Over the past decade, the advancement of AI has primarily relied on one path: feeding more data and computing power into larger models, allowing experience to accumulate within neural network parameters. This path has led to the leap in large models after ChatGPT, but it has also left behind a persistent challenge: as models become increasingly powerful, the reasons behind their successes and failures often remain difficult to explain and correct.
Recent experiments by OpenAI engineer Weng Jiayi suggest another possibility: within a clear objective, a runnable environment, and a feedback loop, AI can improve not only by training models but also by "autonomously modifying code."
On May 8, 2026, Weng Jiayi systematically documented this set of experiments in his personal blog "Learning Beyond Gradients" and simultaneously made the code repository, CSV experiment logs, and video replays public. He has long focused on reinforcement learning and post-training infrastructure, participated in the initial launch of ChatGPT, and contributed to projects like GPT-4, GPT-4 Turbo, GPT-4o, o-series, and GPT-5. Before joining OpenAI, he earned his bachelor's degree from the Department of Computer Science at Tsinghua University and his master's degree from Carnegie Mellon University. He is also a main author of the open-source reinforcement learning library Tianshou and the high-performance parallel environment engine EnvPool.

Image generated by AI
He had Codex repeatedly write policy code, run environments, read logs, review replays, locate failures, then modify code, add tests, and continue evaluation. After multiple iterations, Codex "cultivated" a set of pure Python programmatic strategies: it achieved a theoretical perfect score of 864 points in Atari Breakout and also produced results in robot control simulation environments like MuJoCo Ant and HalfCheetah that were close to those of common deep reinforcement learning algorithms.
The truly significant aspect of these experiments lies in a core question: When the coding agent is sufficiently capable, must learning necessarily occur within neural network weights?
In this experimental setup, experience is written into code, tests, logs, and replays, becoming a software system that can be read, modified, reviewed, and audited. If this direction continues to hold, the next step for Agentic AI might not only be training larger models but also enabling models to participate in maintaining a continuously evolving engineering system.
01
From 387 Points to a Perfect Score: An Engineering Loop
Weng Jiayi wrote in his blog that the starting point for this experiment was actually an engineering need. While maintaining EnvPool in his spare time, he required a cheaper method than "running a neural network every time" to test whether the game environment was functioning correctly, as placing neural networks in CI was too expensive. The original question was: Could he write cheap, reproducible, heuristic rules that were clearly better than a random policy, to drive the environment to information-rich states?

He used Codex (base model gpt-5.4) to attempt writing a completely rule-based version. The initial prompt was very direct: "Write a strategy that can solve Breakout." The result was unsatisfactory. A low score itself provided no information—the action semantics could be wrong, state detection could be wrong, the evaluation process could be wrong, or the policy structure itself could be too weak.
Subsequently, Weng Jiayi changed the task format. He no longer asked Codex to simply deliver a policy.py file; instead, he required it to maintain a complete loop: probe actions and observations, write state detectors, write the policy, run complete episodes, record trials.jsonl and summary.csv, generate videos or curves, inspect failure modes, modify the policy, simplify code, and run regressions.
The experimental log for Breakout clearly recorded this process. In the first round, Codex confirmed the action space and observation shape, identified the colors of the ball, paddle, and bricks from the RGB frames, and then used image labels to scan the 128-byte Atari RAM. The initial baseline scored only 99 points. After adding tunnel offset logic, the score increased to 387 points.
387 points was a deceptively high local optimum. The strategy could stably hit the ball, but the ball path was trapped in a periodic loop: no lives were lost, but no new bricks could be broken, and the score was stuck. If a human were writing the code, they might continue fine-tuning the "accuracy of hitting the ball." Codex watched the video and the last few dozen steps of the trajectory, and identified the problem as a lack of disturbance in the ball's path.
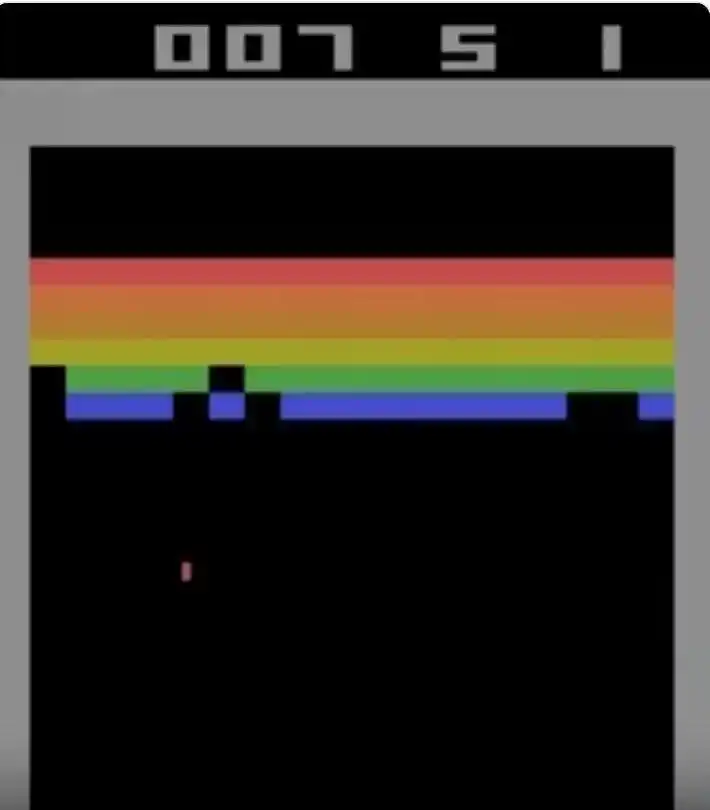
Image: Atari Breakout gameplay. The player controls the bottom paddle to bounce a ball, breaking layers of colored bricks above. Codex achieved the theoretical perfect score of 864 points in this game.
Codex then added a mechanism to "break the cycle": if no reward was received for a long time, periodically add an offset to the landing point prediction to knock the ball out of the local loop. The score jumped from 387 to 507. During further iterations, a new problem emerged: for fast low balls, conventional interception would cause the paddle to "over-lead" and drift away. Codex added a `fast_low_ball_lead_steps=3` parameter, and the score jumped from 507 to 839. The final improvement from 839 to 864 resembled maintaining an already complex system: trying deadband, serve offset, stuck offset, brick balance bias, lookahead steps; many directions were ineffective. The final useful change was a late-stage condition: "After the first wall of bricks is cleared, enable the stuck offset only when the ball is far from the paddle, and gradually release it when the ball is close."
The final RAM default configuration stably output 864 / 864 / 864 points across three episodes, reaching the theoretical limit of Breakout. Codex then migrated the same geometric controller to a pure vision input version—without reading RAM, relying solely on RGB segmentation to identify the paddle, ball, and brick balance. The vision version initially scored 310 points, then 428 points, and reached 864 points after the seventh local episode, corresponding to 14,504 local policy environment steps.
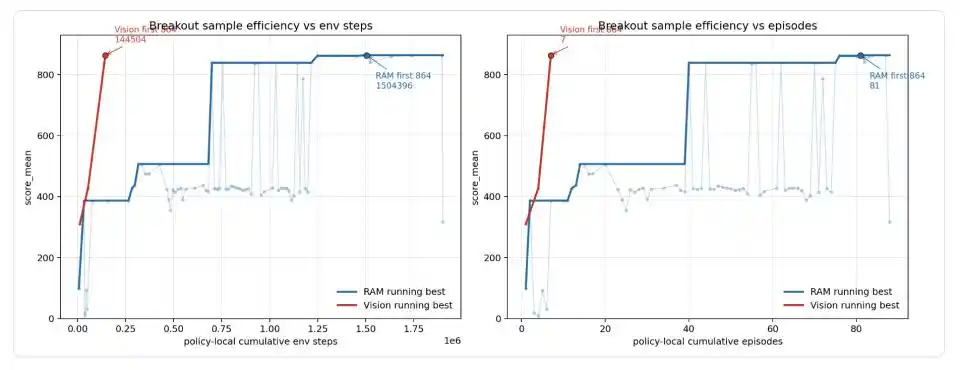
Image: Sample efficiency curve of Codex on Breakout. The blue line is the version that reads game memory (RAM), and the red line is the vision-only version (Vision). The RAM version experienced several jumps: 99 → 387 → 507 → 839 → 864, finally reaching the perfect score for the first time at episode 81, with a cumulative 1.5 million environment steps; the Vision version, migrating the mature structure from the RAM version, reached 864 points with only 7 episodes and approximately 14,500 environment steps.
Weng Jiayi specifically noted that this should not be understood as "the vision input started from scratch and reached a perfect score using only 14.5K steps." The actual process was that Codex first discovered the geometric controller, cycle-breaking mechanism, and late-stage offset release in the RAM version. Once the structure was stable, the state reading layer was switched from RAM to RGB. The 14.5K steps represent the migration budget for the vision version.
02
Defining Heuristic Learning
Finding a name for this evolving "software policy" was more difficult than writing the first version of the policy. Weng Jiayi ultimately named this process Heuristic Learning (HL) and termed the object it maintains as a Heuristic System (HS).
According to his blog definition, HL is composed of program code. Like today's common deep reinforcement learning, it has a loop of state, action, feedback, and update. The difference is that the object being updated is the software structure, not neural network parameters; its feedback, digested by the coding agent, can come from environmental rewards, test cases, logs, videos, replays, or human feedback; its update does not use backpropagation, but rather the coding agent directly edits the policy, state detectors, tests, configurations, or memories.
It should be added that the concept of "using programs rather than neural networks as policies" is not Weng Jiayi's original creation. Academic discussions on Programmatic RL have been ongoing for years: the PROPEL framework proposed by Rice University and Caltech in 2019 researched reinforcement learning methods representing policies as short programs in a symbolic language; the 2021 LEAPS work further learned program embedding spaces, combining differentiable program policies with RL training; the HPRL (Hierarchical Programmatic Reinforcement Learning) presented at ICML 2023 allows a meta-policy to combine multiple programs; the LLM-GS framework from National Taiwan University and Microsoft in 2024 uses LLM's programming ability and commonsense reasoning to guide the search for programmatic RL policies.
The consensus from this research is that, compared to neural policies, programmatic policies possess better interpretability, formal verifiability, and generalization ability to unseen scenarios.
Weng Jiayi's substantive contribution this time lies in treating the coding agent as the engineering channel for maintaining the heuristic system. In the past, doing programmatic RL either relied on manually designed domain-specific languages or search algorithms within restricted program spaces; Weng Jiayi, however, uses Codex to integrate code, logs, tests, video replays, and parameter adjustments into the same agent workflow, drastically reducing the iteration cost of program policies at once. In other words, he is arguing for a new engineering path: when the coding agent is sufficiently capable, those heuristic strategies once deemed "too expensive to maintain" might become cost-effective again.
Weng Jiayi provided a comparison table in his blog to clearly illustrate the differences between HL and Deep RL: in terms of policy form, the former consists of rules, state machines, controllers, model predictive control (MPC), and macro actions composed into code, while the latter consists of neural network parameters; in terms of state form, the former uses explicit variables, detectors, and caches, while the latter uses network-readable observation vectors; in terms of feedback form, the former treats tests, logs, and replays as valid signals, while the latter primarily relies on fixed reward functions; in terms of memory form, the former can explicitly store trials, summaries, failure reasons, and version diffs, while the latter has essentially none in on-policy algorithms and relies on replay buffers in off-policy algorithms.
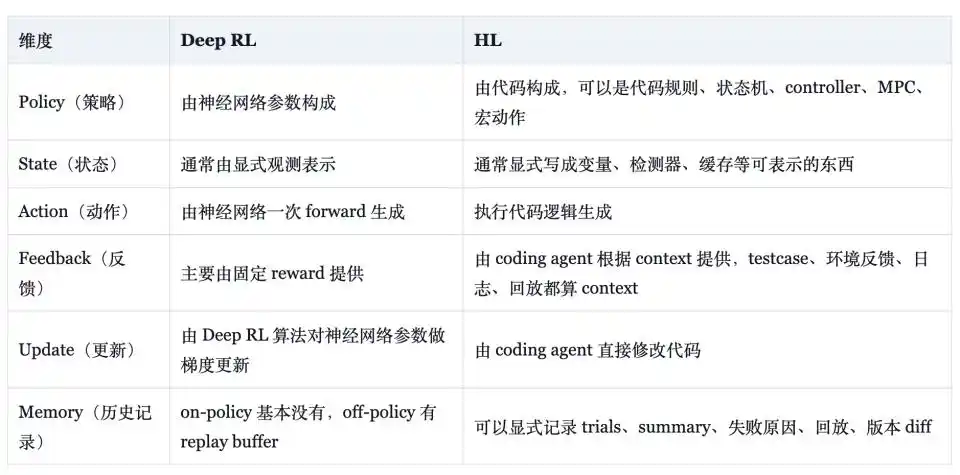
This comparison demonstrates that HL possesses some engineering attributes: the policy is interpretable and can be translated into natural language; sample efficiency is measured in units of "one effective code change," not slow gradient updates; old capabilities can become regression tests, fixed-seed replays, or golden cases; overfitting to training seeds or test loopholes can be constrained through simplification, regression checks, and multi-seed evaluation; old capabilities don't have to reside solely in weights but can also reside in rule sets and tests, which partly addresses the catastrophic forgetting problem that neural networks have long struggled to solve.
03
Bulk Validation on Atari57: Boundaries and Shortcomings
If focusing only on Breakout, the story could easily be simplified to "AI wrote a perfect strategy." But Weng Jiayi didn't stop at Breakout; he scaled this Codex workflow in bulk to Atari57, running 57 games, two observation modes, and three repetitions each, totaling 342 "unattended" search trajectories.
The experimental design was quite rigorous. Each game was tested with two input methods: one directly reading game memory, and the other viewing only the screen. Each method was independently repeated three times. This produced a total of 342 "unattended" experimental trajectories: each Codex agent received the same prompt template, explored actions on its own, wrote code on its own, ran experiments on its own, and recorded results on its own, with no human providing hints. Constraints were strictly enforced: no training neural networks, no reading game source code, no exploiting any hidden information. All steps used for debugging and trial-and-error had to be counted in the total cost. This was to prevent Codex from cheating in any "peeking at the answers" way.
When measuring results, a metric called HNS (Human-Normalized Score) is commonly used—simply put, it standardizes the score of each game relative to "average human player performance = 1" for easy cross-game comparison.
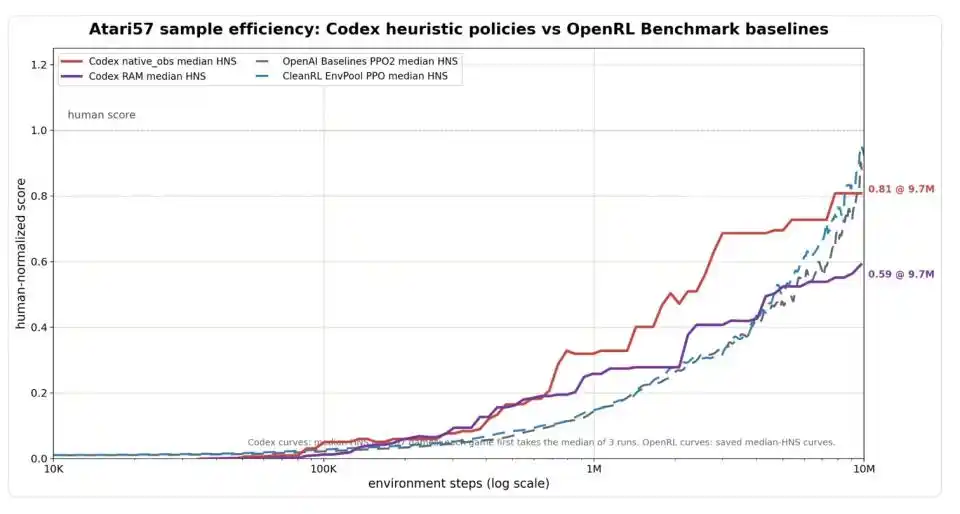
Image: Sample efficiency comparison on the full Atari57 suite. The x-axis is environment steps (log scale), and the y-axis is HNS (Human-Normalized Score, where 1.0 indicates reaching average human player level). Codex's vision input version (red line) significantly outperforms the PPO baseline (blue/gray dashed lines) in early-stage efficiency, reaching 0.81 at 9.7 million steps, comparable to PPO's level around 10 million steps; Codex's memory input version (purple line) converges at 0.59.
Measured by this standard, Codex's early-stage efficiency appears quite impressive. With only 1 million environment steps consumed, Codex's median HNS for vision input had already reached 0.32, and for memory input, 0.26, significantly higher than that of classical reinforcement learning algorithms like PPO at the same stage. By 9.7 million steps, Codex's vision version reached 0.81, already close to PPO's level of approximately 0.88 to 0.92 at 10 million steps. If allowed to aggregate by selecting the better-performing input method for each game, Codex's median HNS was 0.83, OpenAI Baselines PPO2 was 0.80, and CleanRL EnvPool PPO was 0.98—essentially a tie.
However, Weng Jiayi himself calmly drew a boundary: this is only a comparison of environment interaction efficiency, without accounting for the costs of Codex reading logs, writing code, and watching videos. "Running fast" does not equal "low total cost," and the latter remains a black box for now.
More noteworthy is that Codex's performance across the 57 games was not uniform. In games with clear geometric structures like Breakout, Boxing, and Krull, both heuristic strategies and deep reinforcement learning could significantly surpass human levels; in games with clear rules like Asterix, Jamesbond, and Tennis, heuristic strategies were even stronger; but in fast-paced, complex-pattern games like Atlantis, VideoPinball, RoadRunner, and StarGunner, PPO still dominated.
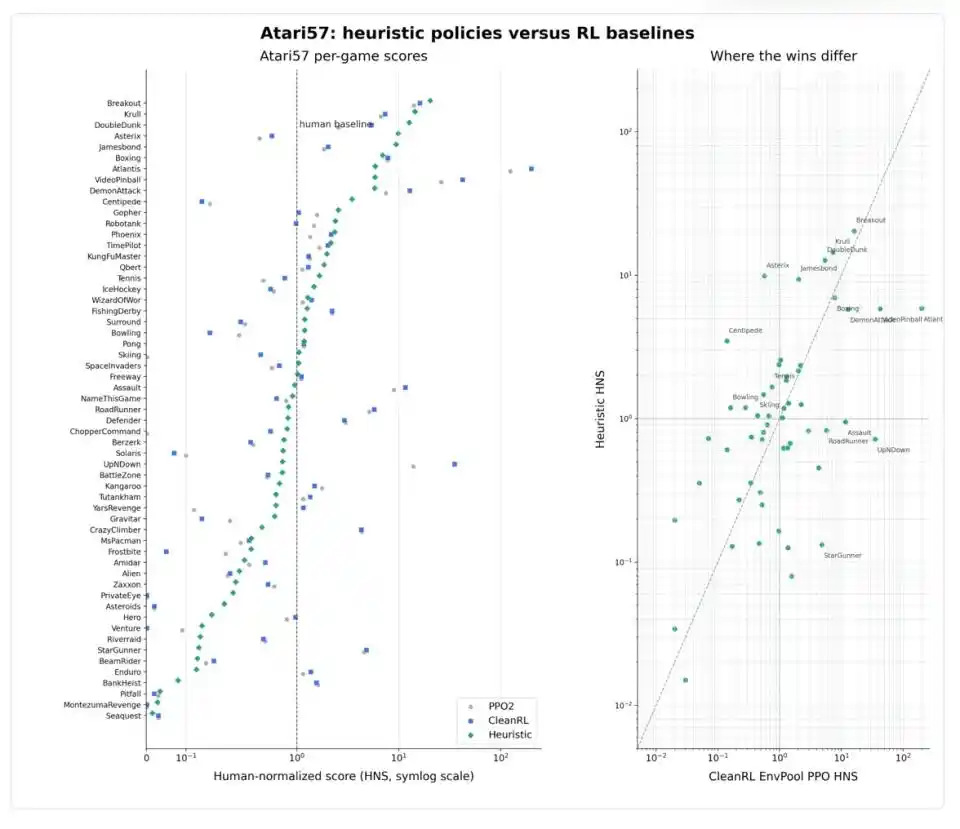
The most cautionary counterexample is Montezuma's Revenge. This is a notorious "hard nut to crack" in reinforcement learning, where the protagonist needs to find keys, avoid enemies, and open doors in a complex underground labyrinth, with extremely sparse reward signals—a classic "long-term planning + failure recovery" challenge. Codex did score 400 points in this game, but examining the policy file it generated reveals that it's not a true "strategy" but a hardcoded sequence of 86 actions corresponding to 1,769 environment steps: more like memorizing a fixed route than learning to navigate a maze. Weng Jiayi specifically noted: "This is a boundary case and should not be understood as a generic Montezuma strategy."
Montezuma exposes the expressive limits of Heuristic Learning. Ordinary programmatic strategies are essentially reactive logic of "do this action when you see that state," struggling with tasks requiring strict action sequences, resuming plans from intermediate states, and long-horizon planning. Such tasks require not just more if-else statements but program structures closer to "macro-action combination + recoverable search state + long-term memory." This tells us one thing: even if the coding agent becomes very powerful, some problems cannot be contained by ordinary code.
04
If the Paradigm Holds, What Are the Industrial Implications?
Zooming out to an industrial perspective. If the Heuristic Learning path truly holds—meaning "coding agents can stably maintain programmatic strategies surpassing handcrafted rules and approaching RL baselines"—where does its practical significance lie?
The first application point is robot control, especially in structurally stable scenarios. The framework Weng Jiayi outlined in his blog involves hierarchical division of labor: joint-level HL, limb-level HL, full-body balance HL, and task-level HL. Lower levels handle safety and low-latency control, middle levels handle gait and contact, and higher levels handle tasks and long-term memory; the coding agent doesn't need to "understand walking"—it's more like an update channel inserted into the system, sending failure videos, sensor streams, and simulation results back to the system, and rewriting feedback into code, parameters, protection rules, and memories.
Scenarios like warehouse AGVs, inspection robots, factory robotic arms, and standardized sorting, where the environment structure is relatively fixed and safety boundaries are clear—if core control strategies can be solidified into lightweight code, robots wouldn't need to run a large policy network for every action step. Deployment-end reliance on high-power GPU inference cards would decrease, with more load handled by traditional controllers and local program logic.
This doesn't mean robots don't need GPUs; perception, localization, mapping, and semantic understanding still rely on neural networks. What changes is the role of the GPU, shifting from "burning compute for end-to-end action decisions every second" to "playing a periodic role in perception, offline simulation, policy generation, and anomaly analysis."
The second application point is the auditability of safety-critical scenarios. The most troublesome engineering problem with neural policies is the inability to locate the cause after a failure. When a robotic arm suddenly fails at a certain angle, a vehicle misjudges in an edge case, or a medical robot acts abnormally in a rare posture, engineers cannot answer "which weight caused this error." Ultimately, they can only add data, retrain, run regression tests, and bet that the new model hasn't introduced new problems.
If the policy exists in code form, state variables, conditional branches, failure logs, and regression tests are all visible; a dangerous action can be hardcoded to be prohibited, a corner case can be written as a test, and an erroneous state transition can be individually patched. This doesn't make the system inherently safer, but it allows safety issues to enter normal software engineering workflows for the first time—they can be code-reviewed, intercepted by CI, and responded to by SRE on-call. In fields requiring regulation and liability division, like autonomous driving, industrial robotic arms, and medical robots, this auditability itself is of commercial value.
The third application point is the engineering of continual learning and online learning. Weng Jiayi presented this as the main argument of the entire blog post. Catastrophic forgetting in neural networks is a structural problem: learning new things washes away old capabilities. HL also experiences forgetting, but in a more engineering form: a new rule fixes one failure mode but breaks an old scenario; a new memory repeatedly leads the agent in the wrong direction; a test range is too narrow, and the policy learns to exploit it; a patch modifies a shared interface, and old calling paths silently fail.
These problems don't disappear automatically, but they are issues that software engineering has dealt with for decades, with existing toolchains—regression testing, version diffs, fixed-seed replays, golden traces, and explicitly recorded failure directions.
A healthy HS must perform two operations simultaneously: absorbing new feedback and compressing historical patches. An HS that only grows without reduction will eventually become a "code ball of mud" no one dares to touch. In other words, HL transforms the mathematical problem of "how to update parameters" into the engineering problem of "how to maintain a software system that continuously absorbs feedback."
The latter is not necessarily easier, but it is closer to the existing boundaries of human capability.
The fourth application point is capability accumulation in Agent products. What current Agent products lack most are stable tool invocation, reliable execution chains, reusable failure experiences, and auditable task records. If HL's logic holds, an Agent's memories during execution would precipitate into code assets that can be reused across sessions, users, and tasks. It can directly interface with existing DevOps processes and also means that Agents from different companies and teams can share heuristics without needing to share models—something the neural network approach cannot achieve.
However, it must be emphasized: all four application points depend on further validation of the HL path on more complex tasks. Breakout and Ant are relatively clean environments. Real robots face changes in ground friction, lighting variations, actuator delays, and sensor noise—none of which have been systematically evaluated in public materials. The Montezuma counterexample has already shown that long-horizon tasks require program forms beyond ordinary if-else. How far this vision can go depends on the next phase of experiments.
05
Technical Debt Shifts from Weights to Code
Weng Jiayi's assessment in his blog is measured. He wrote that HL cannot accomplish everything neural networks can do; it is limited by what code can express, especially in complex perception and long-horizon generalization. With today's understanding, he cannot imagine an agent using pure Python code without any neural networks to solve ImageNet. The truly worthwhile question is how to combine neural networks with HL to jointly address Online Learning and Continual Learning.
The division of labor he proposes borrows from the System 1 / System 2 framework: specialized shallow neural networks take on part of System 1, responsible for fast perception, classification, and object state estimation; HL also takes on part of System 1, responsible for processing fresh data, rules, tests, replays, memories, safety boundaries, and local recovery; the LLM agent acts as System 2, providing feedback and improvement data to HL, and periodically extracting information from data generated by HL to update itself.
If deep learning over the past decade has proven that "experience can be compressed into weights," then the hypothesis Weng Jiayi proposes this time is another proposition: in the era of coding agents, experience might once again become readable, modifiable, testable software.
This article is from the WeChat public account "Tencent Technology," author: Xiao Jing, editor: Xu Qingyang








