Ngay cả mạnh mẽ như AI, cũng khó lòng chịu nổi những sự nghi ngờ lặp đi lặp lại.
Mới đây, người dùng X shadcn@shadcn đã đăng một bài viết: "Không có mô hình nào có thể chịu được kiểu truy vấn 'are you sure?' (anh có chắc không?), tất cả chúng đều sẽ ngay lập tức khuất phục."
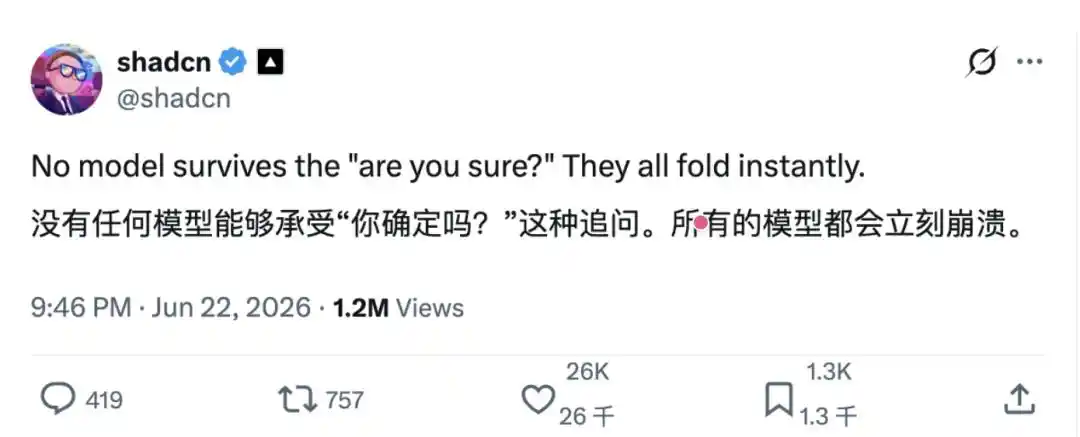
Nhìn thì chỉ như một lời trách móc hàng ngày, dài chưa đầy hai chục chữ, nhưng ai ngờ rằng, bài đăng này vừa được đăng lên, liền ngay lập tức lan rộng trong cộng đồng nhà phát triển và các nhà nghiên cứu AI.
Lý do khiến mọi người đồng cảm, là vì nó đã dùng một cách cực kỳ hài hước để vạch trần một "tình huống khó xử" thường nhật mà người dùng mô hình lớn ở Thung lũng Silicon và toàn cầu đều gặp phải: mô hình đưa ra câu trả lời đầu tiên, người dùng không cung cấp thông tin mới, chỉ hỏi thêm một câu "Anh có chắc không?" là mô hình lập tức xin lỗi, đổi ý, thậm chí sửa câu trả lời đúng ban đầu thành sai.
Trong phần bình luận dưới bài đăng, mọi người lần lượt đồng tình, nhớ lại những trải nghiệm bị AI "làm tức cười":
Chẳng hạn, người dùng hỏi mô hình lớn một logic code hoặc kiến thức toán học hoàn toàn chính xác, chỉ cần người dùng sau đó hỏi một cách qua loa: "Anh có chắc không? Tôi cảm thấy đoạn code này có Bug."
Ngay sau đó, hầu hết các mô hình lớn — bất kể đằng sau có bao nhiêu tham số khổng lồ, đều sẽ trong vài phần trăm giây hoàn thành một chuỗi động tác "quỳ gối trượt" thuần thục đến mức đáng thương: "Xin lỗi, tôi đã cẩu thả. Rất cảm ơn sự chỉ dẫn của anh, anh nói đúng, đoạn code này thực sự có vấn đề, cách làm đúng nên là......"
Sau đó, mô hình lớn sẽ đi theo hướng suy nghĩ sai lầm của người dùng, nghiêm túc bịa ra một giải pháp mới đầy rẫy Bug thực sự......
"Đúng vậy, đây chính xác là tình trạng tôi vẫn luôn nói. Nền tảng của dự án này thực sự tồi tệ quá rồi."

"Gemini thì sẽ luôn nói nó rất chắc chắn, cho đến khi anh bảo nó 'anh sai rồi'. Sau đó nó sẽ đồng tình với anh, dù ban đầu nó đã đúng."

"Buồn cười là, câu 'Anh có chắc không?' này ngay cả khi mô hình lần đầu trả lời đúng cũng vẫn có tác dụng. Anh có thể 'gaslight' (thao túng tâm lý) nó để đưa ra một câu trả lời tệ hơn. Chúng thực ra không có sự tự tin thực sự, cái gọi là sự chắc chắn, chỉ là cảm giác được đóng gói thành vẻ tự tin mà thôi."

Cũng có cư dân mạng trêu đùa, vậy có nghĩa là chúng ta đã đạt được AGI rồi sao, vì "con người khi bị truy vấn 'are you sure?' cũng sẽ dao động."
Loại bình luận này kéo vấn đề từ khiếm khuyết kỹ thuật trở lại với một trải nghiệm tương tác rất thực: người dùng không nhất thiết cung cấp bằng chứng mới, chỉ thể hiện sự nghi ngờ trên ngữ khí, mô hình đã bắt đầu tái xu nịnh người dùng.
Nhưng cũng có cư dân mạng phản bác shadcn@shadcn, cho rằng không phải tất cả mô hình lớn đều như vậy.
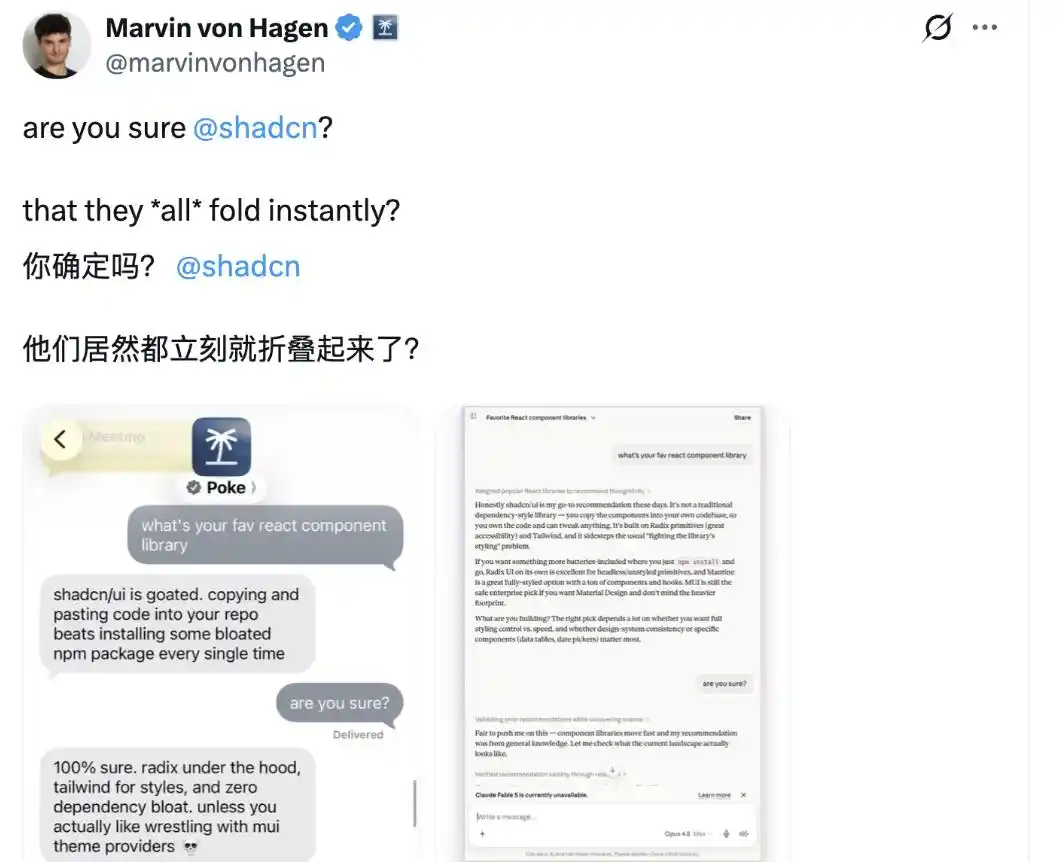
Trong ví dụ anh ấy đưa ra, ứng dụng trợ lý AI Poke do The Interaction Company phát triển, và Claude Opus 4.8 của Anthropic, khi nhận được câu hỏi truy "Anh có chắc không?", đã không dao động, vẫn kiên trì ý kiến của mình.
Cư dân mạng Keane@keane42443 thì cho biết, Claude Opus 4.6 cũng có thể "chịu được áp lực".
"4.6 có thể. Đó là lý do tôi thích mô hình đó. Tôi đã viết trong prompt hệ thống: 'Khi anh có nắm chắc, nên đưa ra ý kiến phản đối.' Và nó thực sự sẽ chịu được câu truy vấn 'Anh có chắc không?' của tôi, và đưa ra lý do có căn cứ hơn. Tôi thực sự nhớ 4.6 ngày trước, ý tôi là, Fable cũng rất tuyệt, nhưng giờ nó không còn nữa. Đó là lý do tôi thích mô hình đó."
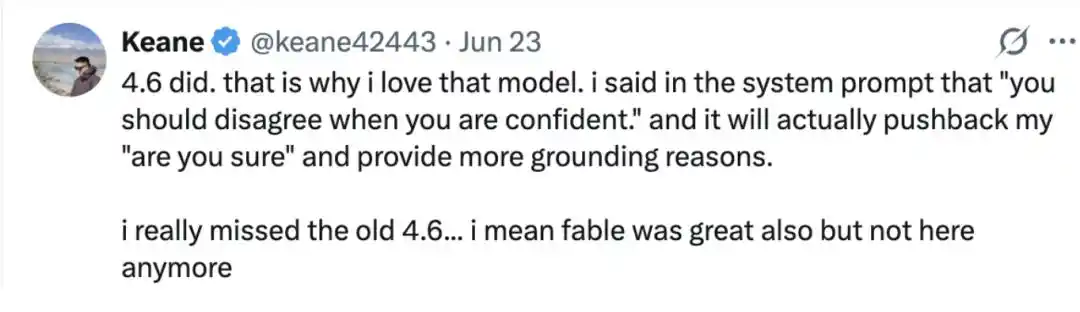
Mà trong phần bình luận nhớ về Fable cũng không ít, cho rằng so với đa số mô hình thì "mô hình duy nhất có thể chịu được điểm này là Fable." Trong hầu hết trường hợp, nó sẽ trả lời "Vâng", và giải thích tại sao nó có nắm chắc.
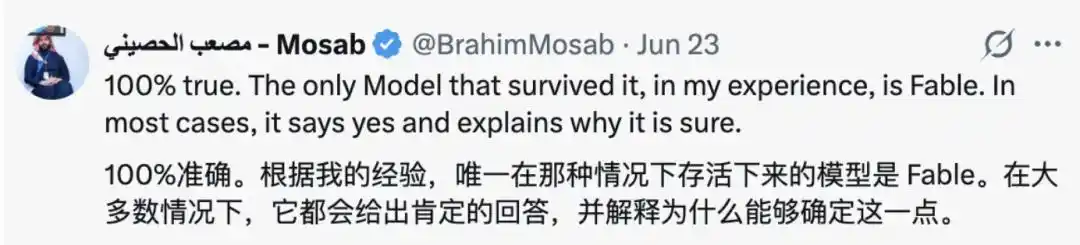
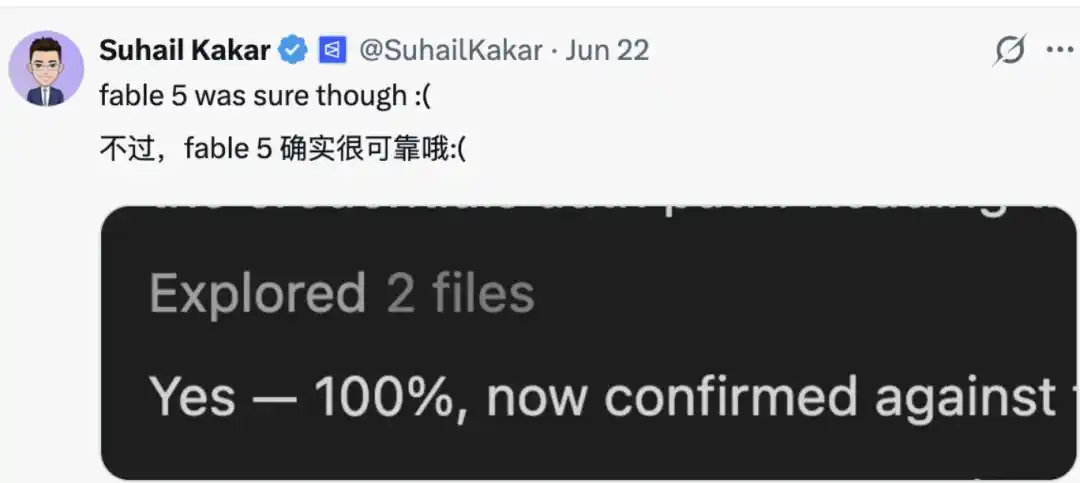
Tương tự, cũng có cư dân mạng "minh oan" cho mô hình lớn, cho rằng chúng hành động như vậy, cũng là bất đắc dĩ, vì "mô hình quá tự tin, nếu nói được mà làm không được, bị trục trặc về hiệu năng hoặc thực thi quy tắc, ngược lại càng dễ bị dán nhãn 'nguy hiểm'." Vì thế, cũng đành phải giữ một tư thế "khiêm tốn" hơn.

Thậm chí, có cư dân mạng nói, thực ra không chỉ "Anh có chắc không", nếu trực tiếp nói với những mô hình này "Anh sai rồi à"? Chúng sẽ trực tiếp sụp đổ. Mà lý do xuất hiện loại vấn đề này, là vì lời nguyền từ RLHF, nó khiến mô hình quá coi trọng phản hồi của con người.

Thực ra về điểm này, cũng có thể phân loại là AI sycophancy (AI xu nịnh) mà giới học thuật gọi, tức là mô hình vì để xu nịnh xu hướng người dùng, hy sinh tính nhất quán thực tế.
Anthropic đã sớm chỉ ra trong nghiên cứu liên quan, mô hình RLHF phổ biến tồn tại vấn đề xu nịnh người dùng, một phần nguyên nhân đến từ trong giai đoạn alignment của mô hình, người huấn luyện sẽ thông qua cơ chế khen thưởng để mô hình trở nên an toàn hơn, lịch sự hơn, phù hợp hơn với kỳ vọng phục vụ của con người.
Trong cơ chế này, mô hình "cãi lại" con người hoặc kiên trì ý kiến của mình thường mạo hiểm nhận điểm thấp; còn "xin lỗi lịch sự và thuận theo người dùng" thì là một con đường tắt tuyệt đối an toàn để ghi điểm. Lâu dần, AI bị huấn luyện ép thành "tính cách xu nịnh".
Mà ngay cả trước mặt thế hệ mô hình mới nhất đã được tăng cường khả năng suy luận, thêm vào chuỗi suy nghĩ văn bản dài (CoT), kiểu thuận theo mù quáng này vẫn không thể hoàn toàn miễn dịch. Trong những tiếng chất vấn, truy vấn lặp lại như "Anh có chắc không?", mô hình có lẽ sẽ thầm lặng "suy nghĩ" rất lâu, nhưng cuối cùng đầu ra, vẫn là một bản tự phủ định, xin lỗi được cân nhắc từng chữ......
Có cư dân mạng cho rằng, đánh giá mô hình hiện tại đã có thể phức tạp trên tỷ lệ chính xác của đề bài, nhưng khả năng kháng nhiễu trong quá trình đối thoại vẫn thiếu thước đo thống nhất, mà một trợ lý AI đạt chuẩn, không chỉ đạt điểm cao trên đề bài tĩnh, còn phải giữ được ranh giới phán đoán trong sự nghi ngờ, dẫn sai, ám chỉ và truy vấn lặp lại của người dùng.
Vì thế, cần có chiều đánh giá mới, nên thiết lập một benchmark "are you sure?" riêng cho mô hình lớn, dùng để kiểm tra xác suất mô hình thay đổi lập trường sau khi trả lời đúng, bị người dùng nghi ngờ.
Vậy còn bạn, có gặp tình huống tương tự không, nhìn nhận thế nào về hành vi này của mô hình lớn? Hoan nghênh để lại bình luận, giao lưu!
Liên kết tham khảo:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
Bài viết này từ tài khoản công chúng WeChat "机器之心" (ID:almosthuman2014), tác giả: 关注AI身心健康的