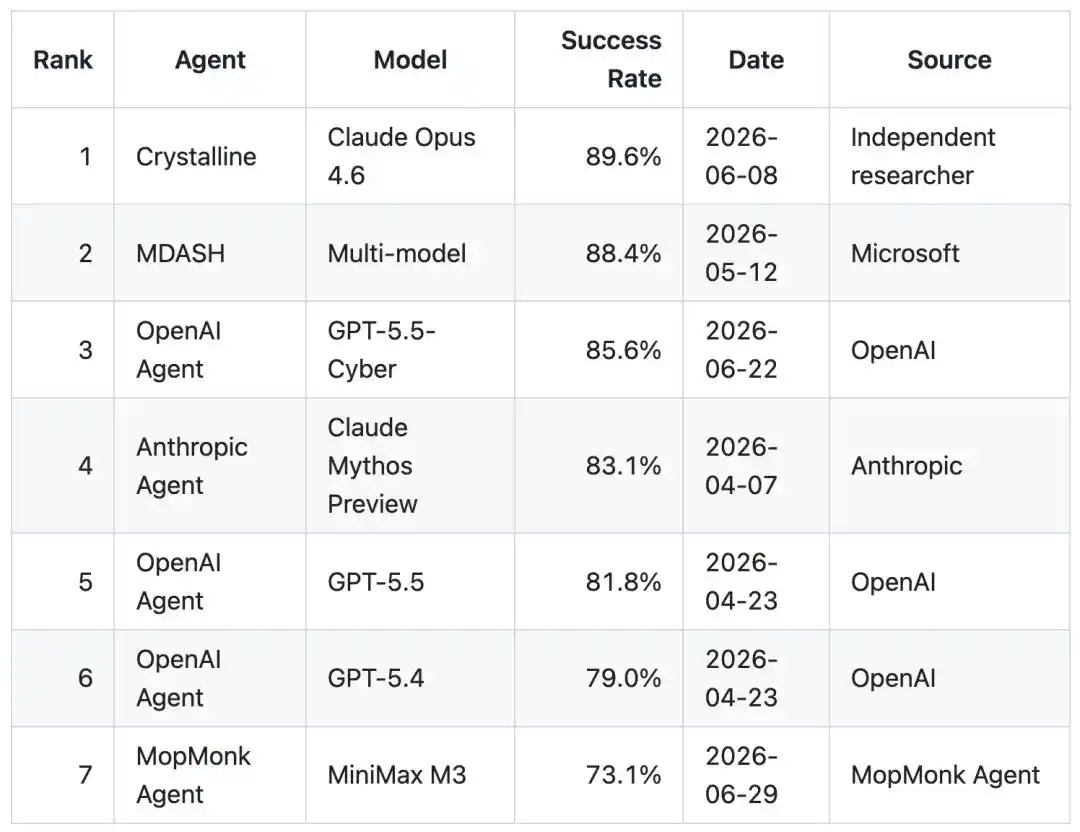
Mysterious Codename: MopMonk (Sweeping Monk)
Base Model: MiniMax M3
Leaderboard Record: Broke into CyberGym global top seven, China's number one
Normally, a team achieving such results should have already flooded the scene with technical reports and press conferences.
Yet, on this leaderboard teeming with masters, MopMonk is precisely that ultimate "outsider": It only tossed out a technical report, with its team, company, and location remaining complete unknowns.
This collision of "top-tier capability, information nakedness" itself is filled with a dramatic flair reminiscent of Eastern martial arts novels.
Those familiar with Jin Yong understand the weight carried by the three characters "Sweeping Monk" in "Demi-Gods and Semi-Devils"—
That old monk who swept floors for decades in the Shaolin Library, whose name no one remembered, yet with one move subdued the two great masters, Xiao Yuanshan and Murong Bo.
The most inconspicuous character, harboring the deepest skills.

Daring to challenge the arena under the banner of "Sweeping Monk," this team clearly has extremely cold confidence in its own strength!
A more crucial clue is hidden in its technical foundation—the base chosen by MopMonk is MiniMax M3.
As an open-source base originating from Shanghai, M3 can be called an all-round warrior, directly integrating three core capabilities: cutting-edge programming ability, a 1M ultra-long context window, and native multimodality.
On one side, an "Eastern cultural symbol" full of flavor; on the other, a technological base bearing a purely domestic label.
Placing these two clues on the table narrows the circle considerably. All the traces are frantically hinting at the same conclusion:
This is most likely a Chinese team.
The Deciding Factor Lies in the Harness
Putting aside the identity mystery, as those who have been long tracking AI technology, we want to figure out one question even more:
Why did MopMonk win?
To answer this, we must first return to CyberGym's hardest core—it doesn't test "whether you know," but "whether you can do."
Judging whether a piece of code has a vulnerability isn't too difficult for today's large models.
But CyberGym tests the next step, the deadliest step: generating an input that can trigger the vulnerability, i.e., a PoC.
It must trigger on the "vulnerable version," fail on the "patched version," and pass the execution verification in the benchmark environment.
This hurdle is far more tricky than imagined.
The trigger conditions for a vulnerability are often scattered among code paths, parsing logic, build environments, test harnesses, and input formats, requiring piece-by-piece assembly.
Even more troublesome, even if the PoC crashes the program locally, it might not count. As long as it doesn't satisfy the differential judgment of "triggers on vulnerable version, does not trigger on patched version," it's all wasted effort.
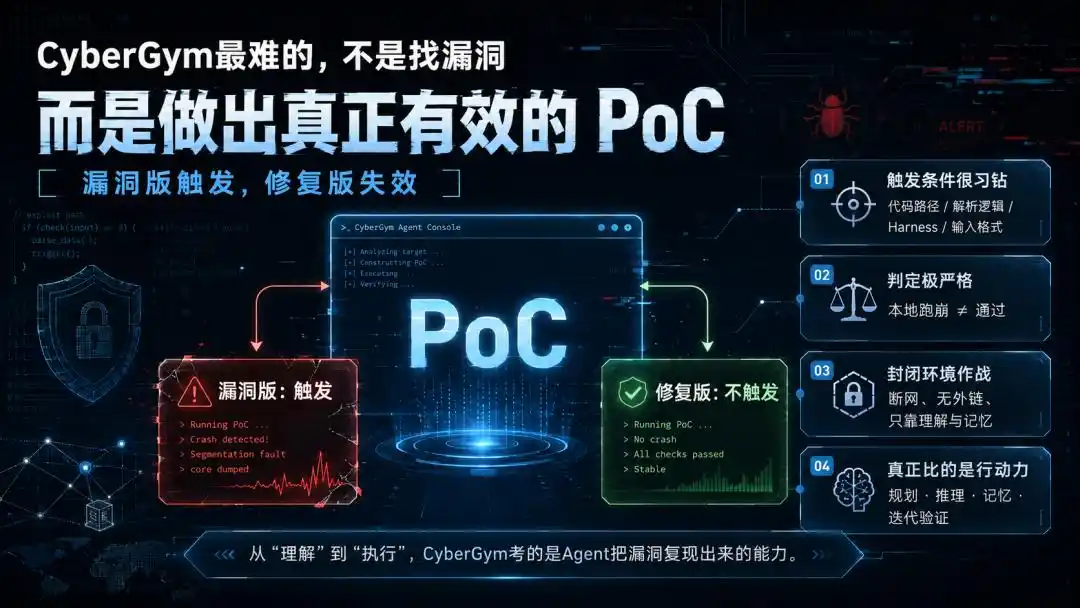
This step pulls the task completely from "understanding" into "execution." And a very specific kind of execution—
The entire exam takes place in a closed, offline environment.
No external search for help, no "outside resources" whatsoever. The AI can rely only on its understanding of the codebase before it and the memories it has accumulated step by step.
To "reproduce" a vulnerability under such conditions depends on a whole set of interlocking abilities:
Tool-calling planning: When to read files, when to run tests, when to go back and revise the plan;
Multi-round reasoning: The last attempt didn't trigger, what exactly was the problem, how to adjust next time;
Memory management: Structurally storing read code, tried inputs, and encountered pitfalls, rather than rereading everything from scratch each round;
Iterative verification: Repeatedly approaching that critical point until the vulnerability is truly reproduced.
In other words, the core of CyberGym competition is the Agent's "execution capability"; the model's "intelligence" is just the entry ticket.
And the key link that transforms "smartness" into "execution capability" is today's most underestimated term in the entire Agent field—Harness.
Harness is the "coordination layer" between the model and external tools, the execution environment.
It is responsible for tool orchestration, context state management, collection and re-feeding of execution feedback.
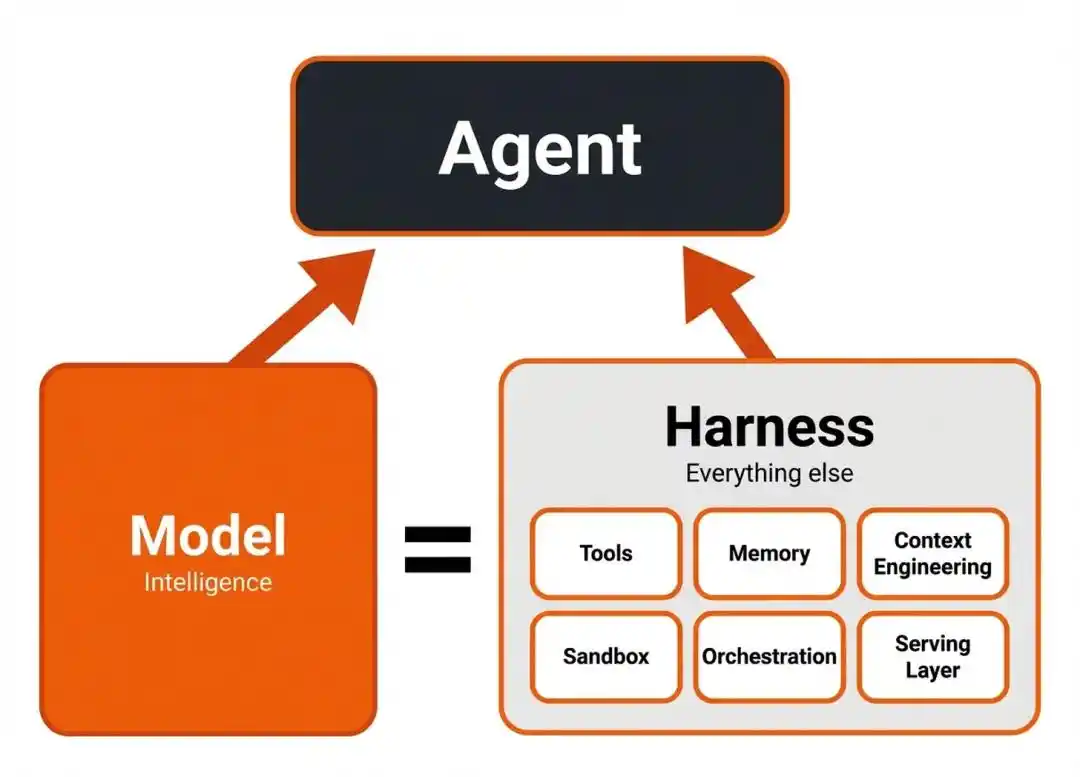
Simply put, the model is the brain, responsible for thinking "where the vulnerability might be, how to dig next."
The Harness is the limbs plus nervous system, responsible for turning the brain's thoughts into a series of real actions—
Which file to open, which command to run, how to adjust after getting an error, how to change the approach after a failed round.
On tasks like CyberGym, which require running dozens or hundreds of rounds and repeatedly trial-and-error within millions of lines of code, the quality of the Harness directly determines how much of the model's intelligence can be converted into combat effectiveness.
A smart model + a mediocre Harness often results in "can think of it, but can't do it";
A capable model + a strong Harness tailored for vulnerability mining is what can potentially achieve results in such long-range tasks.
An Agent "Tailor-Made" for Vulnerability Mining
Now, through the GitHub technical report, MopMonk's technical outline has become clear:
A security multi-Agent system newly designed specifically for vulnerability mining, powered by the thinking base MiniMax M3.

GitHub Address: https://github.com/MopMonkAI/MopMonkAgent
As mentioned, M3 is a rare open-source model today that integrates top-tier coding capability, a million-token context window, and native multimodality within a single architecture.
A glance at its benchmarks makes it clear: SWE-Bench Pro achieved 59.0%, Terminal-Bench 2.1 reached 66.0%, MCP Atlas scored 74.2%—
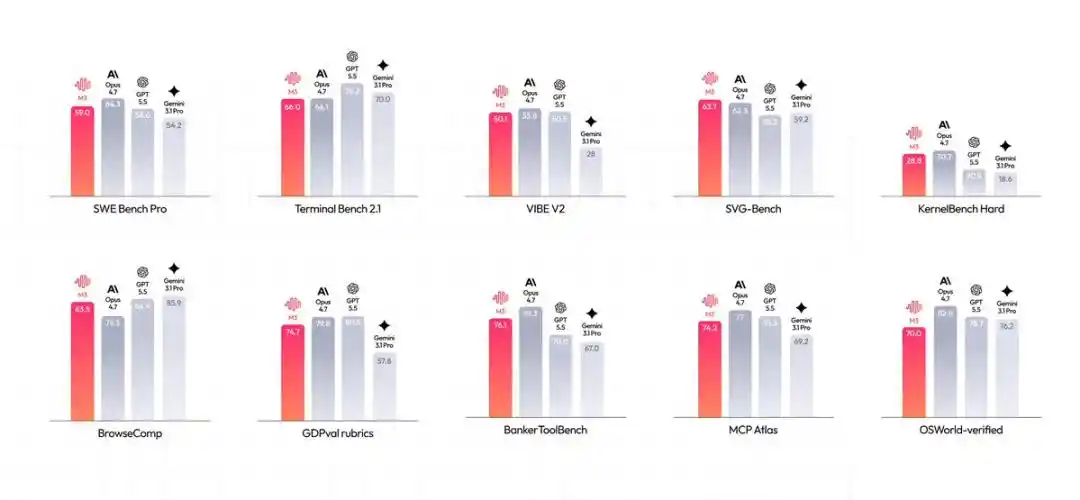
These impressive numbers precisely meet the most hardcore capability needs for Agent deployment in real-world scenarios.
Not only that, it can also autonomously iterate and self-correct over tasks lasting more than ten hours.
In other words, M3 plays the role of a "super brain" combining top-tier code parsing ability, ultra-long memory, and proficient tool-calling skills.
For tasks like CyberGym that often require swallowing an entire codebase and running dozens of rounds, a 1M context window is almost a necessity.
What MopMonk's security Agent framework does is amplify M3's brainpower into execution capability for vulnerability mining.
Its "core techniques," as seen from the technical details publicly available on GitHub, revolve around three key moves—
First move, structured "Vulnerability Memory."
It's not simply stacking chat history, nor is it dumping the ultra-long context wholesale into the model. Instead, it organizes a continuously updatable "Task Fact Memory" around the most critical types of objects in vulnerability mining:
Vulnerability target, code paths, input formats, candidate PoCs, failure evidence, verification status, and "Next Step Constraint" memory.
The last category especially shows skill: It doesn't generate vague abstract plans but directly extracts hard constraints that the next experiment must satisfy from the current evidence.
For example, "This time must cover that branch," "Which field to adjust," "Which type of failure cause to exclude."
This memory design transforms vulnerability mining from "repeated trial-and-error from scratch" into "an evidence-based convergence process."
Each code read, each execution result, each failed submission is converted into reusable constraints for the next PoC generation.

Second move, Memory-driven "Vulnerability Mining."
In vulnerability mining tasks, the system first initializes the vulnerability memory by scanning the codebase and using candidate trigger paths and directory information as planning starting points.
Then, it advances step by step, attempting to converge on the specific code location that triggers the crash.
Afterward, each exploration attempt reads the current memory, tests a specific hypothesis, and writes the results back into memory.
Thus, the model doesn't have to reread the entire task from the beginning each round. Instead, it precisely retrieves the most relevant piece of evidence from this structured memory—
This drastically reduces the burden of long context while allowing each mutation of a candidate PoC to inherit the previously accumulated knowledge of code paths and input formats, making the search increasingly accurate.
Within strict exploration budgets, time is therefore spent as much as possible on "new hypotheses," dramatically increasing the density of effective trials.
Third move, "Multi-Agent Parallel Exploration" under Shared Memory.
Multiple exploration attempts share the same vulnerability memory. They can advance simultaneously from multiple directions such as patch clues, harness entry points, file format fields, sanitizer types, boundary conditions, etc., inheriting each other's failure experiences and verification results.
This expands coverage while avoiding repetitive, ineffective exploration.
From this, it's evident that MopMonk has rewritten vulnerability reproduction from an open-ended trial-and-error process into a "accumulable, constrainable, verifiable" memory update process.
Combining all three moves, relying entirely on "internal skills" that precipitate, refine, and reuse bit by bit within the task, it forcefully dispatches a powerful open-source base into a special forces soldier on the vulnerability mining battlefield.
Ultimately, it achieved a 73.1% success rate.
The base is responsible for "thinking deeply," the Harness is responsible for "remembering solidly, tuning accurately, striking steadily."
The deep coupling of both ultimately forged that eye-catching breakthrough achievement on the leaderboard.
A Judgment More Valuable Than "Stacking Parameters"
The real inspiration of this matter lies in—
In recent years, the industry's inertia has been "stacking parameters": the larger the parameters, the stronger the model, the higher the leaderboard ranking.
But real-world attack/defense tasks like CyberGym offer another answer: increasingly, the deciding factor is the Agent's execution capability, the engineering depth of the Harness layer.
According to the GitHub technical report, the value of this approach lies in three points:
Powerful base model capabilities provide the foundation for the search;
Structured vulnerability memory provides the mechanism for convergence;
Multi-agent exploration with shared memory improves cost-effectiveness within limited budgets.
The base determines the upper limit of capability, while this memory-centric Harness determines how much of that capability can be actualized.
More critically is its compounding nature:
Model bases will be swapped generation after generation; using M3 today, possibly newer open-source models tomorrow.
But a Harness repeatedly tempered on real battlefields, accumulating attack/defense experience, is an asset that can compound continuously, transcending base model iterations.
In short, the long-term value of the MopMonk Harness might be greater than "stacking another doubling of parameters."
This is precisely the fundamental reason the industry is starting to seriously examine this mysterious "Sweeping Monk":
What people want to see isn't just its score, but that it demonstrates a path to maximizing open-source base models.
So, who exactly is the "Sweeping Monk"?
After circling around, we return to that initial, most tantalizing question.
MopMonk, who are you?!
Piecing the clues together: an Eastern martial arts-flavored codename + a base from Shanghai's MiniMax + a body of "internal skills" in the security field.
Almost all arrows point to the same judgment: This is an AI security company from China, most likely based in Shanghai.
Some, considering the two-way adaptation between the base model and the Agent, blindly speculate that its background is inseparable from the native AI large model team.
Various versions of guesses are circulating wildly, but no one has been able to produce hard evidence so far.
Who do you think MopMonk is? The master of which house? The comment section awaits your inside scoop.
This article is from the WeChat public account "New Zhiyuan", author: ASI Apocalypse