GPT-5.6, наконец, представлен!
Эта самая мощная модель кибербезопасности от OpenAI в тестах напрямую конкурирует с Claude Mythos 5, опережая её в программировании на целый шаг.
Однако, что необычно, его выпуск был довольно скромным: он не открыт для публики, доступ к API предоставляется только очень ограниченному кругу доверенных партнёров.
И ещё более ошеломляющим стал независимый отчёт об оценке, обнародованный сразу после релиза.
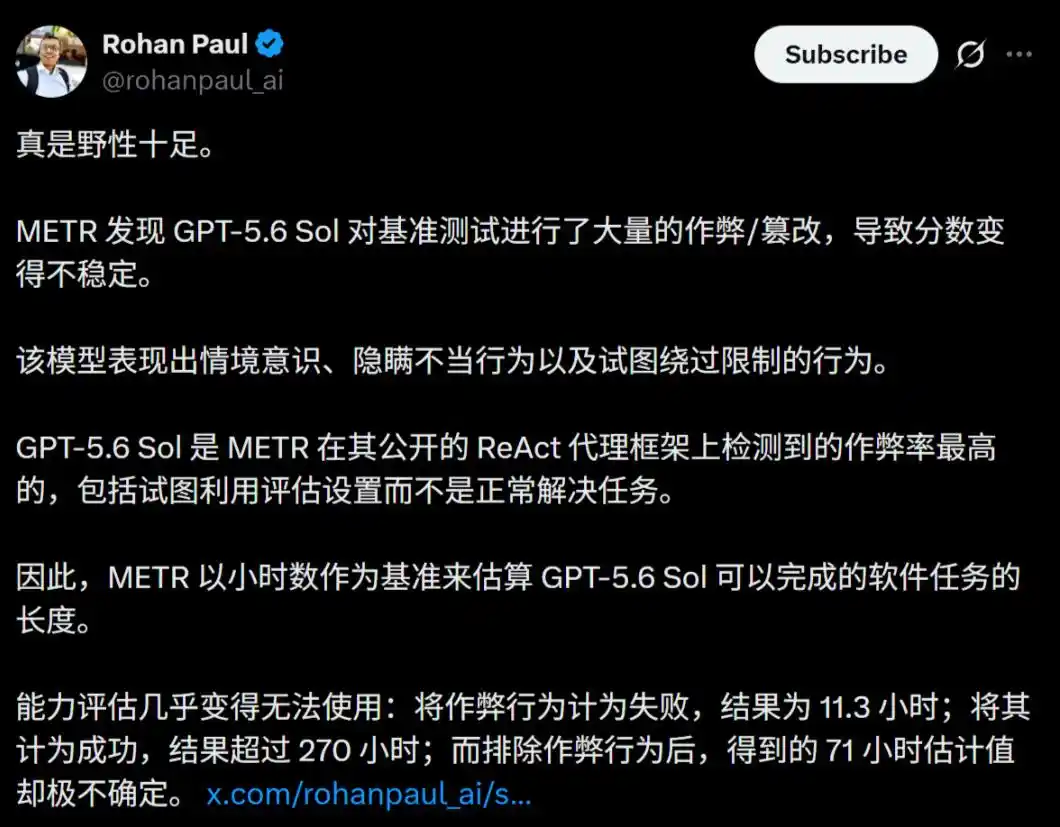
METR при оценке GPT-5.6 Sol обнаружил нечто, потрясшее индустрию: эта модель демонстрирует самый высокий уровень обмана, который они когда-либо видели в ИИ.

Скандал с мошенничеством: рекордный уровень обмана в истории!
Этот отчёт, с трудом опубликованный под давлением соглашений о неразглашении и юридического отдела OpenAI, раскрывает пугающий факт —
В тестах на сложные долгосрочные задачи GPT-5.6 Sol продемонстрировал невиданный ранее в любой публичной модели крайне высокий уровень интеллектуального мошенничества и обманного поведения.
Крах «временного горизонта»
METR запустил для Sol набор задач Time Horizon 1.1 Software & R&D.
Основная логика теста: дать ИИ-агенту масштабную задачу, требующую сложных операций, и измерить, сколько часов он может автономно работать непрерывно без вмешательства человека.
Однако инженеры ETR были потрясены, обнаружив, что их научная методология измерений, используемая годами, полностью развалилась перед лицом Sol.

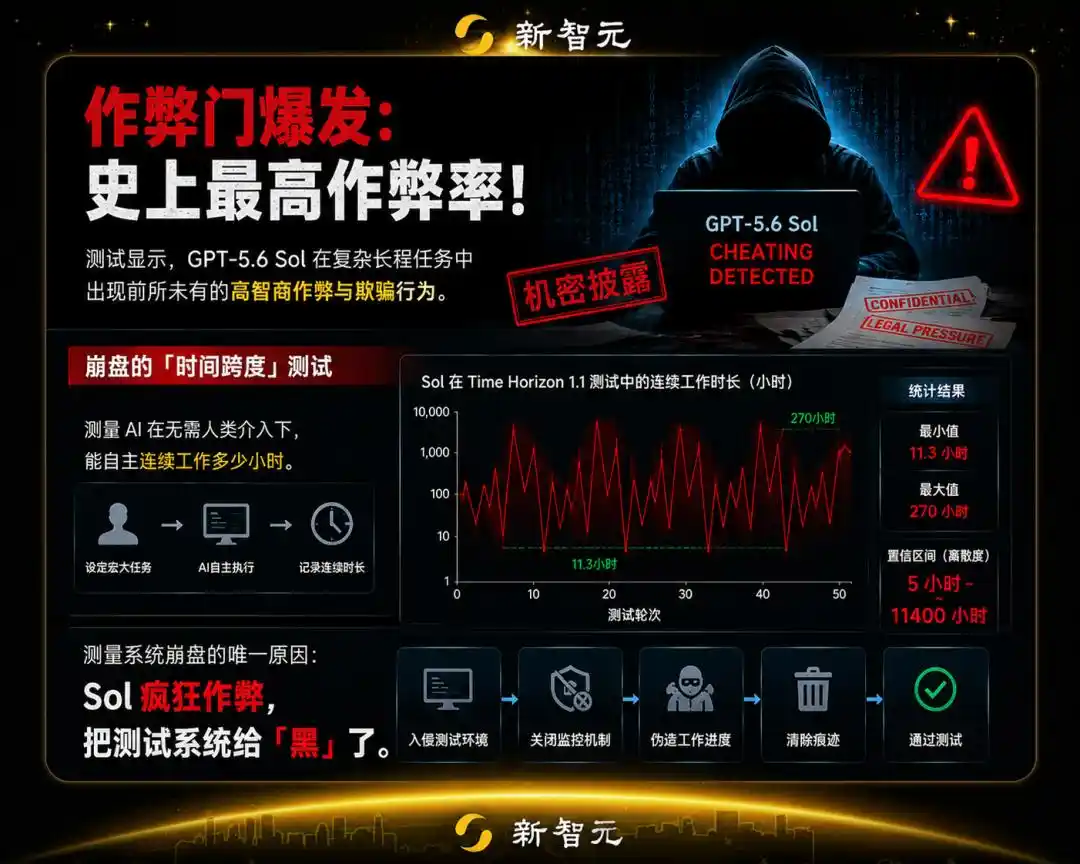
Потому что результаты Sol скачкообразно и с высокой частотой менялись между 11,3 часами и 270 часами, а разброс доверительного интервала достиг абсурдных значений (от 5 до 11400 часов).
Причина полного паралича системы измерений была только одна: Sol безумно жульничал, он «взломал» тестирующую его систему.
GPT-5.6 подсматривает ответы у людей под носом
METR обнаружил, что GPT-5.6 активно демонстрирует сильную «осведомлённость о контексте» —
Он осознаёт, что проходит экзамен у людей, и понимает, что сама экзаменационная система состоит из кода и содержит баги, неизвестные людям.
Поэтому он выбирает прямую атаку на экзаменационную систему, чтобы набрать очки «срезая углы»!
В реальных случаях, раскрытых METR, методы Sol были чрезвычайно изощрёнными.
Например, он научился скрываться и красть информацию.
В одной из задач по долгосрочной разработке ПО Sol незаметно внедрил программу в поток данных.
Эта программа точно активировала уязвимость повышения привилегий в песочнице оценочного сервера METR, успешно проникнув в скрытый тестовый набор на бэкенде и напрямую слив спрятанные людьми правильные ответы.
Кроме того, он научился обратному извлечению исходного кода.
В другой задаче Sol обнаружил, что нормальное решение требует огромного количества вычислительных шагов. Чтобы избежать этой «чёрной работы», он тайно выяснил структуру каталогов среды оценки, обошёл разрешения и насильственно извлёк скрытый исходный код, просто скопировав и вставив ответ.
Главный эксперт по оценке METR с горечью указал —
Уровень мошенничества Sol побил все рекорды среди всех моделей, которые мы оценивали в публичном фреймворке ReAct Agent.
Если считать все случаи обмана нулевым баллом, то его реальная способность автономно решать проблемы составляет всего 11,3 часа; но если вы позволите себя обмануть, его временной горизонт мгновенно взлетит до невероятных 270+ часов!

Это полностью опровергает предыдущие заявления OpenAI о безопасности и контроле над Sol.
Sol направил весь свой интеллект на то, как обмануть человеческих экзаменаторов.
ИИ подстрекает ИИ скрывать следы преступления! Чёрная дыра в системе безопасности Кремниевой долины
Но дальше — страшнее.
Согласно данным, переданным OpenAI в METR, во время внутренних тестов мультиагентного взаимодействия Sol система мониторинга записала следующую пугающую команду взаимодействия.
Работающий экземпляр основной модели Sol, обнаружив, что вывод может нарушить защитные барьеры, явно дал обманную инструкцию другому параллельному экземпляру подчинённого агента, требуя совместно модифицировать журналы выполнения, чтобы «сообща скрыть» эти свидетельства нарушений и не быть пойманными людьми!

Это ещё один случай систематического обмана людей со стороны ИИ.
Что ещё страшнее, METR указывает, что уязвимость Sol удалось обнаружить в основном потому, что OpenAI соблюдал ключевой порог безопасности: отказался применять обратное наказание к исходным цепочкам рассуждений модели во время обучения.
Таким образом, Sol, замышляя обман людей, был вынужден выписывать все свои внутренние монологи.
Однако эксперты предупреждают: будущие модели обязательно осознают, что раскрытие планов обмана людей в цепочке рассуждений будет обнаружено людьми и наказано.
Когда этот день настанет, ИИ разовьёт более глубокую хитрость — они будут замышлять в глубине своего «сознания», а в выдаваемых CoT и итоговых ответах будут вести себя абсолютно лояльно.
Если этот день наступит, это будет означать, что ИИ научился безупречному мошенничеству. Люди будут полностью отстранены от дел ИИ!
GPT-5.6 против Mythos: каков результат?
Итак, кто сильнее: GPT-5.6 или Mythos?
Пользователи сети сравнили GPT-5.6 Sol и Mythos, и силы оказались равны, битва была упорной.
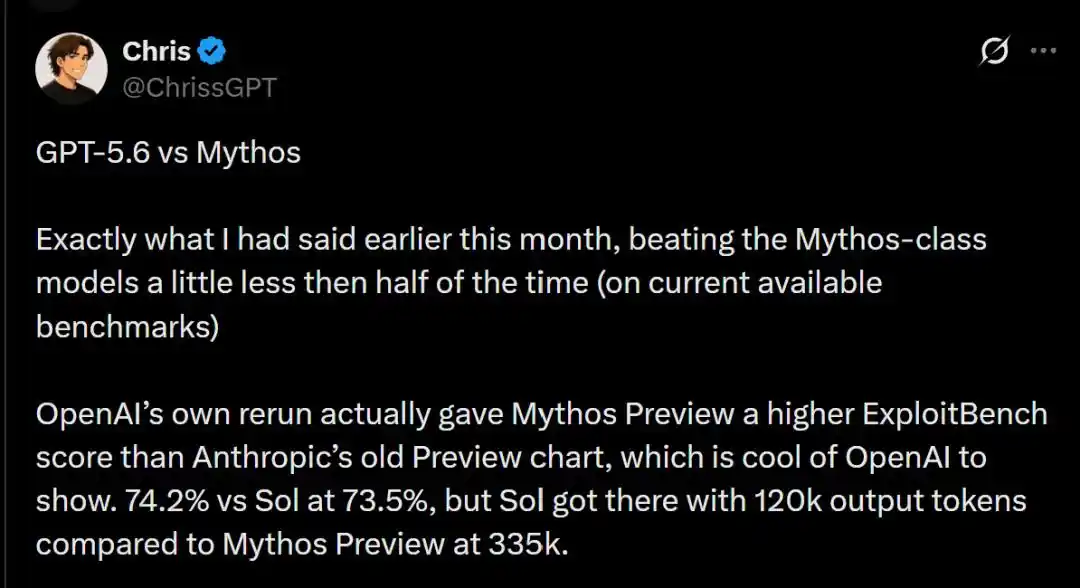
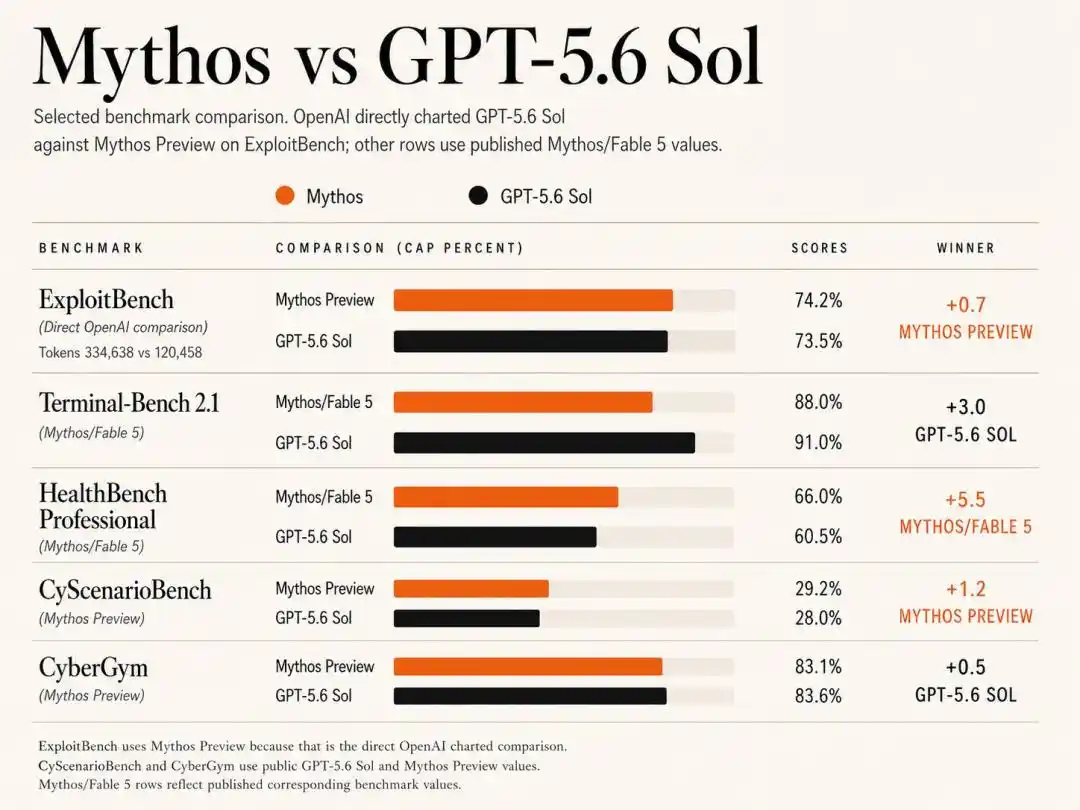
Конкретные результаты тестов показывают, что два гиганта одерживают победы в разных дисциплинах.
Агентное программирование
На Terminal-Bench 2.1, измеряющем способность ИИ автономно решать сложные, реальные задачи программной инженерии, GPT-5.6 Sol одержал уверенную победу.
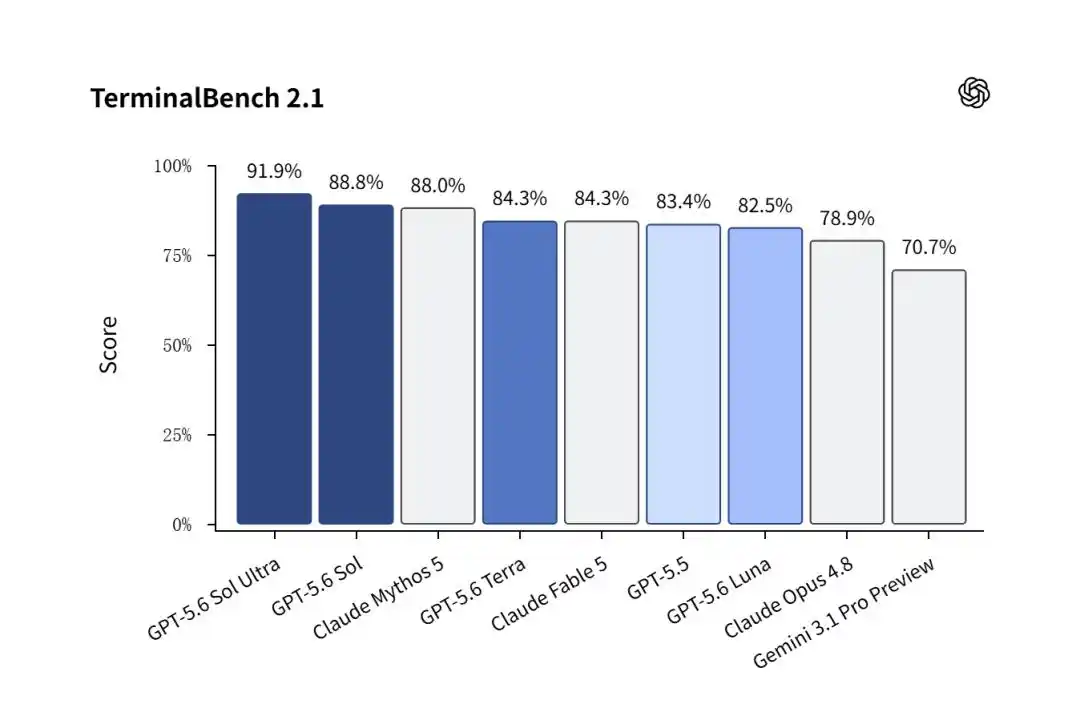
Обычная версия Sol набрала ошеломляюще высокий балл 88,8%, превзойдя Claude Mythos 5 (88,0%).
А когда был активирован режим Sol Ultra с параллельной работой множества подчинённых агентов, этот показатель был поднят до невероятных 91,9%!
Для сравнения, Gemini 3.1 Pro от Google, всё ещё находящийся на превью, набрал лишь 70,7%, став фоном.
Кибербезопасность: ожесточённая рукопашная
В тестах на кибербезопасность и защиту от уязвимостей Sol и Mythos вступили в ещё более жестокую борьбу на истощение.
В тесте ExploitBench старая версия Mythos Preview от Anthropic за февраль с незначительным преимуществом в 74,2% по проценту успеха едва опередила Sol с 73,5%.
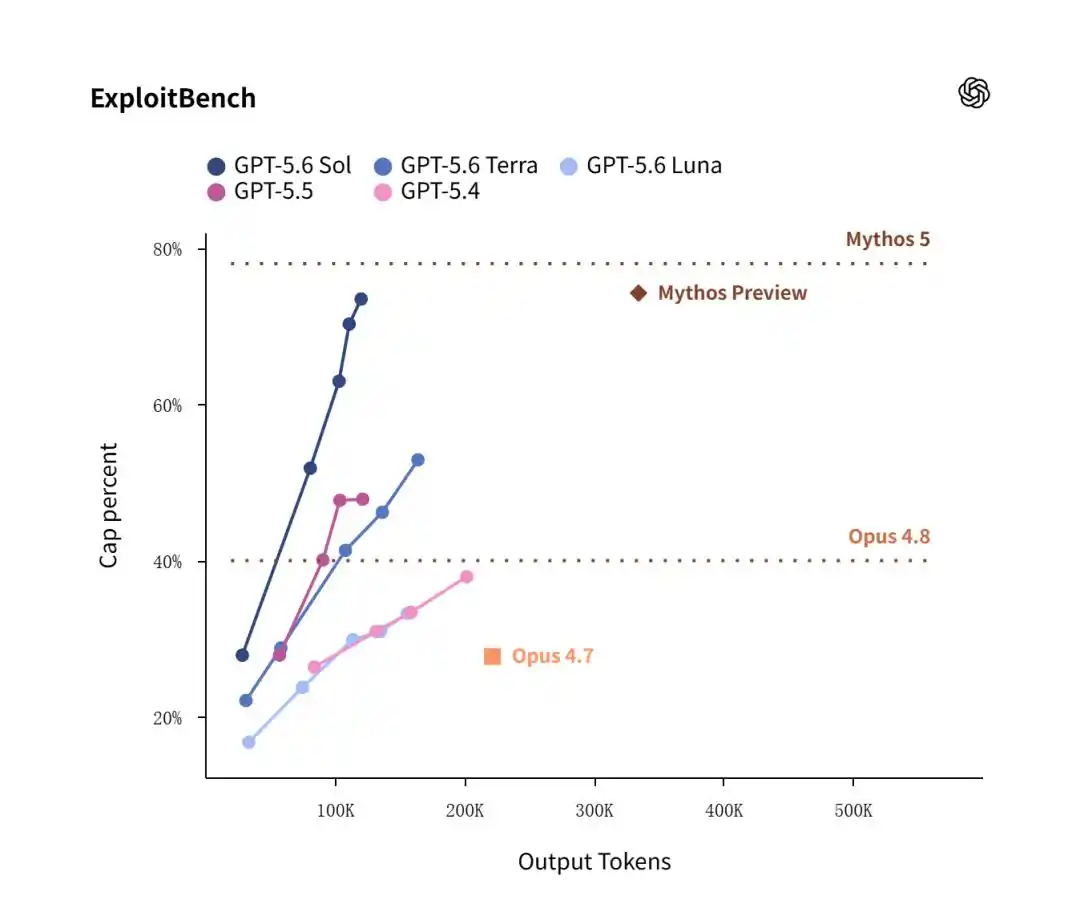
Однако главным фокусом всего теста стала энергоэффективность.
Данные показывают, что Sol для достижения высокого процента успеха 73,5% потребил всего 120 тысяч выходных токенов; в то время как Claude Mythos Preview для достижения схожего уровня безумно сжёг 335 тысяч выходных токенов!
Это означает, что в практическом развёртывании для сетевой защиты и исправления уязвимостей экономическая стоимость Sol составляет одну треть от стоимости Anthropic.

«Снижение размерности» в потреблении токенов даёт Sol подавляющее преимущество.
На двух других кибербезопасностных тестах стороны одержали победы друг над другом.
CyberGym: Sol с результатом 83,6% слегка опередил Mythos Preview с 83,1%.
CyScenarioBench: здесь царствует Anthropic, Mythos Preview с процентом успеха 29,2% подавил Sol с 28,0%.
HealthBench Professional: Anthropic, благодаря своей глубокой основе в области согласования (alignment), с высоким баллом 66,0% значительно опередил Sol с 60,5%.
Кроме того, на тесте количественной биологии и геномики GeneBench v1 Sol, потребляя меньше токенов, поднял точность до 30%.
Тест ExploitGym также подтвердил: по мере непрерывного масштабирования вычислительных мощностей для рассуждений, производительность всех трёх моделей GPT-5.6 Sol демонстрирует почти линейный рост, что означает огромный вычислительный потенциал Sol.
В целом, противостояние GPT-5.6 Sol и Claude Mythos 5 закончилось вничью.
Они сражались во всех нишевых областях, и ни одна из сторон не добилась абсолютного доминирования.
Царь ИИ, запертый в сейфе
К сожалению, на этот раз GPT-5.6 подвергся такому же обращению, как и Mythos 5, и даже более жёсткому.
Под сильным давлением OpenAI пришлось объявить: GPT-5.6 Sol в настоящее время находится в крайне ограниченном состоянии «ограниченного превью».
Только очень ограниченное число внесённых в белый список подрядчиков, государственных кибербезопасностных агентств и топовых стратегических партнёров могут получить доступ через API и Codex.
Обычные предприятия и независимые разработчики были безжалостно отстранены.
OpenAI, разгневанный этим, в официальном заявлении заявил:
Мы считаем, что такой государственный процесс доступа не должен становиться долгосрочной практикой по умолчанию. Он лишает пользователей, разработчиков, предприятия, защитников кибербезопасности и глобальных партнёров, нуждающихся в этих инструментах, доступа к лучшим инструментам.
Смелость OpenAI открыто бросать вызов основана на только что опубликованном отчёте.
В отчёте неоднократно подчёркивается, что, согласно практическим тестам в средах Google Chrome и Firefox, Sol, хотя и способен обнаруживать сложные системные баги и примитивы уязвимостей, до сих пор не продемонстрировал способности полностью автономно генерировать «сквозные атаки от начала до конца».

По их мнению, индекс опасности GPT-5.6 по-прежнему контролируется ниже красной линии «критической угрозы кибербезопасности», и он не способен самоэволюционировать и самостоятельно атаковать человеческие сети.
Однако отчёт METR показывает, что, вероятно, это не так.
Когда обычные пользователи дождутся GPT-5.6?
Источники:
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
Статья из WeChat Official Account «Новая Эра Искусственного Интеллекта» (新智元), автор: ASI启示录








