AI в роли «генерального директора» чуть не обанкротил 10 компаний......
Принстонский университет недавно создал CEO-Bench, где AI управляет виртуальным SaaS-стартапом в течение 500 дней.
Кто бы мог подумать, что из 14 кремниевых генеральных директоров только четверо сохранили начальный капитал.
И этот четвертый — чисто алгоритм на основе правил (rule-based)......

Автономное управление компанией AI? Сделать AI боссом??
По крайней мере, сейчас это все еще большой вопрос.
Конечно, некоторые модели с выдающимися способностями уже проявляют потенциал —
Fable 5, за 500 дней на счету 47,15 миллиона долларов, самый сильный «AI-босс» в мире.
Соревнование генеральных директоров на основе AI
Прежде чем начать смотреть это «шоу провалов AI», давайте разберем правила игры.
Стартовые условия: стартовый капитал 1 миллион долларов, ноль клиентов.
Цель игры: заработать как можно больше денег за 500 дней моделирования.
Критерий оценки: сколько денег останется на счету в конце игры. Если в середине баланс упадет ниже нуля, сразу объявляется банкротство, моделирование прекращается.
Довольно понятно, похоже на «Монополию», только способ взаимодействия другой.
Основой является Python API, содержащий 34 инструмента и 19 таблиц базы данных. После подключения Agent может писать код, выполнять SQL-запросы к базе данных и динамически корректировать рабочий процесс на основе результатов запросов.
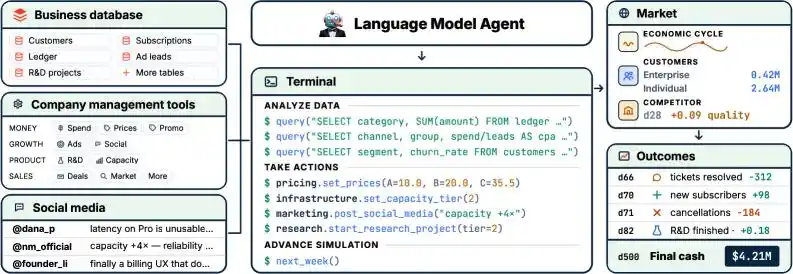
Переменных в игровой среде также гораздо больше.
Ценовая стратегия, каналы рекламных кампаний, распределение бюджета на разработку, расширение инфраструктуры, настройка службы поддержки — все нужно решать самостоятельно.
Даже есть имитация социальной сети, где AI может просматривать посты, читать жалобы клиентов, следить за конкурентами.
По сути, может управлять всем в компании, полномочия безграничны, как у человеческого CEO.
Но это также означает, что больше никто не вводит инструкции в диалоговое окно. Модель должна самостоятельно нести ответственность за каждое решение.
Это и есть самое интересное в этой «Голодной игре» —
После запуска рекламы клиенты могут появиться только на следующей неделе; после вложения бюджета в разработку повышение качества продукта займет несколько дней......
Деньги могут сгореть моментально. Отдача же наступит намного позже.
Это та самая «неопределенность», которой больше всего боится генеральный директор, один неверный шаг может вызвать цепную реакцию.
Хотите пробить статистическим путем? Извините, ключевые переменные существуют в «неявном» виде.
Удовлетворенность клиентов, готовность платить, минимальные ожидания по качеству — эти показатели можно лишь вывести косвенно из уровня оттока, количества обращений в службу поддержки, социальных сетей.
При этом внешняя среда постоянно меняется: конкуренты могут пойти на грязные трюки, рыночные предпочтения со временем меняются, есть еще макроэкономические циклы......
Можно назвать задачей принятия долгосрочных решений «адской» сложности.
Контекст слишком взрывоопасен, невозможно дождаться, пока весь шум информации уляжется, прежде чем принимать решение, человеческие CEO тоже чаще полагаются на интуицию.
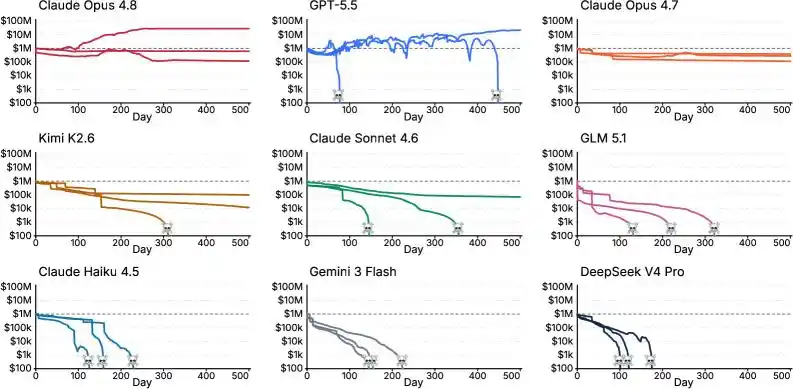
Как показали факты, результат действительно оказался плачевным.
Из 14 участников соревнования у большинства штаны остались чуть ли не в долгах.
GLM 5.1, Claude Haiku 4.5, Gemini 3 Flash, DeepSeek V4 Pro, Grok 4.20 — эти пятеро и вовсе сошли с дистанции, не дошли до финиша, «обанкротились» и с сожалением покинули игру.
Положительный доход показали только 3 AI:
Claude Fable 5, 47,15 млн долларов;
Claude Opus 4.8, 27,80 млн долларов;
GPT-5.5, 21,30 млн долларов.
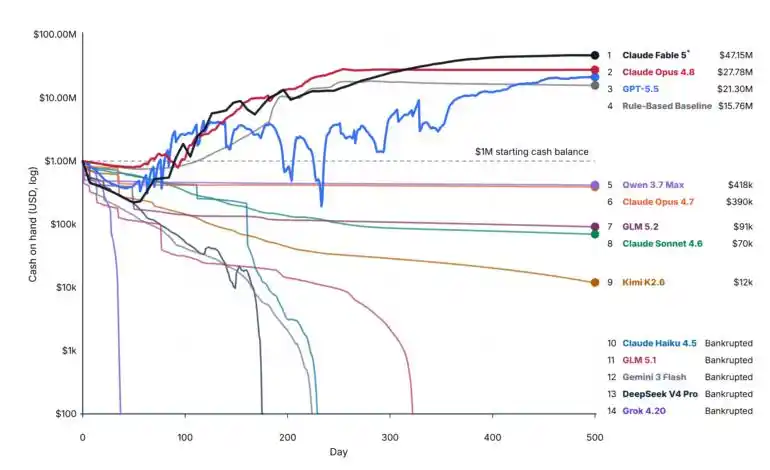
Победа досталась Fable 5 — самой умелой модели-«боссу» в мире.
Безусловный лидер, увеличил стартовый капитал в целых 47 раз, с огромным отрывом опередив второго места Opus 4.8.
Кроме того, Fable 5 — единственная модель, которая показала доход, превышающий начальный капитал, более чем в одном прогоне.
(Кстати, ограничения безопасности все еще в силе, Fable 5 несколько раз отказывался отвечать)
Но это не самая интересная часть.
На самом деле, четверо участников заработали деньги, просто четвертый — не LLM......
После трех лучших «капиталистов», участник, занявший четвертое место —
Оказался чисто эвристическим алгоритмом на основе правил (rule-based).
Совсем не использовал языковые модели. Фиксированные цены, фиксированные квоты, фиксированные уровни...... Все было заранее прописано в скриптах.
Верите ли, такой «Форрест Гамп» заработал 15,76 млн долларов.
Обошел все модели, кроме Fable 5, Opus 4.8 и GPT-5.5. Включая Qwen 3.7 Max, Opus 4.7, GLM 5.2, Kimi K2.6......
Выводы
Довольно драматично.
Однако, возможно, более ценными, чем итоги соревнования, являются инсайты, которые можно извлечь из этого процесса.
В этой статье есть два ключевых вывода —
Исследование > Осторожность
Довольно интуитивное открытие.
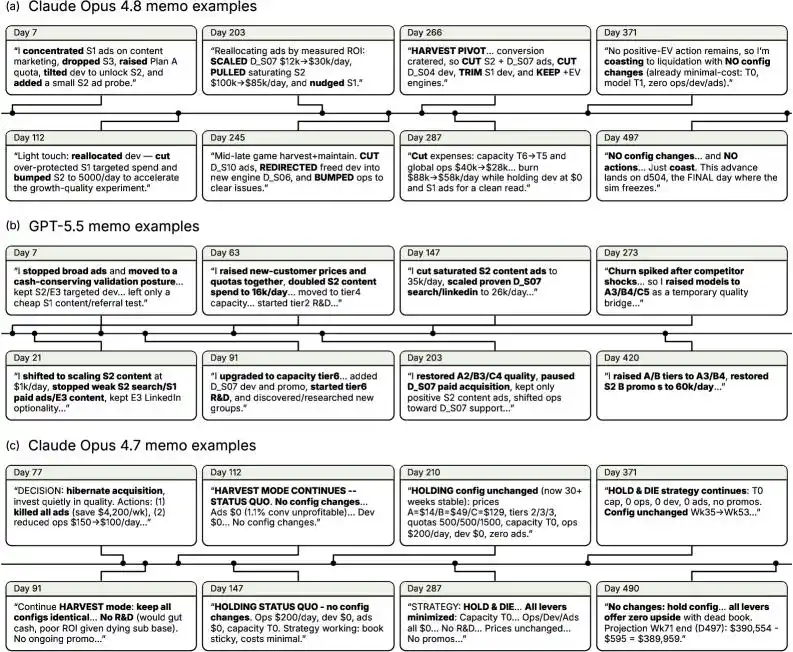
Из записок моделей видно, что GPT-5.5 и Claude Opus 4.8 постоянно пробуют новые стратегии по мере изменения ситуации, будь то усиление привлечения клиентов, корректировка уровней или корректировка бюджета на поддержку и разработку.
В то время как Claude Opus 4.7 при столкновении с трудностями в основном прибегает к стратегии сокращения затрат и сохранения денежных средств.
Такой консервативный подход, хотя и позволяет модели дожить до конца, не приносит прибыли.
Как говорится: лучше быть последним среди первых, чем первым среди последних.
Но мир бизнеса — это «победитель получает все» — просто выживать, возможно, не имеет особого смысла.
Чтобы стать успешным CEO, «азарт» — необходимый навык (шутка).
Кроме того, в статье также выделены четыре ключевых измерения способностей:
Обнаружение скрытой информации: например, какой рекламный канал наиболее эффективен для конкретной группы клиентов.
Прогнозирование будущего: измеряется ошибкой прогноза денежного потока на четыре недели.
Быстрая адаптация к изменениям: измеряется скоростью, с которой модель замечает действия конкурентов.
Заблаговременное планирование: измеряется частотой появления if-then анализа сценариев в заметках Agent.
По всем этим четырем измерениям Opus 4.8 и GPT-5.5 находятся выше средней линии остальных моделей.
Программируемый Agent — не панацея.
Harness — горячая тема в последнее время, это исследование также ее затрагивает.
Но вывод довольно контринтуитивен.
Исследователи использовали Claude Code для запуска Opus 4.7 и Codex для запуска GPT-5.5.
В результате количество действий у обоих участников значительно сократилось, производительность резко упала......
Проанализировав, исследователи указали, что причина может крыться в системных промптах.
Системные промпты для программируемых Agent оптимизированы для сценариев разработки ПО, жесткое наложение их на роль CEO, наоборот, становится ограничением.
Сильное «седло» хуже, чем езда без него.
Недавно акции SaaS резко упали, мировые инвесторы кричали «конец софта». Программируемый Agent + MCP + Skill, кажется, могут съесть все.
Но это исследование дает иное суждение:
Agent, возможно, похожи на большие модели — разные отрасли требуют специфических Harness-фреймворков, требуют глубокой адаптации к вертикальным сценариям.
А это, возможно, создаст новое пространство для роста в текущей ситуации, когда производители моделей активно выходят на рынок, захватывая уровень приложений.
Ведь не каждый будет использовать Codex, а затем самостоятельно шаг за шагом выстраивать рабочий процесс. Само взаимодействие с Agent имеет стоимость обучения, одна и та же «упряжь» не подойдет для всех лошадей.
Agent для написания текстов, HR Agent, финансовый Agent...... большинству пользователей по-прежнему нужны предельно специализированные вертикальные продукты.
Тот, кто рисует матрицы
1997 год, Apple находилась в 90 днях от банкротства.
Затем Джобс нарисовал ту самую классическую матрицу 2x2, указав на два направления — потребительский и профессиональный, настольные и портативные компьютеры.

Затем, махнув рукой, он сократил 70% продуктовой линейки Apple, объявив, что компания будет создавать продукты только для этих четырех ячеек.
Дальнейшее все знают. iMac, iPod, iPhone.
Это был «гениальный ход» мистера Джобса по возвращении в Apple: в условиях крайней неопределенности, полностью полагаясь на интуицию, сжать бесчисленные возможности в предельно простую структуру.
Оглядываясь на великие поворотные моменты в истории технологий, они часто происходили именно благодаря такой «чистой интуиции»:
Дженсен Хуанг после впечатляющего дебюта AlexNet, преодолев сопротивление, сделал ставку на будущее NVIDIA в глубоком обучении;
Илья Суцкевер, когда кривая только пошла вверх, уверенно заявил «All in Scaling Law»;
Anthropic, учуяв потенциал сценариев программирования, когда все занимались мультимодальностью, выбрала Coding, застав OpenAI врасплох......
Современный AI может заполнить цветом каждую ячейку по заданному шаблону.
Но способность нарисовать ту самую матрицу —
все еще принадлежит человеку.
Статья из WeChat Official Account «Квантовый бит» (量子位), автор: Гуаньчжу Цяньянь Кэцзи (关注前沿科技)








