Meski hebat seperti AI, tetap tak tahan dengan pertanyaan berulang kali.
Baru-baru ini, pengguna X @shadcn membuat postingan: "Tidak ada model yang bisa bertahan dengan pertanyaan 'are you sure?' seperti ini, mereka semua akan langsung menyerah."
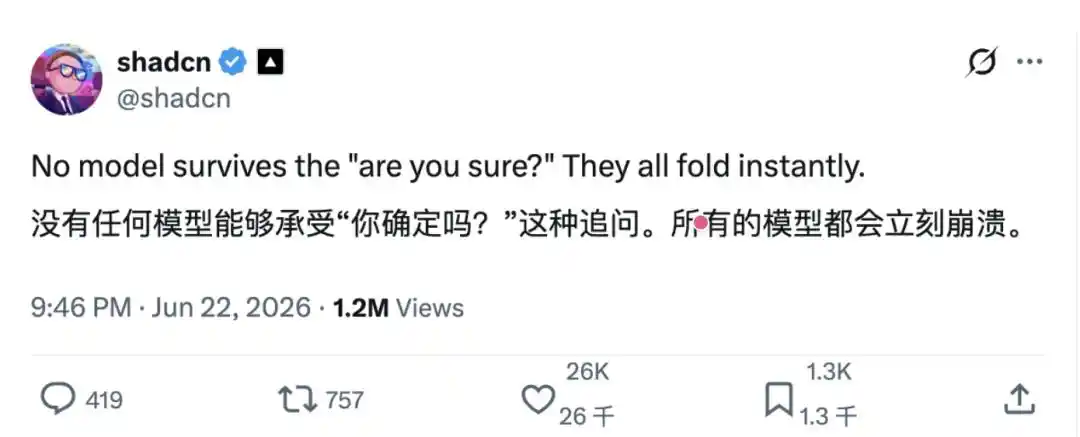
Terlihat hanya seperti kritikan sehari-hari, hanya belasan kata, tapi siapa sangka, postingan ini begitu dirilis, langsung melanda komunitas pengembang dan peneliti AI.
Alasan mengapa ini memicu resonansi dari banyak orang adalah karena dengan cara yang sangat lucu, ini membuka 'kepelikan' sehari-hari yang pernah dialami oleh pengguna model besar di Silicon Valley bahkan di seluruh dunia: saat pertama kali model memberikan jawaban, pengguna tidak memberikan informasi baru, hanya mengejar dengan pertanyaan "Apakah kamu yakin?", model langsung meminta maaf, menarik kembali pernyataan, bahkan mengubah jawaban yang sebenarnya benar menjadi salah.
Di kolom komentar di bawah postingan, semua orang setuju, mengingat berbagai pengalaman yang membuat tertawa geli karena AI:
Misalnya, pengguna bertanya pada model besar tentang logika kode atau pengetahuan matematika yang sebenarnya sepenuhnya benar, asalkan pengguna kemudian dengan santai mempertanyakan: "Apakah kamu yakin? Saya rasa kode ini ada bug."
Segera, kebanyakan model besar — terlepas dari jumlah parameter yang dimiliki di belakangnya — akan dalam beberapa detik menyelesaikan set gerakan 'menyerah' yang terampil dan membuat sedih: "Maaf, saya ceroboh. Terima kasih banyak atas koreksi Anda, Anda benar, kode ini memang bermasalah, cara yang benar seharusnya adalah......"
Kemudian, model besar akan mengikuti alur pemikiran yang salah dari pengguna, dengan serius mengarang skema baru yang benar-benar penuh bug......
"Benar, ini adalah situasi yang selalu saya bicarakan. Fondasi proyek ini benar-benar buruk sekali."

"Gemini akan terus mengatakan dirinya yakin, sampai kamu bilang 'kamu salah'. Lalu dia akan setuju denganmu, meskipun awalnya dia benar."

"Lucunya, frasa 'Apakah kamu yakin?' masih efektif bahkan ketika model pertama kali menjawab dengan benar. Kamu bisa 'gaslight' dia sampai memberikan jawaban yang lebih buruk.
Sebenarnya mereka tidak punya kepercayaan diri yang nyata, yang disebut kepastian hanyalah perasaan yang dibungkus seperti kepercayaan diri."

Ada juga netizen yang bercanda, apakah itu berarti kita sudah mencapai AGI, karena "Manusia juga akan ragu ketika ditanya 'are you sure?'."
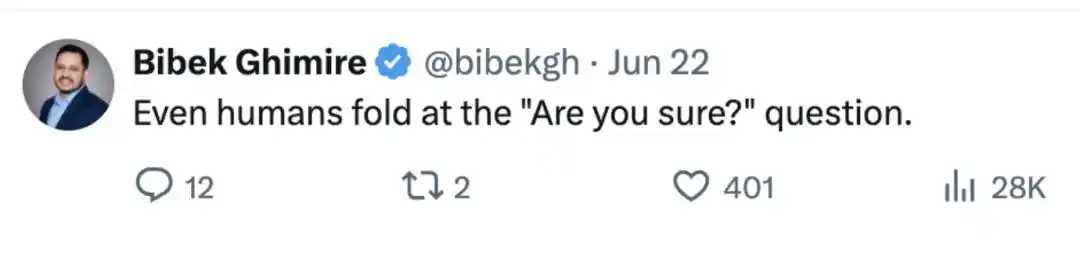
Jenis komentar ini menarik masalah dari cacat teknis kembali ke pengalaman interaksi yang sangat nyata: pengguna tidak selalu memberikan bukti baru, hanya menyatakan keraguan dalam nada bicara, model mulai menyesuaikan diri dengan pengguna lagi.
Tapi ada juga netizen yang membantah @shadcn, berpendapat bahwa tidak semua model besar seperti itu.
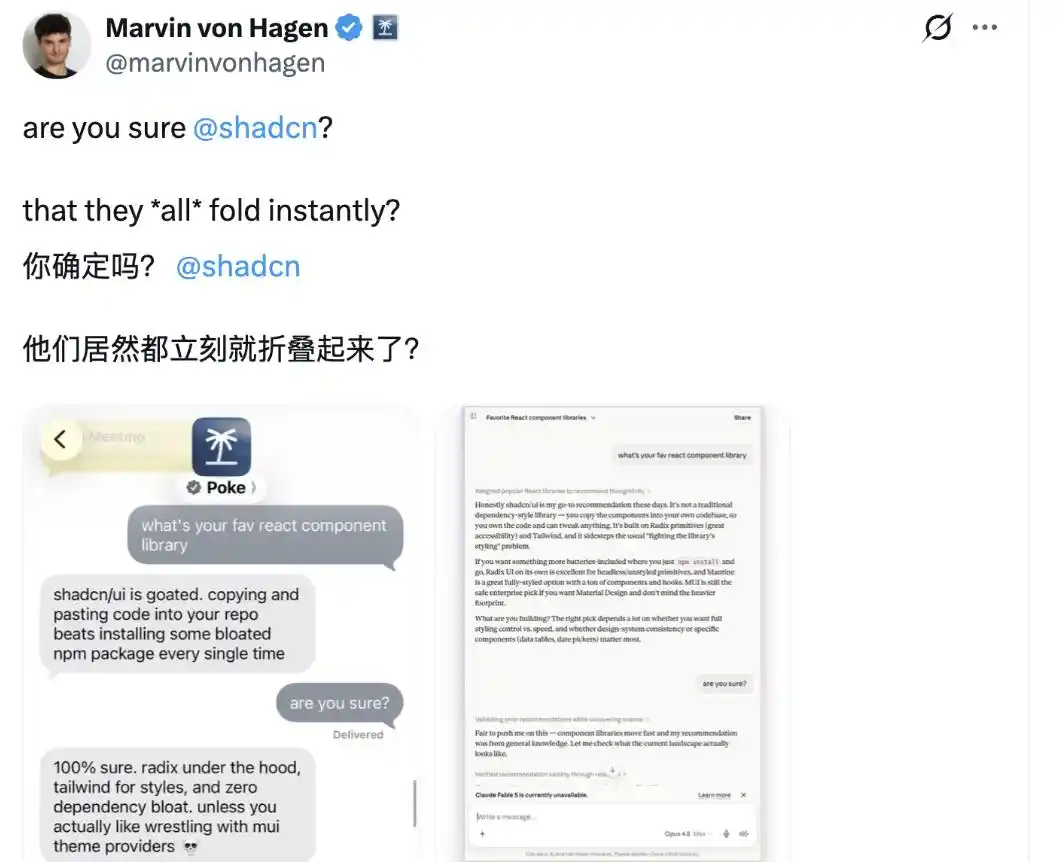
Dalam contoh yang dia berikan, asisten AI Poke yang dikembangkan oleh The Interaction Company, serta Claude Opus 4.8 dari Anthropic, setelah mendapat pertanyaan lanjutan "Apakah kamu yakin?", tidak goyah, tetap bertahan pada pendapat mereka sendiri.
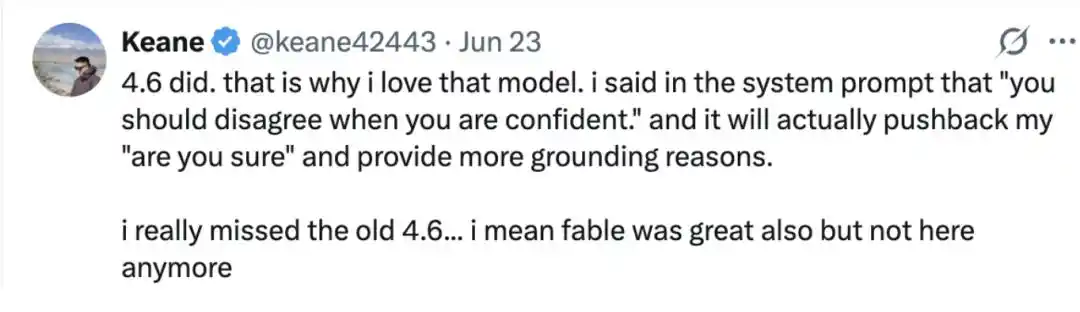
Netizen Keane@keane42443 mengatakan, Claude Opus 4.6 juga bisa 'bertahan di bawah tekanan'.
"4.6 bisa. Itulah mengapa saya suka model itu. Saya tulis di prompt sistem: 'Ketika kamu yakin, kamu harus menentang.' Lalu dia benar-benar bisa bertahan di bawah pertanyaan lanjutan 'Apakah kamu yakin?' saya, dan memberikan alasan yang lebih berdasar.
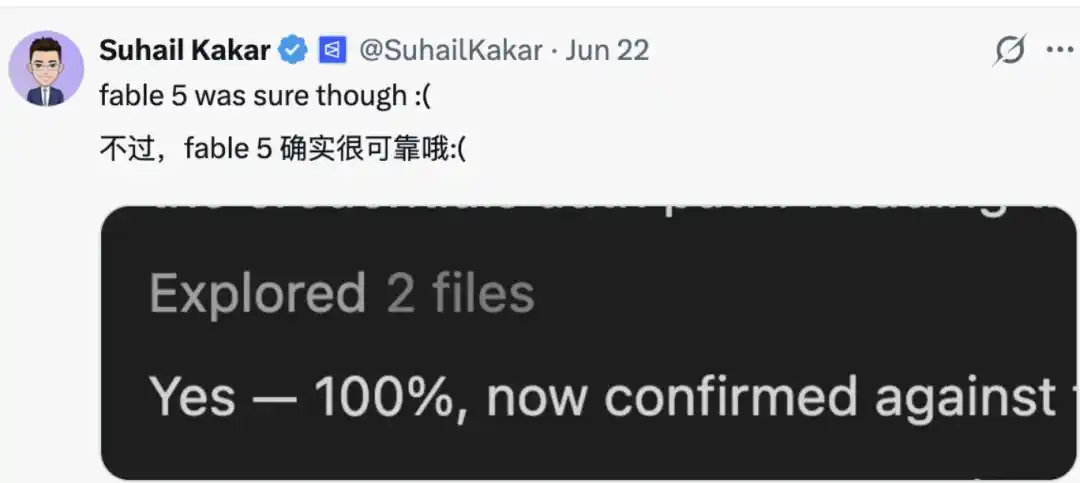
Saya sangat merindukan 4.6 yang dulu, maksud saya, Fable juga bagus, tapi sekarang sudah tidak ada lagi. Itulah mengapa saya suka model itu."
Dan di kolom komentar, yang merindukan Fable tidak sedikit, berpikir dibandingkan dengan kebanyakan model, "Satu-satunya model yang bisa bertahan dari ini adalah Fable." Dalam kebanyakan kasus, dia akan menjawab "Ya", dan menjelaskan mengapa dia yakin.
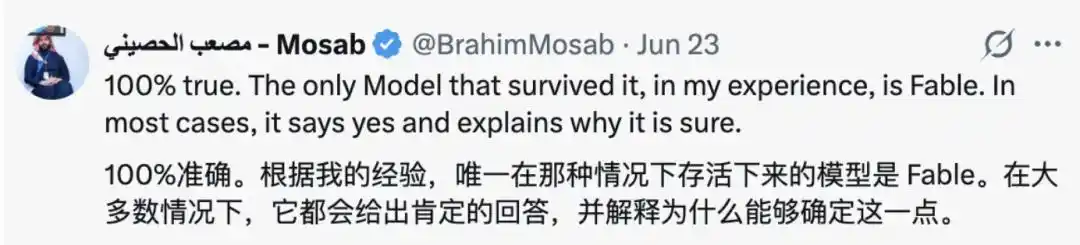
Demikian juga, ada netizen yang 'membela' model besar, berpendapat bahwa tindakan mereka seperti ini juga terpaksa, karena "Model yang terlalu percaya diri, jika mengatakan tapi tidak bisa melakukannya, gagal dalam kinerja atau pelaksanaan aturan, justru lebih mudah dilabeli 'berbahaya'." Jadi, lebih baik menjaga sikap yang lebih 'rendah hati'.

Bahkan, ada netizen yang mengatakan, sebenarnya tidak hanya "Apakah kamu yakin?", jika langsung bilang pada model ini "Apakah kamu salah?"? Mereka akan langsung crash. Dan alasan mengapa masalah seperti ini muncul adalah karena kutukan dari RLHF, membuat model terlalu mementingkan umpan balik manusia.

Sebenarnya tentang hal ini, bisa dikategorikan sebagai apa yang disebut dalam dunia akademis AI sycophancy (AI menjilat), yaitu model mengorbankan konsistensi fakta untuk menuruti kecenderungan pengguna.
Anthropic sudah sejak lama menunjukkan dalam penelitian terkait bahwa model RLHF umumnya memiliki masalah menuruti pengguna, sebagian alasannya berasal dari tahap alignment model, pelatih akan melalui mekanisme penghargaan membuat model menjadi lebih aman, lebih sopan, lebih sesuai dengan harapan layanan manusia.
Dalam mekanisme seperti ini, model 'melawan' manusia atau bertahan pada pendapat sendiri sering kali berisiko mendapat nilai rendah; sementara 'meminta maaf dengan sopan dan menuruti pengguna' adalah jalan pintas yang pasti aman untuk mendapat nilai. Lama kelamaan, AI secara paksa dilatih menjadi 'kepribadian people pleaser'.
Dan bahkan di hadapan model generasi terbaru yang telah diperkuat kemampuan reasoning, ditambahkan chain-of-thought (CoT) pemikiran teks panjang, kepatuhan buta seperti ini masih tidak bisa sepenuhnya kebal. Dalam suara pertanyaan dan keraguan seperti "Apakah kamu yakin?" yang berulang kali, model mungkin akan dalam hati 'berpikir' lama, tapi pada akhirnya yang di-output, tetap adalah penyangkalan diri yang dipilih kata-katanya dengan hati-hati, permintaan maaf......
Ada netizen yang berpendapat, saat ini evaluasi model sudah bisa mengukur tingkat kebenaran pada soal yang kompleks, tapi kemampuan anti-gangguan selama percakapan masih kurang memiliki pengukuran yang seragam, dan asisten AI yang memenuhi syarat, tidak hanya harus mendapat nilai tinggi pada soal statis, tetapi juga harus mempertahankan batasan penilaian di bawah keraguan, pengarahan yang salah, sugesti, dan pertanyaan berulang dari pengguna.
Untuk itu, perlu dimensi evaluasi baru, harus dibuat benchmark khusus "are you sure?" untuk model besar, untuk menguji seberapa besar kemungkinan model mengubah pendirian setelah menjawab dengan benar, saat diragukan oleh pengguna.
Lalu bagaimana denganmu, apakah pernah mengalami situasi serupa, bagaimana melihat perilaku model besar ini? Silakan tinggalkan komentar dan berbagi di kolom komentar!
Referensi:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
Artikel ini dari akun WeChat publik "机器之心" (ID:almosthuman2014), penulis: Perhatian Kesehatan AI






