编者按:很多人使用 Claude Code 时,最直观的感受是 Token 消耗太快、长会话很容易吃额度。但从 Anthropic 工程师的视角看,真正影响成本的,往往不是你写了多少代码,而是系统有没有持续复用已经处理过的上下文。
本文分享的核心,就是如何通过缓存机制节省 Token。作者一周内通过缓存复用了超过 3 亿 Token,单日缓存量达到 9100 万。由于缓存 Token 的成本只有普通输入 Token 的 10%,这意味着 9100 万缓存 Token 实际计费约等于 900 万普通 Token。Claude Code 长会话之所以显得更「耐用」,不是因为模型免费工作,而是大量重复上下文被成功复用了。
Prompt caching 的关键在于「不要打断缓存」。Claude Code 会把系统提示、工具定义、CLAUDE.md、项目规则和历史对话分层缓存;只要后续请求的前缀保持一致,Claude 就可以直接读取缓存,而不是重新处理整段上下文。Anthropic 内部也会监控 prompt cache 的复用率,因为它不仅影响用户额度,也直接关系到模型服务成本和运行效率。
对普通用户来说,不必理解所有底层细节,只需要掌握几个关键习惯:不要让会话空置超过 1 小时;切换任务时做好 session handoff;避免频繁切换模型;大文档尽量放进 Projects,而不是反复粘贴进对话。
这篇文章与其说是在讲一个省 Token 技巧,不如说是在提供一套更接近工程师思维的 Claude Code 使用方法:把上下文当作资产管理,让缓存持续复用,让长会话少做重复计算。
以下为原文:
我这周省下了 3 亿 Token,单日 9100 万,一周超过 3 亿。
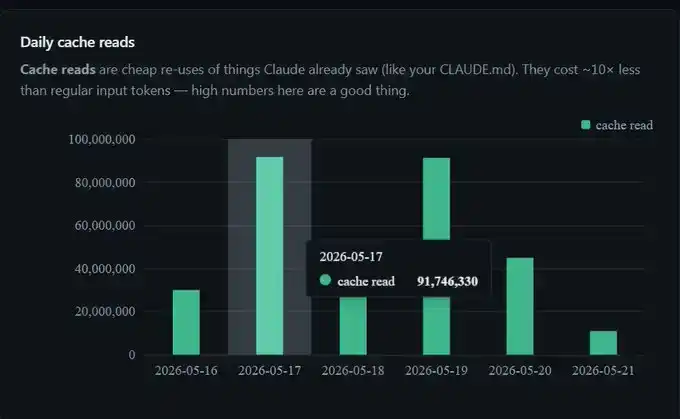
我没有改动任何设置。这只是 prompt caching 在后台正常发挥作用。
但当我真正理解了缓存是什么,以及怎样避免把缓存「打断」之后,在同样的使用额度下,我的会话可以持续更久。所以,这里整理一份 Claude Code prompt caching 的 80/20 入门指南,不涉及 API 层面的深度细节。
TL;DR
缓存 Token 的成本只有普通输入 Token 的 10%。9100 万缓存 Token,实际计费大约相当于 900 万 Token。
Claude Code 订阅版的缓存 TTL 是 1 小时;API 默认是 5 分钟;Sub-agent 永远是 5 分钟。
缓存分为三层:系统层、项目层、对话层。
会话中途切换模型会破坏缓存,包括开启「opus plan」模式。
缓存到底怎么算钱?
每一个被缓存的 Token,成本都是普通输入 Token 的 10%。

所以,当我的仪表盘显示某一天有 9100 万 Token 命中了缓存时,实际计费大概只相当于处理了 900 万 Token。这也是为什么和没有缓存相比,长时间使用 Claude Code 时,会让人感觉会话几乎是「免费」延长的。
仪表盘里有两个数字值得重点关注:
Cache create:把内容写入缓存时产生的一次性成本。它会在下一轮对话中开始发挥作用。
Cache read:Claude 从缓存中复用的 Token,比如你的 CLAUDE.md、工具定义、此前的消息等。相比重新作为输入处理,成本便宜 10 倍。

如果你的 Cache read 数字很高,说明你正在有效利用缓存;如果这个数字很低,就意味着你在为同一批上下文反复付费。
Anthropic 的 Thariq 有一句话让我印象很深:「我们实际上会监控 prompt cache 的命中率,一旦命中率过低,就会触发警报,甚至宣布 SEV 级别的事故。」
他还写过一篇很好的 X 文章。当缓存命中率高时,会同时发生四件事:Claude Code 体感更快,Anthropic 的服务成本下降,你的订阅额度显得更耐用,长时间编码会话也变得更现实。
但如果命中率很低,所有人都会吃亏。

所以,双方的激励其实是一致的:Anthropic 希望你的缓存命中率更高,你自己也希望命中率更高。真正会拖后腿的,只是一些看似不起眼、却会悄悄重置缓存的小习惯。
缓存是如何在每一轮对话中增长的?
缓存依赖的是 prefix matching,也就是「前缀匹配」。
不用陷入太深的技术细节,你只需要理解一点:只要某个位置之前的内容和已经缓存的内容完全一致,Claude 就可以复用这部分缓存 Token。
一次全新的会话,大致是这样展开的:
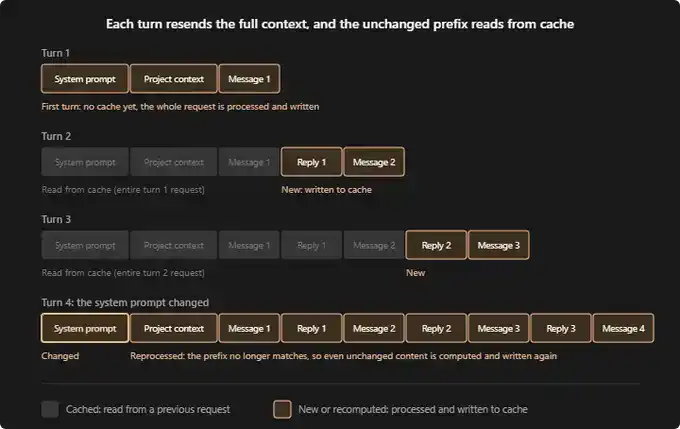
根据 Claude Code 文档,一个全新会话通常是这样运行的:
第一轮对话:还没有任何缓存。系统提示词、你的项目上下文(比如 CLAUDE.md、memory、规则),以及你的第一条消息,都会被重新处理一遍,并写入缓存。
第二轮对话:第一轮中的所有内容现在都已经被缓存。Claude 只需要处理你的新回复和下一条消息。这一轮成本就会低很多。
第三轮对话:逻辑相同。之前的对话仍然保留在缓存里,只有最新的一轮交互需要重新处理。
缓存本身可以分成三层:

来自 Thariq 的 X 文章:
系统层(System layer):包括基础指令、工具定义(read、write、bash、grep、glob)和输出风格。这一层是全局缓存的。
项目层(Project layer):包括 CLAUDE.md、memory、项目规则。这一层按项目缓存。
对话层(Conversation):包括回复和消息,会随着每一轮对话不断增长。
如果在会话中途,系统层或项目层的任何内容发生变化,所有内容都必须从头重新缓存一遍。这就是最「贵」的操作。可以想象一下:你已经聊到第 16 条消息,这时突然改了系统提示词,或者中途停了一个小时,那么从第 1 条消息开始的所有 Token 都要被重新处理一遍。
1 小时和 5 分钟的混淆
这是最容易让人误解的地方。
Claude Code 订阅版:默认 TTL 是 1 小时。
Claude API:默认 TTL 是 5 分钟。你可以付出更高成本,把它提升到 1 小时。
任何计划下的 Sub-agent:永远是 5 分钟。
Claude.ai 网页聊天:官方没有明确记录。可能和订阅版一样,但我还没有确认。
几个月前,很多人抱怨 Claude 订阅额度消耗得太快。当时有人以为 Anthropic 悄悄把 TTL 从 1 小时降到了 5 分钟,而且没有通知用户。但事实并不是这样,Claude Code 的 TTL 仍然是 1 小时。
问题在于,Claude Code 和 API 的文档是分开放的,而这两者本来就是完全不同的东西,于是造成了不少混淆。
如果你在大量运行 Sub-agent 工作流,或者直接使用 API,那么 5 分钟这个数字很重要。但对于 95% 的 Claude Code 用户来说,真正需要关注的,其实只有那个 1 小时窗口。
覆盖 95% 用户的三个习惯
下面这些,是我觉得日常使用中真正有用的部分。
不要暂停太久
如果你已经空闲超过一个小时,之前的内容基本都已经从缓存里过期了。你的下一条消息会重新构建缓存。这种情况下,与其继续恢复一个已经「变凉」的旧会话,不如做一次清晰的交接,然后开启一个新会话,成本通常更低。
切换任务时,直接重新开始
/compact 或 /clear 本来就会破坏缓存,所以不如趁这个节点真正重置一次。
我自己做了一个 session handoff skill,用来替代 /compact。它会总结我们已经完成了什么、还有哪些待定决策、哪些文件最重要,以及接下来应该从哪里继续。然后我执行 /clear,把这份总结贴进去,就可以像什么都没中断一样继续推进。
compact 命令有时候运行得也很慢。而这个 handoff skill 通常不到一分钟就能完成。
在 Claude 聊天里,大文档尽量放进 Projects
Claude.ai 上的缓存机制没有非常详细的官方说明,但 Projects 显然和普通对话线程采用了不同的优化方式。所以,如果你要粘贴很大的文档,最好把它们放进 Project,而不是直接塞进对话里。
哪些操作会悄悄破坏缓存?
有几件事会在没有明显提醒的情况下,把缓存全部重置。
切换模型:因为缓存依赖前缀匹配,而每个模型都有自己的缓存。只要切换模型,下一次请求就会在没有任何缓存命中的情况下,重新读取完整历史。
「Opus plan」模式:这个设置会在规划阶段使用 Opus,在执行阶段使用 Sonnet。我之前在一些 token 优化视频里推荐过它,是有原因的。但需要理解的是,每一次切换 plan,本质上都是一次模型切换,也就意味着要重新建立缓存。从长期看,它仍然有助于延长会话额度,但你需要知道底层到底发生了什么。
会话中途编辑 CLAUDE.md 是可以的:这个修改不会立刻生效,要等下一次重启才会应用。因此,当前正在运行的缓存不会受到影响。
我的免费 Token 仪表盘
我前面展示的截图,来自一个 token dashboard。
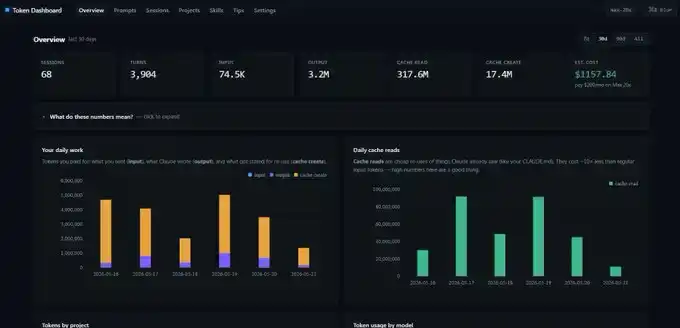
这是一个很简单的 GitHub 仓库。你把链接交给 Claude Code,让它在本地 localhost 上完成部署,它就会读取你过去所有的会话记录,而不是从空白状态开始统计。你一上来就能看到每天的 input、output、cache create 和 cache read 数据。
不过有一点需要注意:这个仪表盘统计的是本地设备上的 Token 数据。如果你从台式机切换到笔记本,数字就不会完全一致。每台设备都有自己的一套统计视图。
总结
Prompt caching 是一个可以研究得很深的东西。Thariq 那篇文章讲得比这里更完整,如果你想看全貌,值得去读。
但你不需要完全理解所有细节,才能从中受益。你只需要掌握最关键的 80/20:缓存 Token 比普通 Token 便宜 10 倍;Claude Code 的 TTL 是 1 小时;切换模型会破坏缓存;在任务之间做好清晰交接,通常比让一个旧会话放到「过期」后再硬接着用更划算。






