Abstract
As the blockchain ecosystem evolves, the cost to use Ethereum has remained high. The scaling solution ,Rollup, requires uploading compressed transaction data to the Ethereum mainnet for data availability (DA), which incurs on-chain storage costs that remain above ideal levels. To meet demand for Rollup data availability and cost reduction, there have been attempts to build an independent DA network.
The DA network ensures that Rollup's transaction data is consistent with the data in its network, under the surveillance of the Ethereum verifier and its own full nodes. It also confirms that this data is published in its network through light node sampling verification and uses data availability attestation to convince Ethereum that the DA network has stored and published the data.
While the DA layer will encounter competition from EIP-4488 and EIP-4844 in the short term, its adoption and ability to generate relatively stable cash flow appears feasible in the long term due to its strong scalability.
From a broader perspective, the data availability layer is the latest step in the modularization process of blockchain, which forms a structure of "consensus-execution-data availability" separated from each other. Due to the trilemma of blockchain, the best way to improve scalability, while ensuring a high degree of decentralization and security, is to reduce the tasks of the mainnet and access additional execution layers, followed by a separate DA layer.
This has the advantage of making the performance of the whole greater than the sum of the parts by dividing the work. Modularized blockchains may better meet expectations in terms of performance and cost over time, and in turn lead other public chains to embrace modular
1 What is Data Availability?
1.1 Definition and Implication of Data Availability
With the blockchain ecosystem – especially for Ethereum – becoming more developed in the past two years, scaling has become a critical priority for a network buckling under an increasing volume of transactions. One approach of scaling is off-chain scaling, which means that ceteris paribus, the calculation is done off-chain, and only the state roots and other necessary information off-chain are synchronized to the chain. Since a large amount of computation takes place off-chain, it reduces the workload of the main Ethereum network and achieves the goal of processing more transactions at the same time. The most popular solution, Rollup, is the most promising for off-chain scaling, which involves uploading compressed transaction data to the mainnet to ensure that its state can be protected by the Ethereum network and enhance security.
As the scale of Rollups grows, the amount of data to be uploaded rises in tandem. On one hand this increases the burden on Ethereum, while on the other, it raises the cost of Rollups. To reduce the cost of Rollups and the pressure on Ethereum, a new idea is to create a separate network to store Rollup's transaction data exclusively at a lower cost. Ensuring that the transaction data is published to this network while granting easy access by Ethereum leads to the topic of this article: the data availability problem.
Data availability is the demand for transaction data in a blockchain network to be viewed and downloaded by nodes. It requires that all transaction data generated in a certain time period be located and witnessed by the whole network. On the flip side, it means that there is no transaction data which has been executed but not published. The issue of data availability is applicable to how nodes can monitor new block generation to ensure all data in that block is published to the network, and that the block generator is not hiding or misrepresenting information.
Data availability was not an issue initially since data is naturally available in a blockchain network. It was only after the scaling crossed a certain threshold that data availability became an inevitable topic of interest. Only by ensuring that all transaction data can be accessed and downloaded can Ethereum track and reconstruct the state on Rollup, and only then it is possible to store Rollup's transaction data in a separate data network, reducing Rollup’s storage cost and further promoting scaling.
In addition, data availability is inextricably linked to Rollup's security. in the event of data omission and irregularities in recording, the state of Rollup would not be discernable from Ethereum’s point of view. In this scenario, in light of the possibility that Rollup cannot fully inherit Ethereum’s security setting, users would be wary of Layer 2 in spite of the good performance.
1.2 The difference between data availability and storage
Data availability involves the storage and retrieval of data, but this issue is not the same as storage; the two have different areas of focus. Storage entails keeping data readily available for retrieval for a longer period of time, during which the data is meaningful. Data availability needs to ensure that the latest transaction data generated by the main blockchain network is published to the network (which could be other than its own) and easily accessible.
Storage here refers to storing data generated by the blockchain itself and applications on the chain, excluding additional data, such as storing images, documents, etc. originating from other places. The difference and connection between storage and data availability are only worth discussing when these two tasks are undertaken by different networks separately. If a main network were to complete all the tasks of computation, storage, and data availability verification, this topic would be redundant.
General storage is not suitable for a DA network because the stored objects are often large files, while the amount of data needed to obtain data availability for all Rollups in each Ethereum block interval is often less than even 2MB. DA networks can be designed with very fine data sampling verification and retrieval processes, but storage networks cannot be designed in this way, otherwise it will be infeasible to process large amounts of data.
Ethereum is a state machine, where transactions drive state changes. In other words, countless transactions shape the current state. Whenever a state is changed and confirmed, the new state inherently contains the previous transactions which are considered to have fulfilled their historical mission. Access to its data is necessary only when it is needed retroactively.
Data availability is a prerequisite for storage. Only transaction data that is fully published in the network and validated can support execution, thus driving state change and making it worthwhile for storing. Storage is the backbone of data availability, and the DA network itself generates a large amount of data which can exist in a separate storage network, facilitating DA nodes to lighten their load and reduce the burden of operations.

Table 1. Difference between data availability and storage Source. Huobi Research
2 The development and realization path of data availability
Data availability was initially included in the blockchain network, then gradually separated from the all-in-one network. Now, a separate DA layer is about to emerge. The following section will look at the evolution of data availability and evaluate how current representative projects are implementing the data availability layer.
2.1 Progressive separation of data availability
Recall the principles here first. There are 2 types of nodes in a blockchain network, full nodes and light nodes. Full nodes store all the contents of the block, including the block header and transaction data. They participate in the production of blocks by validating, packaging transactions and competing for block-out rights. Light nodes only accept block headers, but do not store transaction data or participate in block generation. When light nodes need to use transaction data, they request data from the full nodes. The following is a step-by-step explanation of the evolution of data availability.
In Phase 1, starting with the Bitcoin network (including Ethereum and other public chain networks), data availability is naturally embedded in the network. Full nodes collect and validate transaction data over time, sort and package the transactions well, and then somehow competitively gain the power to generate blocks, put the packaged transaction data into blocks, and release them to the whole network. Other full nodes need to verify that the transaction data is correct, and that the node has the power to generate the block. If the verification is successful, it changes its own ledger and executes the transaction. In this model, executing the transaction, publishing and saving the transaction data are all done by the full nodes, and transactions that can be executed are published and must be accessible to all nodes in the network.
In Phase 2, represented by Plasma technology, data availability is handed over to the operators off-chain, and Ethereum itself does not store the transaction data of Plasma users. This is the first attempt to separate data availability from the main network. Plasma puts data availability outside of the Ethereum. In order to be trustless and to ensure that users can withdraw money from Plasma smoothly, or to resolve disputes, users need to store a portion of their own data to prove their transaction behavior and ownership of assets. In retrospect, this design was too inconvenient to use. Again, because of the 1-week challenge period for withdrawals on Plasma and the poor user experience and fund turnover, it did not enter mainstream technology.
In Phase 3, represented by Rollup technology, data availability returns to Ethereum. Rollup executes transactions off-chain and uploads the transaction data to the calldata of Ethereum after compression. Calldata is a read-only and unmodifiable location in EVM, storing the execution data of all incoming functions, including function parameters. Such a design allows Rollup to inherit the security of Ethereum and achieve the effect of off-chain scaling, enabling Rollup to become the mainstream technology for Layer 2 scaling. In addition to Rollup, there is also a technology in this phase called Validium, which can be seen as a transition from Phase 3 to Phase 4. It is otherwise similar to ZK Rollup, with the difference being the storage of transaction data in a Data Availability Committee (DAC) off-chain composed of multiple institutions. This design is another attempt to separate data availability out of Ethereum and has the benefit of reducing the amount of data stored in Ethereum, thus reducing costs. The disadvantage is that it introduces an assumption of trust, and users must trust the existence of at least one honest institution in the DAC.
Phase 4, represented by Celestia and Polygon Avail, sees data availability separated from Ethereum once again. They try to store and publish on their own network the transactional data that Rollup would otherwise upload to Ethereum, and organize nodes to verify that this data is fully published on the network. Their goal is to become a separate data availability layer (DA layer), which could be deemed as an advanced version of DAC.
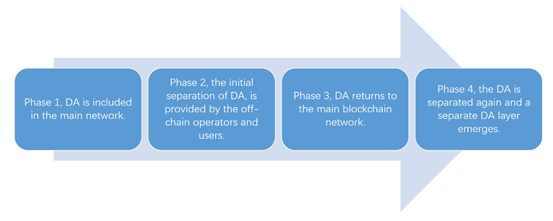
Figure 1. The evolution of data availability Source. Huobi Research
2.2 How to implement an independent data availability layer
Celestia and Polygon Avail have broadly similar ideas, so we will start with Celestia as an example to explain the overall idea.
Implementing a separate data availability layer requires 3 major steps: Rollup passes all the transaction data to Celestia, Celestia publishes all this data on its network, and Ethereum confirms that Celestia has stored and published the data and has access to it at any time.
2.2.1 How to ensure that Rollup's transaction data is uploaded to Celestia as it should be
There is an alignment between two goals: Rollup's need to obtain data availability with a cheaper network and Celestia's need to gain revenue by hosting Rollup's transactional data. It would benefit both for Rollup to deliver data truthfully and for Celestia to publish and verify data truthfully. From a financial interest perspective, they will operate honestly unless they want to be subject to margin deductions.
So, is there a technical way to avoid malpractice?
If Rollup gives all the data to Celestia, but the latter does not publish it on its network, it needs to rely on at least one honest full node in the network to furnish proof of fraud to expose it, which will be discussed later. There is a "1/N" trust assumption here, but it is a weak trust assumption that is relatively easy to implement. If you are completely unwilling to trust the network, Rollup could serve as a full node itself and monitor the state of the network.
If Rollup does not give Celestia the correct transaction data, Celestia will still post this data to the DA network. Validators on Ethereum can request this transaction data and compare the state root calculated through it with the state root Rollup uploaded to the main net, expose the fraudulent behavior and get a reward. If it is OP Rollup that is challenged, it also needs to publish a fraud proof to compare against the challenger. This ensures that the data executing the transaction on Rollup and the data delivered to Celestia are from the same batch.
The general idea of proving fraud is to show the state roots, including the starting point, end point, intermediate states and transactions that prompted the state changes. A third-party arbiter has to be present to execute a certain transaction or transactions from a certain state, and compare the computed state roots with the previously published state roots. Any inconsistency between the two indicates that the operator has committed fraud.

Figure 2. Diagram of fraud proof Source. Huobi Research
2.2.2 How to verify that Celestia's full nodes have published data
After the full node accepts the transaction data, the next step is to verify that it is publishing all this data on the network. According to the general idea, it should be verified by other full nodes in the Celestia network. This increases the storage and computing power of the full nodes as the amount of data to be verified increases, which also requires more advanced hardware devices that exacerbates the network centralization.
Celestia's idea is to have many light nodes to share this task. By breaking a batch of data into pieces, each light node only needs to download a small amount of data to verify with a very high probability that the data in this block is available. This way, the power of light nodes is mobilized to jointly maintain the data availability network. In addition, because each light node only needs to verify a small amount of data, the larger the number of light nodes, the more data that can be verified and become available to the network. Of course, this also requires a sufficient number of light nodes on the network, otherwise the verification will not be completed for lack of samples.
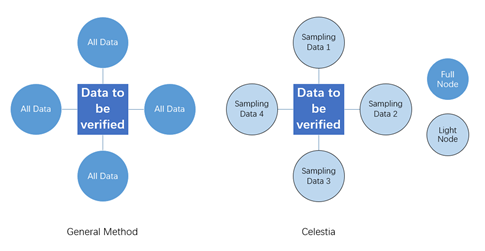
Figure 3. Celestia's idea of verifying data availability Source. Huobi Research
The steps for verifying data availability by light nodes are as follows:
1. Expanding transaction data into erasure codes. Celestia full nodes arrange transactions into data Merkle trees in order, and each leaf node is called a share, assuming there are k shares. Celestia will expand these data into 2-dimensional Reed-Solomon erasure codes into an expanded matrix with 2k rows and columns. Erasure coding (EC) is a data protection method that splits data into segments, extends, encodes, and stores redundant data blocks in different locations. This extended matrix includes not only transaction data but also the parity data generated from this data. 2D erasure codes have an important property: only any (k+1)2 elements are needed to recover the extended matrix containing (2k)2 elements. The erasure code is stored in the block body.
2. Compute the row/column roots and data roots of the extended matrix. The full node computes a Merkle root for each row and column of this extended matrix, here called row/column roots, and later computes several total Merkle roots for all row/column roots, called data root. The data root and all the row and column roots need to be uploaded to the block header of the Celestia block.
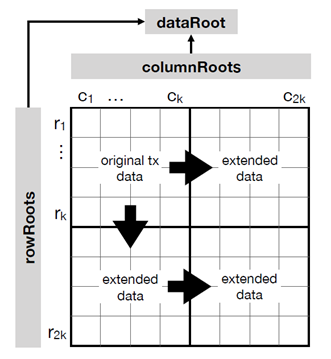
Figure 4. 2D erasure code Source. Celestia
3. Light node overall validation. After receiving the block header, Celestia's light node first computes a Merkle root using the row/column roots and compares it with the data root contained in the block header. If it does not match, it directly determines that the data is invalid; if it agrees, it proceeds to the next step.
4. Light nodes verify locally with sampling. The light node randomly selects a number of shares in the extended matrix, for example, the data in row 3 and column 5, and requests the data of these shares from the full node. The full node sends this data and also has to prove that this share belongs to the Merkle tree of row 3 or column 5, i.e. it can provide a path through which the Merkle root of this row or column can be computed. After the light node computes and compares it with the row and column roots contained in the block header, the agreement means that the transaction data sampled is available. If the full node only publishes the block header but not the transaction data, it can be easily verified by this step. After having all (k+1)2 shares verified successfully, the whole extension matrix can be judged to be valid.
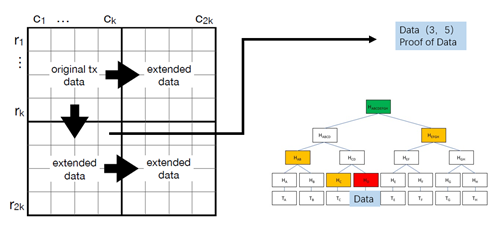
Figure 5. Diagram of light node sampling verification Source. Celestia,Huobi Research
5. Broadcast the validation information. After a light node samples the validation, it tells the full nodes connected to it the share it sampled and the row/column root that passed the validation. The full node also broadcasts this information to all full nodes. This is the process of sharing information on the network. Once enough light nodes have completed multiple sampling, a consensus is formed on the network about the availability of transaction data in a given block.
The erasure code already contains all the transaction data, which is stored in the Celestia blockchain. As we will explain later, this amount of data does not make Celestia unwieldy.
Instead of letting the light nodes group directly verify the original data, the erasure code and this complex set of processes are designed so that even in the case of network failure, such as a massive failure of all nodes, or even many light nodes down, the scattered data saved by multiple light nodes can be recovered from the extended matrix to ensure that the transaction data is still accessible.
Another reason is that since the erasure code can recover the complete data by partial data, a full node simply hiding a single share cannot conceal the data. If the full node really has malicious intent, it has to hide (k+1)2shares, which causes a substantial change in the matrix and can be detected by light nodes with only a few samples.
If some full node intentionally issues the wrong erasure code, it only takes one honest full node to step forward and issue a proof of fraud, pointing out that another data root should be computed according to the data in the proof. It also needs to re-issue a correct block and repeat the above process to re-verify it.
2.2.3 How does Ethereum verify data availability
After a consensus is reached within the Celestia network on the availability of the data stored in a block, Celestia requires a quorum of nodes to jointly sign the data root (the Merkle root of the transaction data) to generate a Data Availability Attestation, indicating that they have stored and published the batch of data on the network. The Quantum Gravity Bridge contract deployed on the Ethereum mainnet verifies the nodes' signatures, and if they pass, the data is considered available on Celestia.
Because a separate data availability layer is set up to reduce the data uploaded to the main Ethereum network, Ethereum does not need to directly verify data availability, but acts more like a supreme adjudicator by verifying that the DA layer has done its job.
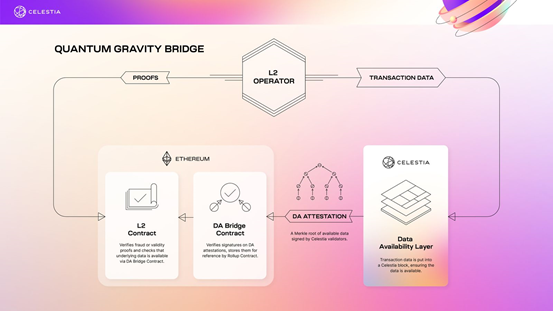
Figure 6. Ethereum verifies Data Availability assertions Source. Celestia
If Ethereum needs to call the data, it can request for it from the Celestia network, where all nodes have Rollup's transaction data, which is easily accessible to Ethereum.
2.2.4 Polygon Avail's design approach
The idea of Avail is basically the same as Celestia, the difference lies in how to generate the expansion matrix and how the light nodes verify the data.
After organizing the data into a matrix of n rows and m columns, Avail constructs a polynomial for each row, and then computes a KZG polynomial commitment for each of these polynomials, and finally expands both the polynomial and the commitment into 2n rows and stores this batch of commitments in the block header. When light nodes are sampled for verification, the correspondence between a certain commitment and the original information (that is, transaction data) is verified, and it is possible to know whether the full node has released the corresponding data. According to the nature of KZG polynomial commitment, a light node only needs to accept a polynomial generated from the original data and a short proof to complete the verification, without downloading the original data. If a light node samples multiple blocks of data which happen to be in the same row, it only needs to accept one polynomial commitment, which alleviates the light node’s bandwidth requirement. Moreover, since the commitment is bound, i.e., it cannot be changed once the computation is completed, the full node cannot tamper with the original data, thus ensuring the validity of verification.
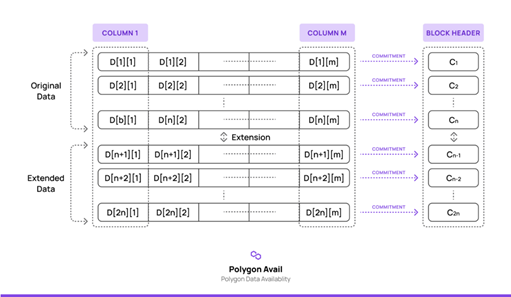
Figure 7. Polygon Avail's erasure code Source. Polygon-blog
Both Avail and Celestia have their advantages and disadvantages. Celestia is simpler to implement but requires slightly higher communication bandwidth because of the large size of its erasure code and light node sampling data. Avail involves a relatively complex cryptographic implementation and is slightly more difficult. It has the advantage of small erasure code size, small amount of data sampled by light nodes, and lower bandwidth requirements. Neither has a test network online yet, and there is still room for technical evolution, so we need to wait for test updates. There may be other competitors in this track, and success belongs to the project that can store and verify transaction data at a lower cost — as reflected by the low cost to Rollup users who access it, and the low cost of running DA network nodes.
2.3 Two competitors in the independent data availability layer
In an effort to reduce the cost of Rollups and ease the pressure on Ethereum, a separate data availability layer is hatching. On the flip side, Ethereum itself is constantly evolving, and there are two EIP proposals that address this issue: they are EIP-4488 and EIP-4844. What impact will they have on data availability?
EIP-4488 proposes to reduce the gas consumption of calldata from 16 to 3 per byte, which would immediately bring Rollup's on-chain storage cost down to 20% of the original. To prevent the cap on block space from increasing too much and pushing the Ethereum p2p network layer to unprecedented levels of stress, this proposal also designs a cap on calldata occupancy at about 1.4MB.
EIP-4488 can immediately reduce the cost of Rollups, which minimizes the changes currently needed. But Rollups will continue to grow, and it is impossible to increase the space of calldata indefinitely, because it will create security risks to the Ethereum network. This also deems it a short-term stopgap measure.
EIP-4844 proposes to introduce a new transaction format called "blob-carrying transactions". The blob contains a large amount of data and costs much less than calldata. EVM does not access this data, but only the commitments of this data. Validating a blob only requires verifying its availability. This transaction format is completely compatible with the future fully sharded transaction format. The blobs are stored on the beacon chain, where the gas used for storing data and for transactions is calculated separately for caps and pricing.
EIP-4844 is a proactive transition plan, which is also provided by the Ethereum mainnet for data availability. However, it cannot be simply equated with the existing scheme. The blob is a prototype of a separate data availability layer that is ready for a separate DA space, both technically and economically. When full sharding is implemented, the blob can be migrated to the sharding chain, which will then require some changes to the beacon chain, but Rollups will require minimal changes. It can be said that after sharding, Ethereum will implement its own relatively independent data availability layer, similar to Celestia and Avail.
There is no doubt that both proposals reduce the cost of Rollups, both of which may make other data availability layer projects appear less cost-advantaged, leading to low adoption rates. Especially EIP-4488, which does not have many new technological requirements, is easy to implement, and may also grab a first-mover advantage. In this way, it seems that the standalone DA layer may face relatively strong pressure in the short term. When data sharding has not yet been implemented, the DA layer may be able to carry more data because the network is more scalable, attracting a portion of Rollups to use it to receive data availability.
2.4 Economic model and market potential of the data availability layer.
Since it is still relatively early days for both Celestia and Avail, an economic model for the agreement has not yet been announced, including the reward and penalty mechanisms, how the agreement will be profitable, whether tokens will be issued and how they will be distributed.
Here, we hazard a guess at the reward and penalty mechanism, as well as the profitability model.
The full node in the DA layer network is required to pledge some assets as margin. If a full node deliberately does not publish the complete transaction data, it should forfeit its margin. Meanwhile, this part of the assets can also be used as the equity to participate in the consensus, and the node that stakes a high number of assets has a higher probability to obtain the power to produce blocks and receive certain rewards and fees.
Light nodes are not pledged and do not participate in fee sharing. This way the number of light nodes will be smaller and the amount of data sampled by each light node will be slightly larger. The light nodes may be mainly composed of access Rollups or dApps running on them, which are directly interested parties and have an incentive to verify the DA network. It is also acceptable for light nodes to pledge a small amount of assets. If the sampling is completed properly, they participate in the fee and reward share, and forfeit the deposit if the quality of multiple sampling is not verified. Due to the large number of light nodes, the rewards need to be accumulated and distributed periodically to reduce network pressure.
If the data availability layer is considered a temporary storage repository for data, the full nodes in the network (full and light nodes) should be paid for data storage. The cost of Ethereum calldata is the upper limit of the DA layer revenue.
Also, since a large amount of data is stored in the DA layer, this can seriously burden the blockchain network. Full nodes may need to periodically transfer some of the long-lived data to other storage platforms and instruct the storage platform to delete the data after a period of time. This may incur some cost. This cost is relatively easy to estimate, as Vitalik once estimated in an article that the implementation of EIP-4488/4844 will add about 2.5 TB of data per year to Ethereum. Assuming that this data needs to be kept for 1 year, according to the current price of mainstream cloud storage, it costs less than US$50 per year for the full node to store this data, and these costs are almost negligible. Even if the DA layer completely takes over the task of Ethereum calldata, and even stores more data, this cost remains very low. Therefore, if other costs of running the network are not taken into account, the profit margin of the DA network is largely determined by how much data it can serve.
Because it seems that in the long run, there will not be much change in revenue per unit of storage space, the DA layer has to increase sales in order to increase revenue, which means attracting more Rollups to the site. The Business Development ability of the project team is very critical here, and this is a key factor for who can be successful.
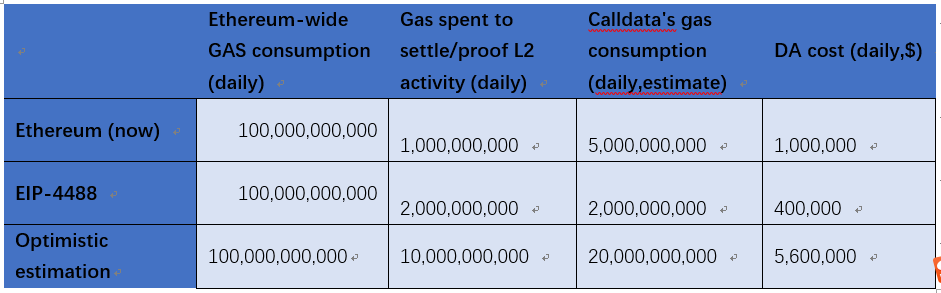
Finally, estimate how much revenue the DA layer as a whole can generate per year. The table below is a rough estimate of Rollup's storage costs based on open data. Ethereum currently consumes 100G gas per day across the network, of which 1G per day is used for Layer 2 uploading proofs and resolving disputes. Since Rollup has become the mainstream technology for Layer 2, this data can be used directly here. How much gas is consumed by calldata is difficult to estimate, and this paper assumes that it consumes 5 times more gas than proving/resolving disputes. Assuming that the average price of ETH in a year is 2500 $ and the average price of gas is 80 Gwei, the DA cost of daily Rollup is calculated to be about US$1M. If after the implementation of EIP-4488, the unit gas consumption of calldata becomes 1/5 of the original, more users will be attracted to use Rollups due to cheaper cost. Assuming the gas consumption for proving and resolving disputes is doubled, the DA cost of Rollup per day is still calculated to be about US$400,000 based on the proportional relationship, and there is a possible market of US$146M in one year. This is a market shared between the Ethereum and DA layers, and if the DA layer is slightly more favorably priced than Ethereum, assuming it gets half the share, it could generate about US$50M per year in relatively stable cash flow. This is all a conservative estimate based on the fact that Rollups are still in their relative early days.
Ethereum-wide GAS consumption (daily) Gas spent to settle/proof L2 activity (daily) Calldata's gas consumption (daily,estimate) DA cost (daily,$)
Ethereum (now) 100,000,000,000 1,000,000,000 5,000,000,000 1,000,000
EIP-4488 100,000,000,000 2,000,000,000 2,000,000,000 400,000
Optimistic estimation 100,000,000,000 10,000,000,000 20,000,000,000 5,600,000
If Rollup achieves greater growth and becomes truly "Rollup-centric", the amount of gas consumed by Rollup for proof uploading and dispute resolution on Ethereum could reach 10G per day. In other words that means 10% of the Ethereum network's gas is consumed by Rollup's proofs/controversies, which is entirely possible. Due to technological progress, Rollup will use more advanced methods to reduce the gas consumption of proof, assuming that reduces to 50%, then the gas consumption of calldata needs to become twice that of the original growth ratio. In addition, the price of ETH will also rise, assuming that the average price is at 3500 U, and the gas fee remains at 80 Gwei. The estimated consumption of DA layer can reach US$2 billion per year. In addition, if other blockchains also develop Rollup technology, the DA layer can also serve those chains and further increase revenue.
The above estimates are very rough and only provide a visual reference.
Table 2. Benchmarks for estimation of data availability market space
Source. etherscan,dune analysis,Huobi Research
3 Data availability and modularity of blockchain
3.1 Blockchain is modularizing
Looking at the journey of progressive separation of data availability from the main network, we can also identify another trend, which is the modularity of the blockchain. This is a larger long-term trend, and separate DA layers are the latest wave are part of this long-term trend.
When blockchain was born, the network was monolithic and it took on all tasks such as consensus, computation, settlement, and data storage. At that time, the on-chain ecology was just starting, the blockchain had more processing power than demand, and the cost was not high.
The computation or execution layer is the first module that is separated from the blockchain. As the blockchain ecosystem grows and the cost of using the blockchain becomes more and more expensive, scaling solutions emerge. The off-chain scaling contains a variety of technical routes, and the idea is to separate the computation from the settlement. Moving the calculation off-chain, without recalculation n on the blockchain, can save the computing resources of the blockchain and result in fee reduction. While completing the calculation under the chain also fulfils the settlement function, the final settlement must be carried out by the blockchain main network.
The data availability layer is the second module separated from the blockchain. One reason why the current off-chain expansion is still unable to reduce the cost of usage to a level that satisfies the public is that data availability still requires the consumption of valuable storage resources on the blockchain. Setting up a separate DA layer can greatly reduce this resource consumption, which can further decrease the cost of using on-chain applications and attract more users to participate. Ethereum's data sharding is also a kind of modular DA layer and achieves the same function.
Separating the above two parts, the only thing left for the blockchain master network to take on is consensus. The main network needs to reach consensus on the result of execution and the basis of execution, that is, data availability. Of course, the settlement function is also included in the consensus module, because the most important part of the consensus is what kind of settlement result the network should agree on. At this point, a structure of "consensus-execution-data availability" is being formed, which is separate from each other.
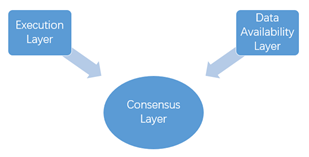
Figure 8. Modular blockchain structure Source. Huobi Research
3.2 Modularity is a natural consequence of blockchain
The blockchain trilemma tells us that blockchain has three essential attributes: decentralization, security and scalability, and due to technical constraints, only two of them can be optimized at the same time, and the remaining one has to be sacrificed. Ethereum has chosen to be highly decentralized and secure, so scalability has become the attribute to be compromised.
Decentralization lies at the heart of the blockchain. It is because of the decentralized nature that no institution on the blockchain has the power to arbitrarily modify or eliminate the user's assets; the assets on the chain are valuable, and the token issuance, asset exchange, lending, etc. generated for these assets are meaningful. Without its decentralized attribute, the blockchain might arguably not need to exist. Security, in turn, is the lifeblood of distributed systems, so decentralization and security should be the two points to be prioritized in this trilemma.
Ensuring decentralization requires a consensus of many nodes, with each full node performing the same operations and backing up the same data. This is a very inefficient process, resulting in low throughput and high transaction fees. Under such conditions, the way to improve scalability is to reduce the tasks that the mainnet needs to perform and let other modules take on more tasks - hence, the emergence of modularity.
Modularity aspires to make the whole more capable than the simple sum of its parts by dividing up the work, which is in line with the general rule of thumb of how things evolve. The separated Rollup and DA networks can focus on execution and data availability, respectively, and are free to develop in their respective domains without any trade-offs. The Ethereum mainnet only needs to verify their proofs, and the "world computer" has become the "Supreme Court of the whole network". This lends credence to the idea of further cost reduction: Rollup minimizes the size of proofs and the resource consumption required to generate them, the DA layer improves the efficiency of coding and verification, and also reduces the size of the assertions uploaded to mainnet. After a period of development, the modular blockchain has every possibility to reach the level of other high-performance public chains in terms of both performance and cost.
Some blockchains have compromised on the degree of decentralization to achieve higher performance, but with development and evolution, there will always be a situation where performance cannot keep up with demand. Currently, it is certainly a positive scenario if it results in a more powerful new network through technical upgrades; while it is also not a bad idea to deploy resources more rationally under the existing technical conditions through more division of labor and collaboration. It is likely that in the coming period, public chains with high decentralization but low performance, as represented by the likes of Ethereum, will firmly promote the modularization process; while some other public chains will also learn from Ethereum’s success and try to implement external modules. After experiencing success from the division of labor, modularization of blockchain may become a new paradigm.
References
[1] https://coinmarketcap.com/alexandria/article/what-is-data-availability
[2] https://blog.celestia.org/ethereum-off-chain-data-availability-landscape/
[3] https://blog.celestia.org/celestiums/
[4] https://arxiv.org/abs/1809.09044
[5] https://medium.com/the-polygon-blog/introducing-avail-by-polygon-a-robust-general-purpose-scalable-data-availability-layer-98bc9814c048
[6] https://blog.polygon.technology/the-data-availability-problem-6b74b619ffcc/
[7] https://eips.ethereum.org/EIPS/eip-4488
[8] https://notes.ethereum.org/@vbuterin/proto_danksharding_faq
[9] https://ethereum.org/en/upgrades/shard-chains/
[10] https://dune.xyz/funnyking/L2-Gas-Consumption
[11] https://newsletter.banklesshq.com/p/ultra-scalable-ethereum?s=r
[12] https://hackmd.io/@alexbeckett/a-brief-data-availability-and-retrievability-faq
Disclaimer
1. The author of this report and his organization do not have any relationship that affects the objectivity, independence, and fairness of the report with other third parties involved in this report.
2. The content of the report is for reference only, and the facts and opinions in the report do not constitute business, investment and other related recommendations. The author does not assume any responsibility for the losses caused by the use of the contents of this report, unless clearly stipulated by laws and regulations. Readers should not only make business and investment decisions based on this report, nor should they lose their ability to make independent judgments based on this report.
3. The information, opinions and inferences contained in this report only reflect the judgments of the researchers on the date of finalizing this report. In the future, based on industry changes and data and information updates, there is the possibility of updates of opinions and judgments.
4. The copyright of this report is only owned by Huobi Blockchain Research Institute. If you need to quote the content of this report, please indicate the source. If you need a large amount of reference, please inform in advance (see “About Huobi Blockchain Research Institute” for contact information), and use it within the allowed scope. Under no circumstances shall this report be quoted, deleted or modified contrary to the original intent.
5. The copyright of this report is only owned by Huobi Blockchain Research Institute. If you need to quote the content of this report, please indicate the source. If you need a large amount of reference, please inform in advance (see "About Huobi Blockchain Research Institute" for contact information), and use it within the allowed scope. Under no circumstances shall this report be quoted, deleted or modified contrary to the original intent.
About Huobi Research Institute
Huobi Blockchain Application Research Institute (referred to as "Huobi Research Institute") was established in April 2016. Since March 2018, it has been committed to comprehensively expanding the research and exploration of various fields of blockchain. As the research object, the research goal is to accelerate the research and development of blockchain technology, promote the application of blockchain industry, and promote the ecological optimization of the blockchain industry. The main research content includes industry trends, technology paths, application innovations in the blockchain field, Model exploration, etc. Based on the principles of public welfare, rigor and innovation, Huobi Research Institute will carry out extensive and in-depth cooperation with governments, enterprises, universities and other institutions through various forms to build a research platform covering the complete industrial chain of the blockchain. Industry professionals provide a solid theoretical basis and trend judgments to promote the healthy and sustainable development of the entire blockchain industry.
Consulting email:
research@huobi.com
Official website:
https://research.huobi.com/
Twitter: @Huobi_Research
https://twitter.com/Huobi_Research
Medium: Huobi Research
https://medium.com/huobi-research







