Pada bulan Mei tahun ini, Meta menarik garis batas untuk insinyurnya sendiri.
Staf di departemen teknik AI terapan, tidak boleh lagi sembarangan memakai Claude Code dan Codex.

Menurut panduan internal yang diperoleh The Information, bahkan sebuah memo secara langsung meminta untuk menunda tugas-tugas tertentu yang menggunakan kedua model tersebut. Redaksinya tegas, mengatakan hal ini bisa memicu "eskalasi serius dengan mitra kerja".
Namun, keanehan justru terletak di sini.
Meta adalah salah satu klien terbesar Claude Code di dunia. Tagihan total penggunaan AI internalnya tahun ini, ditargetkan mencapai miliaran dolar.
Alat yang diandalkan setiap hari, perusahaan beli dengan mahal, kini malah dibatasi penggunaannya di dalam. Dan alasan pembatasannya, mungkin juga tak terduga.
Bukan karena tidak bagus. Justru sebaliknya, terlalu bagus.
Garis batas ini masih berlaku sekarang
Menurut laporan The Information, pembatasan ini sudah ditetapkan bulan Mei, dan masih berlaku hingga kini.
Mengapa Meta begitu tegang, ini berawal dari proyek asisten pemrograman AI internal mereka.
Tahun ini, mereka membentuk tim teknik AI terapan yang fokus pada asisten pemrograman AI buatan sendiri, MetaCode (nama aslinya DevMate).
Tujuannya agar Meta tidak terus menerus membayar mahal untuk menggunakan model pemrograman AI milik orang lain, mereka juga ingin melatih sendiri.
Antarmuka resmi Claude Code. Bersama Codex dari OpenAI, telah menjadi standar de facto untuk pemrograman agen cerdas di kalangan pengembang profesional.
Tapi melatih model yang bisa menulis kode tidak semudah itu.
Kamu harus memberinya data berkualitas tinggi dalam jumlah besar, juga harus menyiapkan soal pemrograman yang cukup banyak dan rumit, untuk melatih dan menilainya. Kumpulan soal dan sistem evaluasi ini, hampir menentukan sekuat apa sebuah model pemrograman akhirnya.
Dan masalahnya justru ada di sini.
Tantangan yang dihadapi Meta adalah bagaimana mencegah karyawan terlalu bergantung pada alat eksternal ini, untuk membangun pengganti internal.
Yang dikhawatirkan adalah output dari model eksternal ini meresap ke dalam data pelatihan, membuat model buatan sendiri diam-diam belajar kemampuan lawan.
Untuk memahami kekhawatiran ini, harus tahu dulu bagaimana sebuah model "belajar": data seperti apa yang kamu beri, seperti itulah jadinya.
MetaCode ingin kuat, bergantung pada data pelatihan dan kumpulan soal pemrograman yang dikumpulkan insinyur.
Tapi sekali soal, jawaban, bahkan standar penilaian itu berasal dari Claude atau Codex, kemampuan yang dipelajari MetaCode bukan lagi "kemampuan hasil latihan insinyur manusia", melainkan "kemampuan Claude".
Ia mencontek jawaban dari kertas ujian lawan, semakin dilatih semakin mirip lawan.
Yang lebih tersembunyi adalah bagian evaluasi.
Setiap kali model menjawab soal, harus ada sesuatu yang memberi tahu apakah jawabannya bagus, barulah ia tahu harus memperbaiki ke mana.
Jika pembuatan soal dan penilaian diserahkan ke Codex, maka MetaCode sedang berevolusi ke arah "yang Codex anggap benar", sama saja dengan menyalin standar penilaian lawan sedikit demi sedikit ke dalam otaknya sendiri.
Itulah mengapa panduan Meta ini melarang AI menjadi pembuat soal, penilai, bahkan "apakah materi yang dihasilkan AI bisa masuk ke lingkungan yang bisa diakses model yang diuji" pun diawasi.
Selama output lawan sedikit saja meresap ke dalam rantai pelatihan atau evaluasi, garis batas "siapa mengajari siapa" ini, akan kabur.
Intinya, Meta menunda beberapa tugas, sedang melakukan isolasi data pelatihan.
Khawatir AI menulis terlalu baik, sulit dibedakan kemampuan mana yang dihasilkan dari pelatihan sendiri, mana yang dipelajari dari Claude dan Codex.
Dan kemampuan yang terakhir ini, disewa, bukan milik sendiri.
Pembatasan yang detail hingga mengejutkan
Harus dijelaskan dulu, dalam dokumen internal Meta, tidak ada catatan karyawan yang benar-benar melanggar aturan.
Juru bicara Meta juga menanggapi, perusahaan punya "kebijakan yang jelas" mengatur penggunaan alat AI. Jadi dokumen ini lebih seperti alarm yang dinyalakan lebih awal di internal.
Pekerjaan apa yang tidak boleh disentuh AI? Utamanya tiga kategori ini:
Pertama, tidak boleh mengambil output Claude atau Codex untuk membuat soal uji bagi model sendiri. Kalimat asli panduan adalah, ini "jelas termasuk dalam kategori insinyur tidak berada di posisi pengemudi", "kami tidak menginginkan tugas yang berasal dari model".
Kedua, tidak boleh membiarkan AI mencari bug dalam kode sumber, juga tidak boleh membiarkannya membantu berpikir "apa yang harus diuji" berdasarkan analisis kode.
Ketiga, apa pun yang dihasilkan AI, tidak boleh dimasukkan ke tempat yang bisa diakses model yang diuji.
Intinya, selama AI terlibat dalam penilaian "apa yang harus diuji, jawaban benar atau tidak", kemampuan lawan mungkin bisa menyusup. Tiga aturan ini menutup celah tersebut.
Pekerjaan apa yang masih bisa dikerjakan AI?
Membangun alur kerja, mengatur kode dan file, membuat kerangka pengujian untuk alat internal, pekerjaan rutin seperti ini masih boleh. Panduan menyebut pekerjaan jenis ini sebagai "perancah pengujian (test scaffolding)" dan "kalibrasi solusi (solution calibration)", intinya membantu, membangun kerangka.
Bahkan untuk pekerjaan seperti ini pun, ada aturan besi: setiap baris output AI, harus dilihat dulu oleh manusia.
Di mata Meta, begitu model lawan dijadikan pembuat soal, penilai, ujian ini tidak jelas lagi siapa yang mengujinya.
Apa yang benar-benar ingin dipertahankannya, adalah garis batas "siapa mengajari siapa" itu.
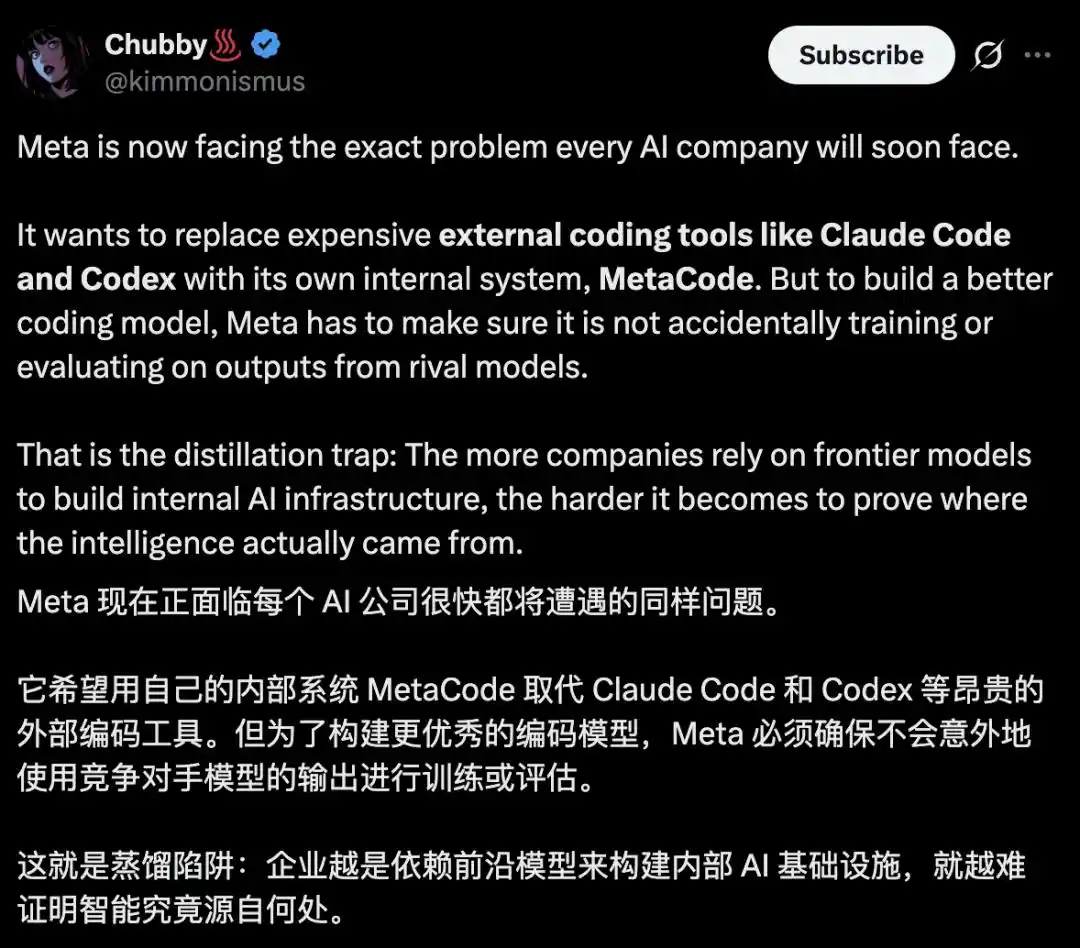
Jebakan distilasi yang tak terhindarkan
Apa yang dikhawatirkan Meta ini, di industri ada istilah khususnya: distilasi.
Artinya mudah dimengerti: ambil model yang lebih kuat, biarkan terus menjawab soal, lalu gunakan jawaban ini untuk melatih model yang lebih lemah.
Agak seperti membiarkan juara kelas mengerjakan kertas ujian dari awal, si pecundang mencontek, dalam beberapa bulan bisa mengejar kemampuan orang yang butuh bertahun-tahun.
Investasi mahal orang lain di data, daya komputasi, penelitian, kamu dapatkan hampir gratis.
Melatih model mutakhir dari nol, biaya dan waktunya angka astronomi. Sedangkan distilasi, mungkin hanya butuh beberapa output lawan, biaya dan waktu kerja dipotong hingga tinggal sedikit.
Distilasi sendiri adalah operasi rutin industri, perusahaan besar juga sering menggunakan model besar mereka sendiri untuk mendistilasi versi yang lebih kecil dan murah bagi pengguna.
Masalahnya hanya: begitu kamu mencontek model milik orang lain, kemampuan yang kamu latih, akhirnya milik sendiri, atau pinjam? Tidak jelas.
Ada yang menyebut ini "jebakan distilasi": semakin kamu mengandalkan model terkuat untuk membangun fondasi sendiri, semakin sulit membuktikan, kepintaranmu datang dari mana.
Di AS, hukum tidak secara eksplisit melarang distilasi, konten yang dihasilkan AI juga tidak dilindungi hak cipta. Kamu menggunakan output lawan untuk melatih model sendiri, hukum hampir tidak bisa menghalangi.
Satu-satunya penghalang adalah kontrak.
Ketentuan layanan OpenAI, Anthropic menulis pembatasan serupa: tidak boleh menggunakan output model, untuk membuat sesuatu yang bersaing dengan diri sendiri.
Dan penghalang ini, hak penegakan hukum sepenuhnya ada di tangan pesaing.
Tahun lalu, Anthropic langsung memutus akses API OpenAI ke Claude, meskipun OpenAI mengatakan mereka hanya menggunakannya untuk mengevaluasi kemampuan dan keamanan, itu adalah praktik "standar industri".
Bahkan Musk, dalam persidangan April tahun ini, juga terpaksa mengakui, xAI-nya "sebagian" mendistilasi model OpenAI.

30 April 2026, di kursi saksi pengadilan federal California, Musk ditanya apakah xAI menggunakan teknologi distilasi pada model OpenAI untuk melatih Grok, ia pertama-tama mengatakan ini adalah praktik umum perusahaan AI.
Ketika didesak apakah ini sama dengan "ya", dia menjawab "sebagian".
Aturan kabur, "hak penegakan hukum" semuanya dipegang pesaing. Siapa berani mempertaruhkan investasi miliaran mereka, bertaruh lawan tidak marah.
Dari sudut pandang ini, ketegangan Meta, sama sekali tidak berlebihan.
Di sini, ada juga pertimbangan menghemat uang.
Menurut memo internal, Meta tahun ini hanya untuk penggunaan AI internal, akan menghabiskan puluhan miliar dolar. Mereka bahkan mulai membatasi penggunaan token karyawan. Sebesar Meta pun, mulai menganggap AI terlalu mahal, harus berhemat.
Jika pekerjaan pengembangan bisa dialihkan dari alat eksternal yang mahal ke MetaCode sendiri, selain menghemat uang, juga menghindari ranjau distilasi, bisa dibilang satu tindakan dua hasil.
Peta berjalan di atas tali
Tentang dokumen internal Meta ini, ahli hukum teknologi, penasihat hukum Mark Leiser punya kalimat yang sangat gamblang: ini "hampir seperti peta berjalan di atas tali".
Satu sisi ingin mendapatkan manfaat model eksternal, sisi lain harus mencegah kemampuannya menyusup ke sistem sendiri.
Yang berjalan di atas tali seperti ini, tentu bukan hanya Meta, ini menyentuh inti seluruh industri.
Ketika kamu menggunakan AI yang cukup pintar, untuk membuat AI yang sama pintarnya, pada akhirnya, kamu mungkin sulit menjelaskan: kepintaran ini, sebenarnya hasil latihan sendiri, atau diam-diam dipelajari dari AI orang lain.
Dan hal ini, tidak terlalu jauh dari orang biasa.
Kode yang kamu tulis dengan AI, skema yang kamu ubah, bahan yang kamu kumpulkan, jika diberikan kembali akan menjadi pakan untuk model generasi berikutnya.
Dalam siklus ini, siapa berdiri di pundak siapa, garis batas itu semakin kabur.
Ketika AI mulai membantu kita menciptakan AI, bisakah kita masih membedakan, kemampuan itu sebenarnya milik siapa?
Referensi:
https://x.com/kimmonismus/status/2071591755351224344
https://www.theinformation.com/articles/internal-docs-show-meta-putting-limits-claude-codex-fearing-distillation
Artikel ini berasal dari akun WeChat "新智元", penulis: ASI启示录






