Es bien sabido que el entrenamiento de modelos grandes tiene un costo extremadamente alto.
Pero también se sabe que reducir la precisión del entrenamiento puede reducir significativamente el costo. DeepSeek-V3, al entrenar con FP8, logró reducir el costo a 5.6 millones de dólares, sorprendiendo a toda la industria.
Tras el éxito de FP8, la industria sigue explorando los límites de la precisión baja: desde FP8 hasta FP4, ¿cuánto más se puede reducir el costo de entrenamiento?
En teoría, el rendimiento computacional de FP4 puede ser el doble que el de FP8. Las series NVIDIA Blackwell y AMD MI350 ya ofrecen soporte nativo de hardware para operaciones FP4; el primero, en el B200, afirma una potencia de FP4 de hasta 4500 TOPS (esparsa). El hardware está listo, pero el lado del software y los algoritmos se ha visto frenado por un problema:
Entrenar modelos grandes desde cero con FP4 es muy inestable.
En los últimos dos años, trabajos como LLM-FP4 y NVFP4 han explorado esta ruta, pero pocas soluciones han logrado ejecutar de manera limpia el preentrenamiento completo con precisión de 4 bits, manteniendo una calidad de convergencia cercana a FP8.
Lo más complicado es que la causa del colapso no estaba clara; los análisis sugerían que la inestabilidad del entrenamiento en FP4 probablemente se debía a la falta de aleatoriedad.
Pero recientemente, AMD, en colaboración con la Universidad Estatal de Pensilvania, publicó un estudio que desafía la creencia tradicional, ofreciendo un nuevo y claro diagnóstico para el entrenamiento nativo en FP4.

- Título del estudio: Pretraining large language models with MXFP4 on Native FP4 Hardware
- Enlace al estudio: https://arxiv.org/abs/2605.09825
Este estudio completó el preentrenamiento completo de Llama 3.1-8B en la GPU AMD Instinct MI355X utilizando el formato MXFP4, logrando una velocidad de entrenamiento de extremo a extremo entre un 9% y un 10% más rápida que la línea de base FP8, con un costo de tokens solo entre un 8% y un 9% mayor. Este es el primer experimento completo en hardware nativo FP4 (no simulado por software) que logra el preentrenamiento de un modelo grande.
Lo más importante es que el estudio revela el problema central: La fuente de la inestabilidad en el entrenamiento FP4 no es la falta de aleatoriedad, sino la acumulación y amplificación de errores estructurales de microescalado a lo largo de rutas de gradiente sensibles.
¿Qué es MXFP4?
Antes de analizar el estudio, es necesario comprender el formato de datos MXFP4.
La cuantificación tradicional por enteros generalmente utiliza un único factor de escala para todo el tensor. El diseño central de MXFP4 se llama "microescalado": divide un tensor en bloques pequeños (por ejemplo, grupos de 32 elementos) y asigna un exponente compartido (formato E8M0) a cada bloque; cada elemento dentro del bloque se representa con un número de punto flotante de 4 bits. La fórmula de reconstrucción se puede escribir como:
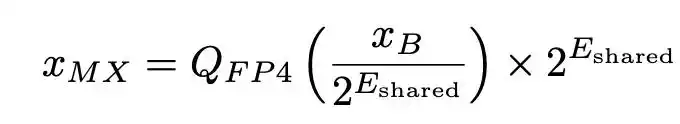
Donde E_shared es el exponente máximo dentro del bloque, y Q_FP4 es el valor redondeado al representable más cercano en punto flotante de 4 bits.
La ventaja del microescalado es que cada bloque pequeño tiene su propio rango dinámico y no se ve "secuestrado" por valores atípicos globales. Esto mejora mucho la calidad de representación de los números de punto flotante de 4 bits en comparación con una cuantificación global simple.
Pero incluso con el microescalado, el entrenamiento en FP4 sigue siendo inestable.
Experimento de diagnóstico: La raíz de la inestabilidad
El equipo de investigación diseñó primero un experimento de control de diagnóstico paso a paso.
Un cálculo completo de la capa lineal de un Transformer implica tres operaciones de multiplicación de matrices generales:
Fprop (Propagación hacia adelante): Calcula Y = XW^T, produciendo valores de activación.
Dgrad (Gradiente de activación): Calcula ∇X = ∇Y · W, propagando el gradiente hacia la entrada.
Wgrad (Gradiente de pesos): Calcula ∇W = (∇Y)^T · X, produciendo el gradiente para actualizar los pesos.
El equipo mantuvo todos los demás factores constantes y reemplazó gradualmente estas tres operaciones de FP8 a MXFP4, observando el impacto en la convergencia en cada paso. Todos los experimentos se ejecutaron en el AMD Instinct MI355X utilizando núcleos tensoriales nativos FP4, sin depender de simulación de software.
La tarea de entrenamiento fue la configuración estándar de MLPerf, preentrenando Llama 3.1-8B en el conjunto de datos C4, con el objetivo de convergencia de alcanzar una perplejidad de 3.3 en el conjunto de validación.
Los primeros dos pasos solo generaron un costo adicional moderado de tokens, pero una vez que Wgrad también se cambió a MXFP4, el costo se disparó directamente al 26-27%.
Wgrad es el cuello de botella para el entrenamiento en FP4. La propagación hacia adelante y el gradiente de activación tienen una tolerancia considerable a la cuantificación FP4, pero una vez que el gradiente de pesos se cuantifica a 4 bits, la calidad de la convergencia se degrada significativamente.
La intuición predominante en la industria hasta ahora era que el error de cuantificación FP4 es esencialmente un problema de ruido, por lo que se podría "suavizar" la distribución del error inyectando aleatoriedad. Dos estrategias comunes son:
Redondeo Estocástico (Stochastic Rounding): Introduce aleatoriedad durante la cuantificación, haciendo que el valor esperado del error de redondeo sea cero.
Rotación Aleatoria de Hadamard (Randomized Hadamard): Antes de la cuantificación, utiliza una transformada de Hadamard con inversión aleatoria de signos para dispersar la distribución de datos.
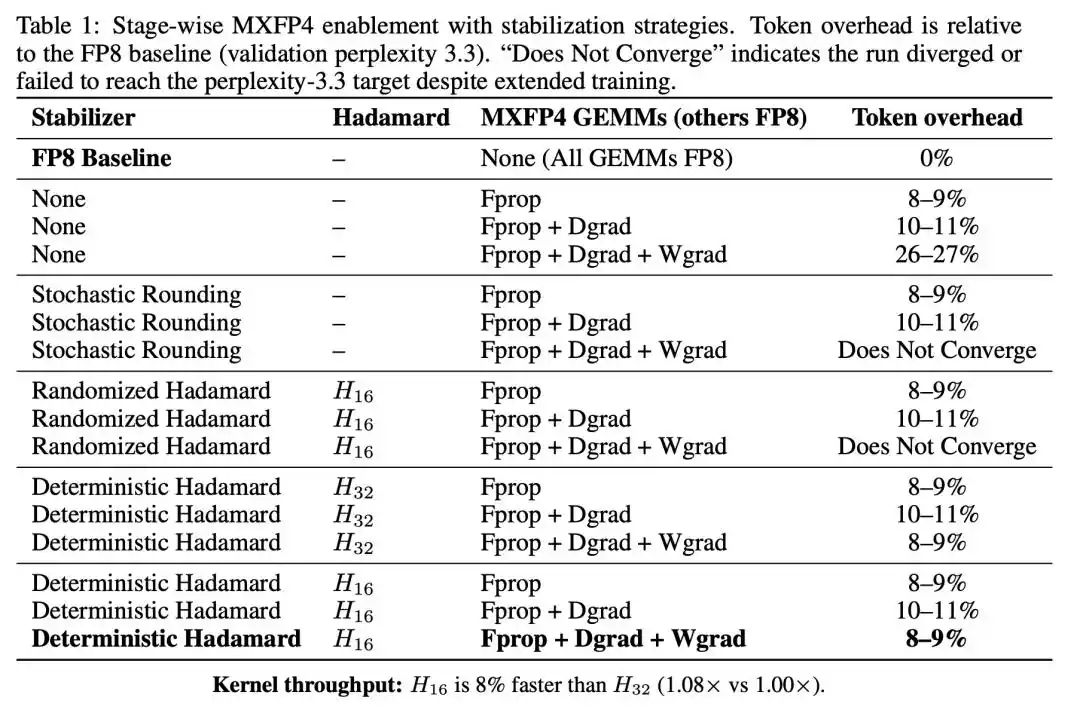
Cuando Wgrad se cuantificó, ambas estrategias de aleatoriedad no solo no estabilizaron el entrenamiento, sino que directamente causaron una falta de convergencia. La aleatoriedad no solo no ayudó, sino que introdujo más error de cuantificación efectivo en la ruta crítica del gradiente.
En contraste, la rotación de Hadamard determinista redujo el costo total de tokens del proceso completo del 26-27% a solo el 8-9%, y la trayectoria de entrenamiento siguió de cerca la línea de base FP8.
Este es un resultado muy valioso para el diagnóstico. Tanto la rotación aleatoria como la determinista de Hadamard son transformaciones ortogonales; ambas pueden dispersar la energía de los valores atípicos y, en teoría, deberían tener efectos similares en la mitigación del error de cuantificación. Pero su comportamiento en el escenario de Wgrad fue diametralmente opuesto, lo que revela la naturaleza del problema:
La inestabilidad del entrenamiento en FP4 está impulsada por errores estructurales generados por el microescalado de MXFP4 en rutas de gradiente sensibles. Las estrategias de aleatoriedad fallan porque introducen patrones de error diferentes en cada paso, y estos patrones de error variables se acumulan a lo largo de la ruta del gradiente, amplificando la inestabilidad. La rotación determinista es efectiva precisamente porque aplica la misma transformación en cada paso, manteniendo el patrón de error consistente y evitando la acumulación de errores.
Eficiencia de extremo a extremo: Rendimiento por paso de entrenamiento +20%, aceleración global del 9-10%
Tras aplicar la rotación de Hadamard determinista junto con MXFP4 en todo el flujo, los datos de eficiencia fueron los siguientes:

El rendimiento por paso de entrenamiento aumentó un 20%. Descontando el costo adicional del 8-9% en tokens, la aceleración global de extremo a extremo sigue siendo de 9-10%.
Considerando que esto implica reducir la precisión directamente de 8 bits a 4 bits, tanto la calidad de convergencia como la magnitud de la aceleración son bastante notables.
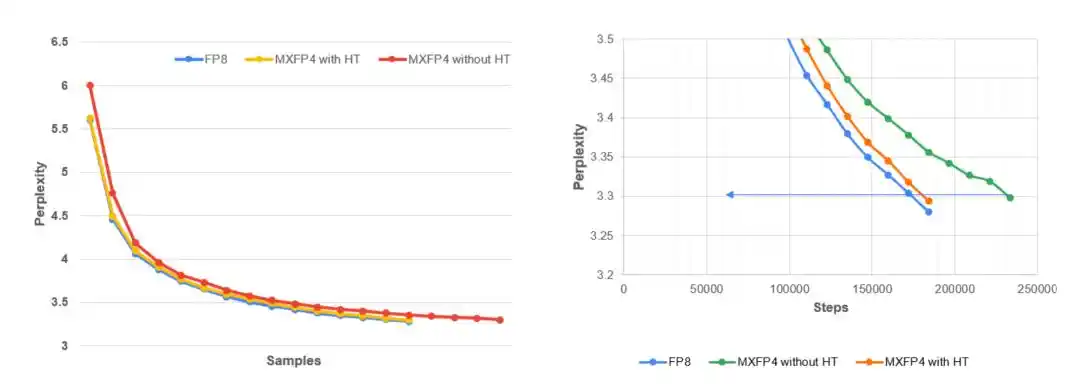
Gráfico izquierdo: Curva de la perplejidad de validación de Llama 3.1–8B en función del número de tokens de entrenamiento durante el preentrenamiento MLPerf en el conjunto de datos C4. Los resultados muestran que MXFP4 + Hadamard determinista se acerca mucho al rendimiento de FP8, mientras que MXFP4 en todo el flujo sin estabilización converge más lentamente y es menos estable. Gráfico derecho: Vista ampliada local de la etapa posterior del entrenamiento. El objetivo de perplejidad de MLPerf es 3.3. En comparación con la ejecución MXFP4 sin estabilizar, la Hadamard determinista (H16) logra mantener una consistencia mucho más estrecha con la línea de base FP8.
Es importante señalar que los autores enfatizan explícitamente en el estudio una limitación importante: la eficacia de este esquema de entrenamiento FP4 (conjunto de datos MLPerf C4 + Llama 3.1-8B) ha sido validada, pero no se puede asumir directamente que se transferirá sin problemas a todos los modelos, conjuntos de datos y métodos de entrenamiento. El comportamiento del entrenamiento FP4 puede depender en gran medida de la configuración, y las estrategias de estabilización específicas deben revalidarse según el escenario.
Conclusión
Colocar este estudio en el contexto más amplio de la industria tiene al menos tres niveles de significado.
Primer nivel: Responde a un "por qué" fundamental. La mayoría de los trabajos previos sobre entrenamiento FP4 se centraban en "cómo evitar que colapse"; este estudio ofrece por primera vez un diagnóstico causal claro: el colapso se origina en errores estructurales de microescalado en la ruta de Wgrad, no en la falta de aleatoriedad. Este diagnóstico en sí mismo tiene valor metodológico; indica a los investigadores posteriores que, al encontrar inestabilidad en el entrenamiento de baja precisión, deben priorizar la investigación de fuentes de error estructural, en lugar de aumentar ciegamente la aleatoriedad.
Segundo nivel: Lleva a FP4 de "exclusivo para inferencia" a "útil para entrenamiento". Anteriormente, el consenso de la industria era que FP4 solo era adecuado para cuantificación de inferencia, y que el entrenamiento requería al menos FP8. El enfoque de NVIDIA en Blackwell en FP4 para inferencia, no para entrenamiento, también refleja esta evaluación. Este estudio ejecuta con éxito el preentrenamiento completo en hardware nativo FP4, lo que significa que la potencia de cálculo FP4 preparada para inferencia en MI355X y Blackwell teóricamente también podría usarse para entrenar. Si el entrenamiento FP4 demuestra ser factible en modelos más grandes y más escenarios, la potencia de cálculo de entrenamiento utilizable del hardware existente prácticamente se duplicaría.
Tercer nivel: Utiliza un estándar abierto de OCP. MXFP4 es parte del estándar de formato de Microescalado de OCP, respaldado conjuntamente por siete compañías: AMD, NVIDIA, Intel, Meta, Microsoft, Arm y Qualcomm. Basarse en un estándar abierto significa que este método tiene portabilidad en el hardware de diferentes fabricantes y no quedará encerrado en un solo ecosistema.
Desde FP16 hasta FP8, DeepSeek-V3 ya ha demostrado que reducir la precisión a la mitad puede disminuir drásticamente el costo de entrenamiento. Desde FP8 hasta FP4, este estudio da el primer paso crucial. Cada reducción de precisión está transformando la economía del entrenamiento de modelos grandes.
Este artículo proviene de la cuenta oficial de WeChat "机器之心" (ID:almosthuman2014), editado por: Leng Mao.







