Kendala Daya Komputasi
Sejak akhir tahun lalu, GPU produksi dalam negeri seperti Moore Thread, MetaX, Biren Technology, dan Enflame telah memicu gelombang euforia modal. Namun, di balik pesta kekayaan di pasar sekunder, sebuah garis gelap yang tidak bisa diabaikan semakin jelas, dan masalah yang ditimbulkannya semakin mendesak.
Dalam beberapa tahun terakhir, chip AI domestik terutama terkonsentrasi di sisi "inferensi" yang relatif aman dan lebih pinggiran, seperti rencana pembelian 50.000 chip Enflame oleh Doubao untuk tugas komputasi inferensi, guna memenuhi pemanggilan frekuensi tinggi dari aplikasi AI terbesar di Tiongkok ini.
Sementara itu, dalam urutan puncak piramida daya komputasi untuk pelatihan AI, chip domestik saat ini hanya dapat berpartisipasi dalam tugas-tugas "sampingan" di pinggiran.
Chip pelatihan AI terutama digunakan untuk melatih model kecerdasan buatan, yang melibatkan sejumlah besar operasi matriks dan penyesuaian parameter, sehingga memerlukan kemampuan komputasi yang kuat dan rasio efisiensi energi yang tinggi. Kinerjanya lebih kuat dan harganya juga sangat mahal, seperti seri NVIDIA A100, H100, H200, dan seri AMD MI300.
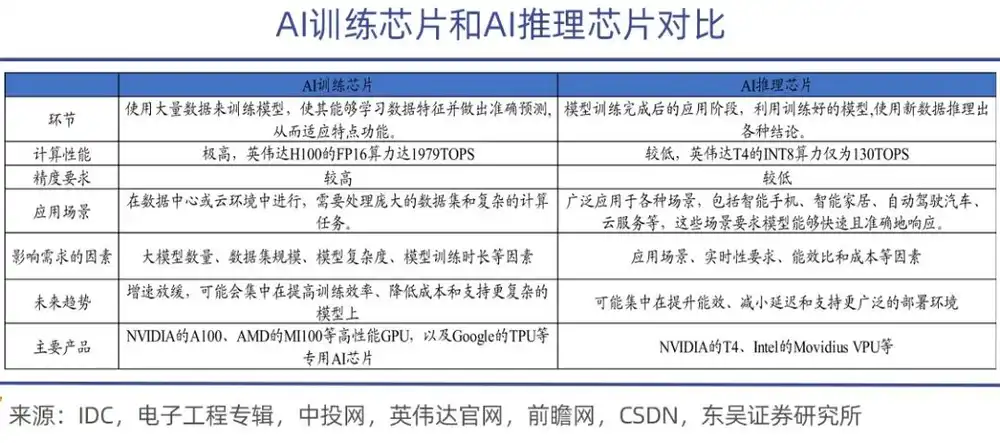
Sebaliknya, tugas chip inferensi jauh lebih ringan. Digunakan pada tahap penerapan setelah model selesai dilatih, terutama bertanggung jawab untuk menjalankan tugas inferensi model, yang memerlukan respons waktu nyata yang tinggi. Chip inferensi perlu memiliki respons cepat dan konsumsi daya rendah sambil memastikan akurasi.
Sebuah analogi yang tepat adalah: pelatihan adalah membuat model AI "belajar pengetahuan", inferensi adalah membuat model besar "menerapkan pengetahuan". Pada tahap belajar, chip pelatihan harus memanggil data dalam jumlah besar untuk "memberi makan" pembaruan dinamis parameter miliaran, triliunan, bahkan puluhan triliun, tidak hanya membutuhkan daya komputasi yang tangguh, tetapi juga memerlukan bandwidth dan kemampuan komunikasi yang efisien, serta stabilitas dalam kluster puluhan ribu kartu.
Akar perbedaan model Tiongkok-AS terletak pada "tempat-tempat yang tidak terlihat" ini, terutama ketidakhadiran chip pelatihan kelas atas.
Di bawah hukum Scaling Law model besar, semakin besar parameter model, kebutuhan daya komputasi tumbuh secara linear, sementara biaya daya komputasi dan perangkat keras yang meledak secara eksponensial, membuat pelatihan model besar menjadi "permainan eksklusif" bagi segelintir raksasa teknologi.
Di antara raksasa teknologi AS, hanya Meta yang berencana menggunakan lebih dari 1,2 juta GPU kelas atas pada akhir 2026, dengan investasi tahunan lebih dari $145 miliar; perhitungan lain menunjukkan bahwa total daya komputasi AI Google setara dengan 5 juta unit NVIDIA H100, satu perusahaan menyumbang 1/4 dari total global.
Pengeluaran modal empat perusahaan Amazon, Microsoft, Alphabet, dan Meta tahun ini mencapai $725 miliar, melonjak 77% dibandingkan tahun lalu. Skala ini setara dengan 13% dari total investasi domestik swasta AS selama setahun. Morgan Stanley bahkan memprediksi bahwa pada 2027, pengeluaran modal perusahaan teknologi AS berpotensi mencapai rekor sejarah $1,1 triliun.
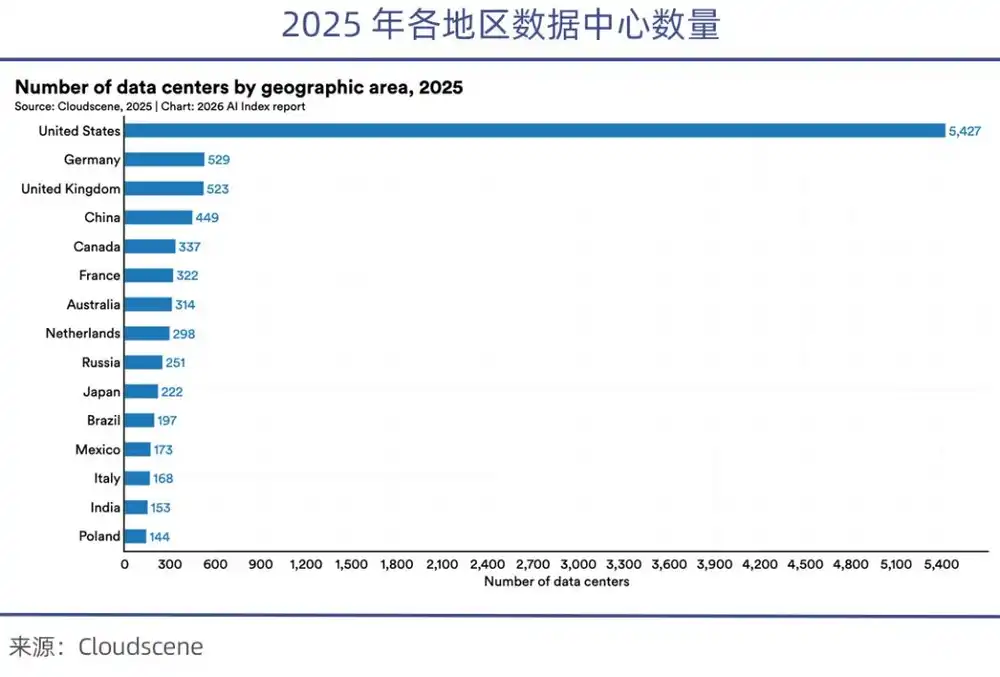
Saat ini AS menguasai lebih dari 70% GPU kelas atas global. Setelah larangan chip, chip kelas atas yang tersedia di Tiongkok hanya 1/8 dari AS. Laporan Indeks AI Stanford 2026 menunjukkan bahwa jumlah pusat data AS (5.427) lebih dari 10 kali lipat Tiongkok.
Menurut perhitungan China Academy of Information and Communications Technology (CAICT), hingga awal 2025, skala daya komputasi AS adalah 2.400 EFLOPS, Tiongkok 1.053 EFLOPS, AS lebih dari dua kali lipat Tiongkok.
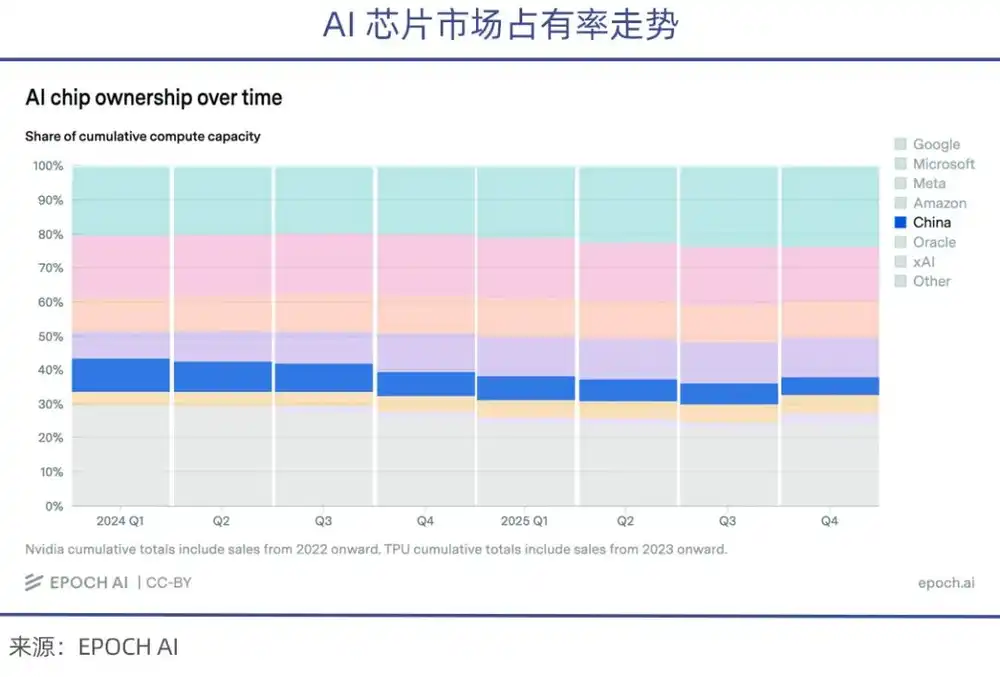
Skala daya komputasi yang dimiliki oleh keempat raksasa teknologi tersebut, masing-masing jika diambil sendiri, telah melebihi jumlah semua perusahaan AI Tiongkok.
Keunggulan daya komputasi yang menghancurkan ini memungkinkan perusahaan AS menyelesaikan lebih dari selusin iterasi eksperimen model besar dalam setahun.
Musk bahkan lebih ekstravaganza. xAI miliknya memiliki Colossus 2 yang disebut sebagai "kluster AI tingkat GW pertama di dunia". Karena itu dia berani mengklaim sedang melatih 7 model secara bersamaan—dua model 1 triliun, dua 1,5 triliun, satu 6 triliun, dan satu 10 triliun parameter. "Estetika kekerasan" seperti ini hanya bisa dilakukan dalam kondisi daya komputasi yang sangat melimpah.

Sementara itu, karena pembatasan ekspor chip oleh AS, pangsa yang diperoleh perusahaan Tiongkok dari chip AI kelas atas yang dikirimkan dalam beberapa tahun terakhir terus menurun (menurut statistik epoch.AI).
Dapat dikatakan tanpa berlebihan bahwa kesenjangan besar dalam fondasi daya komputasi akan membuat AI Tiongkok berada dalam fase pengejaran jangka panjang, dan juga akan membuat proses model besar domestik mengejar rekan-rekan AS menjadi lebih sulit.
Perbedaan Generasi
"Langkah inovasi Tiongkok tidak terbendung", "Siapa yang mengira Tiongkok tidak bisa membuat (chip), sungguh salah lihat. Perbedaan antara Tiongkok dan AS hanya tingkat nanodetik".
Pendiri NVIDIA, Jensen Huang, tidak hanya sekali memuji kemajuan semikonduktor Tiongkok di forum publik.

Musk juga sering menyampaikan pandangan serupa di X—"Tiongkok pasti akan menyelesaikan masalah kendala chip, di bidang daya komputasi AI, akan jauh melampaui negara lain di dunia", "Tiongkok akan memenangkan perlombaan AI di bumi".
Pujian berlebihan dari tokoh besar dunia teknologi terhadap perkembangan AI Tiongkok sangat mudah dipercaya. Namun, komentar-komentar ini jelas memiliki unsur pujian berlebihan yang menyesatkan. Sebagian media AS terus-menerus menyebarkan opini bahwa perbedaan model Tiongkok-AS sangat kecil, mencoba mengaburkan fakta dan menutupi beberapa kebenaran objektif.
Terhadap hal ini, bidang terkait AI domestik harus tetap jernih dan tenang.
Jika model besar canggih Tiongkok saat ini tidak jauh berbeda dengan pesaing AS dalam memecahkan masalah standar, maka dalam lingkungan industri kompleks dan perusahaan, perbedaannya akan tampak lebih jelas.
Dibandingkan dengan model terdepan AS seperti Anthropic, Tiongkok masih termasuk pengejar. Penilaian CAISI AS menganggap DeepSeek V4 Pro terkuat domestik tertinggal sekitar 8 bulan dari garis depan AS.
Kai-Fu Lee baru-baru ini dalam wawancara dengan Wall Street Journal menunjuk model puncak AS seperti Claude Fable 5 yang diluncurkan Anthropic sebagai tolok ukur, menyatakan AS saat ini memimpin Tiongkok sekitar 15 bulan.

Model besar mengikuti hukum Scaling Law: semakin besar jumlah parameter model, semakin banyak data pelatihan, semakin besar daya komputasi yang diinvestasikan, semakin baik kinerja model. Sekarang, model besar terdepan AS telah memasuki era puluhan triliun parameter, dan kecepatan iterasi masih meningkat.
Mythos paling kuat dari Anthropic telah mencapai 10 triliun parameter, melatihnya menghabiskan $10 miliar; Colossus 2 xAI sedang melatih 7 model secara bersamaan, termasuk model 6 triliun dan 10 triliun parameter; OpenAI mengiterasi satu putaran model 4 triliun parameter hanya dalam satu bulan.
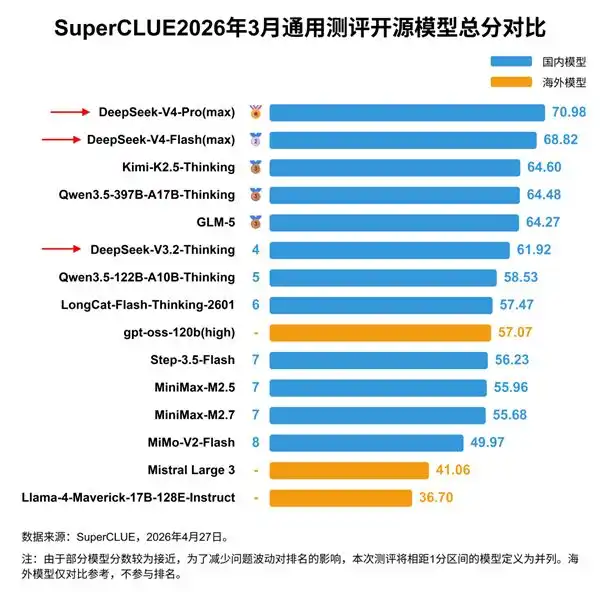
Model terkuat Tiongkok, DeepSeek V4 Pro, memiliki total parameter 1,6 triliun, sekitar 6 kali lebih kecil dari garis depan AS yang berjumlah puluhan triliun.
Seri Claude milik Anthropic telah diakui sebagai model AI pemrograman terkuat dalam dua tahun terakhir, Mythos sekali lagi memperbarui persepsi publik, kinerjanya bahkan lebih kuat dari flagship sebelumnya, Oups 4.6.
OpenBSD terkenal sebagai sistem paling aman di industri, namun Mythos menemukan kerentanan yang tidak terdeteksi selama 27 tahun. Ia juga menemukan kerentanan di FFmpeg, kernel Linux yang tidak ditemukan selama bertahun-tahun bahkan belasan tahun, dan itu ditemukan secara otonom tanpa bantuan manusia.
Perlu diketahui, "pra-pelatihan" model besar menentukan batas atas kemampuan model, tidak dapat disesuaikan melalui "pasca-pelatihan" untuk mencapai kemampuan model 10 triliun parameter dengan model tingkat triliunan parameter. Faktor penentu pra-pelatihan adalah chip daya komputasi kelas atas, yang menentukan skala parameter dan kecepatan iterasi pelatihan.
Ketua Dewan Direksi iFlyTek, Liu Qingfeng, mengakui bahwa saat ini berbagai produsen model besar top, terutama raksasa AS, sedang membangun platform daya komputasi skala super. Daya komputasi domestik memang menghadapi masa sulit, menyebabkan pembatasan dalam melatih konteks teks yang sangat panjang.
Jelas, kesenjangan daya komputasi adalah akar perbedaan model Tiongkok-AS.
Kebangkitan Produk Domestik
Satu perusahaan memonopoli 90% pangsa pasar chip pelatihan AI kelas atas global—ini membantu NVIDIA mempertahankan tahta perusahaan dengan kapitalisasi pasar terbesar di dunia. Kapitalisasi pasarnya pernah melebihi PDB Jerman, ekonomi terbesar ketiga dunia pada 2025.
Data TrendForce menunjukkan, pada Q1 2026, pasar server GPU global, NVIDIA sendiri menelan 68%, AMD menguasai 5%-6%, sementara produsen GPU domestik secara keseluruhan kurang dari 4%.
Dengan keunggulan pertama, hambatan teknologi yang sangat kuat, interkoneksi kecepatan tinggi, ekosistem perangkat lunak, dan pengikatan proses canggih TSMC, NVIDIA mendominasi dunia. Dalam skenario pelatihan kelas atas, kinerja NVIDIA GB300 lebih kuat dari AMD MI325, juga lebih baik dari Cambricon Siyuan 690, Moore Thread MTT40, terutama dalam pelatihan model besar triliunan parameter, kinerjanya 30% lebih baik dari pesaing.
Di bawah larangan ekspor, Jensen Huang sebelumnya telah menyatakan bahwa pangsa pasar NVIDIA di Tiongkok (tambahan) pada dasarnya telah nol, hanya tersisa pasar stok. Dengan dukungan kebijakan substitusi impor, perusahaan-perusahaan termasuk Huawei Ascend 910, Hygon DCU ShenSuan 2, Cambricon Siyuan 370/590, serta Moore, MetaX, dan lainnya bermunculan.
Di antaranya, Ascend 910 adalah chip daya komputasi terkuat Huawei, daya komputasi Ascend 910B mencapai 640 TOPS (INT8), dapat disandingkan dengan chip NVIDIA A100.
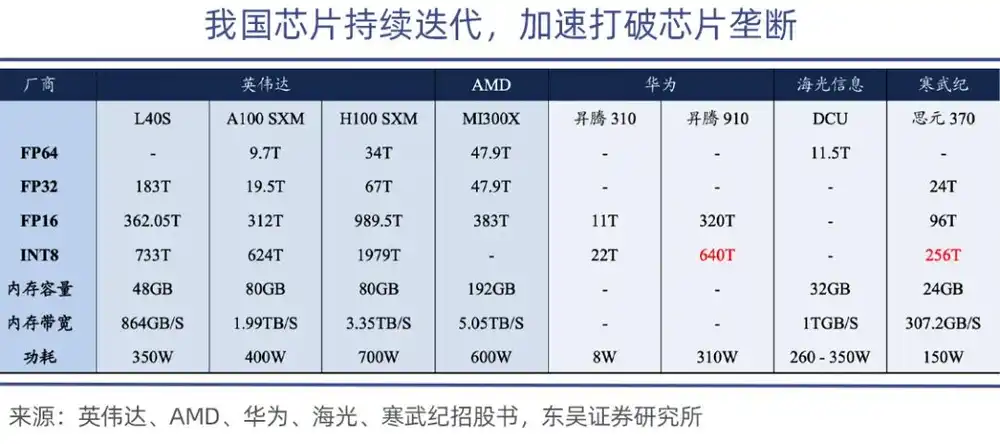
Pada tingkat kinerja absolut, GPU domestik memang masih memiliki kesenjangan, tetapi dapat mulai dari skenario inferensi dan pinggiran. Saat ini GPU domestik pada dasarnya memenuhi kebutuhan inferensi umum pemerintah dan perusahaan domestik, kesenjangan dengan produk menengah NVIDIA menyusut menjadi 15%-20%, memiliki kelayakan substitusi.
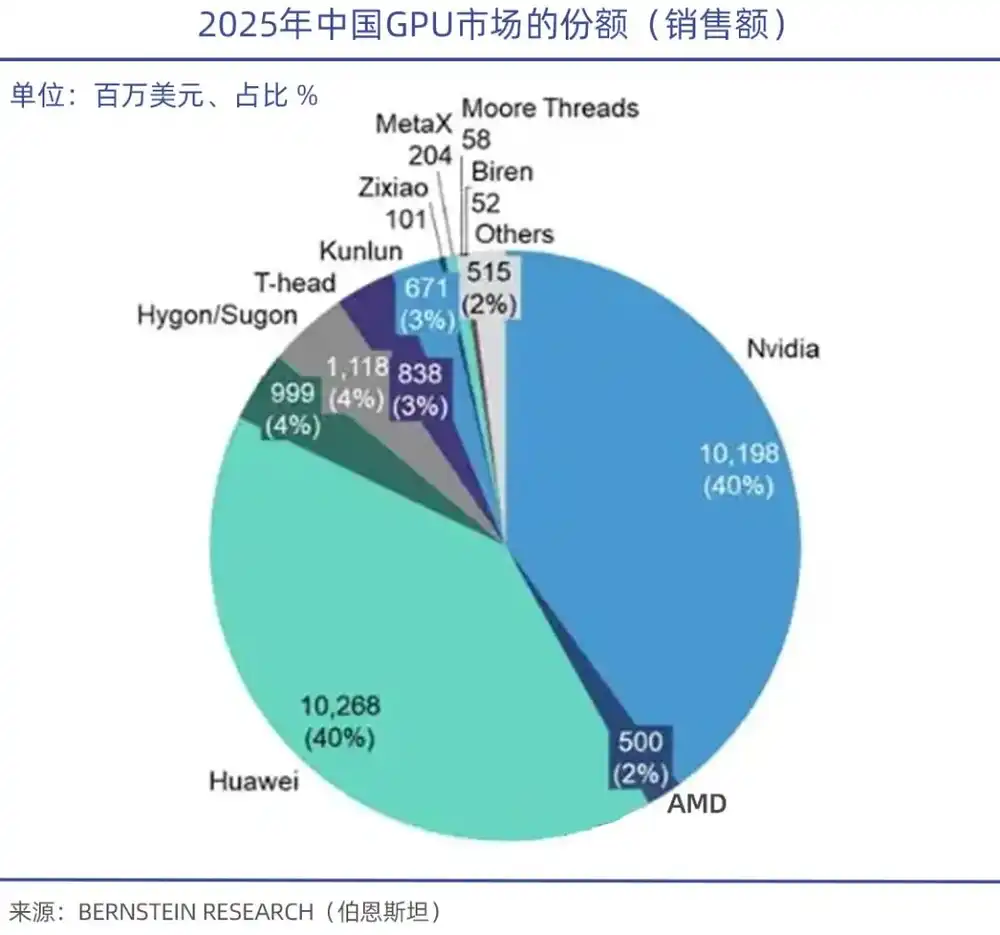
Perlu dicatat khusus, kinerja daya komputasi memang penting, tetapi ekosistem perangkat lunak teknis di baliknya adalah kelemahan GPU domestik. Seperti CUDA yang merupakan fondasi membangun kerajaan GPU NVIDIA, akademisi Akademi Teknik Tiongkok, Zheng Weimin, menyatakan inti masalah chip AI domestik adalah ekosistem yang tidak cukup baik. Jika ekosistemnya baik, kinerja mencapai 60% pun akan ada yang menggunakan.
Dapat dikatakan, ekosistem perangkat lunak adalah hambatan terkeras di jalur GPU, dan kemampuan NVIDIA dalam hal ini juga sulit digantikan.
Ekosistem CUDA telah digarap lebih dari sepuluh tahun, memiliki lebih dari 4 juta pengembang, puluhan ribu model sumber terbuka, rantai alat pihak ketiga lengkap, mencakup pelatihan AI, inferensi, rendering grafis, komputasi ilmiah, dengan hambatan ekosistem yang sangat kuat dan tak tertandingi.
Data IDC menunjukkan, saat ini lebih dari 95% model AI global dikembangkan berdasarkan ekosistem CUDA. Sementara GPU domestik dengan dukungan kebijakan, perlu berkolaborasi jangka panjang dengan rantai industri, memerlukan kesabaran yang cukup dari media, opini publik, dan pasar modal.
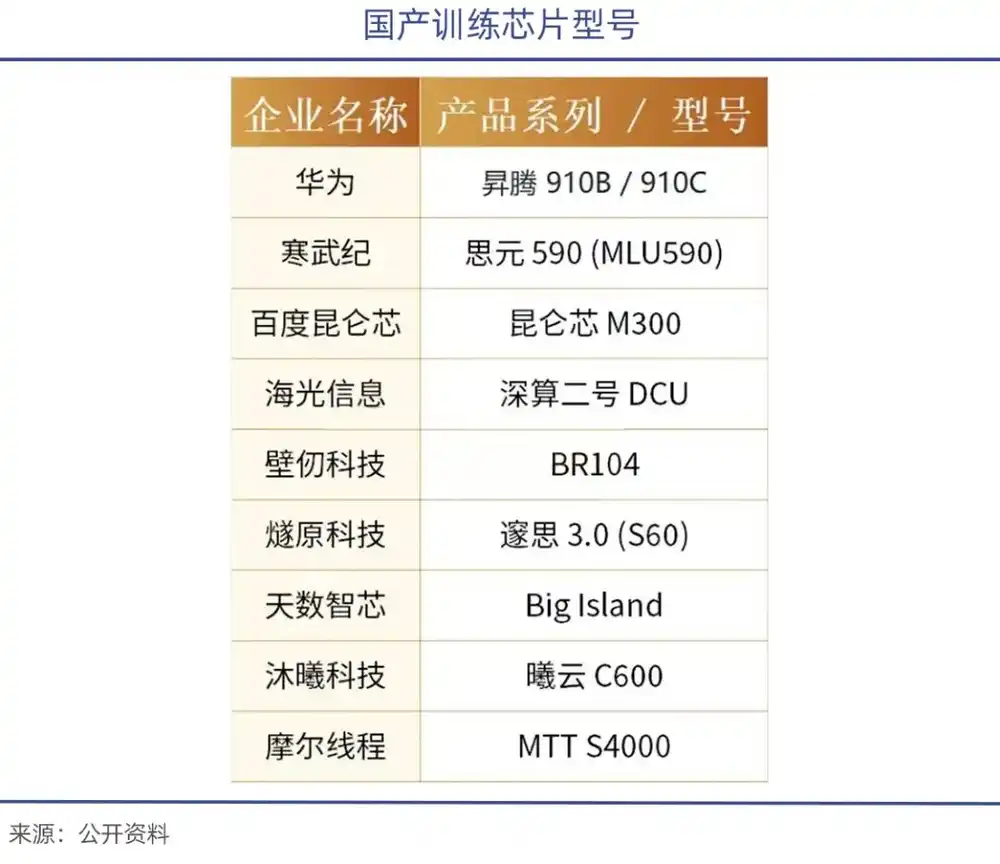
Pada Januari tahun ini, Zhipu bersama Huawei membuka sumber model generasi gambar baru GLM-Image. Model ini berdasarkan perangkat Huawei Ascend Atlas 800T A2 dan kerangka AI Ascend MindSpore, menyelesaikan siklus penuh dari pemrosesan data hingga pelatihan model, menjadi model multimodal SOTA pertama yang dilatih sepenuhnya dengan chip domestik.
Moore Thread juga bersama Beijing Academy of Artificial Intelligence, berdasarkan kluster komputasi cerdas MTT S5000 dan kerangka FlagOS-Robo, menyelesaikan pelatihan penuh model otak berwujud RoboBrain 2.5 yang dikembangkan sendiri oleh akademi. Hasil ini pertama kali memvalidasi ketersediaan kluster daya komputasi domestik dalam pelatihan model besar kecerdasan berwujud.
Dapat dilihat bahwa GPU domestik telah mencapai terobosan dalam adaptasi dan pembangunan ekosistem, dan sedang bergerak dari "terobosan titik" di sisi inferensi, menuju "adaptasi bertahap" di sisi pelatihan, ini sudah merupakan kemajuan yang signifikan.
Kesimpulan
Secara keseluruhan, dalam konteks terhambatnya impor chip canggih dari luar negeri, tidak ada salahnya "menggabungkan Timur dan Barat" dengan berjalan menggunakan dua kaki, sekaligus fokus mendukung chip daya komputasi domestik untuk memenuhi kebutuhan pasar yang mendesak.
Keaslian kebutuhan tidak perlu diragukan lagi, "teori gelembung" masih ada, tetapi suaranya tidak semakin besar. Antusiasme pasar global terhadap pembangunan AI telah melampaui proses awal perkembangan industri mana pun sebelumnya.
Tahun ini, pasar modal global sekali lagi menggelombang siklus super AI, harga saham Samsung, SK Hynix, Broadcom, TSMC terus mencapai rekor tertinggi. Di pasar domestik, teknologi keras yang diwakili oleh Cambricon juga naik pesat, kapitalisasi pasar raksasa modul optik Zhongji Innolight bahkan pernah melebihi Moutai.
Melihat kembali sejarah perkembangan semikonduktor Korea Selatan, Korea Selatan dengan kekuatan nasional mendukung industri chip memori, melewati momen tergelap, dan akhirnya mengalahkan Jepang, menjadi raja absolut industri memori dunia.
Baik chip memori, chip ponsel, bahkan chip AI saat ini, Tiongkok masih berada dalam tahap pengejaran, ini bukanlah prestasi yang bisa dicapai dalam satu malam. Tetapi dengan pasar yang besar, bakat AI yang terus bermunculan, kekuatan modal yang besar, GPU domestik sudah mulai menunjukkan kemampuan adaptasi tertentu, mampu memenuhi banyak kebutuhan nyata perusahaan AI.
Dalam pertarungan AI tentang nasional ini, Tiongkok dan AS adalah lawan, sekaligus memiliki teknologi, pasar, dan sumber daya yang dibutuhkan satu sama lain.
Artikel ini dari akun WeChat publik: Juchao WAVE , Editor: Yang Xuran, Penulis: Xie Zefeng, Judul asli: "Kendala Daya Komputasi dalam Pertarungan AI Tiongkok-AS | Juchao"





