A $500 Million Bill in Just 1 Month!
Recently, a shocking blunder erupted in the tech world. According to Axios, a company actually managed to rack up a $500 million bill on Claude in just one month!
The reason is laughable: management forgot to set usage limits when granting employees access to Claude accounts.

In fact, this isn't the only case of AI bills exploding.
In April, a Google Cloud user, whose publicly accessible API key was misused, received a bill for $18,000 overnight, despite having only a $7 budget set.

The unlucky user, Jesse Davies, is an Australian AI consultant and founder of Agentic Labs. He had set up two safeguards for his Google Cloud account: a A$10 (about $7) budget alert and a hard spending cap of $1,400.
As reported by Tom's Hardware, attackers discovered a Cloud Run service he had deployed months earlier from AI Studio, sending over 60,000 requests. Both safeguards failed: there was a delay in billing calculations, and by the time the system reacted, the amount had skyrocketed to $18,000.
In mid-May, Peter Steinberger, founder of the open-source project OpenClaw, posted a screenshot on X: a $1.3 million OpenAI API bill for 30 days.
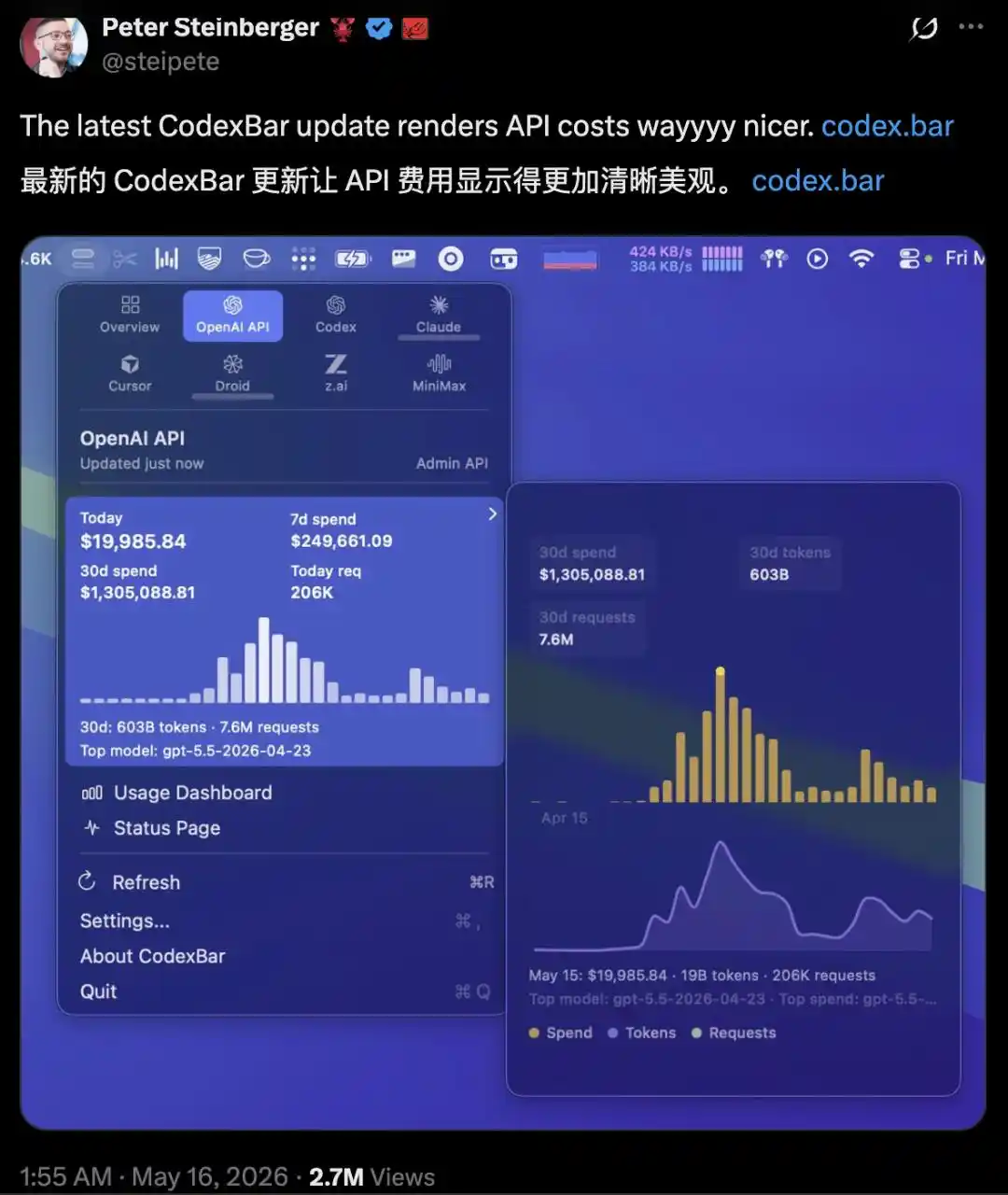
His team has only three people, but they orchestrated 100 Codex agents running in parallel: burning through 603 billion Tokens and making 7.6 million requests in 30 days. Fortunately, he didn't have to foot this $1.3 million bill himself.
Steinberger joined OpenAI this past February, and this $1.3 million was treated as an internal experiment:
to test the absolute limits of AI programming when token cost is not a consideration. He added that this was the result of Codex's "Fast Mode" (higher-tier billing); turning it off reduced the cost to about $300,000.
Even earlier, Uber's CTO Praveen Neppalli Naga had admitted to The Information that the company had exhausted its annual Claude Code budget by April, and their COO also publicly stated that AI costs were becoming increasingly "hard to justify."
$500 million, $1.3 million, $18,000—though these figures differ by orders of magnitude, they point to the same reality:
In the age of agents, any one of these—a compromised key, an army of agents running 24/7, or an account with forgotten limits—can blow up your token bill overnight.
Why Do AI Bills Explode?
The answer lies mainly in the shift in billing methods.
Starting April this year, OpenAI began transitioning from monthly flat fees to usage-based billing by Token.
On April 2, Codex billing shifted from per-message estimates to alignment with actual Token usage: Input, Cached Input, and Output Tokens are billed separately. On April 23, this rule was extended to all Enterprise, Edu, Health, and Gov plans: the invisible discount within the monthly fee was removed.
GitHub followed closely, just announcing: all Copilot plans will switch to usage-based billing effective June 1, 2026. The old premium request logic is scrapped, replaced with AI credits, settled based on actual consumption of Input, Output, and Cached Tokens against each model's API rate.

GitHub officially explained the reason for this change:
Currently, a quick chat question and a multi-hour autonomous coding task cost the user the same amount. GitHub has been subsidizing the heavy users, but this model is no longer sustainable.
Before the rise of AI agents, the costs of chat and completions were similar, and monthly fees could cover them.
After agents rose, a single task could run for hours and modify entire codebases, creating a cost difference of orders of magnitude between heavy and light users. The flat monthly fee model collapses in the face of such disparity.
The news sparked an uproar on Reddit and X.
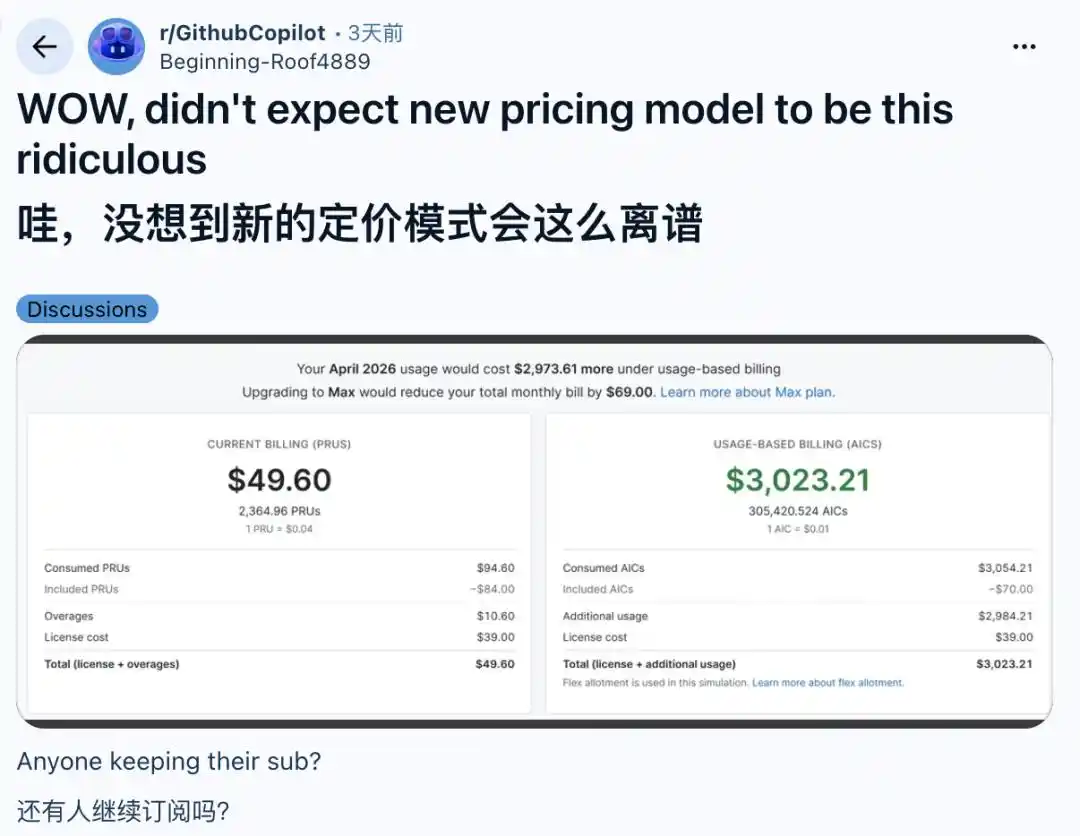
A developer with the ID JBusu shared a screenshot of their bill, bluntly calling the new pricing "a joke." Their previous monthly cost of $28.12 would become $746.01 under the new system. They've decided to cancel, "At this price, I could rent a cloud server myself and it would be cheaper."
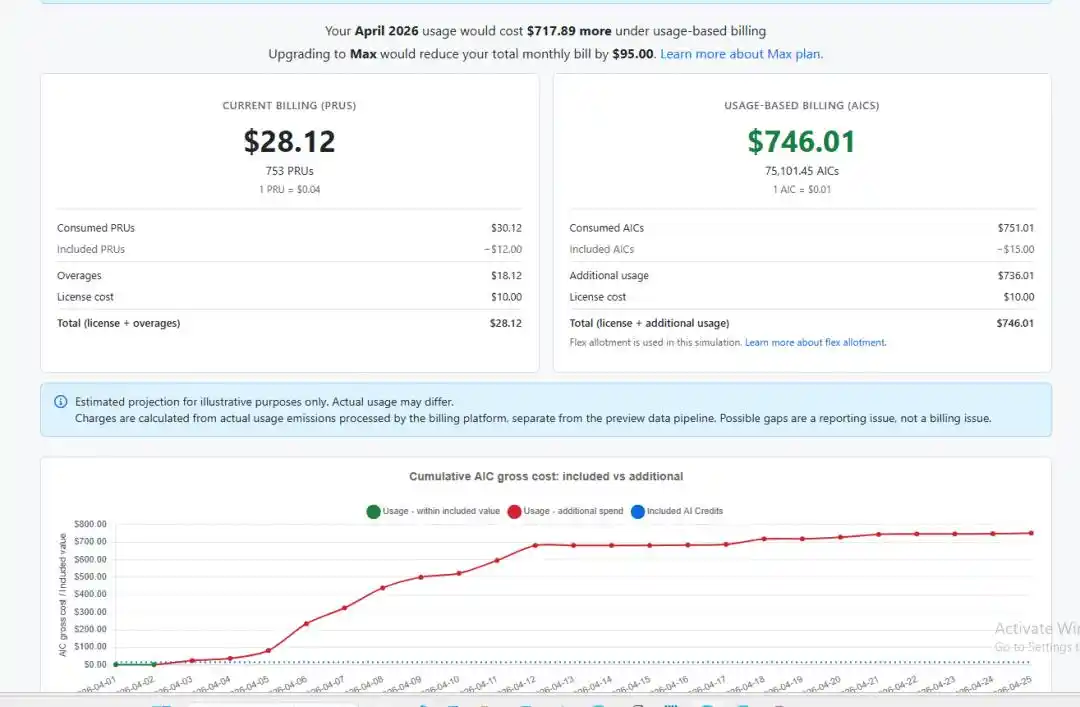
Another user shared an even more extreme screenshot, showing costs soaring from $50 to $3,000. They said they never expected pricing to be this outrageous, "Is anyone still subscribing?"
However, some veteran Copilot users countered: these extreme bills are likely burned by "vibe-coders" who aren't mindful of token usage and may not represent normal use.
One veteran user commented: "I use it all day long and rarely exceed limits by month-end. It's hard to believe this is due to differences in task complexity." Another was more direct: "It's people wanting fully automated YOLO-mode development, letting AI run wild. Culling this waste is actually good for everyone else."
One thing is clear: GitHub hasn't abolished monthly fees; the base subscription price remains unchanged. What has changed is that extra usage, agent tasks, and calls to more expensive models now fall under usage-based billing.
The hardest hit are those heavy agent users who rely on Copilot for long-chain tasks.
The Leaderboard Gamed by Its Own Users
The collapse of flat fees is partly due to platforms changing their billing rules, and partly because AI users themselves are burning through tokens.
In May, Business Insider reported that Amazon took down an internal AI usage leaderboard called KiroRank.
The report cited insiders saying the leaderboard quietly encouraged a strange work style: some employees, to climb the ranks, would burn tokens on tasks that didn't solve actual problems, purely for ranking.

After the story broke, Amazon SVP Dave Treadwell directly addressed all employees: "Don't use AI for the sake of using AI. Use it to solve customer problems, business problems, to innovate."
Though absurd, this is hardly surprising. When "burning tokens" gets you on a leaderboard, employees will naturally burn tokens.
Silicon Valley has coined a term for this phenomenon: Tokenmaxxing—treating consumption volume as productivity.
Axios's report also mentioned CTOs discovering employees using cutting-edge AI models to check the weather or write routine emails—trivial tasks that, when run on the most expensive frontier models, can silently send bills soaring.
KiroRank wasn't part of Amazon's official evaluation system but an informal tool built by employees. Yet it clearly exposes a classic management principle: when KPIs are set wrong, people will use the cleverest ways to game the system.
Equating "how much was used" with "how well it was done"—this is the systemic root of this wave of AI waste.
Those Who Count Tokens Are Already Making Money
On the flip side of token bill anxiety, some are quietly turning it into a business.
First approach: Feed the AI with context.
Glean is actually Arvind Jain's own company. It builds an enterprise AI work assistant: unifying knowledge scattered across a company, giving employees' AI direct context so they don't have to dig around. The AI takes fewer detours, naturally burning fewer tokens.
This mechanism helped Glean's annual revenue triple in 15 months, crossing $300 million, with clients including Databricks, Reddit, and Samsung.
Second approach: Delegate tasks to the right model.
This is what model routing startup Factory AI does: automatically routing each task to the most suitable model, cheap ones for simple tasks, top-tier for complex ones. Arvind also noted: Do routing right, and you can save 10x.
Both paths lead to the same destination: Let AI work, but don't let it burn money indiscriminately.
Academic research is also laying the groundwork for this shift.

https://arxiv.org/pdf/2604.22750
An arXiv paper from April 2026 systematically broke down how agent coding tasks actually burn money for the first time.
Conclusion One: Token consumption for agent tasks can be thousands of times higher than ordinary code reasoning or code chat, with Input Tokens being the main cost driver.
Conclusion Two: Running the same task multiple times can result in a 30x difference in Token consumption.
Conclusion Three: Higher Token consumption does not necessarily lead to higher accuracy. Accuracy often peaks at medium cost—burning more beyond that spends money without yielding better results.
The paper also found that even frontier models can't reliably predict their own token consumption, generally underestimating the real cost.
You think spending more gets more done. In reality, money is spent, the work isn't necessarily better, and the budget is still unpredictable.
When AI Bills Start Rivaling Labor Costs
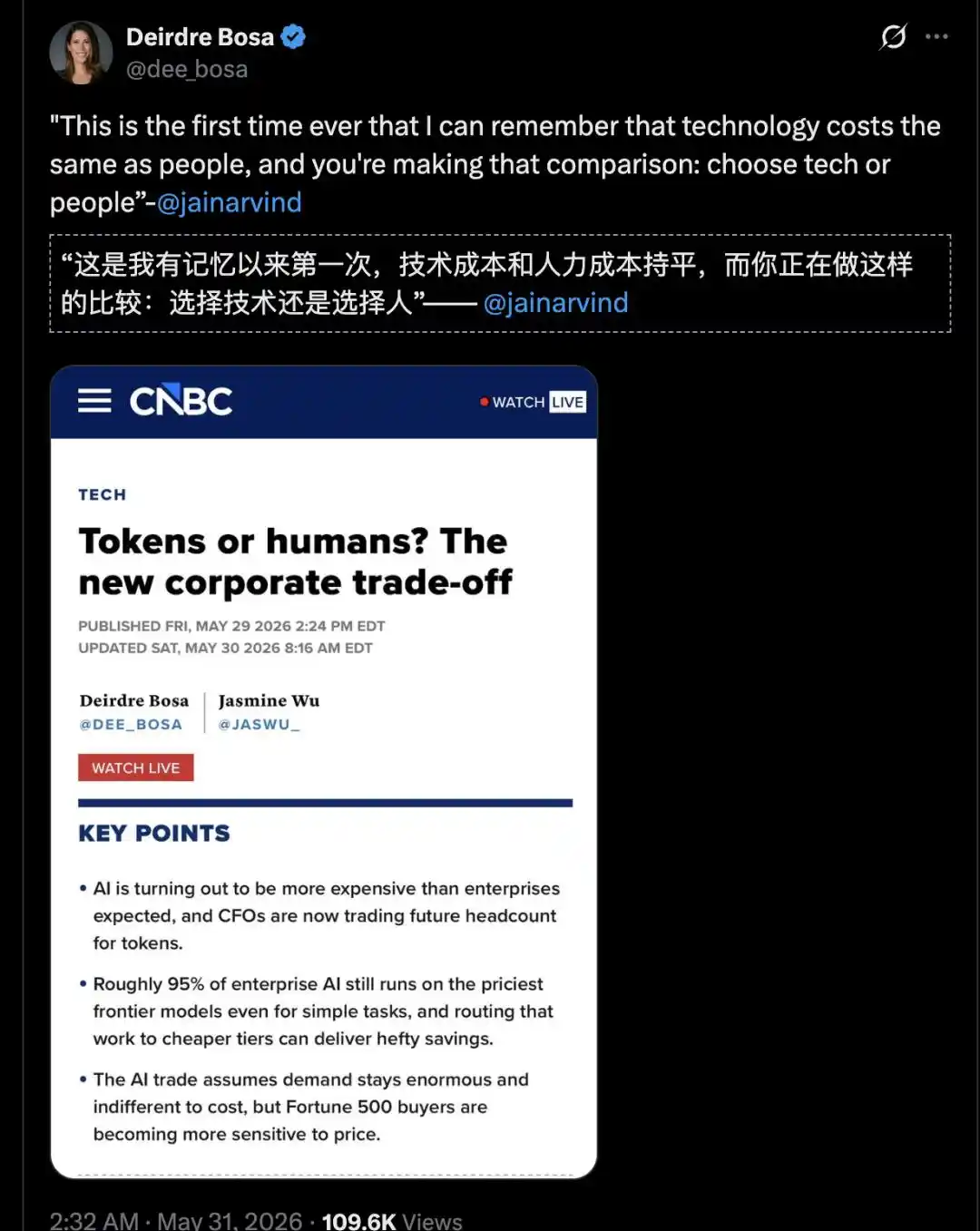
"This is the first time in my memory that technology costs are starting to be on par with human costs."
On May 29, Glean CEO Arvind Jain said this in an interview with CNBC's Deirdre Bosa.
Observations from Nvidia's Vice President of Applied Deep Learning, Bryan Catanzaro, corroborate this.
He mentioned in an Axios interview that for his team, compute costs far exceed employee salaries.
Similar trends are emerging across multiple companies: from enterprise AI player Glean, to AI compute seller Nvidia, to AI user Uber—all are re-evaluating this equation.
In Arvind's view, historically, technology was just a small slice of overall corporate costs. But now, AI costs are catching up to payrolls. Many companies' annual AI budgets are often burned through in just one or two months.

Over the past year, AI usage rate was a worshipped metric: more usage meant being advanced, burning tokens meant embracing the future. Now, many companies are reflecting on that simple question: What exactly did all those burned tokens buy?
The window of free or flat-rate unlimited usage is precisely closing at this moment.
Going forward, the question facing all developers is this: How to budget meticulously and maximize the value of every single Token.
Undoubtedly, the true winners of the future will be those who learn to count tokens first.
References:
https://x.com/dee_bosa/status/2060791500049613306%20
https://www.cnbc.com/2026/05/29/-tokens-or-humans-the-new-corporate-trade-off.html%20
https://www.axios.com/2026/05/28/ai-spending-roi-enterprise-costs%20
https://www.businessinsider.com/amazon-ai-leaderboard-tokenmaxxing-2026-5
This article is from the WeChat public account "AI Era Insights", author: ASI启示录






