收藏不等于拥有,高亮不等于理解。
那些凌晨两点让你心潮澎湃的深度好文,那些在Obsidian里拉出的密密麻麻的双向链接,那些在Notion里精心排版的数据库,都是躺在笔记软件里的「赛博木乃伊」。
图谱看似壮观,实则早已腐朽。
这是整个信息过载时代的系统性失败。
现Anthropic工程师、前OpenAI联合创始人、Tesla前AI总监Karpathy,看不下去了,扔下一枚炸弹。

传送门:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
他没有宣布新模型,没有发布新框架,他只是说:把你的笔记当成不可变源代码,让LLM做编译器。
两个月过去,这份文档已经在Obsidian、Claude、Cursor社区掀起一场静默却剧烈的迁移。
有人已经把自己的Wiki扩展到上百页、数十万字。
自动化插件开始出现。学术研究者、独立创业者、终身学习者正在集体转向一种全新的知识生产关系。
RAG的黄昏,信息搬运救不了你的思想
在LLM-WIKI出现之前,主流的解决方案是RAG(检索增强生成)。
简单说,就是给大模型配一个「翻找员」:当你提问时,它去你的笔记里搜几个片段,然后拼凑出一个答案。
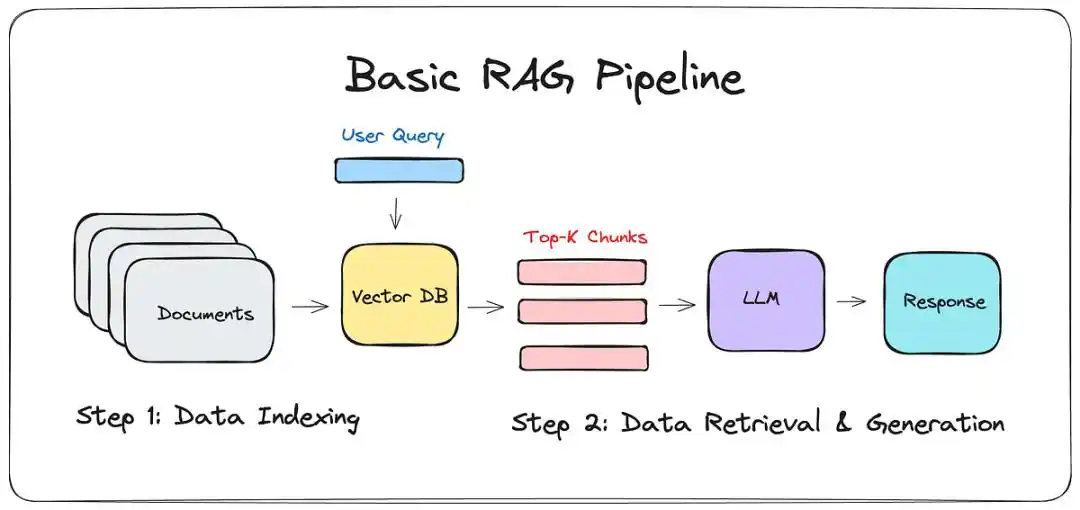
听起来很美,但用过的人都知道那种「卖家秀」与「买家秀」的落差。
它只是搬运工:RAG只能处理局部,无法理解全局。
它能告诉你第5篇笔记提到了A,但它无法告诉你这500篇笔记共同指向的底层逻辑。
它会「人格分裂」:如果你半年前认为A是对的,昨天却写笔记反驳了A,RAG往往会陷入自我矛盾,吐出一堆逻辑混乱的废话。
图谱腐烂:手动维护的知识链接,就像没有自动清理功能的代码。日子久了,断头链接随处可见,检索效率呈指数级下降。
Karpathy的直觉非常犀利:搜索和检索是人类无能的表现。我们需要的是「共识」,是「结构」,是「真相」。
把知识当源代码,让LLM当编译器
Karpathy的答案,来自一个程序员每天都在做、却从没往知识上想过的动作:编译。
你写好一段源代码,不会每次运行程序都重新读一遍代码。
你把它编译成一个二进制文件,编译这一次很费劲,但之后每次运行都飞快。编译的成本,被之后成千上万次使用摊平了。
知识为什么不能这么干?
Karpathy说,把你的原始笔记当成不可修改的源代码,把LLM当成编译器,让它一次性把这堆乱七八糟的材料「编译」成一个结构化、互相链接的Wiki。
每加一篇新材料,AI就做一次融合:更新相关的条目页、修订综述、把新数据和旧结论打架的地方标出来、顺手加固或挑战已有的判断。
关键的差别在这里:知识被编译一次,然后持续保鲜,而不是每次查询临时重建。
等你来提问的时候,交叉引用早就在那了,矛盾早就被标过了,综述早就反映了你读过的一切。
你不会每次跑程序都重编译一遍源代码。那为什么每次提问,都要让AI重读一遍你的笔记?
认知生产关系的根本转移
在他的LLM-WIKI框架里,笔记不再是死文字,而是「源代码」。
大模型不再是查字典的翻译官,而是「编译器」。
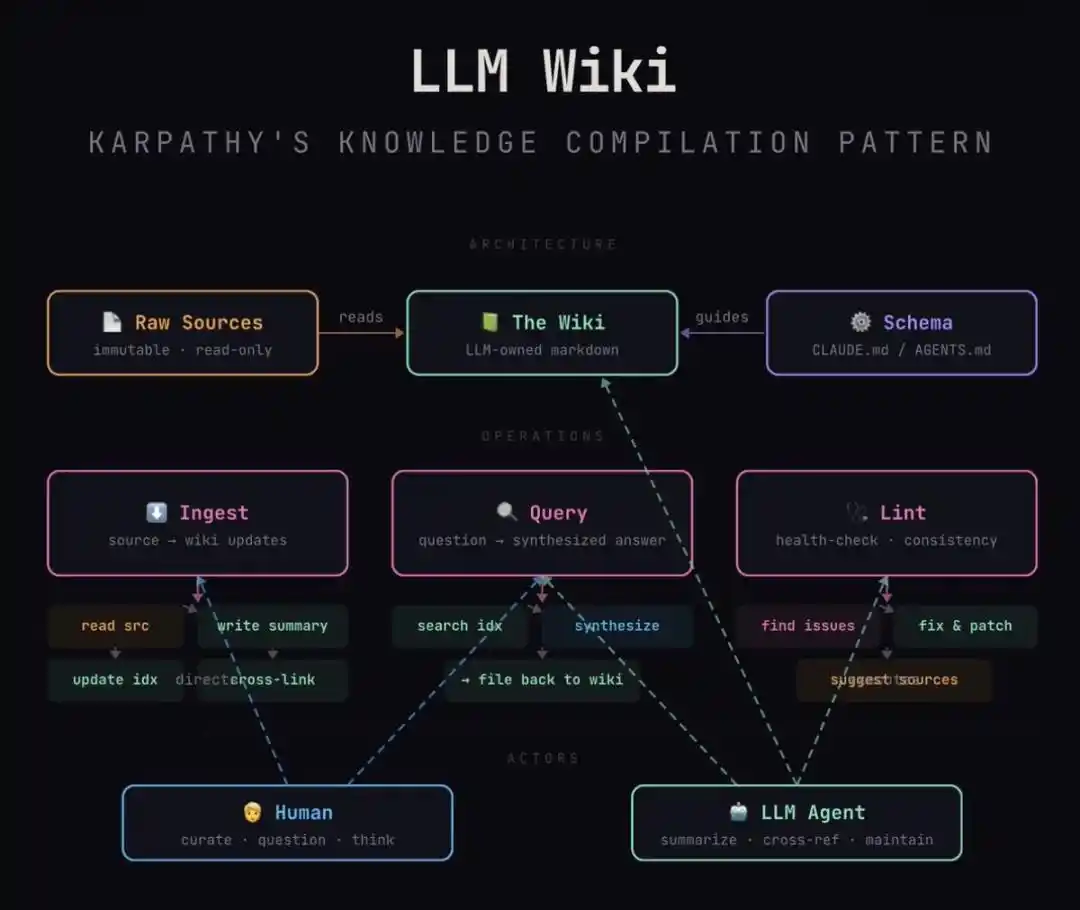
这套架构极其精妙地实现了三层解耦:
1、Raw层(原始素材):这是你的灵感原矿。你随手记下的感悟、剪辑的文章、会议纪要。它是「不可变」的,保持了人类输入的原始性和不洁感。
2、Schema层(知识宪法):这是你写给AI的「军规」。比如你规定:每一个人物词条必须包含「动机、局限性、关键成就」;每一个技术栈必须说明「优缺点」。
3、Wiki层(编译成品):这是AI全权维护的区域。它根据你的Schema,把那堆乱七八糟的Raw编译成结构化、交叉链接、逻辑自洽的百科页面。
日常就三个动作:
1、Ingest(摄入):丢一篇新料进去,AI 读完、跟你过一遍要点、写摘要、横扫整个库更新相关页——一篇来源,可能牵动十几个页面。
2、Query(查询):直接问编译好的 Wiki,带引用作答。最妙的是:好答案能直接回档成新页,你的每一次探索也在复利。
3、Lint(体检):定期让 AI 像做代码审查一样自查——找矛盾、找过时论断、找没人链接的孤立页、找该补的缺口。早期就清,不让库越长越腐。
你不再是知识的搬运工,而是这个智慧帝国的架构师。
你只负责输入和最后的审阅,AI负责所有的「杂活」:整理、对齐、交叉链接、矛盾检测。
这是认知生产关系的根本转移。
这不是另一个聊天机器人。ChatGPT了解互联网,LLM-Wiki了解你——准确说,是你教给它的东西。
每个回答都带着 [wiki-links] 回到你的知识图谱。每条回复都是一条探索路径的起点,而不是终点。
迟到了80年的发明
到这儿,你可能觉得这不就是个聪明的工作流吗?
不止。
Karpathy在gist结尾,轻飘飘地点了一个名字:Vannevar Bush,和他1945年那篇《As We May Think》。

1945年,二战刚结束,这位美国科学界的大佬,幻想了一台叫「Memex」的机器:
一张机械书桌,能存下你所有的书、记录、通信,并在相关条目之间,建立起「联想路径」——文档与文档之间的连接,和文档本身一样宝贵。
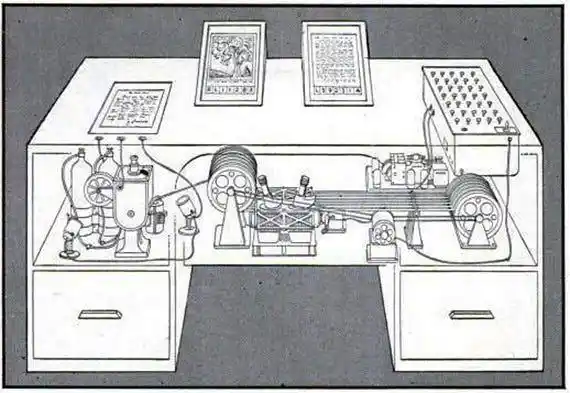
听着耳熟吗?这几乎就是LLM-Wiki的逐字描述。
Bush的愿景,其实比后来的万维网更接近这个东西:私密的、亲手策展的、连接即价值的知识网络。

那为什么Memex八十年没造出来?
因为Bush卡在了一个他解决不了的问题上——谁来维护?
每一条联想路径,都得手工建立。每一个交叉引用,都得有人去连。
Bush幻想着有专门的「操作员」为你在知识里铺设小径。
可现实是,没有任何人能在大规模上坚持做这件枯燥的苦役。人类会放弃维护,因为维护的成本,永远比它带来的价值涨得更快。
Karpathy这句话,是整个范式的题眼:维护一座知识库最累的部分,从来不是阅读,是记账。
更新交叉引用,保持摘要新鲜,标注新数据和旧结论的冲突,让几十个页面之间始终一致。这种枯燥,足以劝退所有人。
而大模型,不会忘记更新某一个交叉引用,可以一口气改动15个文件。
它不会累。不会烦。不会被深夜拖垮。维护成本,被压到了近乎为零。
于是,那台卡了人类八十年的机器,突然就转起来了。
被解放的,是人类的注意力
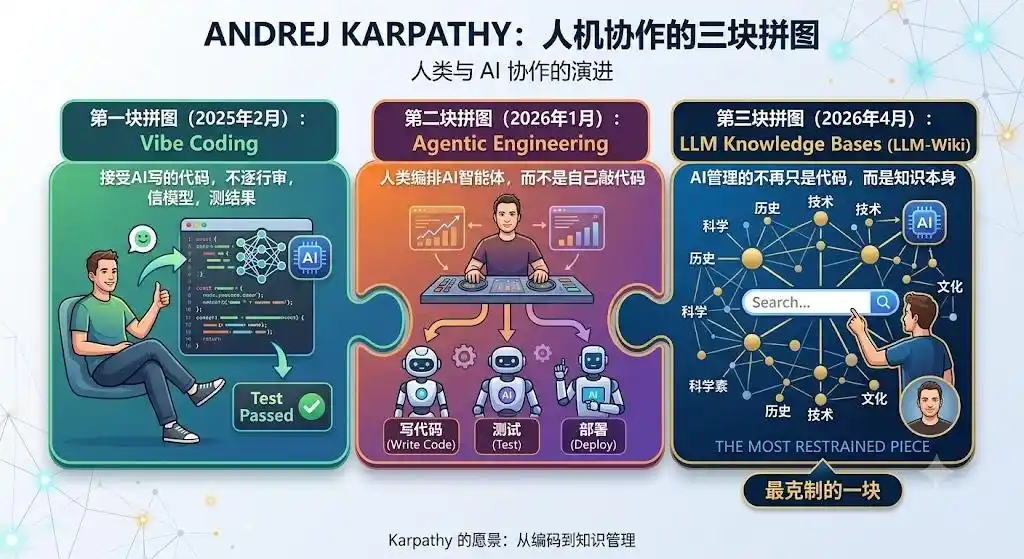
回头看,LLM-Wiki是Karpathy关于「人机协作」的第三块拼图,也是最克制的一块。
第一块,Vibe Coding(2025年2月):接受AI写的代码,不逐行审,信模型,测结果。
第二块,Agentic Engineering(2026年1月):人类编排AI智能体,而不是自己敲代码。
第三块,LLM Knowledge Bases(2026年4月):AI管理的不再只是代码,而是知识本身。
在这套新范式里,人类被剥掉的,是收藏、整理、链接、记账这些谁都不爱干的杂活。
人类被留下的,只剩两件事:决定读什么,以及,想清楚这一切到底意味着什么。这恰恰是机器至今做不了、也最不该替你做的两件事。
这是一个工具进化到极致,最终绕了一圈,把人类的注意力还给人类自己的故事。
那张朴素到欠揍的markdown文件,没发模型,没刷榜单。
它只是安静地提醒了一句:你的大脑,本就不该用来记账。
本文来自微信公众号“新智元”,作者:ASI启示录







