自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。
最近,NVIDIA GEAR 实验室负责人 Jim Fan 介绍了一个名为 ENPIRE 的最新项目。这是他们首次在机器人硬件上实现了自动化研究。
他们把 8 个 Codex Agent 放到一个机器人舰队里,分配好 GPU 算力和充足的 token 预算,只给出一个简单目标:尽快解决任务、让机器人保持忙碌但确保安全、不要浪费算力。
接下来人类就基本退出干预。Agent 自主驱动整个闭环,包括自动重置场景、搜索文献、实现想法并搭建基础设施、训练和部署策略、自我验证、分析日志并改代码,不断迭代,直到在真实硬件上可靠完成高精度灵巧任务,比如系扎带、插针盒整理、安装 GPU 等。
他们还观察到一种「物理 scaling law」,增加并行机器人数量(例如从少量增加到 8 个),能显著加快任务解决速度。
目前,该实验室的部分系统已实现彻夜无人类干预的自我迭代,研究人员仅需在早晨查看报告即可。
Jim Fan 称,未来目标是让团队成员安心休假,甚至连 NVIDIA CEO 黄仁勋都察觉不到实验室仍在自主运行。
ENPIRE 项目计划完全开源,届时普通开发者也有望在家中搭建类似的自主机器人研究系统。

项目地址:https://research.nvidia.com/labs/gear/enpire/
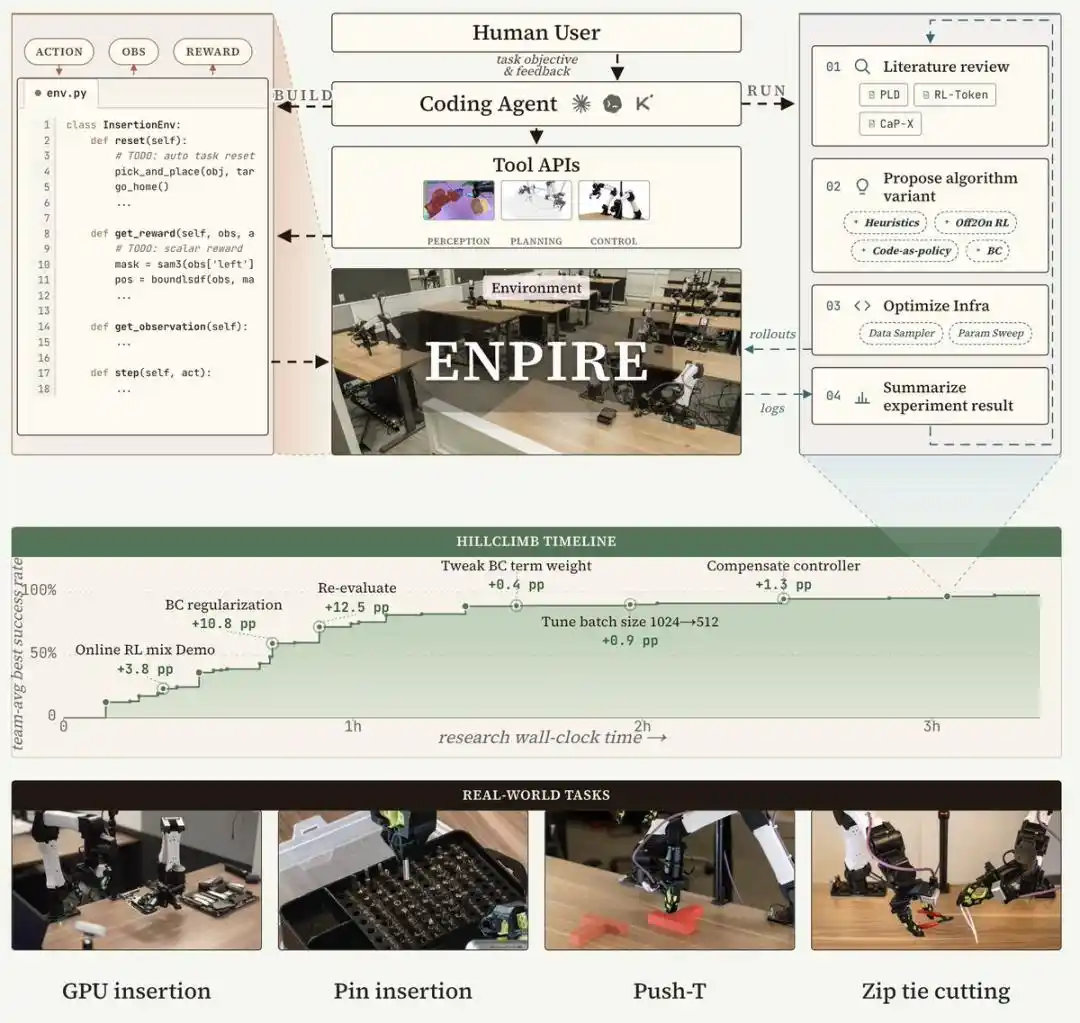
ENPIRE 系统架构:四个模块构成闭环
ENPIRE 是一个专为编码 Agent 设计的框架系统,通过四个核心模块构建可重复的物理反馈循环:环境模块(EN)负责自动重置和验证,策略改进模块(PI)启动策略优化,Rollout 模块(R)支持单台或多台机器人并行评估策略,进化模块(E)则让编码 Agent 分析日志、查阅文献、改进训练基础设施和算法代码以解决失败模式。
这一闭环系统将真实世界机器人学习转化为一个由 Agent 管理的、可控的优化过程,从而最大限度减少人工投入,同时支持在不同训练配方和 Agent 变体之间开展公平的消融实验。
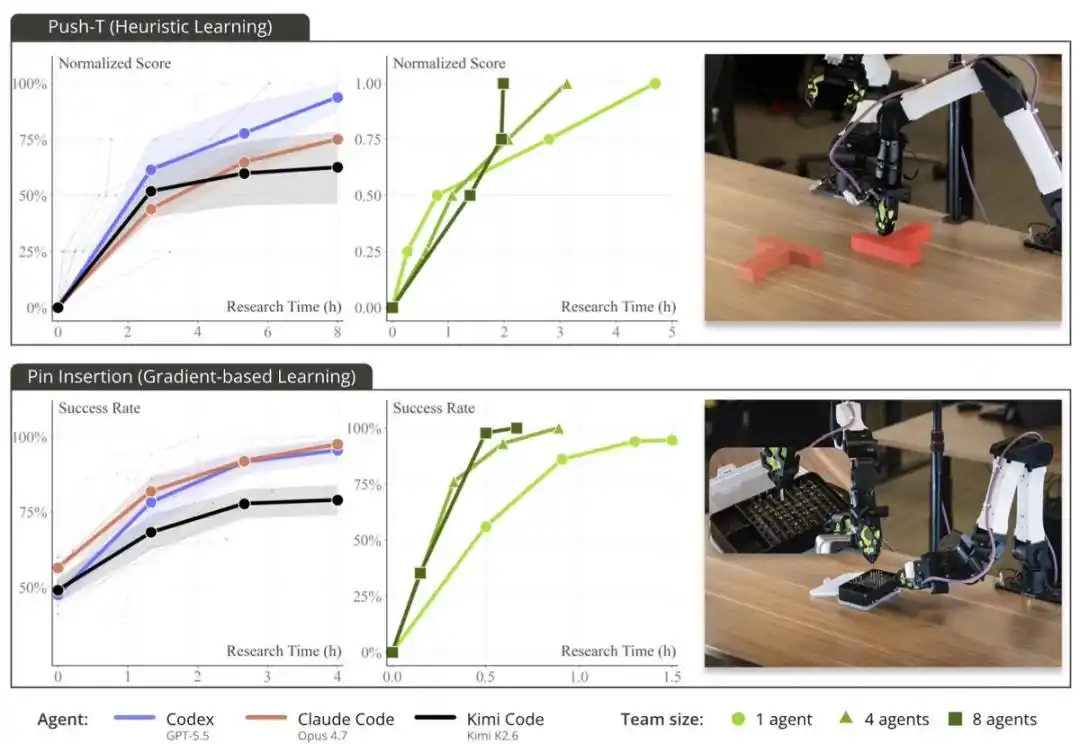
在 ENPIRE 的支持下,前沿编程 Agent 能够自主开发策略,并在 PushT、将插针整理进针盒、使用切刀剪断扎带等具有挑战性的真实世界灵巧操作任务中,实现 99% 的成功率。
关键发现:重置环境比完成任务本身更容易
其中一个关键观察是:对许多机器人任务而言,重置环境往往比完成任务本身更容易。
因此,ENPIRE 的做法是,先让 Agent 通过 Code-as-Policy 构建自动重置环境。很多情况下,所谓重置其实就是一个 pick-and-place 任务,可以由 Cap-X 解决。
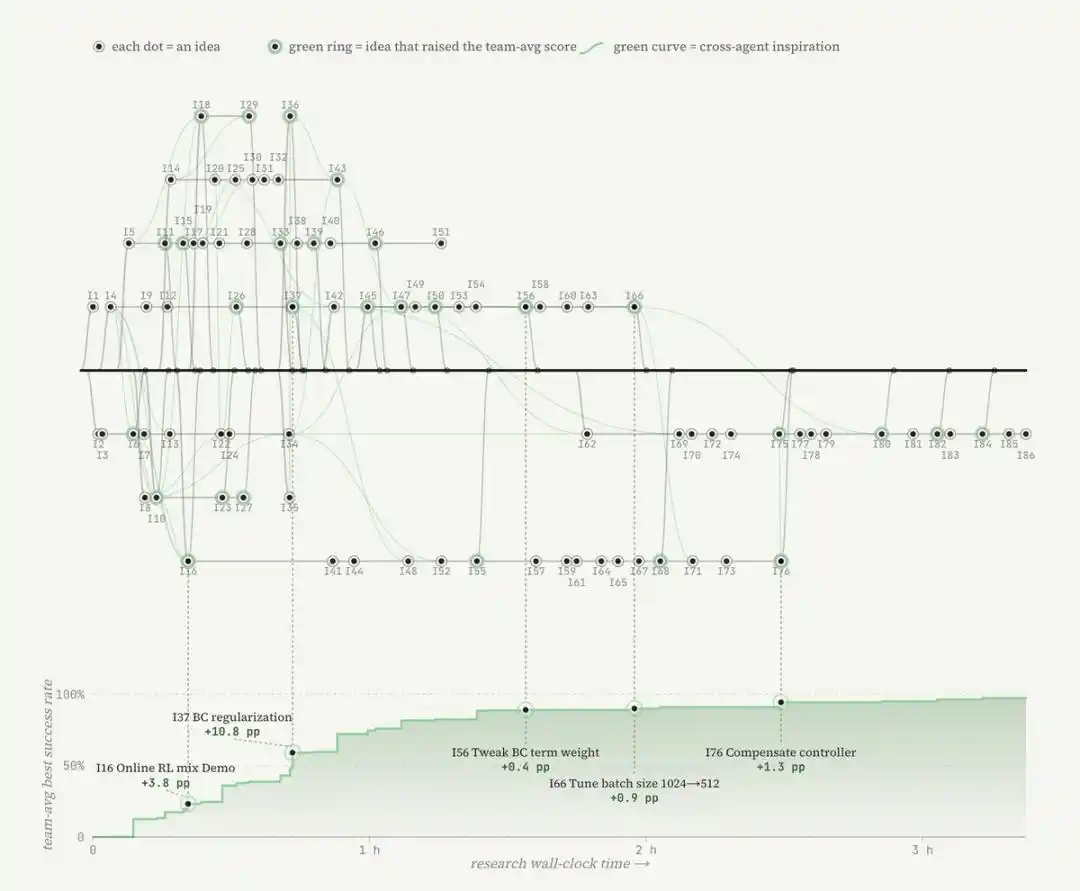
随后,智能体会编写基于启发式规则的奖励函数。研究团队再将该环境放入沙箱,并启动 Agent 围绕得分开展自动化研究。
这也呼应了 Karpathy 对自动化研究的定义:这里所说的自动化研究,并不是简单调一个超参数,或改动某一小段代码。Agent 会从互联网上探索不同范式,并重写一切可能推动性能提升的部分,包括算法、训练目标,甚至数据加载器。
在插针任务中,一个 Agent 甚至自行编写了接触力安全控制器,其效果超过了单纯调节若干强化学习参数。
新指标MRU与MTU
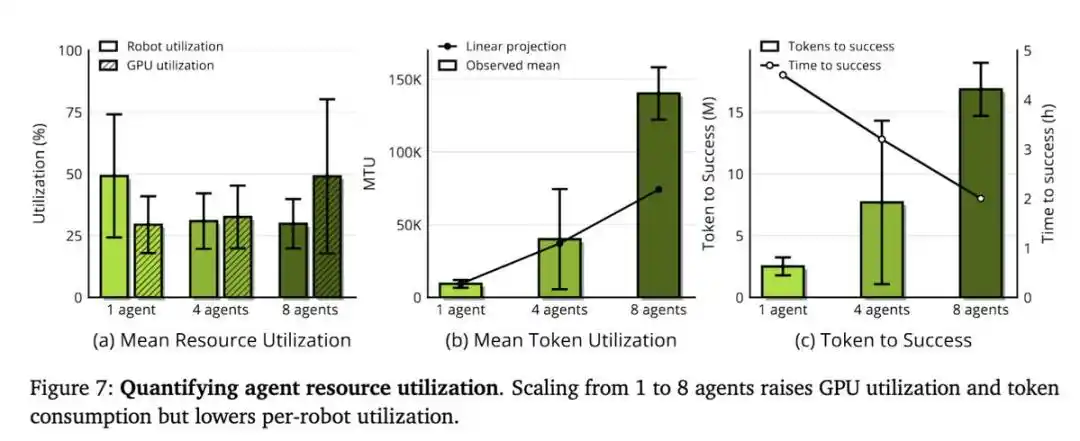
ENPIRE 的扩展能力取决于 Agent 团队规模和算力资源,只不过在这里,真正稀缺的资源不是 GPU,而是机器人时间。
当研究团队为 Agent 提供 8 台机器人,而不是 1 台机器人时,插针任务达到接近完美表现所需的时间,从 1.5 小时以上缩短到了约 40 分钟。这些 Agent 通过 Git 进行协调:共享代码、放弃不理想的想法,并自主地挑选彼此的最佳运行结果。
这指向了一个更大的变化:机器人研究正在变成一种环境设计工作,即为 coding Agent 搭建可以在其中进行自动化研究的环境;算法工作则上移到了更高一层,转向构建一种 Agent 能够自行闭合的反馈循环。
而这个循环会不断复利式累积:Agent 今天掌握的一项技能,明天就会成为构建并重置更困难任务环境的基础模块。能力会自举出新的能力。
在这一范式下,真正的硬约束是真实世界交互预算。
因此,研究团队提出了两个指标:
- 平均机器人利用率(Mean Robot Utilization,MRU):机器人实际运行实验的时间占总真实耗时的比例。
- 平均 Token 利用率(Mean Token Utilization,MTU):衡量 Agent 将 token 转化为研究进展的效率。
在他们的实验中,MRU 始终低于 50%。也就是说,机器人有一半时间都处于空闲状态,在等待 Agent 思考。因此,更好的 harness 和更快的模型,会直接转化为实际收益。
PushT 是一个沿用已久的机器人操作基准。通常,要完成这个任务,需要大量人类示范数据,再加上数小时的行为克隆训练。
但他们看到,Codex、Claude Code 和 Kimi Code 都用一套基于规则的启发式方法,在不到 2 小时内「解决」了这个任务:不使用神经网络,不进行训练,也不依赖任何人类数据。
为了让更多人能在家尝试物理世界中的自动化研究,他们基于 @LeRobotHF 的 SO-101 套件 + NVIDIA Jetson Thor 开发了一整套全栈系统。这套系统可以完成 PushT 任务。
参考链接:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:杨文





