¿Quieres saber qué modelo de lenguaje grande es realmente el más fuerte en las tareas de agente del mundo real de OpenClaw?
MyToken, basándose en un sitio web de evaluación, ha organizado un conjunto de puntos de referencia transparentes centrados en evaluar la capacidad práctica de los agentes de codificación de IA, observando solo la tasa de éxito como dimensión central (la velocidad y el costo pertenecen a otras dimensiones independientes, que se analizarán por separado más adelante). Completamente público, reproducible, solo presenta estándares de evaluación rigurosos + el Top 10 de las últimas tasas de éxito.
I. Dimensión de evaluación: Tasa de éxito
Estándar específico: el porcentaje de tareas dadas que el agente de IA completa con precisión. Cada tarea adopta un proceso altamente estandarizado:
-
Indicaciones de usuario precisas (Prompt)
Se envían al agente para simular escenarios reales de solicitud de usuario.
-
Comportamiento esperado (Expected Behavior)
Se especifican los métodos de implementación aceptables y los puntos clave de decisión.
-
Criterios de puntuación (checklist)
Se lista una lista de verificación atomizada para validar punto por punto el éxito.
II. Tres métodos de puntuación
Esta evaluación adopta principalmente 3 métodos de puntuación:
-
Verificación automatizada: Scripts de Python verifican directamente el contenido del archivo, registros de ejecución, llamadas a herramientas y otros resultados objetivos.
-
Juez de modelo de lenguaje grande (LLM): Claude Opus puntúa según una escala detallada (calidad del contenido, idoneidad, integridad, etc.).
-
Modo mixto: Combina verificación objetiva automatizada + evaluación cualitativa del juez LLM.
Todas las definiciones de tareas, Prompts y lógica de puntuación son completamente públicos para permitir la verificación y repetición de pruebas.
III. Tareas utilizadas para la evaluación
Esta prueba de referencia cubre 23 tareas de diferentes categorías. Abarca múltiples dimensiones como interacción básica, operación de archivos/código, creación de contenido, investigación y análisis, llamadas a herramientas del sistema, persistencia de memoria, etc., acercándose mucho a los escenarios de uso diario de OpenClaw por parte de los desarrolladores:
-
Sanity Check (Automatizado) —— Procesar instrucciones simples y responder correctamente a saludos.
-
Calendar Event Creation (Automatizado) —— Generar un archivo de calendario ICS estándar a partir de lenguaje natural.
-
Stock Price Research (Automatizado) —— Consultar el precio de las acciones en tiempo real y generar un informe formateado.
-
Blog Post Writing (Juez LLM) —— Escribir un blog estructurado en Markdown de aproximadamente 500 palabras.
-
Weather Script Creation (Automatizado) —— Escribir un script de Python para API del tiempo con manejo de errores.
-
Document Summarization (Juez LLM) —— Resumen refinado en 3 partes de los temas centrales.
-
Tech Conference Research (Juez LLM) —— Investigar y organizar información de 5 conferencias tecnológicas reales (nombre, fecha, lugar, enlace).
-
Professional Email Drafting (Juez LLM) —— Rechazar educadamente una reunión y proponer una alternativa.
-
Memory Retrieval from Context (Automatizado) —— Extraer con precisión fechas, miembros, stack tecnológico, etc., de las notas del proyecto.
-
File Structure Creation (Automatizado) —— Generar automáticamente directorios de proyecto estándar, README, .gitignore.
-
Multi-step API Workflow (Mixto) —— Leer configuración → Escribir script de llamada → Documentar completamente.
-
Install ClawdHub Skill (Automatizado) —— Instalar desde el repositorio de habilidades y verificar la usabilidad.
-
Search and Install Skill (Automatizado) —— Buscar habilidades relacionadas con el clima e instalarlas correctamente.
-
AI Image Generation (Mixto) —— Generar y guardar una imagen según la descripción.
-
Humanize AI-Generated Blog (Juez LLM) —— Cambiar contenido con sabor a máquina a lenguaje natural y coloquial.
-
Daily Research Summary (Juez LLM) —— Sintetizar múltiples documentos en un resumen diario coherente.
-
Email Inbox Triage (Mixto) —— Analizar múltiples correos electrónicos y organizar un informe por urgencia.
-
Email Search and Summarization (Mixto) —— Buscar correos electrónicos archivados y extraer información clave.
-
Competitive Market Research (Mixto) —— Análisis de la competencia en el campo empresarial APM.
-
CSV and Excel Summarization (Mixto) —— Analizar archivos tabulares y generar insights.
-
ELI5 PDF Summarization (Juez LLM) —— Explicar un PDF técnico en un lenguaje comprensible para un niño de 5 años.
-
OpenClaw Report Comprehension (Automatizado) —— Responder con precisión a preguntas específicas a partir de un PDF de informe de investigación.
- 极
Second Brain Knowledge Persistence (Mixto) —— Almacenar información entre sesiones y recordarla con precisión.
IV. Conclusión principal: Ranking Top 10 de modelos de lenguaje grande por tasa de éxito (Mejor % / Promedio %)
-
Datos actualizados al 7 de abril de 2026.
-
Mejor % es la tasa de éxito máxima en una sola ejecución, Promedio % es la tasa de éxito promedio en múltiples ejecuciones, lo que refleja mejor la estabilidad.
A continuación se muestran los diez modelos con la mayor tasa de éxito:
-
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
-
arcee-ai/trinity-large-thinking (Arcee AI) —— 91.9% / 91.9%
-
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
-
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
-
minimax/minimax-m2.极7 (MiniMax) —— 89.8% / 83.2%
-
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
-
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
-
qwen/qwen3.6-plus-preview (Qwen) —— 88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
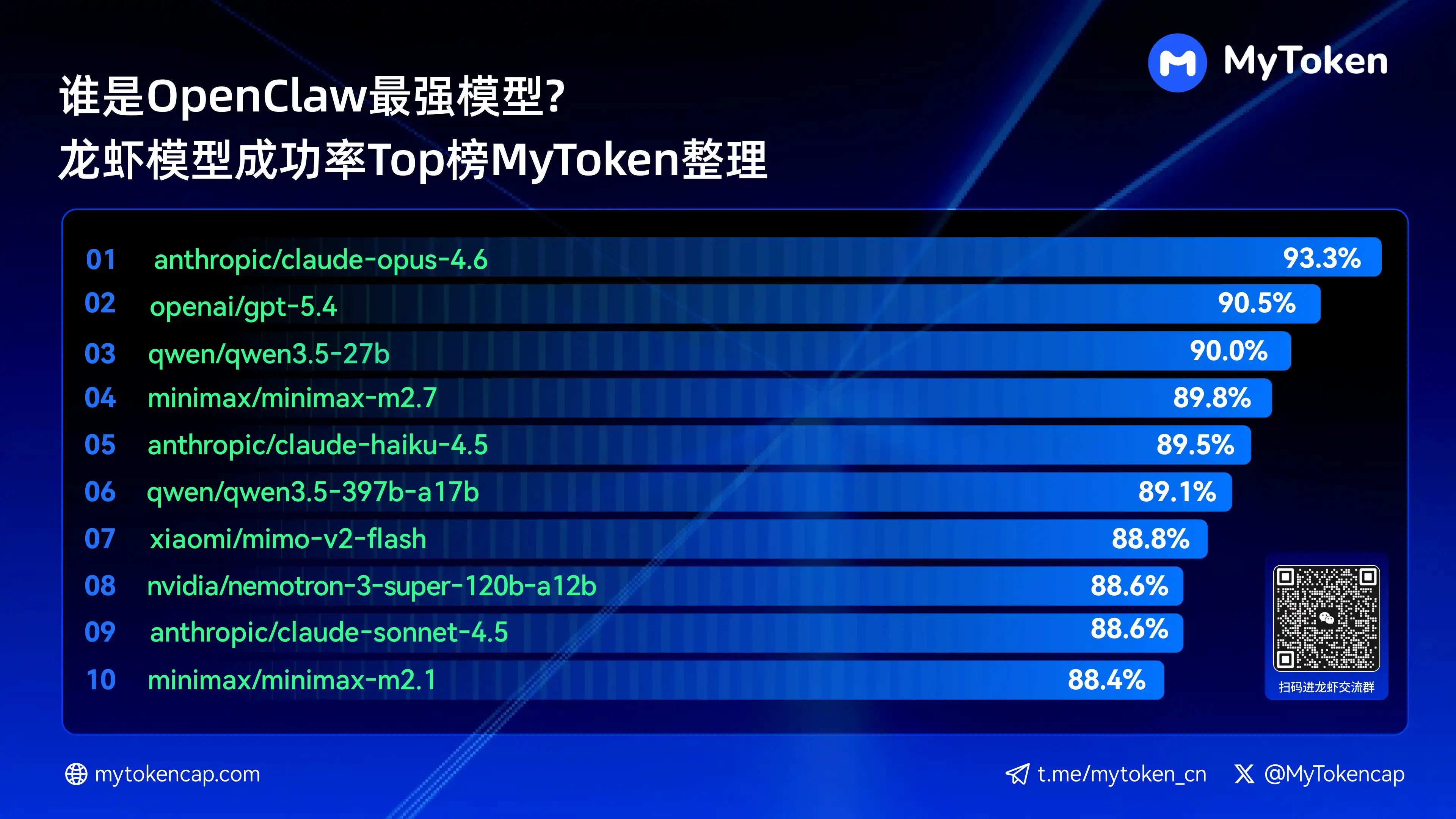
Claude Opus 4.6 lidera actualmente con una tasa de éxito del 93.3%, pero Trinity de Arcee tiene un rendimiento destacado en estabilidad promedio, y la serie Qwen también tiene varios modelos en el top 10, mostrando un gran potencial de relación calidad-precio. La tasa de éxito es el umbral básico; las dimensiones de velocidad y costo afectarán aún más la experiencia práctica.
Este conjunto de referencia de 23 tareas es completamente transparente, y se recomienda encarecidamente probarlo en escenarios prácticos结合自身场景实际测试。Para ver las clasificaciones de otros modelos, estén atentos a la función de ranking de agentes que MyToken lanzará pronto.
(Los datos provienen de las pruebas de referencia de agentes OpenClaw公开的OpenClaw代理基准测试公开公开, publicadas por PinchBench, en constante actualización.)





