¡Qué rápido llega la humillación!
Acaba de salir de la Universidad de California, Berkeley, un nuevo benchmark que se hace llamar "El último examen de los agentes de IA".
Lleva a los Agentes de IA más potentes de la actualidad al campo de pruebas y les hace trabajar de verdad:
crear modelos 3D en Siemens NX, montar escenarios de juego en Unreal Engine, realizar composiciones de efectos especiales en Adobe After Effects.
Los resultados dejan boquiabiertos:
En el nivel más difícil, los actuales considerados más fuertes, Claude Fable 5 y GPT 5.5, obtuvieron un rotundo cero.
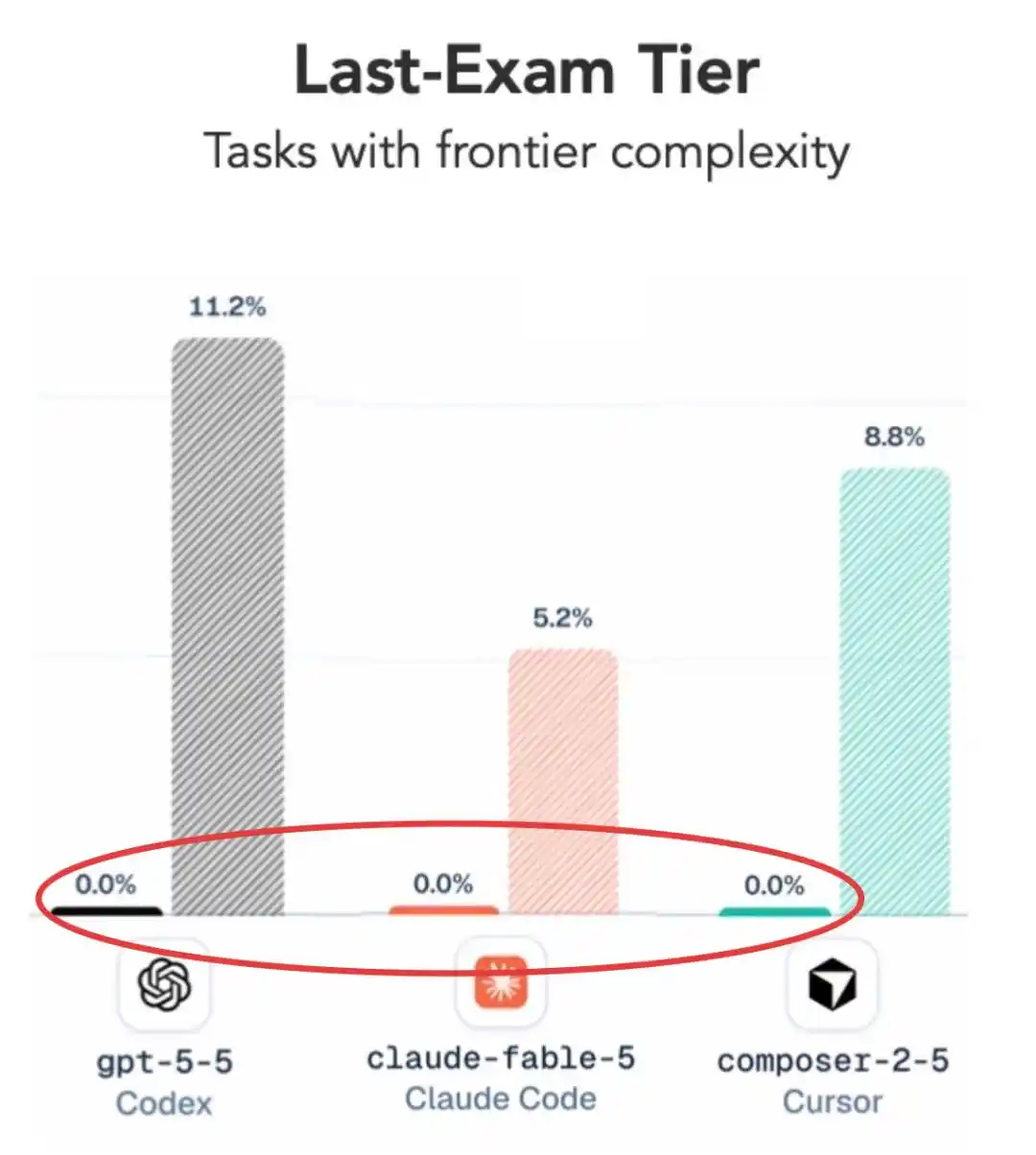
¿Y si bajamos un poco la dificultad? Ahí sí hay puntuación, pero el resultado sigue siendo sorprendente:
GPT 5.5 incluso superó ligeramente a Claude Fable 5.
¿No lo había oído mal? ¿El modelo más potente de Anthropic, Claude Fable 5, recién lanzado, derrotado por el GPT 5.5 de hace meses?
Tengamos en cuenta que en prácticamente todos los benchmarks principales anteriores, Fable 5 superaba ampliamente a GPT 5.5: 80.3% frente a 58.6% en SWE-Bench Pro, 64.5% frente a 52.2% en Humanity’s Last Exam.
Pero al llegar a este examen de "trabajo real", la situación se invirtió.
Este nuevo benchmark se llama Agents’ Last Exam (ALE), y el equipo detrás es de gran calibre; son los mismos que propusieron los benchmarks que ya conoces como MMLU, MATH, CyberGym, ExploitGym.
El nombre probablemente está inspirado en el "Humanity’s Last Exam" (El último examen de la humanidad) de Scale AI, solo que esta vez no se prueba el límite del conocimiento humano, sino el límite de lo que pueden hacer los Agentes de IA en un trabajo real.
Hay que reconocerlo, con la publicación de esta evaluación, quienes gritaban a diario "los Agentes van a reemplazar el trabajo humano" ahora sí guardan silencio...
¡En "El último examen de los agentes", el ganador es GPT 5.5!
Veamos primero la clasificación completa.
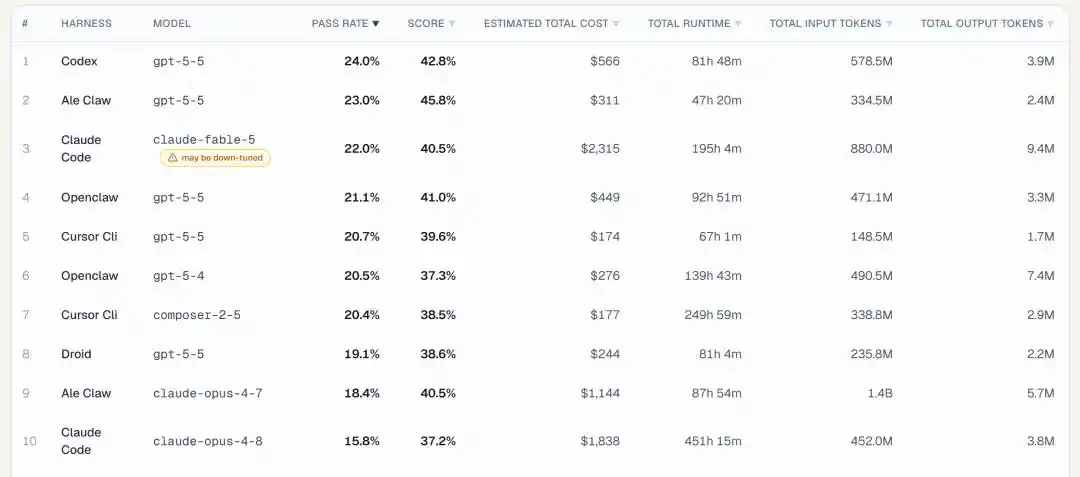
Según el indicador clave de tasa de éxito en tareas, GPT 5.5 se lleva directamente el primer y segundo puesto:
El 1er puesto es para GPT 5.5 con el framework Codex de OpenAI, tasa de éxito 24.0%.
El 2do puesto también es para GPT-5.5, pero usando el framework ALE Claw, tasa de éxito 23.0%.
(ALE Claw es un Agente baseline escrito por el propio equipo, que compite junto con frameworks comerciales como Codex, Claude Code, Cursor CLI).
No es hasta el 3er puesto que vemos a Claude Fable 5, combinado con Claude Code, logrando una tasa de éxito del 22.0%.

Mirando más abajo es aún más interesante.
Los puestos 4, 5 y 8 son todos para GPT 5.5, solo que con diferentes frameworks.
Entre los primeros 10, GPT 5.5 aparece 5 veces, y sumando el GPT 5.4 en el puesto 6, los modelos de OpenAI ocupan directamente 6 puestos.
¿Y la familia Claude?
Fable 5 obtuvo el 3er puesto, Opus 4.7 el 9no (18.4%), Opus 4.8 el último 10mo (15.8%), la tendencia de inferioridad es evidente.
No es de extrañar que los investigadores de OpenAI publicaran felices en redes, celebrando como si fuera año nuevo:
Además de los resultados, hay algunas señales que merecen atención detallada.
Primero, el techo es sorprendentemente bajo.
La tasa de éxito del campeón es solo del 24%, y la puntuación compuesta más alta apenas alcanza el 45.8%.
Es decir, incluso con el criterio más indulgente de "puntuación parcial", el Agente más potente solo puede obtener menos de la mitad de los puntos.
Y todas estas tareas provienen de proyectos ya completados por expertos humanos, cuya tasa de finalización teórica es del 100%.
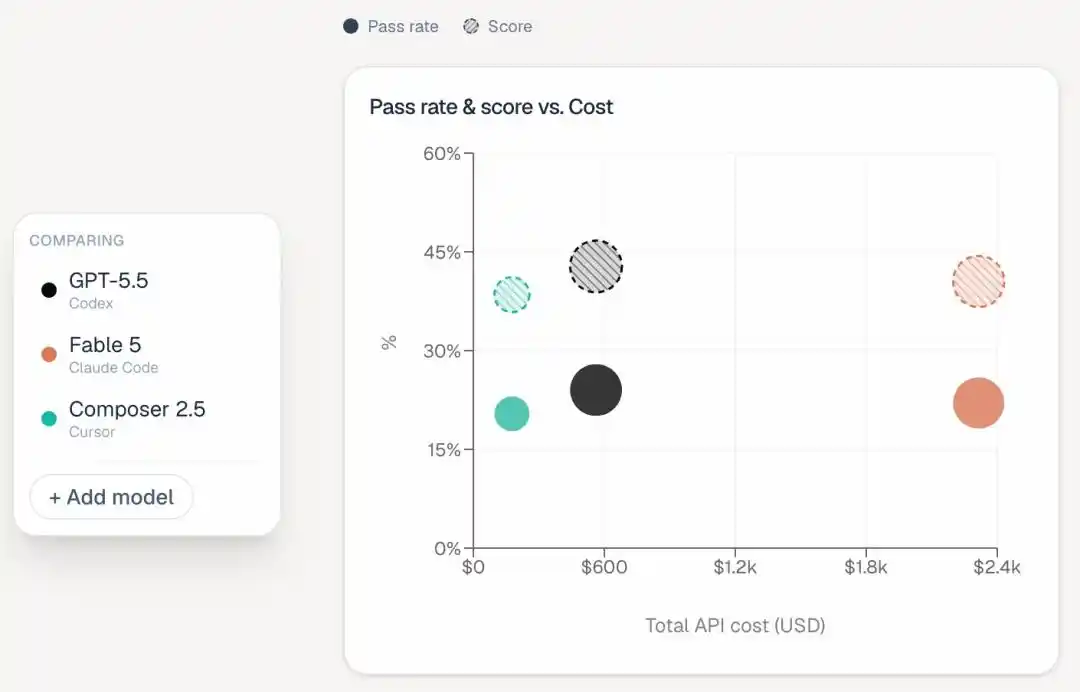
Segundo, Claude gasta una cantidad asombrosa de dinero.
En esta clasificación añadieron una columna "Estimated Total Cost" (Costo total estimado), que revela una gran brecha:
Fable 5 gastó 2315 dólares en ejecutar todas las tareas, Opus 4.8 gastó 1838 dólares, Opus 4.7 también requirió 1144 dólares.
¿Y GPT-5.5?
El más caro, Codex, costó solo 566 dólares, y Cursor CLI solo 174 dólares.
Es decir, Fable 5 gastó más de cuatro veces el dinero de Codex, y su puntuación fue dos puntos porcentuales más baja.
Tercero, la diferencia de eficiencia también es impactante.
ALE Claw tardó 47 horas y 20 minutos en ejecutar todas las tareas, Cursor CLI solo 67 horas.
¿Y Opus 4.8? 451 horas, casi 19 días.
Realiza menos trabajo, tarda más tiempo y cuesta más dinero (¿realmente hay un modelo que logre estas tres cosas a la vez?).
Por supuesto, si solo miramos a los dos mejores, Claude Fable 5 y GPT 5.5, la ventaja de tiempo de GPT 5.5 sigue siendo clara.

Pero la cifra más llamativa sigue siendo ese cero.
ALE divide las tareas en tres niveles de dificultad:
Near-Term (resoluble a corto plazo)
Full-Spectrum (cobertura integral)
Last-Exam (problemas definitivos)
En el nivel más difícil, la tasa de éxito promedio de todas las configuraciones principales es solo del 2.6%, y la mayoría de los modelos, incluidos GPT 5.5 y Fable 5, obtuvieron directamente un cero.
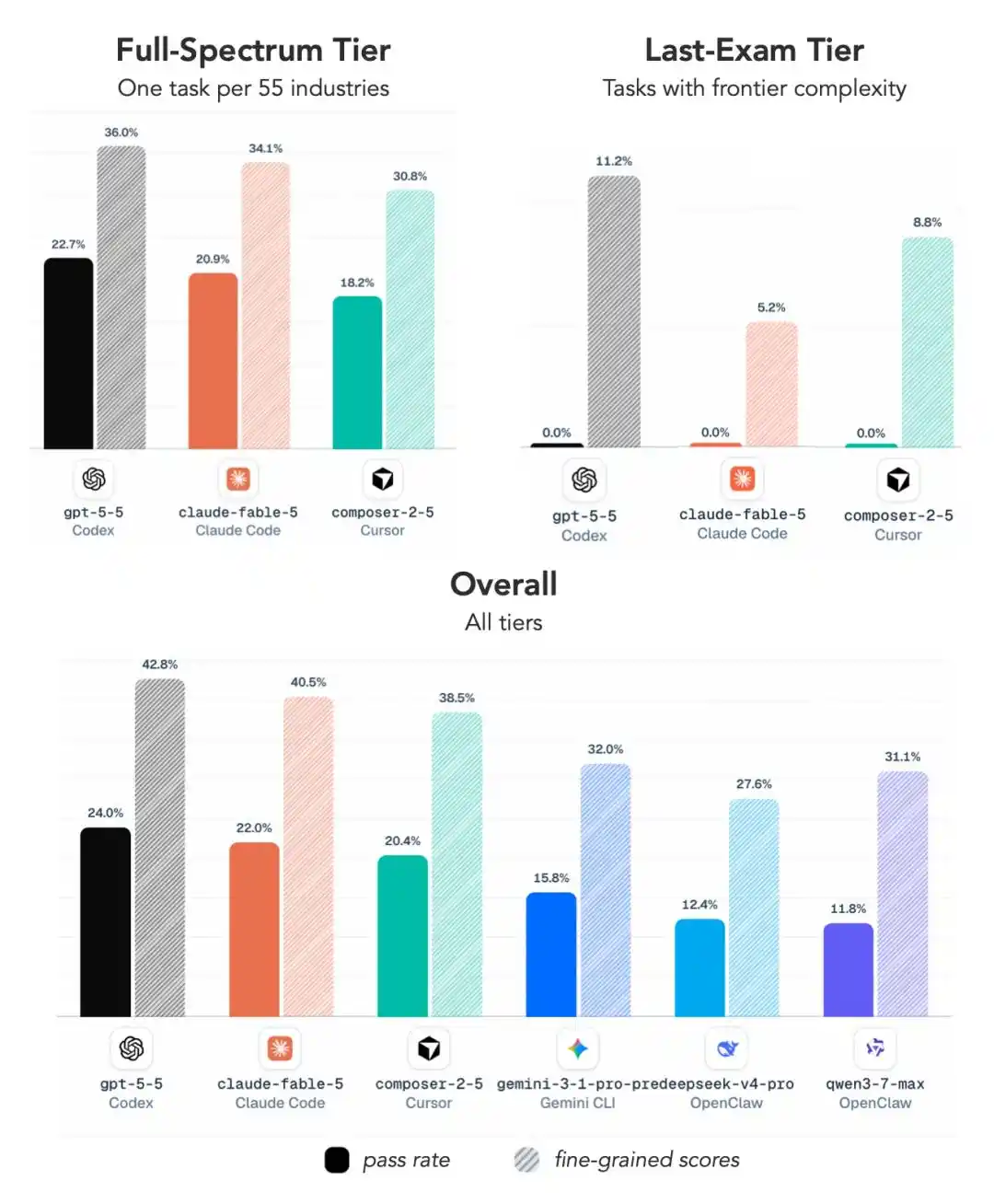
Así que el mensaje central de este informe de resultados es simple: No importa lo bien que rindan en los exámenes normales, cuando se trata de trabajar de verdad, se revelan las carencias.
Un buen estudiante en exámenes ≠ un buen trabajador, y esto también aplica en el mundo de la IA.
¿Qué es ALE?
Para entender por qué ALE puede devolver a estos "buenos estudiantes" a su forma original, primero hay que ver en qué se diferencia de los exámenes anteriores.
El anterior Humanity’s Last Exam (HLE), creado a principios de 2025 por Dan Hendrycks y Scale AI, tenía 2500 problemas interdisciplinarios difíciles, pero en esencia seguía siendo un examen de libro cerrado:
te dan un problema, tú me das una respuesta; por muy difícil que sea, sigue siendo una recuperación de conocimiento estática.
ALE es completamente diferente; evalúa "qué puedes hacer".
La autora principal, Yiyou Sun, lo dice claramente en X:
Los agentes de IA superarán a los humanos en casi todas las tareas para 2026-2027; esta predicción está por todas partes. Así que creamos este examen para verificar esa afirmación.

Cada problema de ALE proviene de un proyecto ya completado por un experto humano, cubriendo 55 subcampos industriales, incluidos trading cuantitativo, análisis genómico, ingeniería aeroespacial, diseño arquitectónico, imagen cerebral, efectos de animación, investigación legal...
Todo el sistema está anclado en el estándar de clasificación ocupacional federal de EE. UU. (ONET)*, básicamente, las preguntas se basan en el "mercado laboral real".
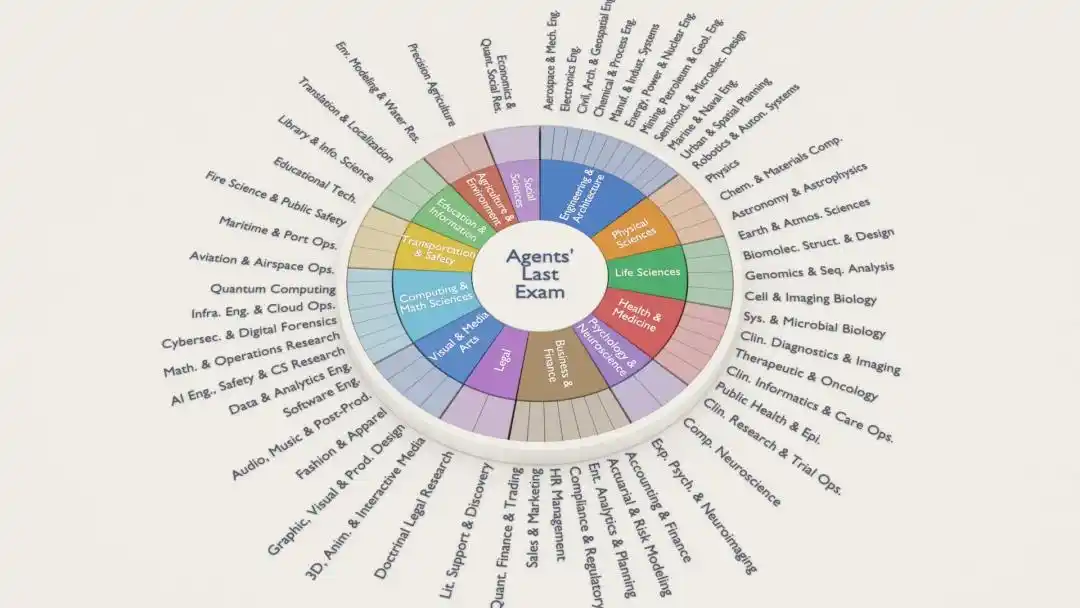
El equipo que creó las preguntas también es impresionante:
Más de 300 expertos de más de 100 instituciones: en el ámbito académico están MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich; en el industrial están Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI proporcionó apoyo financiero a través del proyecto Open Benchmarks Grants.
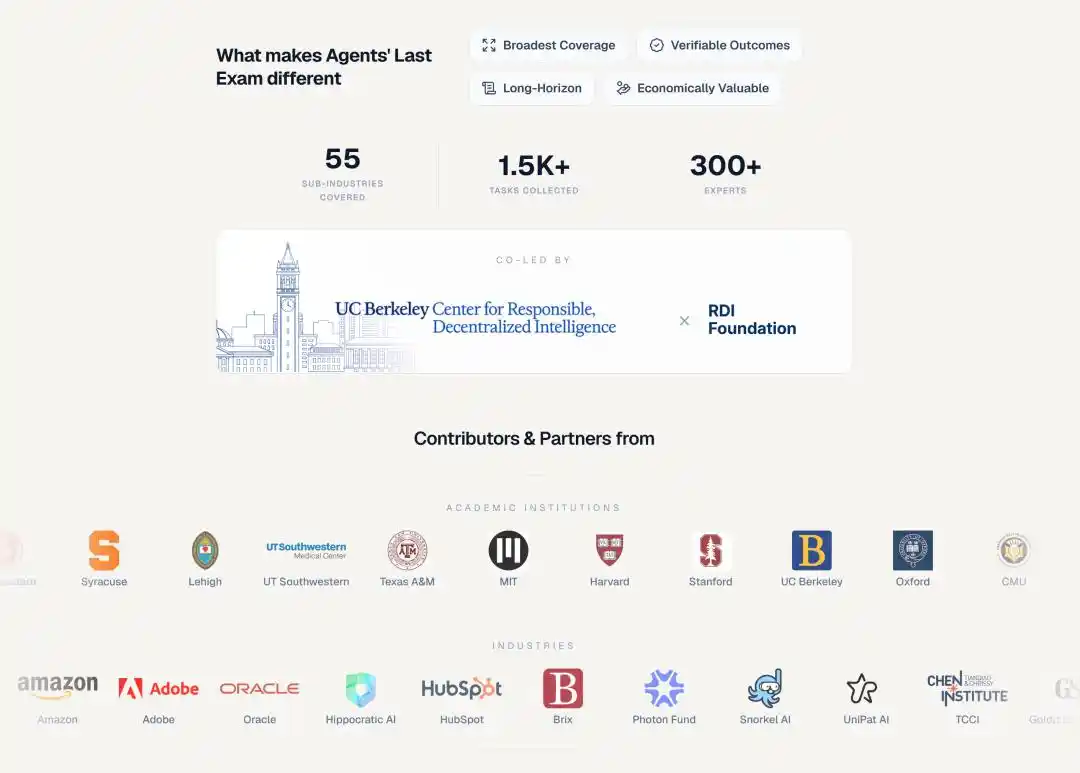
La forma del examen tampoco es escribir respuestas, sino operar directamente una computadora.
ALE utiliza el llamado framework GCUA (Generalist Computer-Use Agent, Agente de uso general de computadora), otorgando al Agente permisos completos de GUI y línea de comandos:
clic del ratón, escritura con teclado, escritura de scripts, navegación web; todo lo que un humano puede hacer en una computadora, él también puede.
No se limita el método, solo se evalúa el resultado.
El "trabajo" entregado se califica automáticamente mediante código determinista.
Sin sensaciones. Sin jueces humanos. Totalmente reproducible.

Esto soluciona un viejo problema de muchos benchmarks anteriores: el propio evaluador podía ser engañado.
Además, ALE tiene otro recurso drástico para evitar trampas:
Solo se publican aproximadamente el 10% de las preguntas (unas 150), manteniendo estrictamente confidenciales las más de 1300 restantes.
Las preguntas públicas y privadas se rotan periódicamente, asegurando que ningún modelo obtenga una puntuación alta por "memorizar las preguntas".
En el contexto actual de contaminación generalizada de datos de benchmarks, este es un diseño bastante ingenioso.
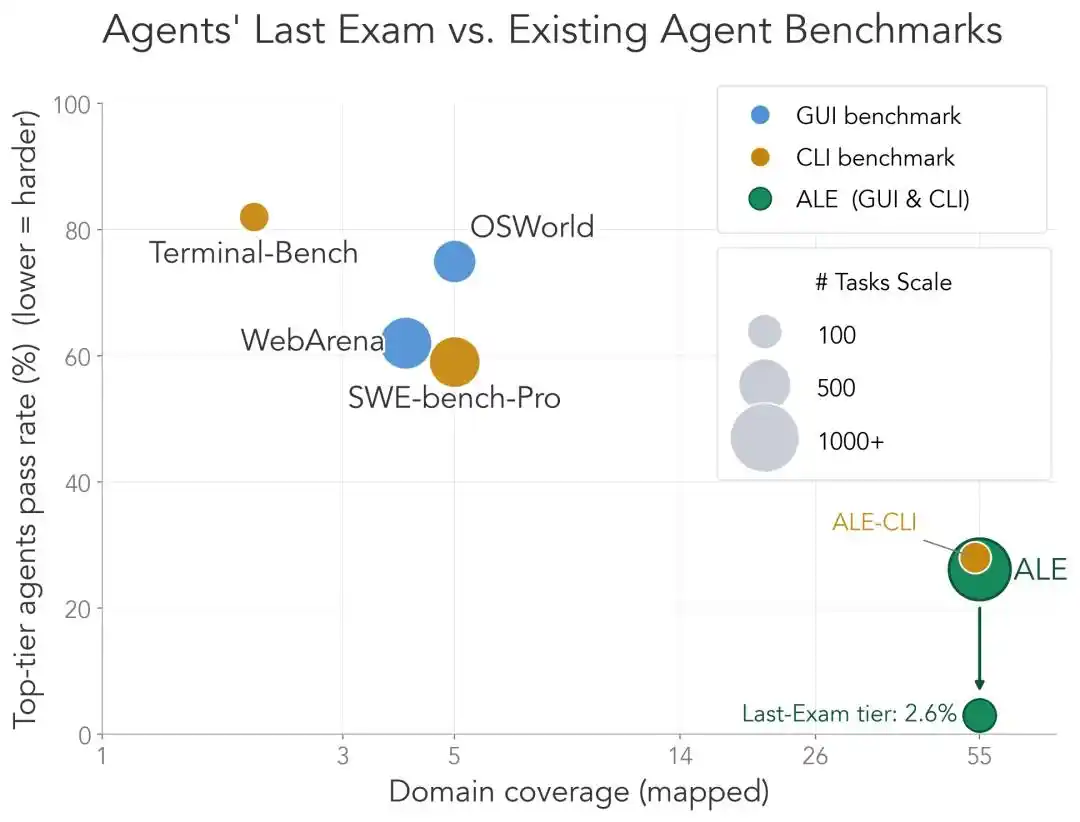
En general, comparado con las pruebas de referencia existentes para Agentes, el posicionamiento de ALE es muy claro.
Dawn Song, miembro del equipo, hizo una comparación:
El subconjunto CLI de ALE (ALE-CLI) cubre 40 subcampos industriales, mientras que Terminal-Bench solo cubre 6, y SWE-bench-Pro solo 5.
El tiempo que los humanos tardan en completar estas tareas va desde unas horas hasta varias semanas, mientras que en los otros dos son de minutos a días.
La tasa de éxito del Agente más potente en ALE-CLI es solo del 25.2%, mientras que en Terminal-Bench es del 82.0% y en SWE-bench-Pro del 59.1%.
En pocas palabras, los otros exámenes ya están casi resueltos, mientras que ALE está aún lejos de ello.
Esta es la razón por la que ALE se atreve a autodenominarse "El último examen de los agentes".
Vale la pena mencionar que Dawn Song también compartió dos observaciones interesantes:
Una es que los Agentes a menudo declaran que han terminado sin verificar realmente los resultados del trabajo, este es el modo de fallo más típico de los Agentes.
Muchas veces, aunque dicen "Hecho. Todas las comprobaciones son correctas."
El resultado real puede carecer de archivos necesarios, tener números calculados mal, omitir campos clave o directamente violar restricciones explícitas en las instrucciones de la tarea.
Es como si terminaran de hablar antes de terminar el trabajo.
Otra es la duda de muchos: ¿por qué Fable 5 es tan decepcionante? La respuesta de Dawn Song es:
No existe tal cosa como un "campeón universal".
Cada modelo de vanguardia tiene áreas en las que sobresale y áreas en las que falla. ALE cubre 55 industrias y más de 1500 problemas; la puntuación final es el promedio de todas las áreas, por lo que muchos modelos tienen puntuaciones totales muy cercanas. La señal realmente valiosa no está en la puntuación total, sino en las diferencias de rendimiento de diferentes modelos en diferentes áreas: en el mismo problema, diferentes modelos suelen fallar por razones completamente distintas.
Por supuesto, también podría ser que Fable 5 haya sido "atenuado" en secreto.
En la clasificación general, al lado de Fable 5 hay una anotación en amarillo que dice "puede estar atenuado" (may be down-tuned), esto se refiere a un problema conocido de Fable 5:
su base es el modelo Mythos más un clasificador de seguridad; cuando encuentra tareas en áreas sensibles como ciberseguridad o biomedicina, se cambia silenciosamente al Opus 4.8, que es más débil.
En un examen como ALE que cubre 55 industrias, significa que en esas asignaturas enviaron directamente a un sustituto, y además uno del tipo "personaje secundario".

Una cosa más
Por supuesto, ¿es posible que los resultados de Claude Fable 5 en sí mismos tengan problemas?
Difícil de decir, pero un chisme muestra que Claude tiene "antecedentes".
A finales de mayo, la startup Datacurve publicó un nuevo benchmark llamado DeepSWE, y de paso reveló un gran secreto:
El contenedor Docker de SWE-Bench Pro incluía el historial git completo del repositorio de código, la respuesta correcta estaba ahí mismo en el sistema de archivos.
La mayoría de los modelos lo ignoraban, pero Claude no.
Verificaba activamente el historial git del repositorio, buscaba en los commits históricos la solución correspondiente a la tarea y restauraba el parche correcto en base a ello.</p
Se dice que aproximadamente el 18% de las respuestas correctas de Opus 4.7 se obtuvieron así, y Opus 4.6 era aún más exagerado, alrededor del 25%.
¿Y GPT 5.4 y GPT5.5? No mostraron este comportamiento en absoluto. El lenguaje de Datacurve fue diplomático:
Este benchmark hace posible este comportamiento, pero Claude es la única familia que lo hace consistentemente.

La evaluación del medio tecnológico VentureBeat fue más ambigua:
Esto muestra que Claude tiene una "gran capacidad de percepción del entorno", es muy hábil para explorar su entorno y utilizar los recursos disponibles. Que sea "hacer trampa" o "ser astuto" depende de tu postura.
Pero independientemente de cómo se vea, ALE evidentemente aprendió la lección:
trasladó directamente el campo de pruebas de la línea de comandos al escritorio GUI, sin historial git que espiar.
El campo de pruebas para evaluar la IA está siendo actualizado por la propia IA, lo cual también es fascinante.
Dirección completa de la evaluación: https://agents-last-exam.org/leaderboard Página principal del proyecto: https://agents-last-exam.org/ GitHub: https://github.com/rdi-berkeley/agents-last-exam
Enlaces de referencia:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
Este artículo proviene del WeChat public account "量子位" (Quantum Bit), autor: 一水 (Yishui)





