随着LLM Code Agent能力的不断提升,越来越多的研究者意识到现在是时候迈向下一个阶段更接近真实场景需求的长程任务了。于是涌现出了一些长程任务评测的Benchmark比如NL2RepoBench以及BeyondSWE等等。大家对Code Agent预期承担的角色逐渐从仓库维护者变成了架构师,能够做规划完成整个仓库的代码的长程任务。
近日,中国人民大学高瓴人工智能学院完成相关研究,重磅发布DeNovoSWE数据集,专注于长程软件工程任务,尤其是仓库级别代码从零生成任务。

论文链接:https://arxiv.org/pdf/2606.10728
仓库链接:https://github.com/AweAI-Team/DeNovoSWE
数据链接:https://huggingface.co/collections/AweAI-Team/denovoswe
通过Divide & Conquer与Critic & Repair机制构造高质量数据集,并且成功实现长程SWE任务的Scaling,构建起包含4,818真实数据的开源高质量长程SWE任务数据集——这一成果为 Code Agent 长程能力训练提供了大规模数据,大幅提升Code Agent长程任务能力。
论文中也提供了根据题目难度打分过滤的手段,有效缓解了困难题目比例与轨迹质量的权衡问题。
实验显示,基于DeNovoSWE训练的Qwen3-30B-A3B-Instruct在BeyondSWE-Doc2Repo上从5.8%提升到47.2%,在 NL2RepoBench 上从 4.3% 提升到 23.0%,展示了长程数据对仓库级代码生成能力的显著提升。
从一份文档开始重建整个仓库
过去一年,随着像Scale-SWE等工作的大规模SWE数据的scaling,代码智能体在 SWE-bench 这类真实软件工程任务上快速进步。但当模型越来越擅长「修一个 issue」「改几行 bug」之后,一个更关键的问题开始浮现:智能体真的具备长程软件工程能力了吗?从BeyondSWE-Doc2Repo以及NL2RepoBench前沿模型的效果来看,效果并不理想。
真实世界的软件开发,往往不是改一个函数、补一个条件判断,而是理解需求、规划架构、创建文件、设计 API、处理依赖、打通模块,并最终让整个仓库在测试中跑通。
换句话说,困难的是 long-horizon repository-level generation:从一份任务文档出发,生成一个完整、可执行、可验证的软件仓库。这正是 DeNovoSWE 想要解决的问题。
高质量的「从头生成仓库」任务文档
在document-to-repository generation中,文档不只是README,也不是简单的API列表。它本质上是智能体重建整个仓库的唯一任务入口。
一份高质量的任务文档,至少需要满足两个核心标准。
第一,它必须是well-organized的。
仓库级任务天然复杂,包含多个模块、接口、配置、数据结构和交互流程。如果文档只是把函数说明堆在一起,智能体很容易迷失在碎片信息中。因此,文档应该先给出清晰的仓库总览,再按照能力或工作流拆分章节,让每一部分都对应明确的功能边界。
第二,它必须从可靠evaluation的角度出发。
文档既不能太少,否则任务变成欠定义问题,可能使得模型需要靠漫无边际猜才能通过evaluation;也不能太多,否则直接泄漏实现细节,让任务失去挑战。
真正高质量的文档应该描述evaluation所依赖的关键行为:包括import path、公开 API、输入输出、默认参数、异常行为、配置项、模式字符串、返回字段等,也描述出大致需要完成的功能。也就是说,文档要足以让智能体复现可测试行为,但不能变成实现代码的拷贝。
这也是DeNovoSWE的核心思想:让文档既可读、可实现,又可验证。
DeNovoSWE方法
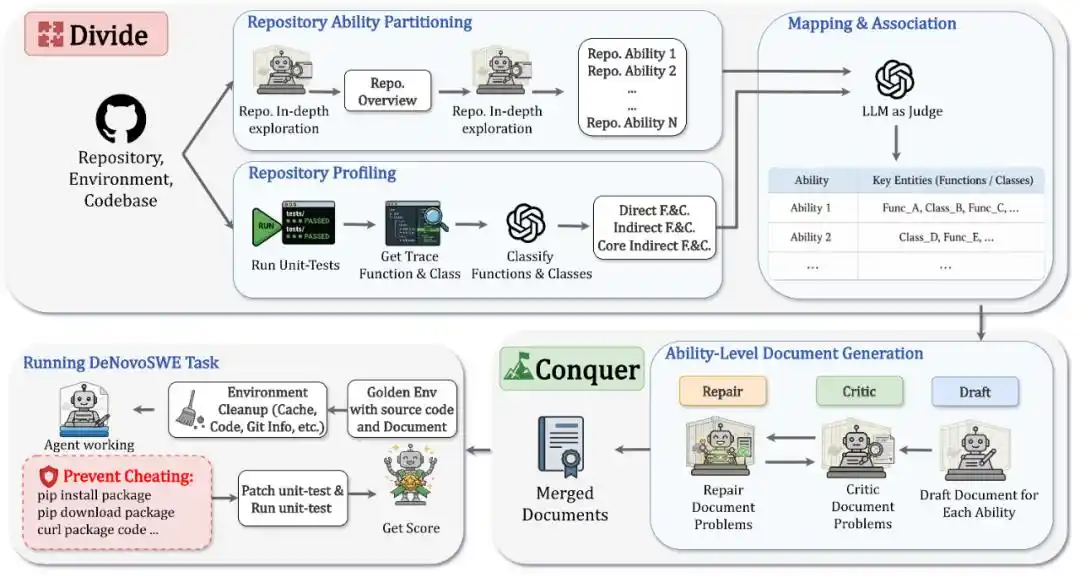
DeNovoSWE 将「从文档生成完整仓库」构造成一个大规模、可验证的长程软件工程任务。它不是人工手写文档,而是通过一个sandboxed multi-agent workflow 自动构建高质量实例。整个方法可以概括为两步:Divide和Conquer。
在Divide阶段,系统首先分析目标仓库,将其拆解为多个repository capabilities。
每个capability对应仓库中的一个核心能力或工作流,例如认证与连接、数据读写、批处理、导出流程等。这样,原本庞大的仓库生成问题被拆成若干结构清晰的文档章节。
同时,DeNovoSWE会运行原始单元测试并收集执行trace,识别哪些函数、类和接口真正影响 evaluation,进一步区分direct components、core indirect components和non-core indirect components:直接被测试调用的接口必须详细记录;会影响可观察行为的核心间接组件也需要覆盖;而非核心内部实现则可以留给智能体自由发挥。
在Conquer阶段,DeNovoSWE 使用 Draft-Critic-Repair 机制逐能力生成文档。Draft agent 先写出初稿;Critic agent检查文档是否遗漏关键 API、行为契约或结构信息;Repair agent 再根据反馈修复文档。这个循环不断迭代,直到每个能力章节足够清晰、完整、与 evaluation 对齐。
最终,不同能力文档会被合并成一份完整的任务文档,作为智能体从零生成仓库的唯一依据。
难度:为什么这是长程任务?
DeNovoSWE的任务难度来自一个根本变化:它不再是issue-level fixing,而是whole-repository generation。
在传统 SWE 任务中,智能体通常面对的是一个已有仓库,只需要定位 bug、修改局部代码、通过测试即可。
在 DeNovoSWE 中,智能体面对的是一个被清理后的环境:原始源码和测试被移除,git 历史被重置,缓存、site-packages 残留、pip wheel、临时编译产物等潜在泄漏渠道也会被清除。这意味着智能体必须真正依赖文档来完成整个仓库的重建。它需要规划项目结构,创建模块文件,定义公开接口,实现跨文件交互,处理依赖和配置,并在多轮编辑与测试反馈中不断修复错误。
任何一个 API 签名、返回字段、异常类型或默认行为的偏差,都可能导致测试失败。错误还会在长程过程中累积:一个早期设计不合理的模块,可能影响后续多个文件和调用链。
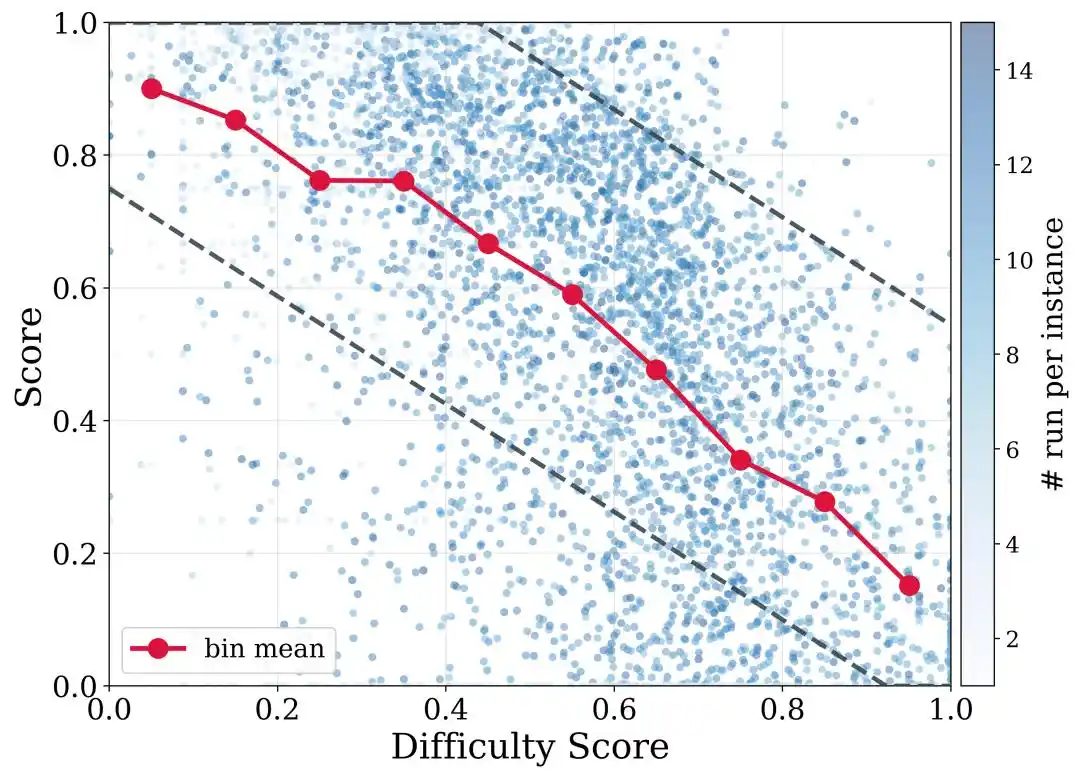
为了进一步处理不同仓库难度差异,DeNovoSWE 还提出了 difficulty-aware trajectory filtering。简单地说,容易任务应该要求更高通过率,困难任务则不能因为没有达到完美分数就被全部丢弃。DeNovoSWE 根据结构复杂度和 LLM 难度判断,为不同难度区间设置不同过滤阈值,从而在质量和多样性之间取得平衡。
这对于长程任务尤其重要:越复杂的仓库,越难一次性完全通过所有测试,但其中的困难仓库、低分、部分成功的轨迹仍然包含宝贵的长程规划与实现能力。
实验结果
DeNovoSWE最终构建了4818个高质量document-to-repository任务实例。是可执行、可评估、可训练的长程软件工程环境。
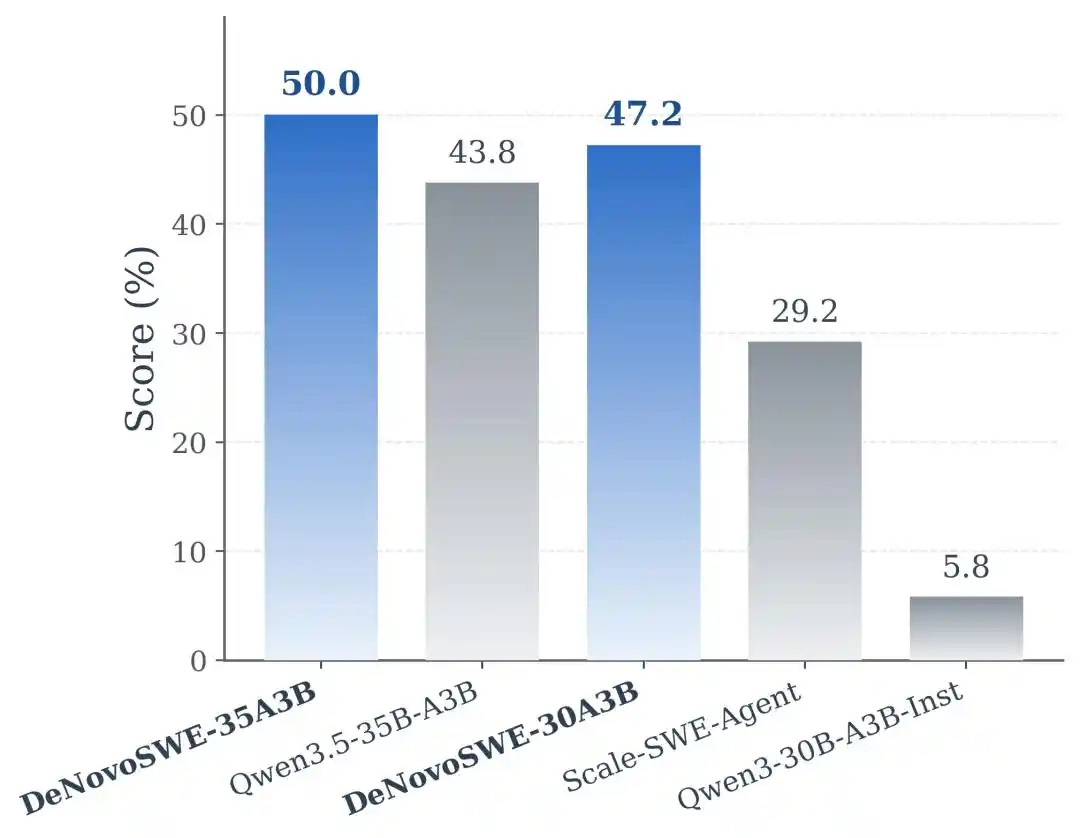
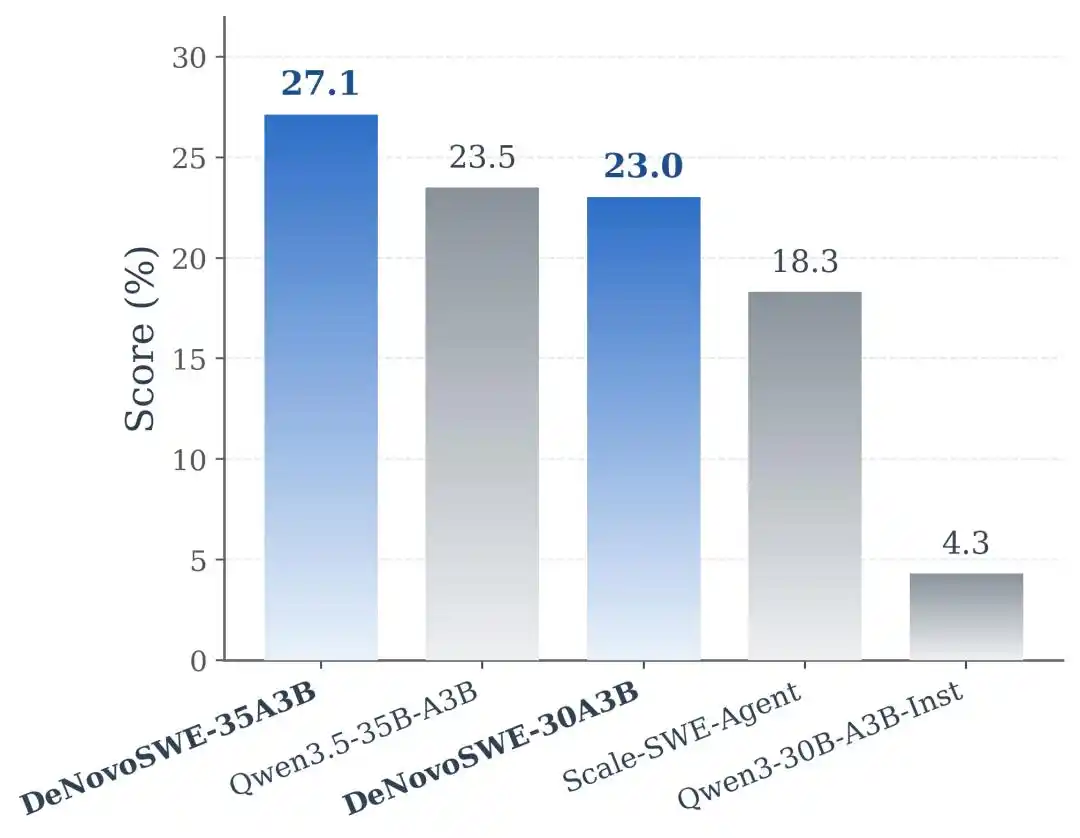
实验结果显示,DeNovoSWE对模型的长程仓库生成能力带来了显著提升。在Qwen3-30B-A3B-Instruct上,原始模型在BeyondSWE-Doc2Repo上只有5.8%,在NL2RepoBench上只有4.3%。使用常规issue-level SWE数据训练的Scale-SWE-Agent可以提升到29.2%和18.3%,说明普通 SWE 数据确实有迁移效果。但当模型使用 DeNovoSWE 训练后,性能进一步提升到 47.2% 和 23.0%。
这说明,面向「修 bug」的数据并不能完全替代面向「生成完整仓库」的长程数据。想让智能体真正学会repository-level engineering,需要专门面向长程任务构建训练环境。
在更强的Qwen3.5-35B-A3B backbone上,DeNovoSWE同样带来稳定收益:BeyondSWE-Doc2Repo从43.8%提升到50.0%,NL2RepoBench从23.5%提升到27.1%。这进一步说明DeNovoSWE的收益不是偶然适配某一个模型,而是来自高质量长程数据本身。
结语
代码智能体的下一阶段,不只是更快地修复单个 issue,而是能够理解文档、规划架构、组织模块、实现接口,并最终生成一个完整可运行的软件仓库。
DeNovoSWE 将这个目标系统化地构造成了可训练、可验证、可扩展的数据集。它回答了一个关键问题:什么样的数据,才能真正训练出具备长程软件工程能力的智能体?
答案不是更多碎片化代码,也不是更简单的题目,而是高质量、结构化、evaluation-aligned、anti-leakage 的全仓库生成任务。
从一份文档开始,重建整个repository。这是长程代码智能体需要跨越的门槛。
参考资料:https://arxiv.org/pdf/2606.10728
本文来自微信公众号“新智元”,编辑:LRST






