Oleh Kresi dari Aofeisi
QbitAI | Akun Resmi Publik QbitAI
Baru seminggu dibuka sumbernya, DSpark langsung dipindahkan ke komputer Apple.
Versi transplantasi ini disebut mlx-dspark, menjalankan dua model: Gemma-4 12B dan Qwen3-4B.
Setelah dipasang, kecepatan generasi kedua model ini di Mac meningkat masing-masing 1,6 kali dan 1,4 kali lipat.
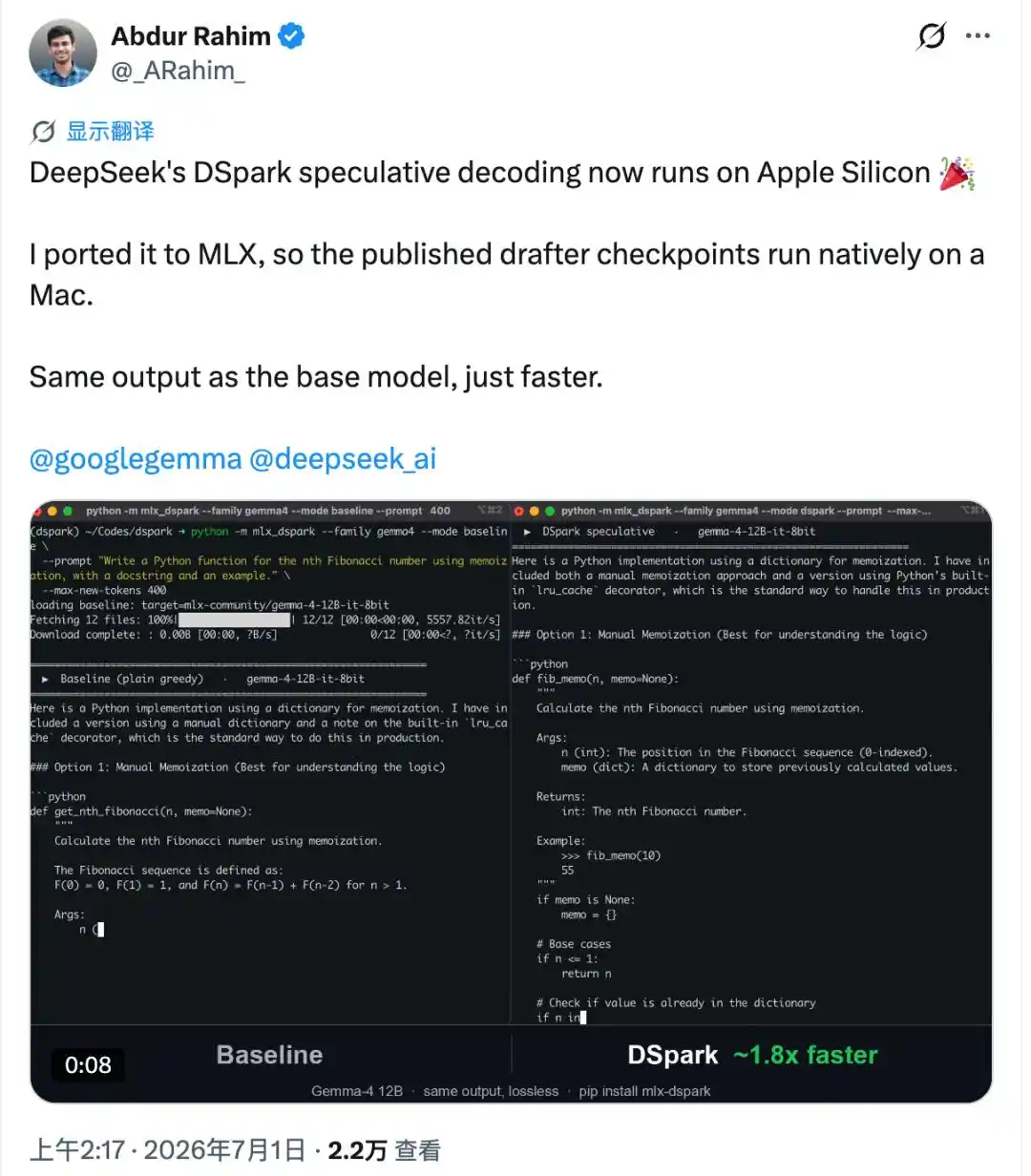
Yang lebih sulit lagi, ia berhasil melakukan sesuatu yang kebanyakan versi transplantasi tidak mampu lakukan — outputnya sama persis byte demi byte dengan model aslinya, tidak ada satu kata pun yang berbeda.
Artinya, kecepatan bertambah, kualitas sama sekali tidak berkurang.
Orang yang mengerjakannya adalah Abdur Rahim, seorang insinyur yang mengutak-atik proyek sumber terbuka di waktu luangnya. Versi native Mac pertama sejak DSpark dibuka sumber, semuanya dia kerjakan sendiri.
Menjalankan Model Besar di Komputer Apple, Kecepatan Naik 60%
Untuk DSpark yang dibuka sumber oleh DeepSeek pada 27 Juni, angka yang diberikan resmi adalah peningkatan kecepatan 60% hingga 85% dalam skenario sisi server.
Namun, teknologi ini pada awalnya hanya memiliki implementasi untuk GPU di pusat data, tidak ada versi yang diadaptasi untuk chip Apple.
mlx-dspark adalah versi native chip Apple pertama untuk teknologi ini.

Ide DSpark adalah memasangkan model yang lebih kecil untuk membantu model target. Model kecil ini melontarkan beberapa kandidat kata sekaligus, lalu model target memeriksanya secara batch, menerima yang benar, dan menolak yang salah untuk ditebak ulang.
Biaya langkah ini berbeda antara pusat data dan komputer Apple.
Di GPU pusat data, memeriksa sekumpulan kandidat kata lebih seperti menyewa mobil sewaan, berapa pun penumpangnya tarifnya tetap. Dekoding memang menjadi hambatan memori, memeriksa beberapa kata tambahan hampir tidak menambah waktu.
Chip Apple lebih seperti taksi dengan argometer, semakin banyak kandidat kata yang diperiksa, semakin banyak angka yang meloncat.
Rahim sendiri menguji, untuk Gemma-4 12B, setiap tambahan pemeriksaan satu token membutuhkan waktu sekitar 14 milidetik lebih lama. Dia menghitung perhitungan ini menjadi sebuah model biaya, dan menyimpulkan bahwa batas kecepatan di chip Apple adalah sekitar 2,2 kali lipat.
Singkatnya, Rahim memindahkan model kecil pembantu ini dari checkpoint HuggingFace, lalu memasangkannya untuk digunakan oleh dua model target: Gemma-4 12B dan Qwen3-4B.
Dia juga membangun ulang alur verifikasi di dalam kerangka kerja MLX, dan mengkuantisasi bobot model menjadi 4-bit.

Hasilnya, di M4 Pro, dibandingkan dengan alat resmi MLX dari Apple, kecepatan generasi Gemma-4 12B naik dari 18,4 tok/s menjadi sekitar 30 tok/s, sekitar 1,6 kali lipat dari sebelumnya; Qwen3-4B naik dari 52,9 tok/s menjadi sekitar 73 tok/s, sekitar 1,4 kali lipat.
Selain itu, di dalam mlx-dspark, Rahim juga melakukan sesuatu yang kebanyakan pekerjaan transplantasi tidak lakukan.
Versi Transplantasi Juga Bisa Mengembalikan dengan Presisi Tinggi
Kebanyakan versi yang memindahkan model besar ke lokal hanya mendukung decoding serakah (greedy decoding), yaitu memilih kata dengan probabilitas tertinggi di setiap langkah.
Rahim di mlx-dspark, juga mengimplementasikan metode sampling suhu yang dijelaskan di makalah DSpark asli. Model draf memberikan kandidat kata, probabilitas penerimaannya adalah min(1, p/q), bagian yang tidak lolos disampling ulang dari residu.
Dia sendiri memverifikasi, output yang dihasilkan dari alur ini, secara ketat sama dengan distribusi persis yang akan diberikan oleh model target pada suhu yang sama, bukan versi perkiraan yang dikurangi.
Kebanyakan decoding spekulatif hanya membuat versi serakah, karena memverifikasi kebenaran mode serakah itu sederhana, cukup bandingkan kata demi kata.
Langkah ekstra yang dilakukan Rahim adalah dengan memverifikasi sendiri distribusi output yang dihasilkan dalam mode sampling, memastikan tidak ada penyimpangan.
Presisi apa yang harus digunakan untuk model target yang bertanggung jawab memverifikasi, adalah salah satu kendala yang dia coba sendiri.
Jika model kecil dipasangkan dengan model target versi dasar yang belum mengalami fine-tuning instruksi, kandidat kata yang dilontarkan hanya 47% yang lolos verifikasi; jika diganti dengan versi fine-tuning instruksi yang sesuai, proporsi ini naik menjadi 82%.
Dia juga menguji mengganti model target ke presisi bf16, biaya verifikasi naik lebih banyak daripada kenaikan tingkat penerimaan, justru lebih lambat, jadi model target defaultnya paling efisien tetap di 8-bit.
Model kecil yang bertanggung jawab melontarkan kandidat kata pendahuluan, menggunakan presisi yang berbeda.
Model draf itu sendiri dikompresi olehnya, setelah dikuantisasi 4-bit hanya berukuran 1,8GB, dapat dimasukkan ke memori tanpa masalah, dan tetap berjalan tanpa kehilangan kualitas (lossless).
Hasilnya, DSpark tidak hanya mencapai percepatan, tetapi juga benar-benar mereproduksi peningkatan tingkat penerimaan 16% hingga 18% yang disebutkan di makalah, di perangkat ujung.
DFlash Juga Dihubungkan, Tugas Kode Lebih Cepat
Setelah tweet dikirim, di bagian komentar ada yang bertanya, Jian Chen, salah satu penulis makalah DFlash, bertanya apakah bisa mencoba model dari tim mereka.
DFlash adalah skema decoding spekulatif lain yang diusulkan di makalah yang dirilis lab z pada bulan Mei, pemimpin tim penulis adalah Zhijian Liu, asisten profesor UCSD, sekaligus ilmuwan peneliti di NVIDIA.
Ide DFlash sedikit berbeda dengan DSpark, ia menggunakan "difusi blok" paralel satu kali untuk mendekode seluruh blok 16 token sekaligus, bukan seperti DSpark yang menebak langkah demi langkah dengan ketergantungan.
Rahim segera bertindak.
Dia menggunakan skrip transplantasi yang ditulis Jian sendiri, menghubungkan gemma4-12B-it-DFlash yang dirilis lab z ke model target Gemma-4 dari mlx-vlm, dan di Mac yang sama, menjalankan perbandingan head-to-head lagi dengan DSpark yang baru saja dia uji.
Pada tugas kode dan matematika, panjang penerimaan (acceptance length) decoding blok penuh DFlash bisa mencapai 5,95 hingga 6,20, kecepatan sekitar 36 tok/s, mencapai sekitar 2,1 kali lipat, mengalahkan DSpark.
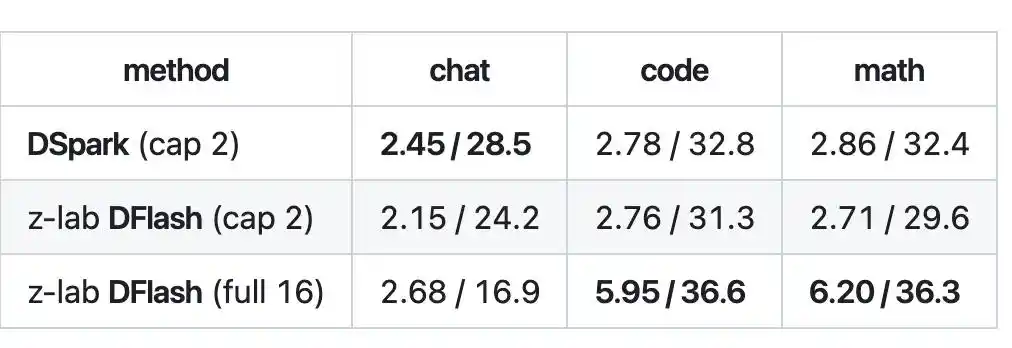
Namun, DFlash perlu melontarkan seluruh blok 16 token sekaligus, tetapi model target belum tentu menerima semuanya, yang sebenarnya lolos verifikasi hanyalah sebagian darinya. Dalam industri, ini disebut "panjang penerimaan", tidak selalu bisa mengisi penuh 16 token setiap kali.
Jadi dalam skenario obrolan terbuka di mana konten sulit diprediksi, panjang penerimaan tidak bisa tinggi, blok tidak terisi penuh, keunggulan DFlash tidak bisa dimanfaatkan.
Markov head DSpark justru ada untuk mengatasi masalah yang sama ini, melontarkan sekumpulan kata secara paralel, semakin ke posisi belakang dihitung secara independen, mudah menjadi tidak selaras. Markov head menambahkan lapisan ketergantungan antara posisi-posisi ini, khusus untuk mengoreksi masalah ini.
Hasilnya, dalam skenario obrolan, DSpark justru lebih cepat daripada DFlash.
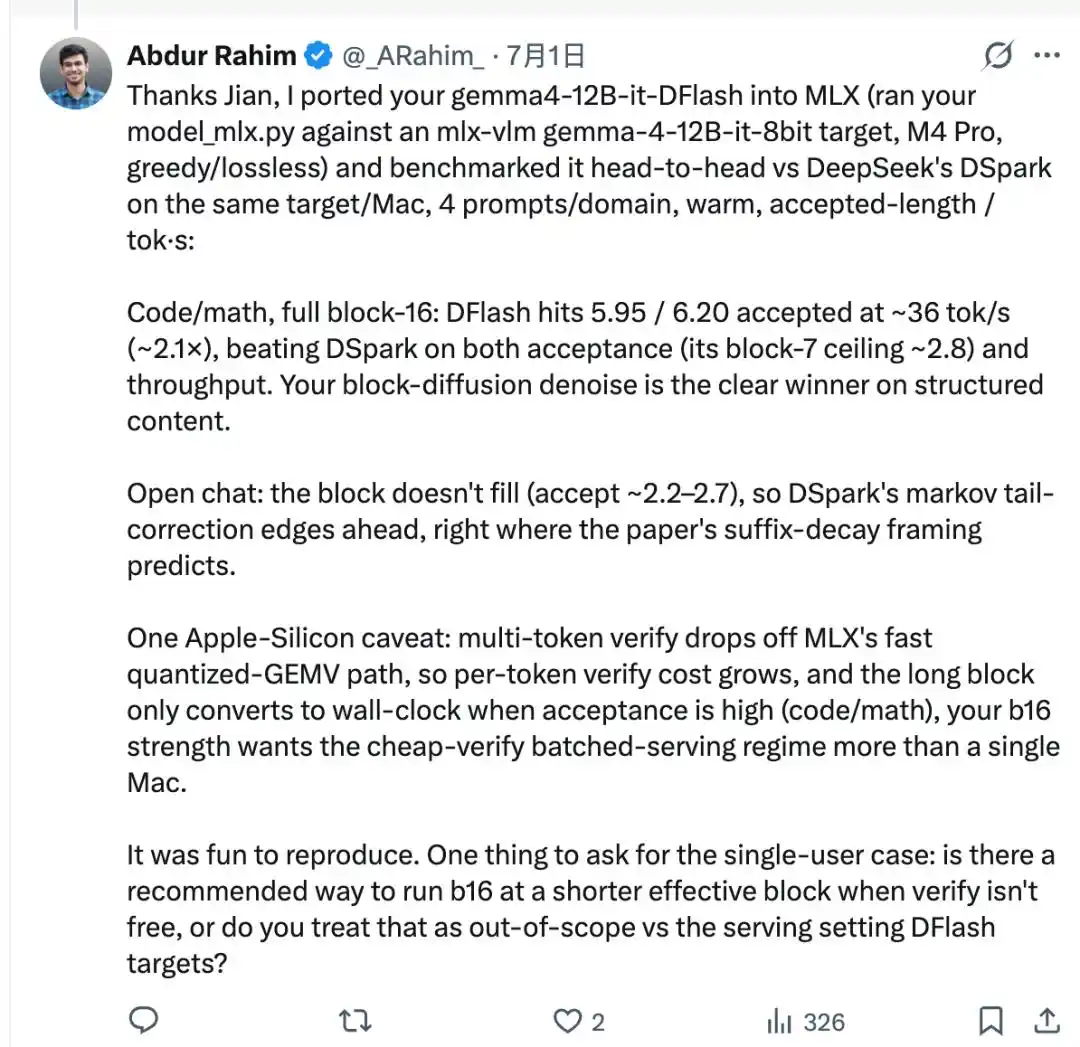
Dan kemudian, mlx-dspark v0.0.3 yang diperbarui, secara resmi menghubungkan DFlash versi asli lab z ke dalam paket, dan menambahkan sebuah parameter, yang dapat secara manual menyesuaikan panjang blok efektif DFlash menjadi lebih pendek. Skenario obrolan menggunakan blok pendek, skenario kode dan matematika tetap menggunakan blok penuh 16.
Setelah ini, Mac yang sama, paket yang sama, dapat menyelesaikan tugas obrolan dan tugas kode serta matematika secara bersamaan, tidak perlu lagi berpindah-pindah antara proyek DSpark dan DFlash.
Rahim mengatakan di tweet-nya, metode yang sama seharusnya juga bisa berjalan pada model draf Qwen3-8B dan 14B yang lebih besar.
Tautan Referensi:
[1]https://x.com/_ARahim_/status/2072021710602432577
[2]https://github.com/ARahim3/mlx-dspark
Artikel ini berasal dari akun resmi publik "QbitAI", penulis: Perhatian Teknologi Terdepan






