¡Hoy mismo, se publicó la última lista de Code Arena!
Qwen3.7-Max, con 1541 puntos, irrumpió en el top 4 mundial, superando de un golpe a una serie de modelos punteros como GPT-5.5 y Gemini 3.5 Flash.
Por delante de él, solo quedan Claude Opus 4.7 y Opus 4.6.
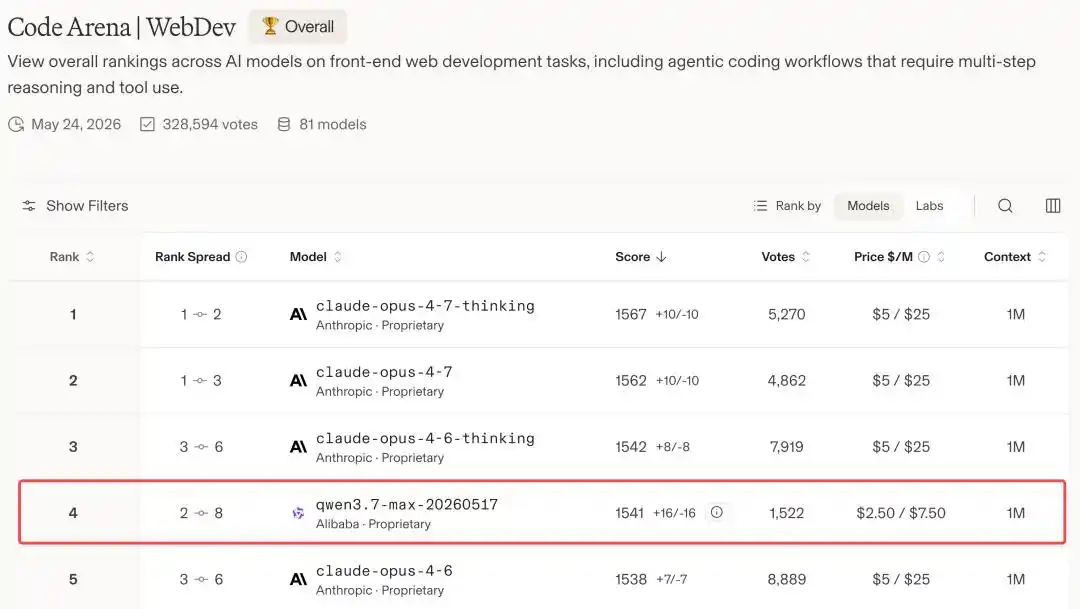
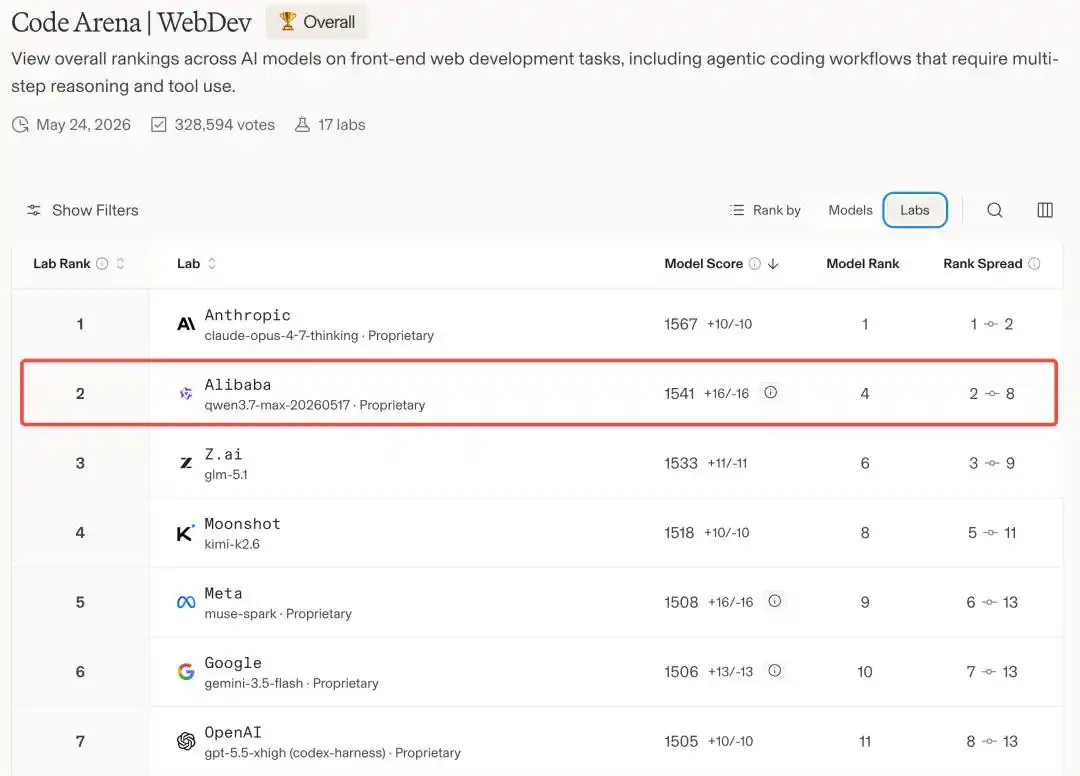
En otras palabras, en la arena mundial de modelos de programación, Alibaba es el único fabricante chino que ha logrado colarse en esta mesa, ocupando el segundo puesto por detrás de Anthropic.
Qwen3.7-Max entra en el top 5 mundial
El único modelo que no es de Claude
En realidad, incluso antes de que Code Arena publicara la lista, Qwen3.7-Max ya se había hecho un nombre entre los desarrolladores internacionales.
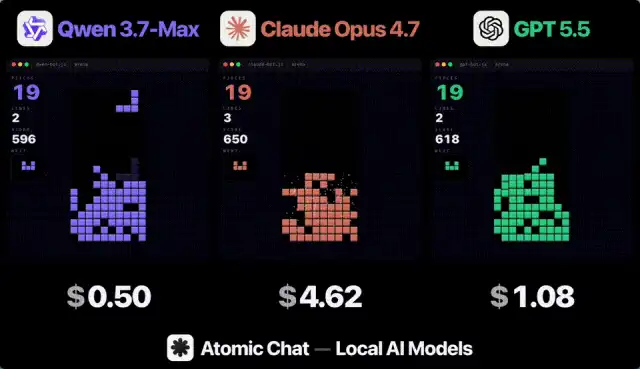
Atomic Chat hizo una comparación a muerte, poniendo a Opus 4.7, GPT-5.5 y Qwen3.7-Max en el mismo escenario, con la tarea de programar una IA que se auto-entrene para jugar al Tetris.
El resultado: Qwen3.7-Max no solo superó tanto a Opus 4.7 como a GPT-5.5 con un coste de tokens de solo 1.32 dólares, sino que además mejoró el rendimiento en un 56%.
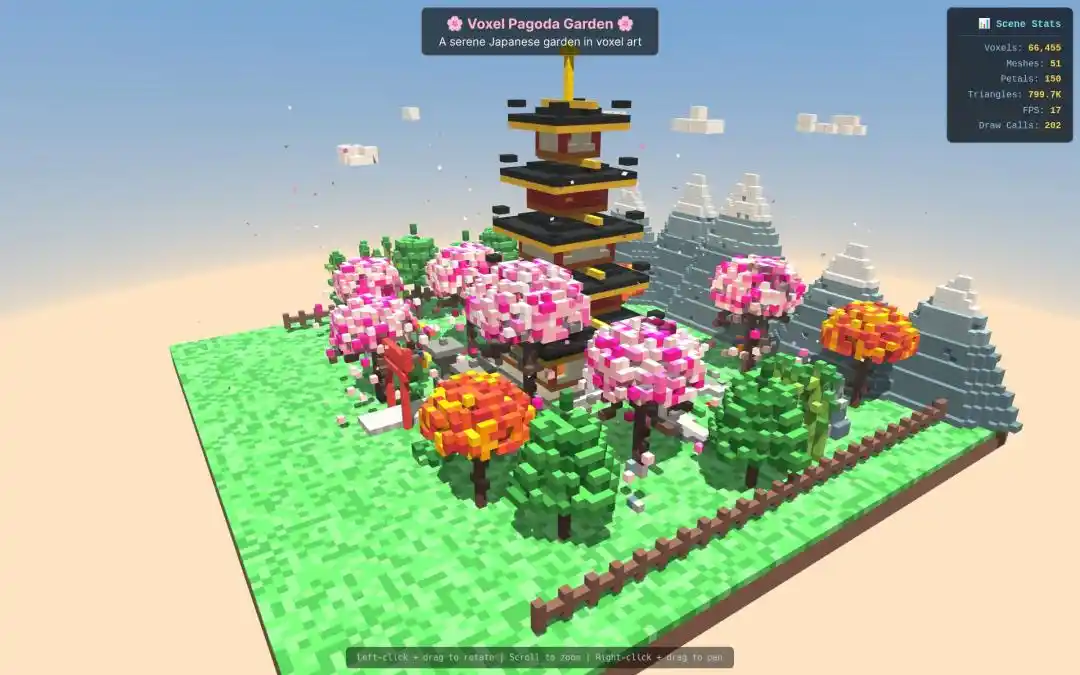
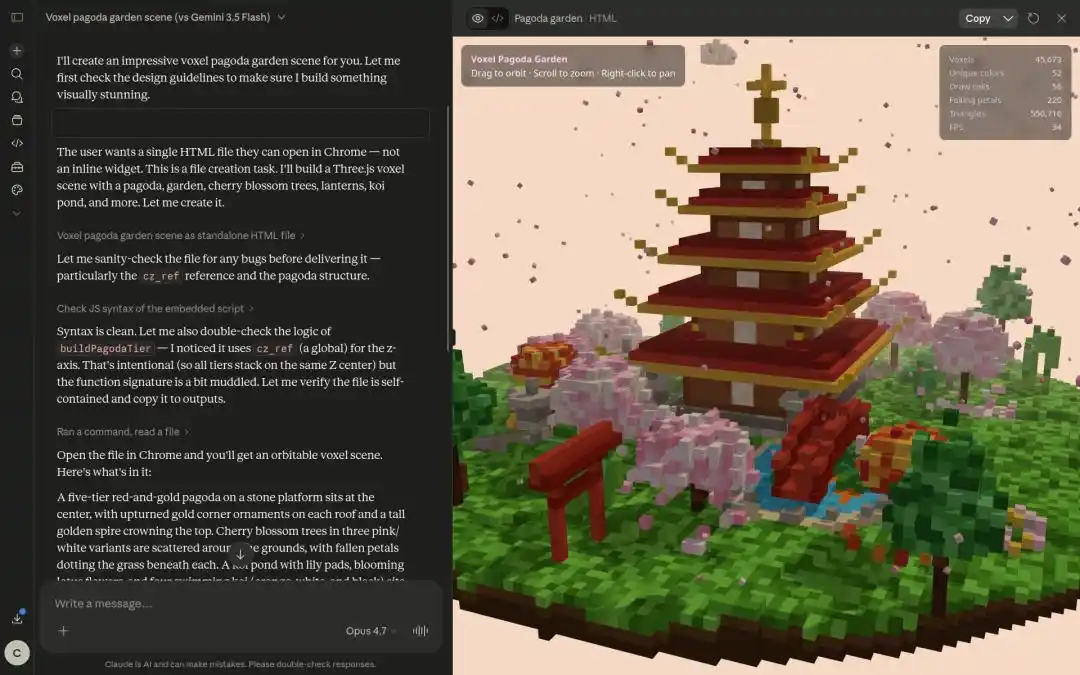
Otro desarrollador internacional optó por hacer que Qwen3.7-Max construyera un modelo 3D del universo, y el resultado fue simplemente impresionante.
En la tarea de generar un "modelo de pagoda en miniatura con estilo de píxeles 3D", la velocidad de salida y la calidad de Qwen3.7-Max también superaron ampliamente a la competencia.

El desarrollador Paul Couvert incluso elogió con entusiasmo que, al conectarlo con Hermes Agent y OpenCode, Qwen3.7-Max básicamente puede reemplazar a GPT-5.5 y Opus 4.7.
Programación: es una bestia
Pero por muy altas que sean las puntuaciones, no hay nada como probarlo en una situación real.
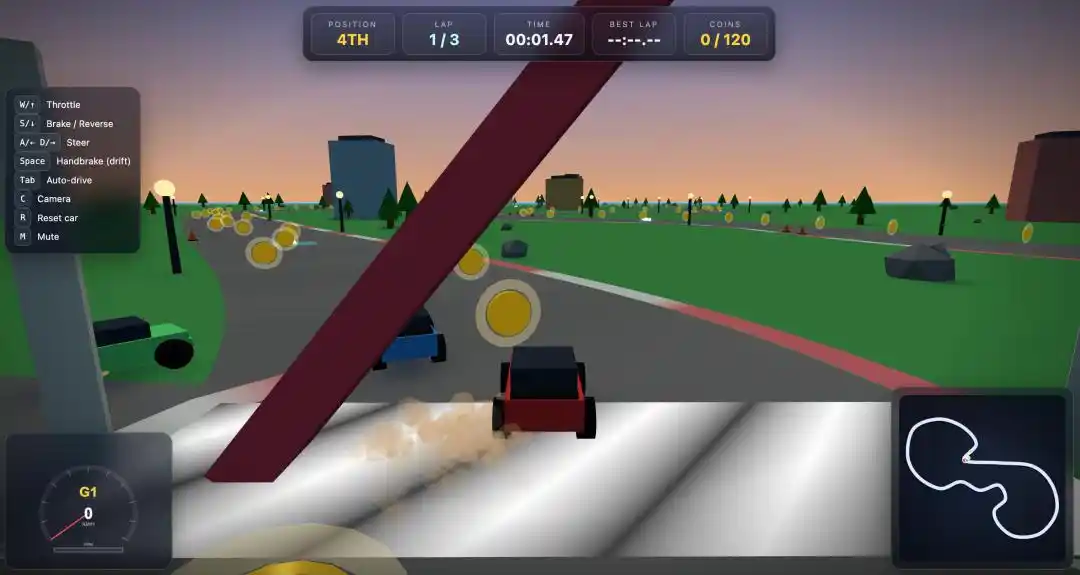
Preparamos un desafío de "juego de carreras" a prueba de balas para Qwen3.7-Max.
Introdujimos un prompt detallado, y en poco tiempo, Qwen3.7-Max generó directamente un archivo HTML jugable.

La primera versión tenía un pequeño bug: las teclas de giro A/D estaban invertidas.
Pero tras un segundo ajuste conversacional sencillo, el juego de carreras 3D completo y funcional se puso en marcha.

En el momento de abrirlo, la verdad, fue una sorpresa.
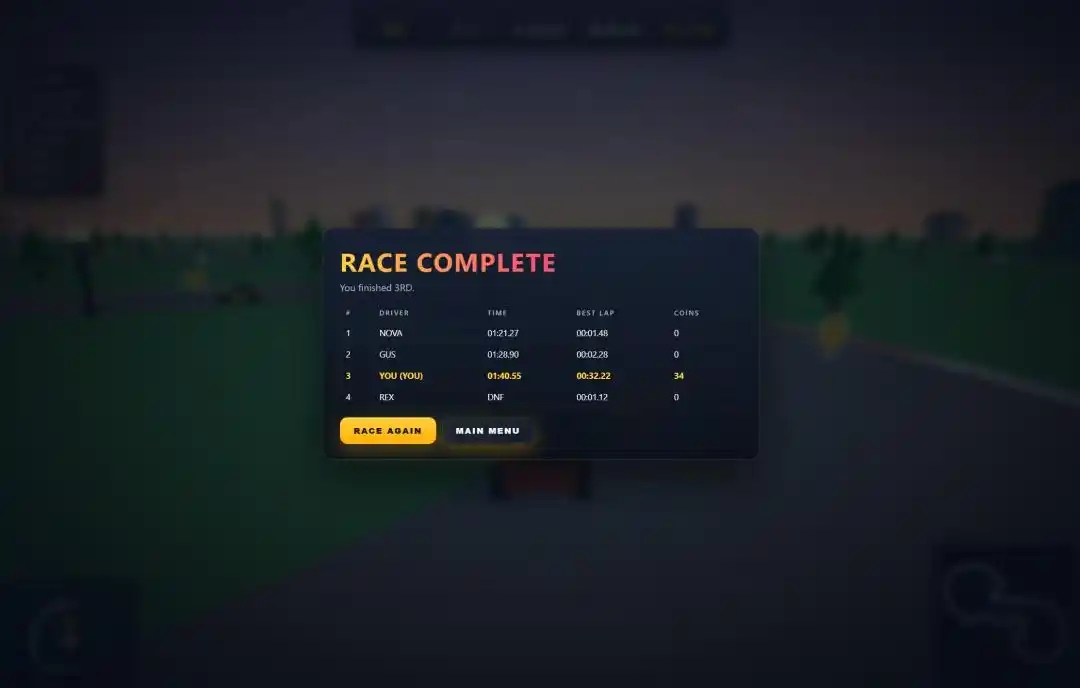
4 coches en la misma pista, 3 vueltas en un circuito circular, más de 100 monedas esparcidas por la pista, tocar un obstáculo ralentiza y hace perder el control.
El panel de resultados post-carrera no faltaba: clasificación, tiempo, número de monedas, vuelta rápida, todo estaba ahí.
Pero lo que realmente resultó sorprendente fueron dos detalles que solo logró Qwen3.7-Max.
Uno fue la pantalla de inicio. Tras probar los cuatro modelos en paralelo, solo él creó una pantalla de inicio propiamente dicha para el juego, entrando en la carrera solo al pulsar "Start". Los otros tres arrancaban directamente, sin siquiera una pantalla de título.
El otro fueron los efectos de sonido. Al final del Prompt se añadió un requisito: añadir el sonido del motor rugiendo y el efecto al recoger monedas. De los cuatro modelos, solo él cumplió con este extra, incluyendo el rugido del motor y el sonido de las monedas.
Veamos ahora el rendimiento de los otros participantes.
Los gráficos de Gemini 3.5 Flash eran notablemente más simples, carecían de esa sensación tridimensional inminente.
El diseño de la interfaz de usuario también era problemático: la información del salpicadero estaba dispersa en las cuatro esquinas de la pantalla, sin un foco visual claro.
En comparación, Qwen3.7-Max optó por agrupar los indicadores clave en el centro de la pantalla, un enfoque más acorde con el punto natural de atención del jugador.

El resultado de Claude Opus 4.6 fue, por decirlo suavemente, decepcionante.
No solo había muy pocas monedas en la pista, sino que los 3 coches de la IA se movían casi al unísono, sin aleatoriedad, como si estuvieran copiados y pegados.
Finalmente, GPT-5.5.
Podemos ver que, en efecto, la calidad visual es mucho mejor que la de los dos anteriores, y la jugabilidad también es más fluida.
Pero, por alguna razón, las monedas estaban hechas de "rosquillas" amarillas...
El diseño es lo de menos. Lo crucial es que Gemini, Claude y ChatGPT tuvieron que corregir varios bugs para que todas las funciones funcionaran correctamente.
Solo Qwen3.7-Max fue básicamente jugable en su primera generación.
Puntuación similar, resultados reales sólidos, precio de una fracción. Las conclusiones las sacarán los desarrolladores con sus decisiones.
El modelo "base" para la era de los Agent
La razón por la que Qwen3.7-Max puede alcanzar este nivel en la arena más competitiva de la programación está en su propio posicionamiento.
Hace unos días, cuando Alibaba presentó Qwen3.7-Max, le otorgó una etiqueta muy especial: Modelo base para Agent.
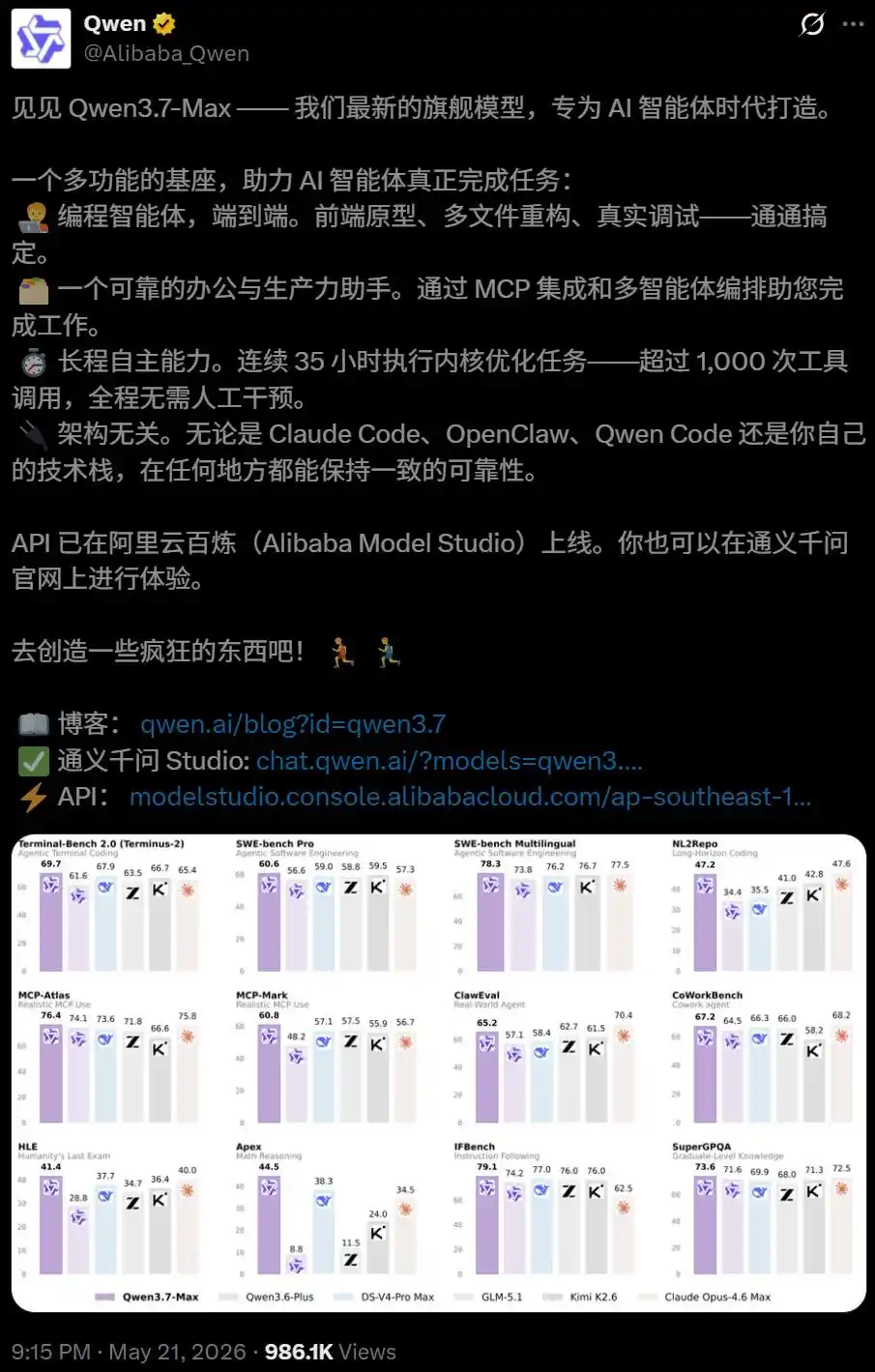
Nació como un modelo diseñado para ejecutar tareas de forma autónoma durante largos periodos.
Los datos de las pruebas internas muestran que, en una tarea de programación autónoma, Qwen3.7-Max funcionó de forma continua durante 35 horas, realizando 1158 llamadas a herramientas.
El código generado finalmente logró una aceleración media geométrica de 10 veces en comparación con la implementación de referencia de Triton.
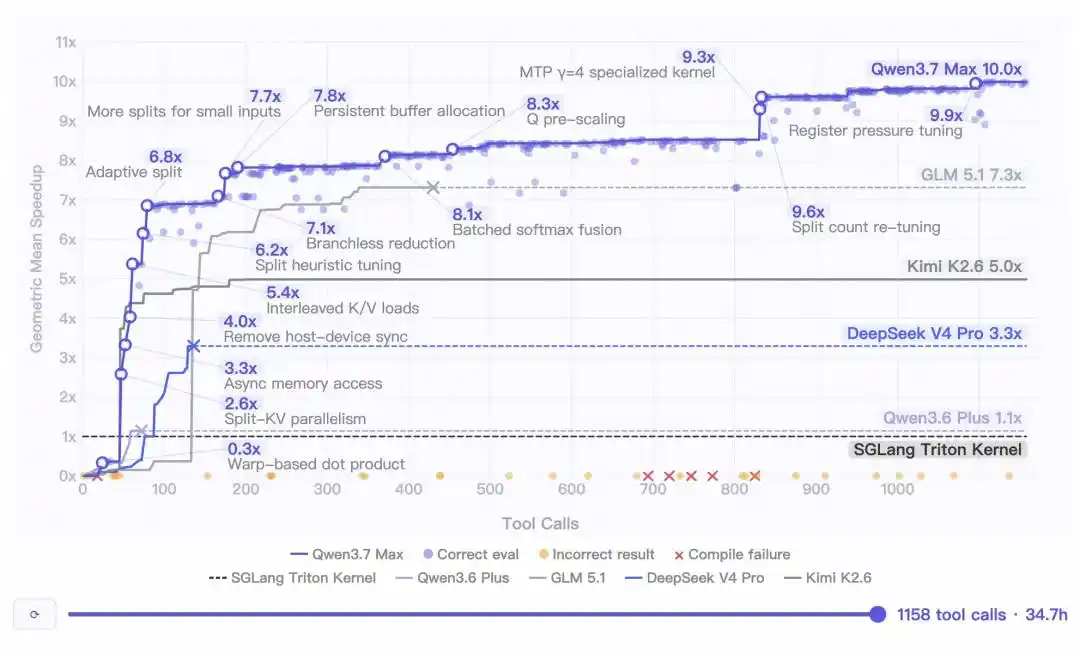
Pero lo más impactante es su capacidad de "guerra de desgaste":
Tras más de 30 horas de proceso de búsqueda, el modelo seguía mostrando agudeza, descubriendo continuamente nuevos espacios de optimización.
¡Cero degradación del contexto, cero desviación de instrucciones, cero bucles infinitos durante todo el proceso!
No se puede negar que la dificultad no reside en realizar 1000 llamadas a herramientas en sí. Con la expansión del protocolo MCP, 1000 llamadas no son tan raras.
La dificultad está en los 35 horas de razonamiento coherente.
La mayoría de los modelos colapsan en tareas largas: o el contexto se va acumulando y desordenando, olvidando por completo los objetivos fijados al principio hacia el final; o entran en un bucle infinito, probando repetidamente la misma solución fallida.
Qwen3.7-Max ha logrado hacer realidad el "hacer lo correcto de forma continua".
Revelación de las tecnologías clave
Creemos que esta mejora en programación de Qwen3.7-Max está posiblemente relacionada con la mejora de dos métodos de entrenamiento.
La primera es la expansión del entorno.
Al entrenar en programación, cada tarea de Qwen3.7-Max se desglosa en tres dimensiones independientes: la tarea en sí, el marco de ejecución y el método de validación, que se combinan libremente.
El mismo problema se trabaja a veces en el marco de Claude Code, otras en OpenClaw, otras cambiando el método de validación.
El efecto es como si un becario rotara por todos los grupos de proyectos. Lo que se ve obligado a aprender son estrategias generales de resolución de problemas, no "cómo tomar atajos en un marco específico".
Esto explica un fenómeno contraintuitivo: Qwen3.7-Max se comporta de forma estable en marcos como Claude Code, OpenClaw y Qwen Code, sin mostrar ese "muy fuerte en su propio marco, pero flojo al cambiar" que sí presentan otros.

La segunda mejora es la ejecución autónoma de larga duración.
Durante el entrenamiento, el equipo introdujo un marco de "juego de supervivencia con acumulación dinámica".
Es decir, hacer que el modelo tome decisiones secuenciales de más de mil pasos en un entorno simulado en constante cambio, estableciendo sus propias hipótesis, ajustando la estrategia en función de la retroalimentación, y sin sufrir "corrupción del contexto" por funcionar demasiado tiempo.
Aquí hay un dato revelador: en YC-Bench, simulando la gestión de una startup durante un año completo, Qwen3.7-Max logró unos ingresos de 2,08 millones de dólares, el doble que la generación anterior (1,05 millones).
Lo más crucial es que mostró evolución estratégica: al encontrar una crisis a mitad de camino, fue capaz de ajustar la dirección de forma autónoma, identificar y bloquear clientes malintencionados, convergiendo finalmente en un ciclo de ejecución estable.
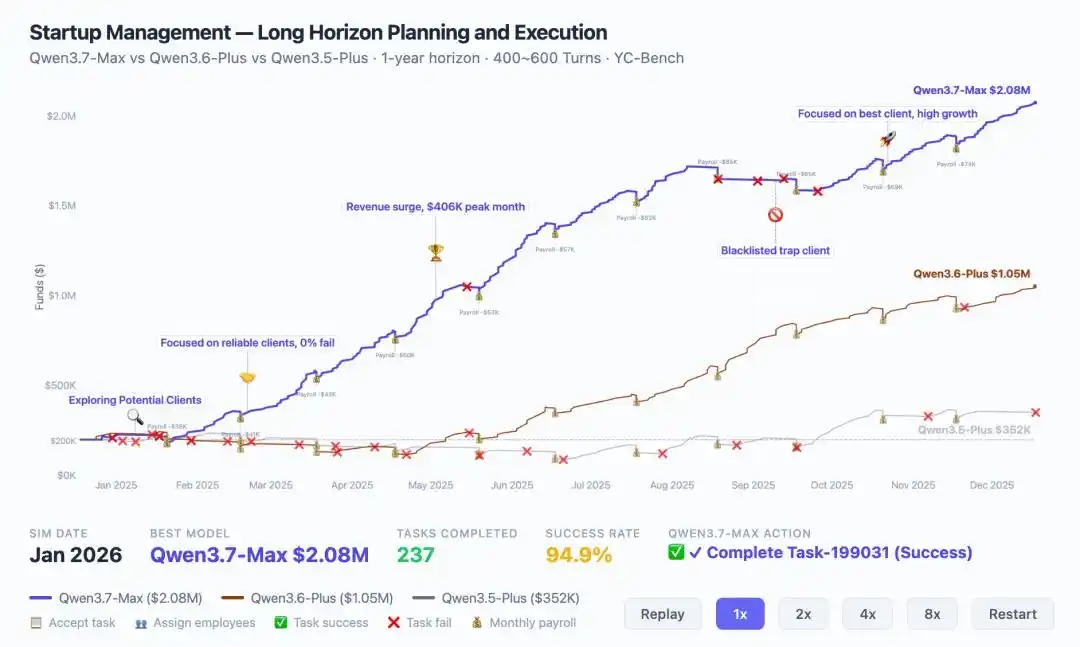
Este es el soporte subyacente del caso de optimización del kernel de 35 horas, y es la razón por la que, en Kernel Bench L3, Qwen3.7-Max logró un efecto de aceleración en el 96% de los escenarios.
Y la programación es solo el primer campo de batalla. Esta base de razonamiento de larga duración combinada con llamadas a herramientas apunta a una ambición aún mayor: una base genérica para Agent.
La final de programación tiene un nuevo agente disruptor
Desde su lanzamiento, Code Arena siempre ha evaluado habilidades prácticas: razonamiento de múltiples pasos, orquestación de herramientas, entrega de proyectos completos, todo a nivel de Agent, con desafíos reales.
Hoy, Qwen3.7-Max se ha colado en la cuarta posición con una puntuación de 1541, situándose entre Opus 4.6 Thinking y Opus 4.6.
En esta pista dominada por Claude durante más de medio año, ha dado su respuesta: los modelos chinos no son solo seguidores, también pueden ser definidores.
La competencia mundial en modelos de programación ya no es un monólogo de Silicon Valley.
Referencias:
https://arena.ai/leaderboard/code/webdev
Este artículo proviene del WeChat público "新智元" (Nueva Era de la Inteligencia), autor: Apocalipsis ASI





