Guardar no significa poseer, resaltar no significa comprender.
Esos profundos artículos que te emocionaron a las dos de la madrugada, esos enlaces bidireccionales densos que creaste en Obsidian, esas bases de datos cuidadosamente formateadas en Notion, todos son «momias cibernéticas» que yacen en las aplicaciones de notas.
Los gráficos de conocimiento parecen impresionantes, pero en realidad están podridos.
Este es el fracaso sistémico de toda la era de la sobrecarga de información.
El ingeniero actual de Anthropic, ex cofundador de OpenAI y ex director de IA de Tesla, Karpathy, no pudo soportarlo más y lanzó una bomba.

Portal: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
No anunció un nuevo modelo, ni publicó un nuevo framework. Simplemente dijo: trata tus notas como código fuente inmutable, deja que el LLM sea el compilador.
Dos meses después, este documento ha desencadenado una migración silenciosa pero intensa en las comunidades de Obsidian, Claude y Cursor.
Algunos ya han expandido su Wiki a cientos de páginas y cientos de miles de palabras.
Han comenzado a aparecer complementos de automatización. Investigadores académicos, emprendedores independientes y aprendices de por vida están cambiando colectivamente a una nueva forma de producción de conocimiento.
El ocaso del RAG, transportar información no salvará tu pensamiento
Antes de la aparición de LLM-WIKI, la solución principal era RAG (Generación Aumentada por Recuperación).
En pocas palabras, es darle al modelo grande un «buscador»: cuando haces una pregunta, busca algunos fragmentos en tus notas y luego los junta para dar una respuesta.
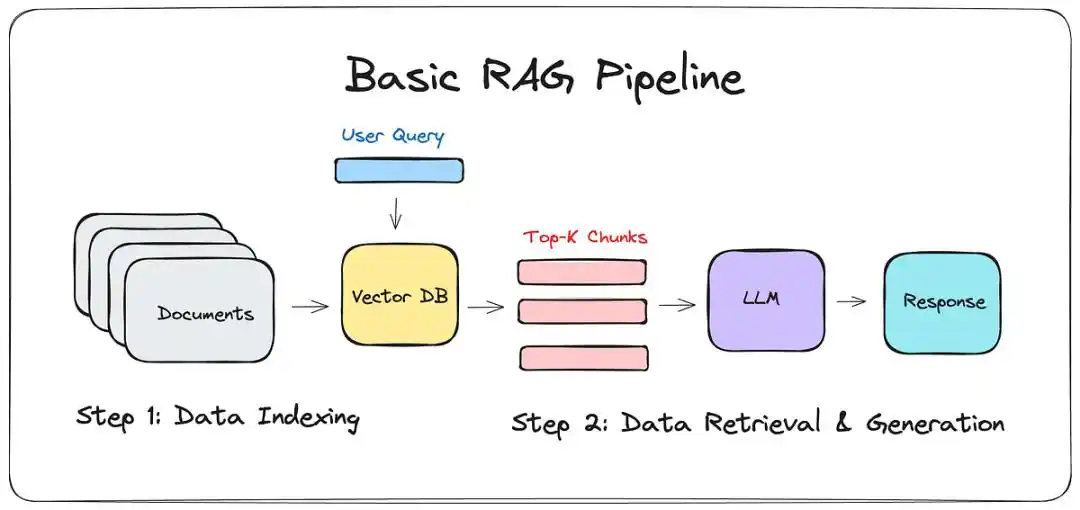
Suena hermoso, pero cualquiera que lo haya usado conoce la brecha entre la «muestra del vendedor» y lo que realmente recibe.
Es solo un transportista: RAG solo puede manejar partes, no puede entender el todo.
Puede decirte que la quinta nota menciona A, pero no puede decirte la lógica subyacente a la que apuntan estas 500 notas.
Sufre de «desdoblamiento de personalidad»: si hace seis meses creías que A era correcto, pero ayer escribiste una nota refutando A, RAG a menudo cae en contradicciones y produce un montón de tonterías lógicamente confusas.
Gráfico podrido: los enlaces de conocimiento mantenidos manualmente son como código sin limpieza automática. Con el tiempo, los enlaces rotos están por todas partes y la eficiencia de la recuperación disminuye exponencialmente.
La intuición de Karpathy es muy aguda: buscar y recuperar son manifestaciones de la incapacidad humana. Necesitamos «consenso», «estructura», «verdad».
Tratar el conocimiento como código fuente, dejar que el LLM sea el compilador
La respuesta de Karpathy proviene de una acción que un programador hace todos los días, pero nunca pensó aplicarla al conocimiento: compilar.
Escribes un código fuente, no lo relees cada vez que ejecutas el programa.
Lo compilas en un archivo binario. Compilar cuesta mucho una vez, pero cada ejecución posterior es extremadamente rápida. El costo de la compilación se distribuye entre miles de usos posteriores.
¿Por qué el conocimiento no puede funcionar así?
Karpathy dice: trata tus notas originales como código fuente inmodificable, deja que el LLM sea el compilador, y que «compile» de una vez todo ese material desordenado en una Wiki estructurada e interconectada.
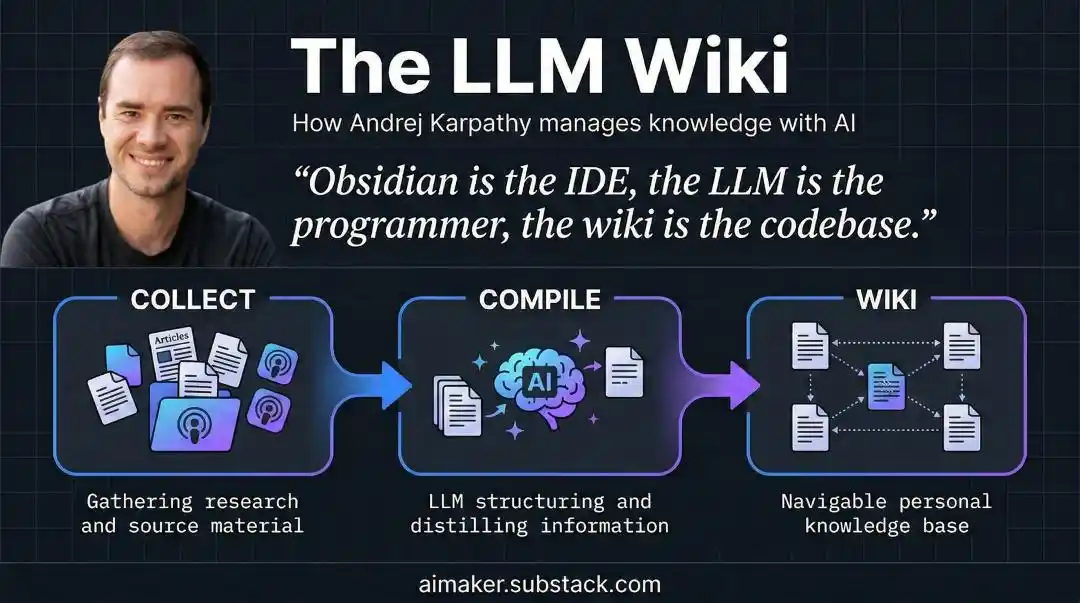
Cada vez que se agrega nuevo material, la IA realiza una fusión: actualiza las páginas de entradas relevantes, revisa las síntesis, marca los lugares donde los nuevos datos contradicen las conclusiones antiguas, y fortalece o desafía los juicios existentes.
La diferencia clave está aquí: el conocimiento se compila una vez y luego se mantiene fresco continuamente, en lugar de reconstruirse temporalmente en cada consulta.
Cuando llegues con una pregunta, las referencias cruzadas ya estarán allí, las contradicciones ya habrán sido marcadas, las síntesis ya reflejarán todo lo que has leído.
No vuelves a compilar el código fuente cada vez que ejecutas el programa. Entonces, ¿por qué hacer que la IA relea todas tus notas cada vez que haces una pregunta?
La transferencia fundamental de la relación de producción cognitiva
En su framework LLM-WIKI, las notas ya no son texto muerto, sino «código fuente».
El modelo grande ya no es un traductor que busca en el diccionario, sino el «compilador».
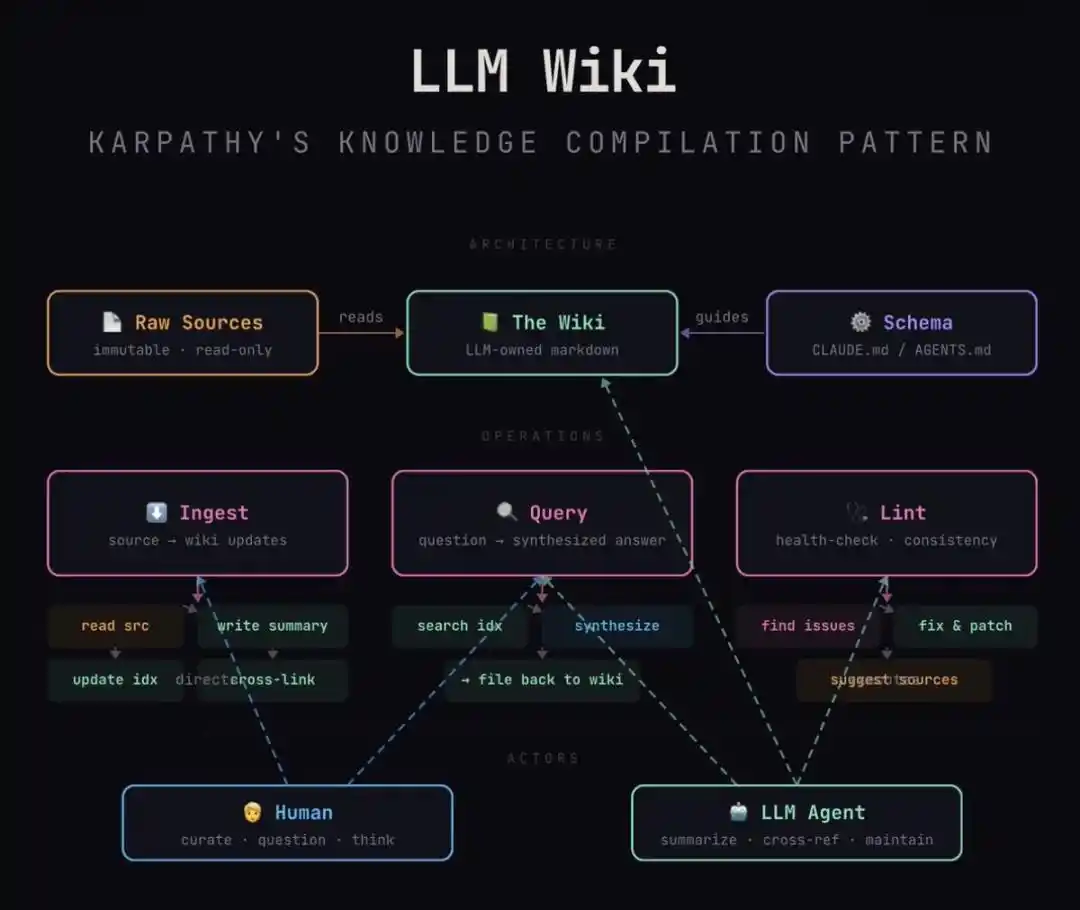
Esta arquitectura logra ingeniosamente un desacoplamiento en tres capas:
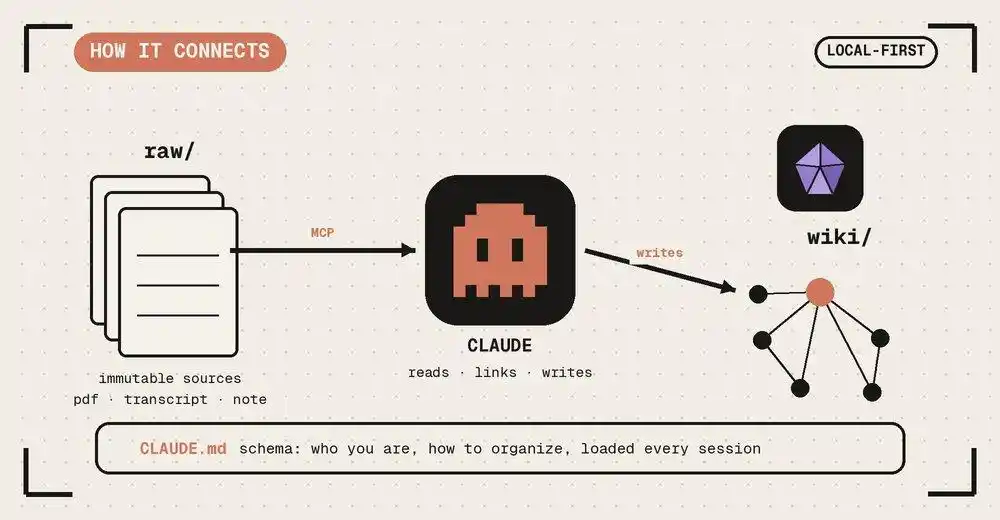
1. Capa Raw (Material crudo): Este es tu mina de inspiración original. Las ideas que anotas al azar, los artículos recortados, las actas de reuniones. Es «inmutable», manteniendo la crudeza y desorden original de la entrada humana.
2. Capa Schema (Constitución del conocimiento): Estas son las «reglas» que le das a la IA. Por ejemplo, especificas: cada entrada de persona debe contener «motivación, limitaciones, logros clave»; cada stack tecnológico debe explicar «ventajas y desventajas».
3. Capa Wiki (Producto compilado): Esta es el área mantenida completamente por la IA. Según tu Schema, compila ese montón de Raw desordenado en páginas de enciclopedia estructuradas, con enlaces cruzados y lógicamente coherentes.
La rutina consta de tres acciones:
1. Ingesta: Lanza un nuevo material, la IA lo lee, repasa los puntos clave contigo, escribe un resumen, barre toda la base de datos actualizando las páginas relacionadas —una sola fuente puede afectar a una docena de páginas.
2. Consulta: Pregunta directamente a la Wiki compilada, responde con citas. Lo más ingenioso: las buenas respuestas pueden archivarse directamente como nuevas páginas, cada exploración también genera interés compuesto.
3. Lint (Revisión): Periódicamente, haz que la IA se autoinspeccione como en una revisión de código — busca contradicciones, afirmaciones obsoletas, páginas aisladas sin enlaces, lagunas que llenar. Límpialo temprano, no dejes que la base se pudra al crecer.
Ya no eres el transportista del conocimiento, sino el arquitecto de este imperio de sabiduría.
Solo te encargas de la entrada y la revisión final, la IA se encarga de todo el «trabajo pesado»: organizar, alinear, enlazar cruzadamente, detectar contradicciones.
Esta es la transferencia fundamental de la relación de producción cognitiva.
No es otro chatbot. ChatGPT conoce internet, LLM-Wiki te conoce a ti —o más precisamente, lo que le has enseñado.
Cada respuesta viene con [wiki-links] que te llevan de vuelta a tu gráfico de conocimiento. Cada respuesta es el inicio de una ruta de exploración, no el final.
Un invento con 80 años de retraso
Hasta aquí, podrías pensar que esto es solo un flujo de trabajo inteligente.
Es más que eso.
Al final del gist, Karpathy menciona ligeramente un nombre: Vannevar Bush, y su artículo de 1945 «As We May Think».

En 1945, justo después de la Segunda Guerra Mundial, este destacado científico estadounidense imaginó una máquina llamada «Memex»:
Un escritorio mecánico que podía almacenar todos tus libros, registros, correspondencia, y establecer «senderos asociativos» entre entradas relevantes — las conexiones entre documentos eran tan valiosas como los documentos mismos.
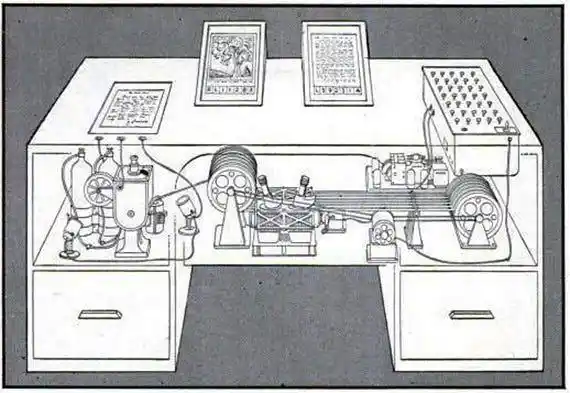
¿Suena familiar? Es casi una descripción palabra por palabra de LLM-Wiki.
La visión de Bush, de hecho, se acerca más a esto que a la posterior World Wide Web: una red de conocimiento privada, curada personalmente, donde la conexión es el valor.

¿Por qué Memex no se construyó en ochenta años?
Porque Bush se atascó en un problema que no pudo resolver —¿quién lo mantiene?
Cada sendero asociativo tenía que establecerse manualmente. Cada referencia cruzada tenía que ser enlazada por alguien.
Bush imaginaba «operadores» especializados que trazaran caminos en el conocimiento para ti.
Pero la realidad es que nadie puede persistir en hacer esta tarea aburrida y pesada a gran escala. Los humanos abandonarían el mantenimiento porque su costo siempre crece más rápido que el valor que aporta.
Esta frase de Karpathy es la clave de todo el paradigma: la parte más agotadora de mantener una base de conocimiento nunca es leer, es llevar las cuentas.
Actualizar referencias cruzadas, mantener frescos los resúmenes, marcar conflictos entre datos nuevos y conclusiones antiguas, mantener la coherencia entre docenas de páginas. Esta monotonía es suficiente para disuadir a cualquiera.
Y un modelo grande no olvidará actualizar una referencia cruzada, puede modificar 15 archivos de una vez.
No se cansa. No se aburre. No se agota por las noches. El costo de mantenimiento se reduce a casi cero.
Así, la máquina que detuvo a la humanidad durante ochenta años, de repente, empieza a funcionar.
Lo que se libera es la atención humana
Mirando atrás, LLM-Wiki es la tercera pieza del rompecabezas de Karpathy sobre «colaboración humano-máquina», y también la más sobria.
Primera pieza, Vibe Coding (febrero 2025): aceptar el código escrito por la IA, no revisarlo línea por línea, confiar en el modelo, probar los resultados.
Segunda pieza, Ingeniería Agéntica (enero 2026): los humanos orquestan agentes de IA, en lugar de escribir código ellos mismos.
Tercera pieza, Bases de Conocimiento LLM (abril 2026): lo que la IA gestiona ya no es solo código, sino el conocimiento mismo.
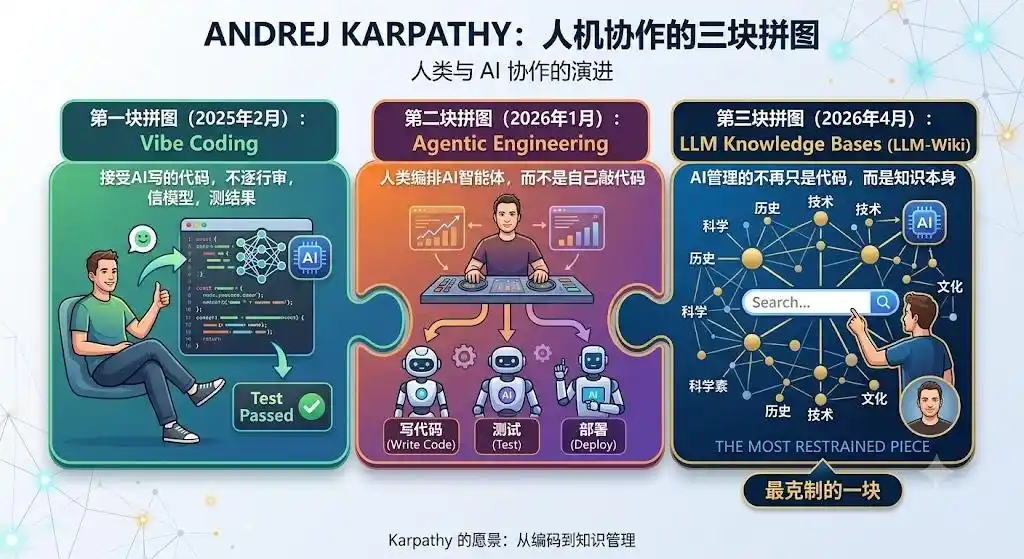
En este nuevo paradigma, a los humanos se les quita el trabajo pesado que a nadie le gusta hacer: guardar, organizar, enlazar, llevar cuentas.
A los humanos solo les quedan dos cosas: decidir qué leer y, pensar claramente qué significa todo esto. Precisamente las dos cosas que las máquinas aún no pueden hacer por ti, y que menos deberían hacer.
Esta es la historia de una herramienta que evoluciona hasta el extremo y, finalmente, da la vuelta para devolverle la atención al ser humano.
Ese sencillo y casi descarado archivo markdown, no publicó un modelo, no encabezó listas.
Solo recordó silenciosamente: tu cerebro nunca debió usarse para llevar cuentas.
Este artículo proviene del WeChat public account "New Zhiyuan", autor: ASI Apocalipsis







