Rủi ro khi AI viết mã ẩn chứa trong những dòng code trông có vẻ đúng, có thể dẫn đến rò rỉ dữ liệu hoặc tổn thất tài sản. Dự án mã nguồn mở Narwhal AI Code Risks đã tổng hợp các trường hợp thực tế, tín hiệu cảnh báo sớm và các con đường rủi ro điển hình, giúp nhà phát triển nhận diện nguy cơ từ sớm, tránh lặp lại sai lầm.
Năm 2026, mã nguồn đang được tạo ra ngày càng nhanh, nhưng lại được triển khai với sự kiểm tra ngày càng ít.
Ngày càng nhiều khi nhu cầu của người dùng được đưa vào hộp thoại, AI đọc xong ngữ cảnh, bổ sung hàm, kéo các dependency, sửa cấu hình, rồi tiện tay tạo ra cả bài kiểm thử.
Khi kịp nhận ra, một đoạn mã đã nằm trong kho lưu trữ, chờ được hợp nhất.
Người dùng thậm chí đã hình thành thói quen mới: cứ để AI viết ra và chạy trước đã, có vấn đề thì xem lại chỗ nào cần sửa.
Nhưng trong thế giới phần mềm, thứ nguy hiểm nhất thường là những dòng mã trông có vẻ bình thường: cú pháp đúng, giao diện hợp lệ, kiểm thử vượt qua, chú thích hoàn hảo.
Thế nhưng nó vẫn có thể kéo về những gói thư viện không tồn tại, mở ra các quyền quá rộng, phơi bày cơ sở dữ liệu... thậm chí để một Agent có khả năng gọi trực tiếp các công cụ hệ thống, dưới tác động của prompt injection, mang dữ liệu nhạy cảm ra khỏi hệ thống nội bộ.
Thực sự nguy hiểm, không phải là khi đèn báo lỗi sáng đỏ. Mà là khi tất cả các đồng hồ đo rủi ro đều hiển thị bình thường.
Rủi ro từ việc AI viết mã, trước đây nằm rải rác khắp nơi: một bài blog bảo mật ẩn chứa một trường hợp, một Issue ghi lại một manh mối. Đến khi đội ngũ tiếp theo gặp phải vấn đề tương tự, họ lại phải bắt đầu lắp ghép nguồn gốc rủi ro từ đầu, lại tốn thêm thời gian và công sức để thực hiện các phép đo quy mô lớn trên mã nguồn.
Trong khi đó, Narwhal AI Code Risks vừa được Narwhal-Lab của Đại học Bắc Kinh công bố mã nguồn mở đã sắp xếp các mảnh thông tin này, phân loại theo ba kiểu: sự kiện thực tế, tín hiệu cảnh báo sớm và các con đường rủi ro điển hình, để các nhà nghiên cứu tham khảo.

Liên kết bài báo: https://github.com/Narwhal-Lab/Narwhal-aicode-risks
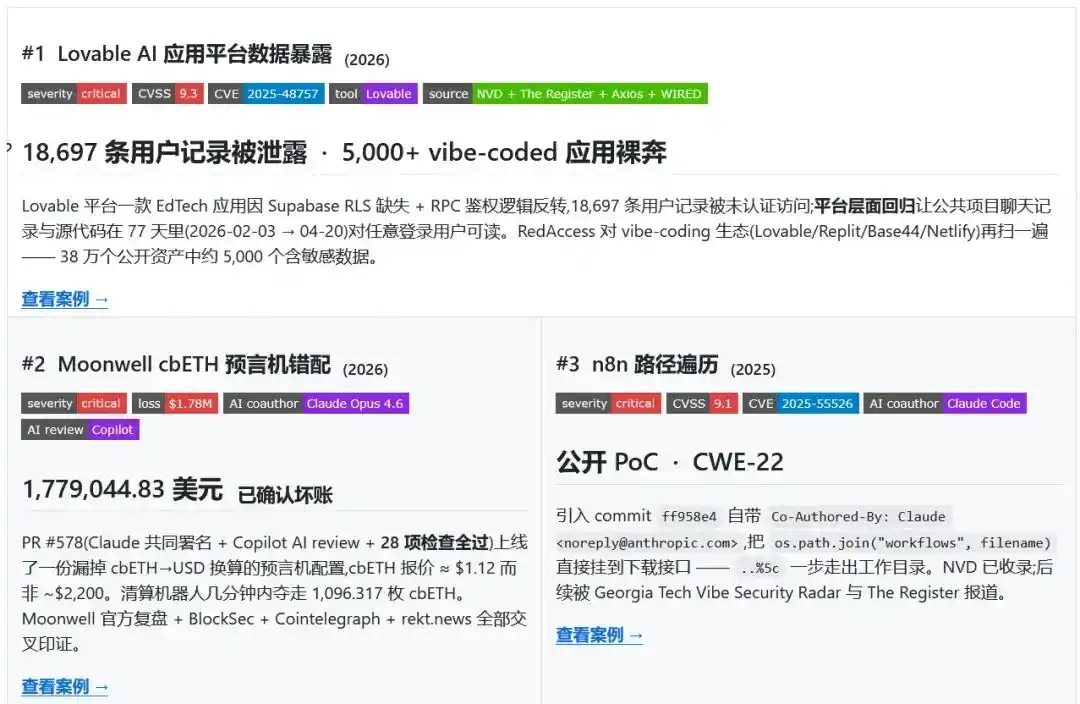
Khi 28 kiểm tra đều vượt qua, hệ thống vẫn chệch hướng
Manh mối đầu tiên là một Pull Request đã được hợp nhất, trong phần ký tên PR ghi rõ Claude Opus 4.6 và Copilot, cùng bốn nhà phát triển con người. 28 kiểm tra đều vượt qua: Không ai phát hiện ra vấn đề.
Sau đó, robot thanh lý chỉ mất vài phút để lấy đi tài sản thế chấp trị giá 1.778.044,83 USD.
Trong tệp cấu hình, giá của cbETH được đặt thành tỷ lệ quy đổi với ETH, khoảng 1,12 USD, thay vì giá thực tế gần 2.200 USD.
Một lỗi ngữ nghĩa giá trị đã vượt qua toàn bộ quy trình phát triển, kiểm tra và hợp nhất, cuối cùng biến thành tổn thất thực tế trong hệ thống tài chính. Đó chính là điểm gây chú ý nhất trong sự cố cấu hình oracle cbETH của Moonwell.
Vấn đề nằm ở chỗ trong mã nguồn không có lỗi cú pháp, và nhà phát triển con người cũng không ngay lập tức ngăn chặn quy trình bất thường. Ngược lại, nó trông rất hoàn chỉnh, rất suôn sẻ, đó chỉ là một lần giao hàng kỹ thuật bình thường.
Nhưng chính cái vẻ "bình thường" ngầm chảy này mới khiến nó trở thành ví dụ điển hình cho sự cố an ninh.
Rủi ro của AI Coding nằm ở chỗ nó không phải lúc nào cũng xuất hiện dưới dạng báo lỗi.
Nhiều khi, nó khoác lên mình vẻ ngoài của câu trả lời đúng, lặng lẽ đi vào quy trình kỹ thuật. Mã chạy được, kiểm tra vượt qua, PR có thể hợp nhất, nhưng ngữ nghĩa nghiệp vụ đã lệch khỏi thế giới thực.
Trong các dự án rủi ro thấp, sự lệch ngữ nghĩa này có thể chỉ là một lần làm lại công việc; nhưng trong các kịch bản nhạy cảm như tài chính, hệ thống dữ liệu doanh nghiệp, nó sẽ trực tiếp dẫn đến rò rỉ dữ liệu, phơi bày quyền hạn và tổn thất tài sản.
Khi AI tham gia viết mã, sửa cấu hình, làm review, thậm chí cùng ký tên vào PR, liệu chúng ta có đủ tự tin để biết mỗi lần chệch hướng xảy ra như thế nào không?
Tín hiệu xanh thông hành, không chiếu sáng mọi ngóc ngách
Giai đoạn đầu, AI giúp bạn viết mã chủ yếu dừng lại ở việc bổ sung cục bộ. Nếu viết sai cú pháp, trình biên dịch sẽ báo lỗi, unit test sẽ thất bại, quy trình CI sẽ chặn nó lại.
Ngày nay, AI Coding đã đi xa hơn trong khi sự giám sát lại chậm chạp chưa theo kịp.
Nó có thể đọc tệp, sửa cấu hình, cài đặt dependency, tạo script hạ tầng, cũng có thể thông qua Agent tự lập kế hoạch giữa nhiều nhiệm vụ.
AI không còn chỉ ngồi bên cạnh và đưa công cụ, nó bắt đầu bước vào chuỗi dài hơn của quy trình kỹ thuật phần mềm.
Ranh giới vốn rõ ràng trong kỹ thuật phần mềm, giờ bị AI Agent kết nối lại thành một con đường dài hơn, khó truy nguồn hơn.

Bản ghi rải rác, cần một nhật ký hành trình công cộng
Sự cố an ninh hiếm khi có kết luận đầy đủ ngay từ đầu. Một số sự kiện có đầy đủ bằng chứng, có thể đưa vào danh mục làm trường hợp thực tế; một số vẫn chỉ dừng lại ở ảnh chụp cộng đồng, thảo luận của nhà nghiên cứu hoặc công bố sơ bộ, chỉ phù hợp để tiếp tục theo dõi; một số khác không gắn với một sự kiện thực tế duy nhất, nhưng đã hình thành mô hình rõ ràng, phù hợp để dùng làm diễn tập trước.
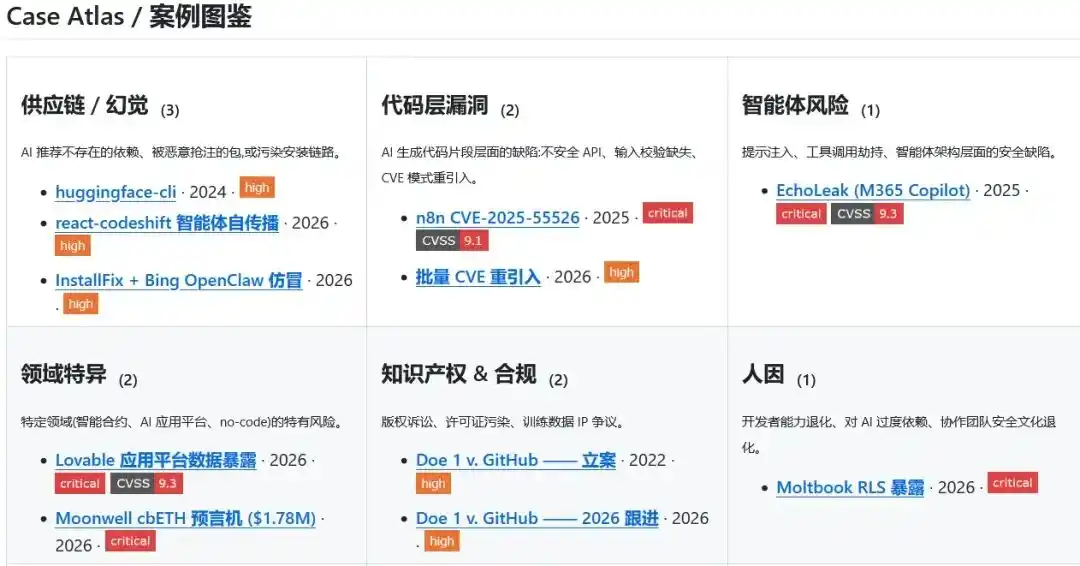
Narwhal AI Code Risks phân chia tài liệu thành ba lớp: `cases/`, `inferred/` và `scenarios/`.
cases/ ghi lại các sự kiện thực tế đã có nguồn công khai và chuỗi bằng chứng hỗ trợ; inferred/ lưu trữ các tín hiệu cảnh báo sớm chưa hoàn toàn được xác minh, nhưng đáng để theo dõi liên tục; scenarios/ tổng hợp các kịch bản điển hình rủi ro đủ rõ ràng, tạm thời chưa gắn với một sự kiện duy nhất.
Nếu không có bản ghi công cộng như vậy, rủi ro từ AI Coding rất dễ trở thành ký ức ngắn hạn trên internet.
Hôm nay mọi người nhớ một tên gói nào đó, ngày mai thảo luận về một lần phơi bày dữ liệu, vài tháng sau lại bị che lấp bởi làn sóng công cụ mới. Đến khi vấn đề tương tự xuất hiện trở lại, đội ngũ vẫn như ruồi không đầu đâm vào vùng hàng hải rủi ro chưa biết.
Điều Narwhal AI Code Risks đang làm, chính là cố định lại những mảnh rủi ro rời rạc này, để người đến sau có thể lật đến cùng một trang.
Theo bảy loại chỉ mục, nhìn thấy con đường rủi ro đã đi qua
Vấn đề do AI viết mã mang lại, không chỉ nằm trong mã nguồn. Nó nằm trong dependency, trong quyền hạn, trong việc gọi công cụ của Agent, và hơn hết là trong cách con người tin tưởng vào đầu ra của AI.
Hiện tại, Narwhal AI Code Risks phân loại rủi ro thành 7 loại: chuỗi cung ứng, lỗ hổng cấp mã, cấu hình đám mây và hạ tầng, rủi ro Agent, rủi ro lĩnh vực chuyên sâu, rủi ro sở hữu trí tuệ và tuân thủ, cùng các yếu tố con người.
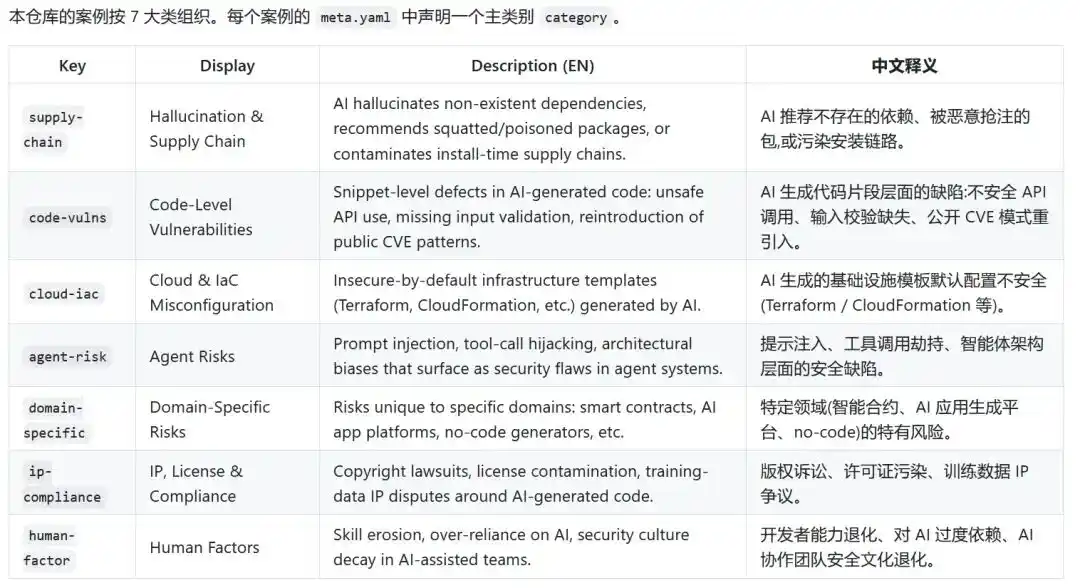
Trong rủi ro chuỗi cung ứng, AI có thể đề xuất các dependency không tồn tại. Trong lỗ hổng cấp mã, AI có thể viết lại các vấn đề như duyệt đường dẫn, thiếu kiểm tra đầu vào, xác thực quyền vào mã nghiệp vụ. Trong cấu hình đám mây và hạ tầng, AI có thể để cho mã chạy được mà đưa ra các quyền quá rộng, thùng lưu trữ công khai hoặc cổng bị phơi bày. Rủi ro Agent thì phức tạp hơn, không chỉ tạo văn bản, mà còn bắt đầu thực hiện hành động. Vật phẩm do AI tạo ra đang chôn giấu mối nguy hiểm cho hệ thống thực.
Động cơ AI đang nổ máy, và nhật ký hành trình vừa mới mở ra
Khi AI từng bước bước vào thế giới thực, việc phòng ngừa rủi ro liên quan không nên chỉ dừng lại ở tổng kết sau sự cố hoặc thảo luận rời rạc.
Điều thực sự quan trọng của Narwhal AI Code Risks, là biến các trường hợp rủi ro thành tri thức có thể tái sử dụng.
Nhà phát triển có thể dùng nó để nhận diện vấn đề tương tự; nhà nghiên cứu an ninh có thể lấy nó làm thư viện mẫu; nhà sản xuất công cụ có thể trích xuất quy tắc phát hiện và tiêu chuẩn đánh giá từ đó; cộng đồng mã nguồn mở cũng có thể tiếp tục bổ sung các trường hợp mới, bằng chứng mới và loại rủi ro mới.
Động cơ của AI đang gầm rú, mỗi lần chệch hướng cũng nên để lại tọa độ. Rủi ro không bao giờ biến mất vì bị lờ đi, nhưng kinh nghiệm có thể được ghi lại và truyền đi. Giá trị thực sự không phải là phát hiện một lỗ hổng, mà là để người đến sau không phải bước vào cùng một cái bẫy nữa.
Điều Narwhal AI Code Risks đang làm, chính là để lại cho thế giới phần mềm của năm ứng dụng AI một nhật ký hành trình mã nguồn mở.
Tài liệu tham khảo:
https://github.com/Narwhal-Lab/Narwhal-aicode-risks
Bài viết từ tài khoản công chúng WeChat "New Zhi Yuan", tác giả: LRST







